信息提供装置及存储信息提供程序的存储介质的制作方法
本发明涉及一种将用户(驾驶员)对所提供的信息进行的响应的历史记录数据进行存储并学习,基于该学习结果而提供符合用户(驾驶员)意图的信息的信息提供装置、以及存储信息提供程序的存储介质。
背景技术:
作为这种信息提供装置,已知例如国际公开wo2015/162638中所记载的装置(用户界面系统)。在该装置中,在通过语音输入而执行功能时,首先使用与当前时刻的车辆状况相关的信息推定用户(驾驶员)可能进行的语音操作的候选,将上述推定出的语音操作的候选中概率从高到低的顺序的前3个作为选项显示在触摸屏上。然后,对从上述选项中由驾驶员手动输入而选择的候选进行判断,确定语音操作的对象,并且与该所确定的语音操作的对象对应而生成催促用户进行语音输入的引导并输出。然后,通过与该引导对应而驾驶员进行语音输入,从而确定作为对象的车辆功能并执行该功能。并且,通过如上所述,通过与当前时刻的车辆状况对应而提供符合用户意图的语音操作的入口,从而能够降低进行语音输入的用户的操作负担。
但是,在上述文献所记载的装置中,在执行车辆功能时,用户界面需要从针对显示在触摸屏上的选项进行手动输入的操作模式切换为利用语音输入的操作模式,不可避免地导致驾驶员负担增加。
另外,在上述文献所记载的装置中,虽然简化了语音操作的入口,但其后的操作不过是实现了与现有的语音对话系统相同的功能,因此,人们期望进一步降低驾驶员的负担。
技术实现要素:
本发明提供一种信息提供装置及存储信息提供程序的存储介质,其能够通过始终使用简单的用户界面,在减轻驾驶员负担的同时,作为信息提供而执行符合驾驶员意图的更适当的车载设备的操作提案。
本发明的第1方式所涉及的信息提供装置具有智能电子控制单元(智能ecu)。所述智能ecu含有:状态空间构成部,其通过将多种车辆数据关联起来而定义车辆的状态,从而构成多个状态的集合即状态空间;行动空间构成部,其将表示基于驾驶员对车载设备的操作提案的响应而执行的车载设备的操作内容的数据,定义为行动,从而构成多个行动的集合即行动空间;增强学习部,其存储驾驶员对所述车载设备的操作提案的响应的历史记录,使用该存储的历史记录,设定作为表示所述车载设备的操作提案的适合程度的指标的回报函数,并且通过基于该回报函数的增强学习,计算出在构成所述状态空间的各状态下,执行构成所述行动空间的各行动的概率分布;分散度运算部,其对所述增强学习部计算出的概率分布的分散度进行运算;以及信息提供部,其在由所述分散度运算部运算出的概率分布的分散度小于阈值时,将成为对象的行动固定为操作提案的对象而输出,即进行确定的操作提案,在由所述分散度运算部运算出的概率分布的分散度为所述阈值以上时,从多个候选中将成为对象的行动选择为操作提案的对象而输出,即,进行试错性的操作提案。
另外,本发明的第2方式所涉及的存储信息提供程序的非易失性计算机可读介质中,所述信息提供程序使计算机实现下述功能,即:状态空间构成功能,其通过将多种车辆数据关联起来而定义车辆的状态,从而构成多个状态的集合即状态空间;行动空间构成功能,其将表示基于驾驶员对车载设备的操作提案的响应而执行的车载设备的操作内容的数据,定义为行动,从而构成多个行动的集合即行动空间;增强学习功能,其存储驾驶员对所述车载设备的操作提案的响应的历史记录,使用该存储的历史记录,设定作为表示所述车载设备的操作提案的适合程度的指标的回报函数,并且通过基于该回报函数的增强学习,计算出在构成所述状态空间的各状态下,执行构成所述行动空间的各行动的概率分布;分散度运算功能,其对所述增强学习功能计算出的概率分布的分散度进行运算;以及信息提供功能,其在由所述分散度运算功能运算出的概率分布的分散度小于阈值时,将成为对象的行动固定为操作提案的对象而输出,即进行确定的操作提案,在由所述分散度运算功能运算出的概率分布的分散度为所述阈值以上时,从多个候选中将成为对象的行动选择为操作提案的对象而输出,即,进行试错性的操作提案。
在上述第1、第2方式中,使用驾驶员对车载设备的操作提案的响应的历史记录,设定表示车载设备的操作提案的适合程度的指标的回报函数。并且,通过基于该回报函数的增强学习,构筑在各状态下驾驶员针对车载设备的操作提案的意思决定的模型。另外,使用该构筑好的模型,计算出在各状态下基于驾驶员针对车载设备的操作提案的响应而执行的车载设备的操作内容的概率分布。在这里,车载设备的操作内容的概率分布的分散度通常是根据车载设备的操作提案的对象不同而不同的。例如,如果车载设备的操作提案的对象是声音播放,则通常不仅受到车辆状态的影响,还容易受到此时驾驶员的情绪等影响,其选项也非常多,因此,很可能使得车载设备的操作内容的概率分布的分散度变大。另一方面,如果车载设备的操作提案的对象为目的地设定,则通常与声音播放相比,容易根据该时刻的车辆状态缩小选项范围,因此,很可能车载设备的操作内容的概率分布的分散度变小。针对这一点,在上述结构中,在概率分布的分散度小于阈值时,将成为对象的行动固定作为操作提案的对象而输出,即进行确定的操作提案,从而进行符合驾驶员意图的车载设备的操作提案,而无需驾驶员选择车载设备的操作内容。另一方面,在上述结构中,在概率分布的分散度为阈值以上时,通过从多个候选中选择成为对象的行动作为操作提案的对象进行输出,即进行试错性的操作提案,从而更可靠得进行符合驾驶员意图的车载设备的操作提案。即,在上述结构中,无论概率分布的分散度是大还是小,作为操作提案的对象而一次输出的车载设备的操作内容都只有一个,因此,驾驶员只要对每次提议的车载设备的操作内容进行是否同意的意思表示即可。因此,针对目的地的设定及声音播放这些概率分布的分散度不同的不同种类的车载设备的操作提案的响应,能够始终使用简单且相同的用户界面进行。由此,能够在减轻驾驶员的负担的同时执行符合驾驶员意图的车载设备的操作提案。
本发明的第3方式所涉及的信息提供装置具有智能电子控制单元(智能ecu)。智能ecu含有:状态空间构成部,其通过将多种车辆数据关联起来而定义车辆的状态,从而构成多个状态的集合即状态空间;行动空间构成部,其将表示基于驾驶员对车载设备的操作提案的响应而执行的车载设备的操作内容的数据,定义为行动,从而构成多个行动的集合即行动空间;增强学习部,其存储驾驶员对所述车载设备的操作提案的响应的历史记录,使用该存储的历史记录,设定作为表示所述车载设备的操作提案的适合程度的指标的回报函数,并且通过基于该回报函数的增强学习,计算出在构成所述状态空间的各状态下,执行构成所述行动空间的各行动的概率分布;分散度运算部,其通过将与构成所述状态空间的多个状态相对应的、由所述增强学习部计算出的概率分布的分散度进行加合运算,从而运算所述状态空间的分散度;以及信息提供部,其在由所述分散度运算部运算出的所述状态空间的分散度小于阈值时,将成为对象的行动固定为操作提案的对象而输出,即进行确定的操作提案,在由所述分散度运算部运算出的所述状态空间的分散度为所述阈值以上时,从多个候选中将成为对象的行动选择为操作提案的对象而输出,即,进行试错性的操作提案。
在第4方式所涉及的存储信息提供程序的非易失性计算机可读介质中,所述信息提供程序使计算机实现下述功能,即:状态空间构成功能,其通过将多种车辆数据关联起来而定义车辆的状态,从而构成多个状态的集合即状态空间;行动空间构成功能,其将表示基于驾驶员对车载设备的操作提案的响应而执行的车载设备的操作内容的数据,定义为行动,从而构成多个行动的集合即行动空间;增强学习功能,其存储驾驶员对所述车载设备的操作提案的响应的历史记录,使用该存储的历史记录,设定作为表示所述车载设备的操作提案的适合程度的指标的回报函数,并且通过基于该回报函数的增强学习,计算出在构成所述状态空间的各状态下,执行构成所述行动空间的各行动的概率分布;分散度运算功能,其通过将与构成所述状态空间的多个状态相对应的、由所述增强学习功能计算出的概率分布的分散度进行加合运算,从而运算所述状态空间的分散度;以及信息提供功能,其在由所述分散度运算功能运算出的所述状态空间的分散度小于阈值时,将成为对象的行动固定为操作提案的对象而输出,即进行确定的操作提案,在由所述分散度运算功能运算出的所述状态空间的分散度为所述阈值以上时,从多个候选中将成为对象的行动选择为操作提案的对象而输出,即,进行试错性的操作提案。
根据上述第3、第4方式,使用驾驶员对车载设备的操作提案的响应的历史记录,设定表示车载设备的操作提案的适合程度的指标的回报函数。并且,通过基于该回报函数的增强学习,构筑在各状态下驾驶员针对车载设备的操作提案的意思决定的模型。另外,使用该构筑好的模型,计算出在各状态下基于驾驶员针对车载设备的操作提案的响应而执行的车载设备的操作内容的概率分布。在这里,车载设备的操作内容的概率分布的分散度通常是根据车载设备的操作提案的对象不同而不同的。例如,如果车载设备的操作提案的对象是声音播放,则通常不仅受到车辆状态的影响,还容易受到此时驾驶员的情绪等影响,其选项也非常多,因此,很可能使得车载设备的操作内容的概率分布的分散度变大。另一方面,如果车载设备的操作提案的对象为目的地设定,则通常与声音播放相比,容易根据该时刻的车辆状态缩小选项范围,因此,很可能车载设备的操作内容的概率分布的分散度变小。针对这一点,在上述结构中,在根据概率分布的分散度的加合运算值求出的状态空间的分散度小于阈值时,将成为对象的行动固定作为操作提案的对象而输出,即进行确定的操作提案,从而进行符合驾驶员意图的车载设备的操作提案,而无需驾驶员选择车载设备的操作内容。另一方面,在上述结构中,在根据概率分布的分散度的加合运算值求出的状态空间的分散度为阈值以上时,通过从多个候选中选择成为对象的行动作为操作提案的对象进行输出,即进行试错性的操作提案,从而更可靠得进行符合驾驶员意图的车载设备的操作提案。即,在上述结构中,无论状态空间的分散度是大还是小,作为操作提案的对象而一次输出的车载设备的操作内容都只有一个,因此,驾驶员只要对每次提议的车载设备的操作内容进行是否同意的意思表示即可。因此,针对目的地的设定及声音播放这些概率分布的分散度不同的不同种类的车载设备的操作提案的响应,能够始终使用简单且相同的用户界面进行。由此,能够在减轻驾驶员的负担的同时执行符合驾驶员意图的车载设备的操作提案。
在上述第2方式中,也可以是所述增强学习部构成为,在将构成所述状态空间的各状态至构成所述行动空间的各行动的映射作为策略,且将在所述各状态下遵从所述策略的情况下所得到的累计回报的期待值设为状态值函数,将构成所述状态空间的全部状态中使所述状态值函数最大的所述策略设为最优策略时,将构成所述状态空间的各状态下从所述行动空间中选择了规定行动后遵从所述最优策略的情况下始终得到的累计回报的期待值推定为最优行动值函数,基于该推定出的最优行动值函数计算所述概率分布,所述信息提供部构成为,在由所述分散度运算部运算出的所述状态空间的分散度小于所述阈值时,将当前状态下的使所述最优行动值函数最大化的行动作为对象,进行所述确定的操作提案。
在上述结构中,在状态空间的分散度小于阈值时,将当前状态下的使最优行动值函数最大化的行动、即在当前状态下的最有价值的行动也就是预测驾驶员采用可能性最高的行动作为对象,执行确定的操作提案。由此,能够以更高一级的可靠性实现符合驾驶员意图的车载设备的操作提案。
在上述信息提供装置中,也可以是所述信息提供部构成为,在由所述分散度运算部运算出的所述状态空间的分散度为所述阈值以上时,其执行的所述试错性的操作提案呈现出的趋势为,当前状态下的所述概率分布的概率密度越高的行动,被选择为对象的频率越高。
在上述结构中,在状态空间的分散度为阈值以上时,执行的试错性的操作提案呈现出的趋势为,当前状态下的概率分布的概率密度越高的行动,即当前状态下驾驶员采用可能性较高的行动被选择为车载设备的操作提案的对象的频率越高。由此,对于作为对象的车载设备的操作提案,即使难以事先确定驾驶员的行动,也能够以更高一级的可靠性实现符合驾驶员意图的车载设备的操作提案。
在上述信息提供装置中,也可以使所述分散度运算部将构成所述状态空间的各状态下的构成所述行动空间的各行动被执行的概率分布的分散度定义为熵,并且将所述状态空间的分散度定义为平均熵,所述信息提供部使用将所述平均熵的值设定为ε值的ε-贪婪法,以ε值越大则所述试错性的操作提案频率越高的趋势,选择所述确定的操作提案或所述试错性的操作提案。
在上述结构中,定义为状态空间的分散度的平均熵的值即ε值越大、即状态空间的分散度越大,则选择试错性的操作提案的频率越高。由此,对于作为对象的车载设备的操作提案,即使难以确定驾驶员的行动,也能够以更高一级的可靠性实现符合驾驶员意图的车载设备的操作提案。
在上述信息提供装置中,也可以是所述增强学习部构成为,将根据驾驶员对所述车载设备的操作提案的响应而执行的车载设备的操作的频率,设定为所述回报函数,在与所述车载设备的操作提案对应地进行车载设备的操作时,与该操作历史记录的变更对应而更新所述回报函数。
在上述结构中,作为针对驾驶员意图的车载设备的操作提案的适合程度的指标,应用根据驾驶员对车载设备的操作提案的响应而执行的行动的频率设定回报函数,并在每次响应历史记录变更时都更新回报函数。由此,能够在符合驾驶员意图的情形下计算出构成状态空间的各状态下的执行构成行动空间的各行动的概率分布,并且能够随着驾驶员响应的频率增加,在符合驾驶员个人进行的响应的实际状态的情形下提高概率分布的精度。
在上述信息提供装置中,也可以是所述状态空间构成部构成为,作为将所述车载设备的操作状况、所述车辆的乘客的特性、以及所述车辆的行驶状况关联起来的数据组即状态的集合,构成所述状态空间。
在上述结构中,考虑车载设备的操作状况、车辆的乘客的特性、以及车辆的行驶状况等多种对向驾驶员提出的车载设备的操作提案产生影响的要素,定义构成状态空间的各状态。由此,能够在更高一级地符合实际情况的情形下,实现符合驾驶员意图的车载设备的操作提案。此外,在上述结构中,如上所述考虑到各种要素后,还可预想到构成状态空间的状态的数量变得庞大这一情况。但是,通过在存储历史记录数据的同时使用实现精度提高的增强学习的方法,从而即使没有例如像使用监督学习那样事先准备庞大数量的训练数据,也能够实现符合驾驶员意图的车载设备的操作提案。
附图说明
下面,参照附图记载本发明所示例的实施例的特征、优点、以及技术上和工业上的意义,在附图中,同一附图标记示出同一部件。
图1是表示信息提供装置的第1实施方式的概略结构的框图。
图2是表示对状态空间进行定义的车辆数据的属性的一个例子的图。
图3是表示状态空间表格的设定内容的一个例子的图。
图4是表示对状态空间进行定义的车辆数据的属性的一个例子的图。
图5是表示状态空间表格的设定内容的一个例子的图。
图6是表示行动空间表格的设定内容的一个例子的图。
图7是表示行动空间表格的设定内容的一个例子的图。
图8是表示在构成状态空间的各状态下进行构成行动空间的各行动时的跳转概率矩阵的一个例子的图。
图9是表示执行试错性的操作提案时使用的累积分布函数的一个例子的曲线图。
图10a是表示对当前状态进行定义的车辆数据的属性的一个例子的图,图10b是用于说明在图10a所示的状态下选择确定的操作提案所使用的行动的过程的图。
图11a是表示对当前状态进行定义的车辆数据的属性的一个例子的图,图11b是用于说明在图11a所示的状态下选择试错性的操作提案所使用的行动的过程的图。
图12是表示方向盘操作开关的一个例子的图。
图13是作为信息提供处理的一个例子而示出车载设备的操作提案处理的处理内容的流程图。
图14是表示在包括确定的操作提案的方式下,智能ecu与驾驶员之间交互对话的内容的一个例子的图。
图15是表示在包括试错性的操作提案的方式下,智能ecu与驾驶员之间交互对话的内容的一个例子的图。
图16是用于说明信息提供装置的第2实施方式中,选择确定的操作提案及试错性的操作提案的过程的图。
图17是表示方向盘操作开关的另一个例子的图。
图18是表示方向盘操作开关的其它例子的图。
具体实施方式
(第1实施方式)以下,说明信息提供装置的第1实施方式。本实施方式的信息提供装置由智能ecu(电子控制装置)构成,该智能ecu搭载于车辆上,向驾驶员进行作为信息提供的车载设备的操作提案。在这里,智能ecu的功能大致划分为学习类、信息获取类、用户界面类。并且,智能ecu基于通过信息获取类获取到的各种信息,将车载设备的操作历史记录根据当时的各种车辆状态而分类,并在学习类中作为学习的一个方式而执行增强学习,并且基于该增强学习的学习结果,执行经由用户界面类的车载设备的操作提案。在这里,增强学习是指,在智能ecu基于环境选择了某种行动时,通过与基于该所选择的行动发生的环境变化相伴而对智能ecu产生的某种回报,从而通过试错使得智能ecu不断适应环境的学习方法。此外,在本实施方式中,智能ecu将例如车载设备的操作状况、车辆的乘客的特性、车辆的行驶状况等各种车辆数据彼此关联起来而定义状态,从而构成多个状态的集合即状态空间。另外,智能ecu将伴随着驾驶员对操作提案的响应而智能ecu能够代替实行的某一车载设备的操作的种类定义为行动,从而构成多个行动的集合即行动空间。并且,在构成状态空间的各状态下,作为针对车载设备的操作提案的响应而执行的车载设备的操作的历史记录,相当于增强学习中所谓的回报。另外,智能ecu通过执行上述增强学习,计算出在构成状态空间的各状态下执行构成行动空间的各行动的概率分布。另外,智能ecu基于上述计算出的概率分布,根据此刻的车辆状态预测驾驶员采用可能性较高的行动,以添加该预测结果的方式执行车载设备的操作提案。
首先,参照附图说明本实施方式的装置的构成。如图1所示,智能ecu100具有:控制部110,其控制车载设备的操作提案;以及存储部120,其存储控制部110在进行车载设备的操作提案时执行的信息提供程序、以及执行该信息提供程序时控制部110读写的各种数据。在这里,作为存储在存储部120中各种数据,包括定义状态空间的状态空间表格t1、t1α,定义行动空间的行动空间表格t2、t2α、以及车载设备的操作历史记录ra。状态空间表格作为状态空间构成部起作用,行动空间表格作为行动空间构成部起作用。此外,在本实施方式中,准备了例如声音播放、目的地设定、空调设定、座椅位置设定、镜子设定、雨刷设定等多种作为操作提案的对象的服务种类。并且,在智能ecu100的存储部120中,针对上述服务的各个种类而分别存储相应的状态空间表格t1、t1α及行动空间表格t2、t2α。
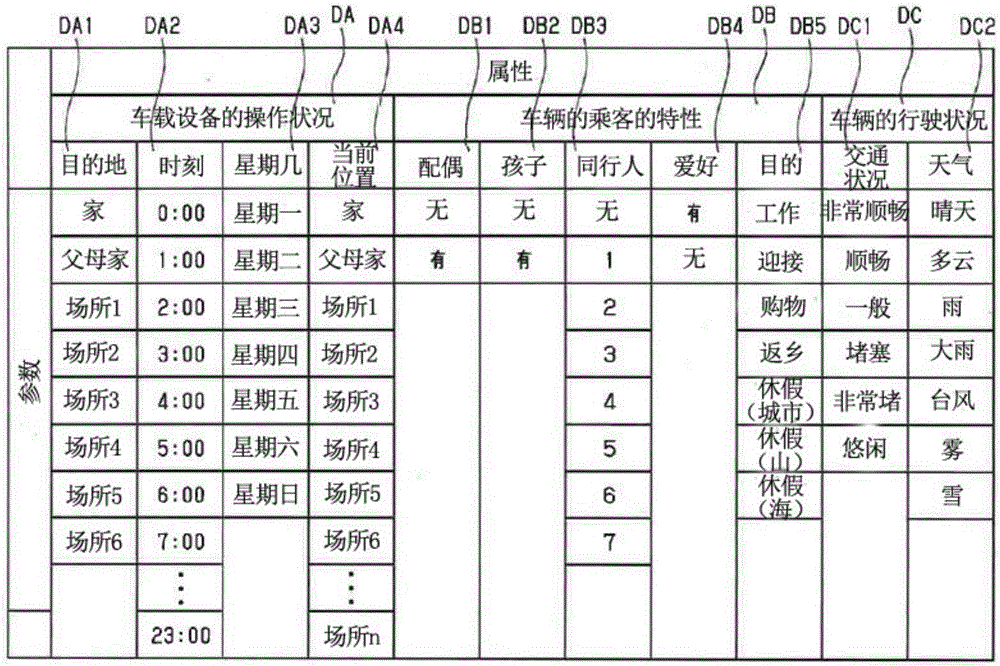
图2中,作为操作提案的一个例子而示出在进行目的地设定时状态定义所使用的车辆数据的属性的一个例子。在这里,车辆数据的属性是指作为对目的地设定的方法有帮助的要素而预先登记的内容,在该图所示的例子中,包括与车载设备的操作状况da、车辆的乘客的特性db、车辆的行驶状况dc相关的车辆数据。此外,作为与车载设备的操作状况da相关的车辆数据的一个例子,举出目的地da1、时刻da2、星期几da3、当前位置da4。另外,作为与车辆的乘客的特性db相关的车辆数据的一个例子,举出有无配偶db1、有无孩子db2、同行人数量db3、有无爱好db4、目的db5。另外,作为与车辆的行驶状况dc相关的车辆数据的一个例子,举出交通状况(堵车程度)dc1、天气dc2。
并且,如图3所示,状态空间表格t1通过将图2所示的车辆数据的属性通过轮询方式进行组合而定义状态,构成多个状态的集合即状态空间。在这里,状态空间表格t1含有的状态的数量m(例如为400万左右)随着构成车辆数据的属性的要素种类(在图2所示的例子中,包括从左侧开始顺序为“目的地”至“天气”为止的11种)或各要素的参数数量(在图2所示的例子中,例如作为“目的地”的参数数量为8个)变多而增加。
另一方面,图4中,作为操作提案的一个例子而示出进行声音播放时的状态定义所使用的车辆数据的属性的一个例子。在这里,车辆数据的属性是指作为对声音播放的方式有帮助的要素而预先登记的内容,在该图所示的例子中,包含与车载设备的操作状况daα、车辆的乘客的特性dbα、车辆的行驶状况dcα相关的车辆数据。此外,作为与车载设备的操作状况daα相关的车辆数据的一个例子,举出音源da1α、重复播放设定da2α、音量da3α、时刻da4α、星期几da5α、当前位置da6α。另外,作为与车辆的乘客的特性dbα相关的车辆数据的一个例子,举出有无配偶db1α、有无孩子db2α、同行人数量db3α、驾驶员的困倦程度db4α。另外,作为与车辆的行驶状况dcα相关的车辆数据的一个例子,举出包括车辆周边的城市化·郊野化的程度及道路环境在内的环境dc1α。
并且,如图5所示,状态空间表格t1α通过将图4所示的车辆数据的属性通过轮询方式进行组合而定义状态,构成多个状态的集合即状态空间。在这里,状态空间表格t1α含有的状态的数量n(例如为15亿左右)也是随着构成车辆数据的属性的要素种类或各要素的参数数量变多而增加。
图6示出智能ecu100对作为操作提案的一个例子的代为实行目的地设定时的行动进行定义而构成多个行动的集合即行动空间的行动空间表格t2的一个例子。在该图所示的例子中,作为行动空间含有的行动的种类,举出作为设定的对象的目的地的场所名称的一览。在这里,作为设定的对象的目的地的场所是指,例如作为过去由驾驶员自己设定的频率特别高的场所名而预先登记的内容,在该图所示的例子中,除了“家”,“父母家”之外,还登记有“场所1”~“场所6”等共计8个场所名。
另外,图7示出智能ecu100对作为操作提案的一个例子的代为实行声音播放时的行动进行定义而构成多个行动的集合即行动空间的行动空间表格t2α的一个例子。在该图所示的例子中,作为行动空间所包含的行动的种类,举出作为播放对象的音源的一览。在这里,作为播放对象的音源是指,例如作为过去由驾驶员播放的频率特别高的音源而预先登记的内容,在该图所示的例子中,登记有包括收音机的频道名、以及移动终端或cd(compactdisk)等存储介质中保存的乐曲的曲名在内的共计100个音源。
另外,如图1所示,智能ecu100经由例如can(控制器局域网)等构成的车辆网络nw而与其它ecu组130、传感器组131、以及开关组132连接。
其它ecu组130是控制各种车载设备的动作的车载ecu,包括对发动机、制动器、转向舵等进行控制的车辆驱动类的车载ecu、对空调、仪表等进行控制的车身类的车载ecu、对导航系统、音频系统等进行控制的信息类的车载ecu。
传感器组131是用于取得各种车辆数据的传感器组,包括gps(全球定位系统)传感器、激光雷达、红外线传感器、超声波传感器、雨滴传感器、外部气温传感器、车厢内温度传感器、就座传感器、安全带佩戴状态传感器、车厢内照相机、智能钥匙传感器(注册商标“スマートキー”)、入侵监视传感器、花粉等微粒传感器、加速度传感器、电场强度传感器、驾驶员监视器、车速传感器、转向角传感器、偏航率传感器,生物体传感器。
开关组132是用于对各种车载设备的动作进行切换的开关组,包括转向杆开关、雨刷操作开关、车灯操作开关、方向盘操作开关、导航·音频操作开关、车窗操作开关、车门·行李箱开闭·锁定开关、空调操作开关、座椅加热·通风开关、座椅位置调整·预设值存储开关、入侵监视系统开关、后视镜操作开关、自适应巡航控制(acc)开关、发动机开关。
并且,智能ecu100的控制部110在从上述其它ecu组130、传感器组131、及开关组132经由车辆网络nw输入了各种车辆数据后,参照存储在存储部120中的状态空间表格t1、t1α确定相应的车辆状态。另外,智能ecu100的控制部110在每次根据驾驶员针对车载设备的操作提案的响应而从行动空间所包含的行动中选择规定的行动并执行车载设备的操作时,都对存储在存储部120中的车载设备的操作历史记录ra中与该状态对应的操作历史记录的计数值进行累加计算。在这一点上,智能ecu100的控制部110是存储在构成状态空间的各状态下驾驶员针对车载设备的操作提案的响应的历史记录数据的部件。
另外,智能ecu100的控制部110,对于在如上所述进行了学习的各状态下,将接受操作提案时的车载设备的操作历史记录的计数值设定为回报函数,同时作为通过以下(步骤1)~(步骤7)的流程执行增强学习种类之一的q学习的增强学习部111起作用。
(步骤1)在将从构成状态空间的各状态至构成行动空间的各行动的映射作为策略π时,在初始设定任意的策略π。(步骤2)观测当前状态st(t为时间步长)。(步骤3)基于任意的行动选择方法执行行动at(t为时间步长)。(步骤4)获取回报rt(t为时间步长)。(步骤5)观测状态跳转后的状态s(t+1)(其前提为,向状态s(t+1)的跳转仅与此时的状态st和行动at相关,并不受到此前的状态及行动的影响(即所谓的马尔可夫性))。(步骤6)更新行动值函数q(st,at)。(步骤7)将时间步长t前进至(t+1)后返回(步骤1)。
此外,作为在(步骤3)的流程中的行动选择方法,可以使用后述的必定选择使行动值函数q(st,at)的值为最大的行动的贪婪法,或者相反地使用将各种行动以相同概率进行选择的随机法。另外,还可以使用以概率ε通过随机法进行行动选择且以概率(1-ε)通过贪婪法进行行动选择的ε-贪婪法,或者以高概率选择行动值函数q(st,at)较高的行动且以低概率选择行动值函数q(st,at)较低的行动的玻尔兹曼选择等方法。
另外,在(步骤6)的流程中的行动值函数q(st,at)的更新基于下述算式(1)进行。
q(st,at)=(1-α)q(st,at)+α(rt+γmaxat+1∈aq(st+1,at+1))
...(1)
此外,在算式(1)中将学习率α设定为0<α<1的数值范围内。这是为了使得随着时间经过而不断更新的行动值函数q(st,at)的增大量逐渐减少而容易收敛。另外,在该算式(1)中,q(st,at)表示上述的行动值函数,其表示以增强学习部111与时间经过无关地采取固定策略π为前提时,在状态st下采用行动at后遵从策略π的情况所得到的折算累积回报rt的期待值。在这里,折算累积回报rt是指在反复发生状态跳转中得到的回报的总和,根据以下算式(2)得出。
此外,在算式(2)(算式(1)也相同地)中,将折算率γ设定在0<γ<1的数值范围内。这是为了使得随着时间经过而得到的回报值逐渐减少,从而使得折算累积回报rt的值容易收敛。
然后,增强学习部111通过反复进行上述(步骤1)~(步骤7)的流程,从而计算出使行动值函数q(st,at)最大化(最优化)的最优行动值函数q*(st,at)。在这里,最优行动值函数q*(st,at)表示在将表示状态st下遵从策略π的情况所得到的折算累积回报rt的期待值的函数设为状态值函数v(st),将所有状态st下满足v(st)≧v’(st)的策略π作为最优策略π*时,在状态st下选择行动at后遵从最优策略π*的情况下所得到的折算累积回报rt的期待值。
并且,增强学习部111将如上所述得到的最优行动值函数q*(st,at)代入以下算式(3)。由此,计算出从构成状态空间的各状态向构成行动空间的各行动跳转的跳转概率矩阵中的使折算累积回报rt最大化的跳转概率矩阵、即计算出考虑各状态的操作历史记录ra的计数值且符合驾驶员意图的跳转概率矩阵p(st,at)。
图8示出如上所述计算出的跳转概率矩阵p(st,at)的一个例子。跳转概率矩阵p(st,at)的各行对应于构成状态空间的各状态,各列对应于构成行动空间的各行动。并且,在该图所示的例子中,例如将状态s1下采用行动a1的概率设为“0.01”,在该状态s1下采用行动a2的概率设为“0.10”,在该状态s1下采用行动a100的概率设为“0.03”。
并且,智能ecu100的控制部110在将上述概率作为p时,使用图8所示的算式计算出信息熵h(s)。此外,信息熵h(s)是作为概率分布的分散度的指标的参数。从这一点来说,智能ecu100的控制部110还作为对由增强学习部111计算出的概率分布的分散度进行运算的分散度运算部112起作用。并且,信息熵h(s)的值越大,就表示概率分布的分散度越大,即状态st下采用构成行动空间的各行动的概率越均匀地分散。因此,在信息熵h(s)的值较大的情况下,难以预测驾驶员要从构成行动空间的行动中采用的行动。
另外,分散度运算部112如以下的算式(4)所示,将针对构成状态空间的各状态计算出的信息熵h(s)进行加合运算而计算出平均熵h(ω)。
此外,平均熵h(ω)是表示状态空间的分散度的参数。并且,平均熵h(ω)的值越大,表示状态空间的分散度就越大,即在对状态空间整体进行观察时各状态下采用构成行动空间的各行动的概率就越均匀地分散。因此,平均熵h(ω)的值成为能否针对作为操作提案的对象的服务而预测驾驶员从构成行动空间的行动中可能采用的行动的指标。
因此,智能ecu100的控制部110还作为提案信息生成部113起作用,该提案信息生成部113根据以下算法而使用将由增强学习部111求出的平均熵h(ω)作为ε值的ε-贪婪法,生成与车载设备的操作提案相关的信息。提案信息生成部还作为信息提供部起作用。
此外,在上述算法中,提案信息生成部113设定落在0~1的数值范围内的随机数δ(阈值),在满足“δ>ε”的条件时,应用算式(5)。即,由增强学习部111求出的平均熵h(ω)的值越小,提案信息生成部113就越提高应用算式(5)的频率。并且,提案信息生成部113通过应用算式(5),将如上所述使得由增强学习部111求出的最优行动值函数q*(st,at)最大化的行动a也就是状态s下最有价值的行动作为操作提案的对象进行输出,即执行确定的操作提案。
另一方面,在上述算法中,提案信息生成部113在满足“δ≦ε”的条件时,应用算式(6)。即,由增强学习部111求出的平均熵h(ω)的值越大,提案信息生成部113就越提高应用算式(6)的频率。提案信息生成部113在应用算式(6)时,首先将某一状态s下采用构成行动空间的各行动的概率进行加合运算而求出累积分布函数f(s)。并且,提案信息生成部113在设定与上述随机数δ不同的变量即落在0~1的数值范围内的随机数τ时,执行将满足“f(s)=τ”的行动作为操作提案的对象进行输出的试错性的操作提案。
根据图9中作为一个例子而示出的累积分布函数f(s)也可知,与采用构成行动空间的各行动的概率对应地,累积分布函数f(s)的增加量也发生变动。具体地说,在概率较高的行动所对应的横轴的区间,累积分布函数f(s)的增加量变得剧烈,另一方面,在概率较低的行动所对应的横轴的区间,累积分布函数f(s)的增加量也变得缓慢。因此,在使随机数τ在0~1的数值范围内变化时,概率较高的行动更容易满足“f(s)=τ”这一条件,概率较低的行动难以满足“f(s)=τ”这一条件。由此,如上述所示,在将满足“f(s)=τ”的行动作为操作提案的对象进行输出时,以概率越高的行动被选择的频率就越高的趋势而进行输出。此外,在该图所示的例子中,满足f(s)=τ时的所对应的行动为行动a3’。因此,从构成行动空间的多个行动中选择行动a3’作为操作提案的对象而输出。
图10a、b示出用于说明在作为操作提案而进行目的地设定时,使用ε-贪婪法进行确定的操作提案和试错性的操作提案的选择的具体例子。
在该例子中,如图10a所示,智能ecu100首先基于通过车辆网络nw获取的各种车辆数据,提取出当前状态符合状态空间表格t1中构成状态空间的各状态中的哪一个状态(在该图中,提取出状态si)。并且,在该例子中,处于根据跳转概率矩阵p(st,at)求出的平均熵h(ω)比较高的状况,进行应用上述算式(5)的确定的操作提案的频率变高。在此情况下,如图10b所示,智能ecu100将构成行动空间的各行动中的当前状态下最有价值的行动(在该图所示的例子中为“家”)作为操作提案的对象而输出。
另外,图11a、b示出用于说明在作为操作提案而进行声音播放时,使用ε-贪婪法进行确定的操作提案和试错性的操作提案的选择的具体例子。
该例子如图11a所示,智能ecu100首先基于通过车辆网络nw获取的各种车辆数据,提取出当前状态符合状态空间表格t1α中构成状态空间的各状态中的哪一个状态(在该图中,提取出状态sj)。并且,在该例子中,处于根据跳转概率矩阵p(st,at)求出的平均熵h(ω)较低的状况,进行应用上述算式(6)的试错性的操作提案的频率变高。在此情况下,如图11b所示,智能ecu100以构成行动空间的各行动中的从当前状态跳转的跳转概率的概率密度越高的行动被选择的频率就越高的趋势,作为操作提案的对象而随机输出(在该图所示的例子中为“fmd”)。
并且,智能ecu100将上述作为操作提案的对象输出的行动的相关信息,经由车辆网络nw向扬声器等声音输出部140、或者lcd(液晶显示器)及hud(抬头显示器)等的图像输出部141发送,执行经由声音或图像的车载设备的操作提案。
另外,智能ecu100还作为操作检测部114起作用,该操作检测部114经由车辆网络nw接收经由方向盘操作开关、拾音器等操作输入部142的操作输入、或者语音输入的操作信号,从而检测驾驶员对操作提案的响应。
图12是用于说明经由方向盘操作开关进行的操作输入的一个例子的图。在该图所示的例子中,方向盘操作开关142a具有4个操作按钮ba1~ba4,这些操作按钮中位于上方的第1操作按钮ba1及位于下方的第2操作按钮ba2,被分配为在对来自智能ecu100的操作提案进行响应时操作的操作按钮。并且,在接受操作提案时操作第1操作按钮ba1,相反,在拒绝操作提案时操作第2操作按钮ba2。另外,这些操作按钮中位于左方的第3操作按钮ba3及位于右方的第4操作按钮ba4,被分配为在进行与来自智能ecu100的操作提案无关的车载设备操作时进行操作的操作按钮。并且,通过由驾驶员自己手动输入而操作车载设备时,操作第3操作按钮ba3,在驾驶员自己进行与此刻的车辆状态无关且以较高频率进行的车载设备的操作时,操作第4操作按钮ba4。此外,第4操作按钮ba4也可以被分配成为如下的操作按钮,即,将从外部服务器获取的、在与当前状况为相同状况时其他驾驶员曾经进行的车载设备的操作相关的信息,提供给本驾驶员时进行操作的操作按钮。
并且,智能ecu100的控制部110在由操作检测部114检测出操作信号后,促使从学习更新触发部115向增强学习部111发送触发信号。此外,如上所述,在本实施方式中,接受操作提案时的车载设备的操作历史记录的计数值被设定为增强学习中的回报函数。因此,如果以图12所示的方向盘操作开关142a为例,则在操作第1操作按钮ba1而接受操作提案时,从学习更新触发部115向增强学习部111发送触发信号。
并且,增强学习部111在从学习更新触发部115接收到触发信号后,基于该时刻通过车辆网络nw获取的各种车辆数据,确定当前状态符合状态空间表格t1、t1α中的构成状态空间的各状态中的哪一种状态。并且,增强学习部111对存储在存储部120中的车载设备的操作历史记录ra中与该状态对应的操作历史记录的计数值进行累加计算。
另外,增强学习部111在更新车载设备的操作历史记录ra后,使用与该操作历史记录ra更新一起更新后的回报函数,重新计算出最优行动值函数q*(st,at)、及基于该最优行动值函数q*(st,at)得到的跳转概率矩阵p(st,at)。并且,提案信息生成部113基于由增强学习部111重新计算出的跳转概率矩阵p(st,at),执行符合驾驶员意图的车载设备的操作提案。
然后,针对本实施方式的智能ecu100读出存储在存储部120中的信息提供程序并执行的车载设备的操作提案处理,说明该具体的处理步骤。在这里,智能ecu100以车辆的点火开关接通为条件,开始图13所示的车载设备的操作提案处理。
如图13所示,在该车载设备的操作提案处理中,首先智能ecu100判定存储在存储部120中的操作历史记录ra是否更新、即是否从学习更新触发部115向增强学习部111发送了触发信号(步骤s10)。
然后,智能ecu100在操作历史记录ra有更新时(步骤s10=是),因回报函数也被同时更新了,所以使用该更新后的回报函数而通过增强学习部111计算出最优行动值函数q*(st,at)(步骤s11)。
另外,智能ecu100基于如上述所示计算出的最优行动值函数q*(st,at),通过增强学习部111计算出从构成状态空间的各状态向构成行动空间的各行动跳转的跳转概率矩阵p(st,at)(步骤s12)。
另外,智能ecu100基于如上述所示计算出的跳转概率矩阵p(st,at),通过分散度运算部112计算出构成状态空间的各状态的各自的信息熵h(s)(步骤s13)。进而,智能ecu100通过分散度运算部112计算出对各状态的各自的信息熵h(s)进行加合运算而得到的平均熵h(ω)(步骤s14)。
并且,智能ecu100在如上述所示计算出的平均熵h(ω)小于作为随机数设定的随机数δ时(步骤s15=是),将使得在先前的步骤s11中计算出的最优行动值函数q*(st,at)最大化的行动a,作为自动设定的对象而从提案信息生成部113固定地向声音输出部140或图像输出部141输出,即执行确定的操作提案(步骤s16)。
另一方面,智能ecu100在先前的步骤s14中计算出的平均熵h(ω)为随机数δ以上时(步骤s15=否),基于在先前的步骤s12中计算出的跳转概率矩阵p(st,at),以在当前状态st下执行概率越高的行动则被选择的频率越高的趋势,将该行动作为自动设定的对象随机输出,即执行试错性的操作提案(步骤s17)。
然后,智能ecu100在驾驶员对先前的步骤s16或先前的步骤s17的操作提案进行响应时,通过操作输入部142获取与该响应相关的信息(步骤s18)。并且,智能ecu100判断如上述所示获取到的来自驾驶员的响应是否为接受操作提案(步骤s19)。例如在经由方向盘操作开关进行操作输入的情况下,根据是否按压了确定按钮(在图12所示的例子中为第1操作按钮ba1)、或者在经由拾音器进行语音输入的情况下,根据是否输入了表示肯定响应的单词(例如“是”、“yes”等)而进行上述判断。
并且,在来自驾驶员的响应为接受操作提案时(步骤s19=是),智能ecu100执行在先前的步骤s16或步骤s17中作为自动设定的对象而输出的行动(步骤s20)。另外,智能ecu100随着作为自动设定的对象而输出的行动的执行,从学习更新触发部115向增强学习部111发送触发信号,在通过增强学习部111更新车载设备的操作历史记录ra后(步骤s21),使该处理跳转至步骤s22。
另一方面,智能ecu100在来自驾驶员的响应并非接受操作提案时(步骤s19=否),不经过前述步骤s20及步骤s21的处理而使处理跳转至步骤s22。
然后,智能ecu100在车辆的点火开关接通的期间(步骤s22=否),使该处理返回步骤s10,以规定周期反复进行步骤s10~步骤s22的处理。此时,如果在先前的步骤s21中更新了车载设备的操作历史记录ra,智能ecu100则使用伴随该操作历史记录ra更新而一起更新后的回报函数,重新计算出最优行动值函数q*(st,at)、以及基于该最优行动值函数q*(st,at)的新的跳转概率矩阵p(st,at)(步骤s11、步骤s12)。并且,智能ecu100基于重新计算出的跳转概率矩阵p(st,at),作为车载设备的操作提案而执行上述的确定的操作提案或试错性的操作提案(步骤s16、步骤s17)。
然后,在每次作为对操作提案的响应而驾驶员对操作输入部142进行操作接受操作提案时,智能ecu100都更新车载设备的操作历史记录ra,并与该更新一起反复进行由增强学习部111进行的增强学习。由此,随着驾驶员对车载设备的操作提案的响应频率不断增加,跳转概率矩阵p(st,at)的精度提高并从而符合驾驶员个人行动的实际情况。
下面,针对本实施方式的智能ecu100的作用,特别着眼于在执行车载设备的操作提案时的作用进行如下说明。在执行车载设备的操作提案时,通常,与此时的车辆状态对应而提前预测驾驶员要采用的行动的难度是随着成为对象的操作提案的种类不同而变化的。例如收音机播放或乐曲播放等在车辆行驶时的声音播放,通常不仅受到车辆状态的影响,还容易受到此时的驾驶员的情绪等影响,其选项也很多。因此,提前预测驾驶员要采用的行动变得困难这一情况是可以预想到的。另一方面,例如目的地设定等,可以预想到,通常与声音播放相比,容易根据此时的车辆状态缩小选项范围,从而提前预测驾驶员要采用的行动。
因此,在本实施方式中,智能ecu100针对各种不同的操作提案种类,将作为对操作提案的响应而进行的车载设备的操作历史记录ra作为日志进行记录,执行将记录到的操作历史记录ra设定为回报函数的增强学习。由此,智能ecu100以符合驾驶员个人行动的实际情况的方式,计算出从构成状态空间的各状态向构成行动空间的各行动跳转的跳转概率矩阵p(st,at)。
在此情况下,如上述所示,在基于与声音播放对应的车载设备的操作历史记录ra计算出的跳转概率矩阵p(st,at)中,在构成状态空间的各状态下采用构成行动空间的各行动的概率相对容易分散。另一方面,也如上述所示,在基于与目的地设定对应的车载设备的操作历史记录ra计算出的跳转概率矩阵p(st,at)中,在构成状态空间的各状态下采用构成行动空间的各行动的概率相对难以分散。
因此,在本实施方式中,智能ecu100基于将构成状态空间的各状态的各自的信息熵h(s)的值进行加合运算而得到的平均熵h(ω)的值,进行上述状态空间的分散度的评价。
并且,智能ecu100在平均熵h(ω)小于随机数δ时,将当前状态下最有价值的行动固定为操作提案的对象而输出,即执行确定的操作提案。在此情况下,平均熵h(ω)的值越小,智能ecu100就越提高执行确定的操作提案的频率。
图14示出以包含确定的操作提案的方式在智能ecu100和驾驶员之间进行交互对话的内容的一个例子。在该图所示的例子中,智能ecu100作为确定的操作提案而确认成为自动设定的对象的目的地是否为“家”。并且,智能ecu100在驾驶员输入了表示接受确定的操作提案这一情况的声音指令(在该图所示的例子中为“yes”)后,作为目的地而自动设定为“家”。这样,智能ecu100在例如目的地设定这种易于确定当前状态下驾驶员采用构成行动空间的行动中的哪一种行动的状况下,能够进行符合驾驶员意图的车载设备的操作提案,而无需驾驶员进行选择行动的操作。
另一方面,智能ecu100在平均熵h(ω)为随机数δ以上时,以从当前状态跳转的跳转概率的概率密度越高则被选择的频率越高的趋势,将随机选择的行动作为操作提案的对象输出,即执行试错性的操作提案。在此情况下,平均熵h(ω)的值越大,智能ecu100执行试错性的操作提案的频率越高。
图15示出以包含试错性的操作提案的方式在智能ecu100和驾驶员之间进行交互对话的内容的一个例子。在该图所示的例子中,智能ecu100首先向驾驶员确认是否开始试错性的操作提案。然后,智能ecu100在驾驶员输入接受试错性的操作提案的声音指令(在该图所示的例子中为“yes”)后,作为在从当前状态跳转的跳转概率的概率密度较高的行动中随机选择的行动,将“fma”这一选择向驾驶员提出。然后,智能ecu100在驾驶员输入接受所提出的声音方案的声音指令后,作为声音方案而自动设定“fma”。另外,如果在播放声音后,被输入了拒绝所提出的声音方案的声音指令(在该图所示的例子中为“no”)后,智能ecu100以上述跳转概率的概率密度越高的行动则被选择的频率越高的趋势,作为随机选择的其它行动而将“cd乐曲n”这一选择向驾驶员提出。并且,智能ecu100以跳转概率的概率密度越高的行动则被选择的频率越高的趋势,将随机选择的其它行动依次向驾驶员提出,直至驾驶员输入了接受所提出的声音方案的声音指令为止。并且,在“cd乐曲2”这一选择的提案被接受时,智能ecu100作为声音而自动设定“cd乐曲2”。这样,智能ecu100在例如声音设定这种难以确定在当前状态下驾驶员会采用构成行动空间的行动中的哪一个行动的状况下,通过从多个候选中选择成为对象的行动并输出,从而更可靠地进行符合驾驶员意图的车载设备的操作提案。
如上述说明所示,根据本实施方式,能够得到下述效果。
(1)智能ecu100在基于通过增强学习计算出的跳转概率矩阵p(st,at)中的各状态各自的信息熵h(s)的加合运算值而求出的平均熵h(ω)小于随机数δ时,将成为对象的行动固定为操作提案的对象而输出,即进行确定的操作提案。由此,能够进行符合驾驶员意图的车载设备的操作提案,而无需驾驶员进行选择行动的操作。另一方面,智能ecu100在基于通过增强学习计算出的跳转概率矩阵p(st,at)中的各状态各自的信息熵h(s)的加合运算值而求出的平均熵h(ω)为随机数δ以上时,从多个候选中选择成为对象的行动作为操作提案的对象进行输出,即进行试错性的操作提案。由此,能够更可靠得进行符合驾驶员意图的车载设备的操作提案。即,无论平均熵h(ω)是大还是小,作为操作提案的对象而一次输出的车载设备的操作内容都只有一个,因此,驾驶员只要对每次提议的车载设备的操作内容进行是否同意的意思表示即可。因此,针对目的地的设定及声音播放这些平均熵h(ω)的分散度不同的不同种类的车载设备的操作提案的响应,能够始终使用简单且相同的作为用户界面的操作输入部142进行。由此,能够在减轻驾驶员的负担的同时执行符合驾驶员意图的车载设备的操作提案。
(2)智能ecu100在平均熵h(ω)的值小于随机数δ时,将当前状态下的使最优行动值函数q*(st,at)最大化的行动、即在当前状态下的最有价值的行动也就是预测驾驶员采用可能性最高的行动作为对象,执行确定的操作提案。由此,能够以更高一级的可靠性实现符合驾驶员意图的操作提案。
(3)智能ecu100在平均熵h(ω)的值为随机数δ以上时,以当前状态下的概率分布的概率密度越高的行动、即当前状态下驾驶员采用可能性越高的行动被选择为对象的频率越高的趋势,进行试错性的操作提案。由此,即使事先难以确定作为对象的车载设备的操作提案,也能够以更高一级的可靠性实现符合驾驶员意图的操作提案。
(4)智能ecu100使用将平均熵h(ω)的值设定为ε值的ε-贪婪法,以ε值越大则进行试错性的操作提案的频率越高的趋势,进行确定的操作提案和试错性的操作提案的选择。因此,平均熵的值即ε值越大即状态空间的分散度越大,智能ecu100选择试错性的操作提案的频率越高。由此,在提供作为对象的信息时,即使难以确定驾驶员的行动,也能够以更高一级的可靠性实现符合驾驶员意图的操作提案。
(5)作为针对驾驶员意图的车载设备的操作提案的适合程度的指标,智能ecu100应用根据对操作提案的响应而从构成行动空间的行动中选择并执行的行动的频率设定回报函数,并在每次响应历史记录(车载设备的操作历史记录ra)更新时一并更新回报函数。由此,能够在符合驾驶员意图的情形下就算出构成状态空间的各状态下执行构成行动空间的各行动的跳转概率矩阵p(st,at),并且能够随着驾驶员响应的频率不断增加而使跳转概率矩阵p(st,at)的精度提高进而更符合驾驶员个人进行的响应的实际状态。
(6)智能ecu100考虑车载设备的操作状况da、daα、车辆的乘客的特性db、dbα、以及车辆的行驶状况dc、dcα等多种对车载设备的操作提案产生影响的要素,定义构成状态空间的各状态。由此,能够在更高一级地符合实际情况的情形下,实现符合驾驶员意图的操作提案。此外,可以预想到,如上所述考虑了各种要素后,构成状态空间的状态的数量变得庞大。对于这一点,在上述实施方式中,通过在存储操作历史记录ra的同时使用实现精度提高的增强学习的方法,从而即使没有例如像监督学习那样事先准备庞大数量的训练数据,也能够实现符合驾驶员意图的操作提案。
(第2实施方式)下面,参照附图,说明信息提供装置的第2实施方式。此外,第2实施方式与第1实施方式不同的点在于,不将各状态各自的信息熵的值进行加合运算求出平均熵的值,而是基于与当前状态对应的信息熵的值进行确定的操作提案及试错性的操作提案的选择。由此,在以下的说明中,主要说明与第1实施方式不同的结构,对于与第1实施方式相同或相当的结构,省略重复的说明。
图16示出本实施方式中在确定的操作提案及试错性的操作提案的选择时所使用的跳转概率矩阵p(st,at)的一个例子。在该图所示的例子中,例如假设状态si下采用行动a1的概率为“0.03”,假设该状态si下采用行动a2的概率为“0.04”,假设该状态si下采用行动a100的概率为“0.02”。并且,在将上述概率设为p时,智能ecu100使用图8所示的算式计算出信息熵h(s)的值。在此情况下,由于这些概率均匀地分散,所以信息熵h(s)的值变得较大。
另外,同样在该图所示的例子中,例如假设状态sj下采用行动a1的概率为“0.6”,假设该状态sj下采用行动a2的概率为“0.02”,假设该状态sj下采用行动a100的概率为“0.04”。并且,在将上述概率设为p时,智能ecu100使用图8所示的算式计算出信息熵h(s)的值。在此情况下,由于上述概率偏向一处(“行动a1”),所以信息熵h(s)的值变得较小。
并且,智能ecu100大致基于上述第1实施方式中使用的算法,使用将与当前状态对应的信息熵h(s)的值设为ε值的ε-贪婪法,生成与车载设备的操作提案相关的信息。由此,在假设当前状态为图16所示的状态si时那样,与当前状态对应的信息熵h(s)的值较大时,智能ecu100通过应用上述算式(6),从而提高执行试错性的操作提案的频率。另一方面,在假设当前状态如图16所示的状态sj时那样,与当前状态对应的信息熵h(s)的值较小时,智能ecu100通过应用上述算式(5),从而提高执行确定的操作提案的频率。即,即使在例如目的地设定这样从状态空间整体观察时平均熵h(ω)的值较小的情况下,在与当前状态对应的信息熵h(s)的值为随机数δ以上时,智能ecu100也判断为处于仅考虑当前状态的话难以确定驾驶员会采用构成行动空间的行动中的哪一个行动的状况,因而执行试错性的操作提案。另外相反地,即使在例如声音设定这样从状态空间整体观察时平均熵h(ω)的值较大时,在与当前状态对应的信息熵h(s)的值小于随机数δ时,智能ecu100也判断为处于仅考虑当前状态的话容易确定驾驶员会采用构成行动空间的行动中的哪一种行动的状况,因而执行确定的操作提案。这样,智能ecu100通过个别具体地考虑当前状态下是否容易确定驾驶员的行动,从而能够以更高一层地契合实际情形的方式,进行符合驾驶员意图的车载设备的操作提案。
如以上说明所示,根据上述第2实施方式,能够替代第1实施方式的上述(1)所述的效果而得到以下所示的效果。(1a)在通过增强学习计算出的跳转概率矩阵p(st,at)中与当前状态对应的信息熵h(s)为随机数δ以上时,智能ecu100将从多个候选中选择成为对象的行动进行输出的试错性的操作提案,作为车载设备的操作提案。由此,能够更可靠地进行符合驾驶员意图的车载设备的操作提案。另一方面,在通过增强学习就算出的跳转概率矩阵p(st,at)中与当前状态对应的信息熵h(s)小于随机数δ时,智能ecu100将固定成为对象的行动进行输出的确定的操作提案,作为车载设备的操作提案。由此,能够进行符合驾驶员意图的车载设备的操作提案,而无需驾驶员进行选择行动的操作。即,无论各状态各自的信息熵h(s)的分散度是大还是小,作为操作提案的对象而一次输出的车载设备的操作内容都只有一个,因此,驾驶员只要对每次提议的车载设备的操作内容进行是否同意的意思表示即可。因此,针对目的地的设定及声音播放这些各状态各自的信息熵h(s)的分散度不同的不同种类的车载设备的操作提案的响应,能够始终使用简单且相同的作为用户界面的操作输入部142进行。由此,能够在减轻驾驶员的负担的同时执行符合驾驶员意图的车载设备的操作提案。另外,智能ecu100与定义从状态空间整体观察下的状态空间的分散度的平均熵h(ω)的值无关地,基于与当前状态对应的信息熵h(s)的值,选择试错性的操作提案及确定的操作提案。由此,智能ecu100通过个别具体地考虑当前状态下是否容易确定驾驶员的行动,从而能够以更高一层地契合实际情形的方式,进行符合驾驶员意图的车载设备的操作提案。
(其它实施方式)此外,上述各实施方式也可以以下述方式实施。
·在上述第1实施方式中,通过对定义状态空间的所有状态所对应的信息熵h(s)进行加合运算,从而计算出对状态空间的分散度进行定义的平均熵h(ω)。但也可以不用这种方式,而是将定义状态空间的状态中的一部分状态所对应的信息熵h(s)进行加合运算而计算出平均熵h(ω)。
·在上述第1实施方式中,作为成为与平均熵h(ω)进行比较的对象的阈值而使用随机数δ。由此,能够更具多样性地进行分配,但为了降低处理负载,也可以不用这种方式,而使用固定值作为与平均熵h(ω)进行比较的对象的阈值。在此情况下,在平均熵h(ω)小于固定值时,应用上述算式(5)执行确定的操作提案,另一方面在平均熵h(ω)为固定值以上时,应用上述算式(6)执行试错性的操作提案即可。
·相同地,在上述第2实施方式中,作为成为与当前状态对应的信息熵h(s)进行比较的对象的阈值而使用随机数δ。也可以不用这种方式,而使用固定值作为成为与当前状态对应的信息熵h(s)进行比较的对象的阈值。在此情况下,在信息熵h(s)小于固定值时,应用上述算式(5)执行确定的操作提案,另一方面在与当前状态对应的信息熵h(s)为固定值以上时,应用上述算式(6)执行试错性的操作提案即可。
·在上述第1实施方式中,状态空间的分散度的评价是基于将与构成状态空间的各状态对应的信息熵h(s)进行加合运算而得到的平均熵h(ω)进行的。也可以不用这种方式,而使状态空间的分散度的评价基于将构成状态空间的各状态各自的概率分布的分散或标准方差进行加合运算而得到的值进行。
·相同地,在上述第2实施方式中,当前状态下的概率分布的分散度的评价是基于与当前状态对应的信息熵h(s)进行的,也可以不用这种方式,而基于当前状态下的概率分布的分散或标准方差进行。
·在上述各实施方式中,作为定义状态的车辆数据的属性,包括车载设备的操作状况da、daα、车辆的乘客的特性db、dbα、以及车辆的行驶状况dc、dcα。但并不限定于此,定义状态的车辆数据的属性只要是对驾驶员操作车载设备的方式有帮助的要素即可,也可以采用其它要素。
·在上述各实施方式中,作为确定的操作提案,将构成行动空间的各行动中使得当前状态下的最优行动值函数q*(st,at)最大化的行动、即当前状态下最有价值的行动作为操作提案的对象进行输出。也可以不用这种方式,而是例如将当前状态下跳转概率最大的行动作为操作提案的对象进行输出。只要是将预测驾驶员采用可能性最大的行动作为对象而执行确定的操作提案即可。
·在上述各实施方式中,作为试错性的操作提案,将满足“f(s)=τ”的行动作为操作提案的对象进行输出。也可以不用这种方式,而是在通过将某一状态s下采用构成行动空间的各行动的概率以从低到高的顺序排列后进行加合运算而求出累积分布函数f(s)时,将满足“f(s)≧τ”的行动作为操作提案的对象进行输出。另外,也可以在通过将某一状态s下采用构成行动空间的各行动的概率以从高到低的顺序排列后进行加合运算而求出累积分布函数f(s)时,将满足“f(s)≦τ”的行动作为操作提案的对象进行输出。只要是以当前状态下的概率分布的概率密度越高的行动则被选择作为对象的频率越高的趋势执行试错性的操作提案即可。
·在上述各实施方式中,作为增强学习中的回报函数,设定作为对操作提案的响应的为图12所示的方向盘操作开关142a中的第1操作按钮ba1的操作次数。也可以不用这种方式,而是作为增强学习中的回报函数,设定为图12所示的方向盘操作开关中从第1操作按钮ba1的操作次数减去第2操作按钮ba2的操作次数而得到的值。另外,也可以将第1操作按钮ba1的操作次数减去第3操作按钮ba3的操作次数或第4操作按钮ba4的操作次数而得到的值,设定为增强学习中的回报函数。另外,也可以将在驾驶员针对车载设备的操作提案没有进行任何操作时,将该次数作为日志进行记录,并将从第1操作按钮ba1的操作次数中减去该次数后的值,设定为增强学习中的回报函数。另外,也可以基于驾驶员的身体信号等测量驾驶员对车载设备的操作提案感觉到愉快·不愉快的感情的次数,将驾驶员感觉愉快的次数设定为增强学习中的回报函数。另外,也可以将驾驶员感觉愉快的次数减去感觉不愉快的次数而得到的值,设定为增强学习中的回报函数。只要是能够表示车载设备的操作提案相对于驾驶员意图的适合程度的指标,都可以设定为增强学习中的回报函数。
·在上述各实施方式中,作为方向盘操作开关,以具有在对来自智能ecu100的操作提案进行响应时操作的第1操作按钮ba1及第2操作按钮ba2、以及与来自智能ecu100的操作提案无关地操作车载设备时进行操作的第3操作按钮ba3及第4操作按钮ba4的结构作为例子进行了说明。但也可以如图17所示,作为方向盘操作开关的另一个例子,采用仅具有在对来自智能ecu100的操作提案进行响应时操作的第1操作按钮ba1及第2操作按钮ba2的方向盘操作开关142b的结构。另外,也可以如图18所示,作为方向盘操作开关的其它例子,采用不用图12所示的在驾驶员自身手动输入而操作车载设备时进行操作的第3操作按钮ba3,而使用具有在启动管家服务时进行操作的第3操作按钮ba3α的方向盘操作开关142c的结构。并且,上述方向盘操作开关142b、142c的结构,都可以通过方向盘操作开关142b、142c的操作而检测出驾驶员对操作提案的响应,并用作为增强学习中的回报函数。
·在上述各实施方式中,作为增强学习的方法而进行q学习。但也可以不用这种方式,而是作为增强学习的方法而使用例如sarsa法、actor-critic法等其它方法。
- 还没有人留言评论。精彩留言会获得点赞!