一种基于多文件格式自动识别的跨地域关联统计方法与流程
本发明涉及一种在多文件格式存储系统中自动识别文件格式关联统计的技术,特别是涉及一种利用统一sql(structuredquerylanguage,结构化查询语言)入口实现多文件格式自动识别并支持跨地域关联统计的方法,属于大数据检索领域。
背景技术:
近几年来,随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百tb甚至数十至数百pb规模的行业/企业大数据已远远超出了现有传统的计算技术和信息系统的处理能力,因此,寻求有效的大数据处理技术、方法和手段已经成为现实世界的迫切需求。
随着需要处理数据量越来越多,在单一服务器系统管辖下根本无法满足目前的数据存储和数据计算分析的需求,因此产生了分布式文件管理系统和基于分布式文件管理系统的检索引擎。
分布式文件系统英文名成为dfs(distributedfilesystem),即一种允许文件通过网络在多台主机上分享的文件系统,可以让多个机器上的多个用户分享文件和存储空间。它最大的特点是“通透性”,dfs实际上是通过网络来访问文件,在用户和程序看来,就像是访问本地的磁盘一般。目前应用最广泛的分布式文件系统是hadoop分布式文件系统(hdfs),hdfs是运行在通用硬件上的分布式文件系统。hdfs提供了一个高容错性和高吞吐量的海量数据存储解决方案,已经成为在线/离线的海量存储事实标准,多年来在各种应用场景提供了可靠高效的服务。hdfs中的文件格式大致上分为面向行和面向列两类。面向行存储:同一行的数据存储在一起,即连续存储,包括sequencefile,mapfile,avro,datafile等。采用这种方式,如果只需要访问每行的一小部分数据,亦需要将整行读入内存,推迟序列化一定程度上可以缓解这个问题,但是从磁盘读取整行数据的开销却无法避免。面向行的存储适合于整行数据需要同时处理的情况。面向列存储:整个文件被切割为若干列数据,每一列数据一起存储,包括parquet,rcfile,orcfile等。面向列的格式使得读取数据时,可以跳过不需要的列,适合于只处理每行的一小部分字段的情况。在处理大数据检索时为了有效地节省时间和空间,更适合选用parquet文件格式。在数据压缩方面,parquet文件中数据以列的形式存储,所以能将完全不同的值一起存储在内存中,为存储的数据提供了更高的压缩率;在i/o操作方面,parquet文件只需扫描部分列,大大减少了i/o操作;在编码模式方面,列式存储在压缩选项外提供了一种高效方式来存储数据。
hbase是一个构建在hdfs上的分布式列存储系统,是典型的key/value系统。主要用于海量非结构化数据存储,hbase将数据按照表、行和列进行存储。在存储结构方面,hbase支持无模式存储,每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;在数据类型方面,hbase中的数据都是字符串,没有类型区别;在数据一致性方面,每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;在存储空间方面,表中的空列并不占用存储空间,表可以设计的非常稀疏;在系统扩展方面,hbase依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
lucene是一个高效的,基于java的全文检索引擎工具包,它的全文检索技术是信息检索领域广泛使用的基本技术,具有访问索引时间快,多用户访问,跨平台使用的特点。lucene的检索算法属于索引检索,即用空间来换取时间,主要适用于文档集的全文检索,以及海量数据库的模糊检索,同时支持单个和多个词汇的查询,短语查询,通配符,结果分级以及排序功能。在建立索引方面,lucene支持多种分词器对不同的文本进行分词及建立索引;在存储方面,支持多种压缩格式,降低数据的存储成本;在存储方面,lucene具有多种合并索引策略,通过将多个小文件合并成一个大文件,提高检索效率。
综上所述,在大数据存储系统中,针对不同的应用场景通常采用多种存储模式,在不同存储模式中进行统一关联统计的需求也越来越大。在关联统计中统一检索入口和标准,自动识别检索场景以及解决跨地域的技术逐渐成为大数据分析领域的关键问题。
技术实现要素:
本发明的主要目的是提供在多地域多文件格式存储系统下进行跨地域关联统计的技术,统一检索入口,兼容多种数据存储格式,支持多种文件系统,优化检索,提升关联统计效率,有效解决多地域多文件格式下大数据关联统计问题。
本发明采用的技术方案如下:
一种基于多文件格式自动识别的跨地域关联统计方法,其步骤包括:
1)通过统一sql查询入口接收sql查询请求;
2)对sql查询请求进行解析,以识别查询的不同文件格式;
3)全局节点将解析成功后的查询请求发送到对应的分节点;
4)各分节点进行相应的查询操作,并将查询结果回传给全局节点;
5)全局节点对各分节点回传的数据进行关联统计,并输出统计结果。
进一步地,步骤1)所述统一sql查询入口支持多种过滤条件,包括数值类型的判定、逻辑表达式、模糊匹配、正则匹配,并且这些过滤条件能够任意组合。
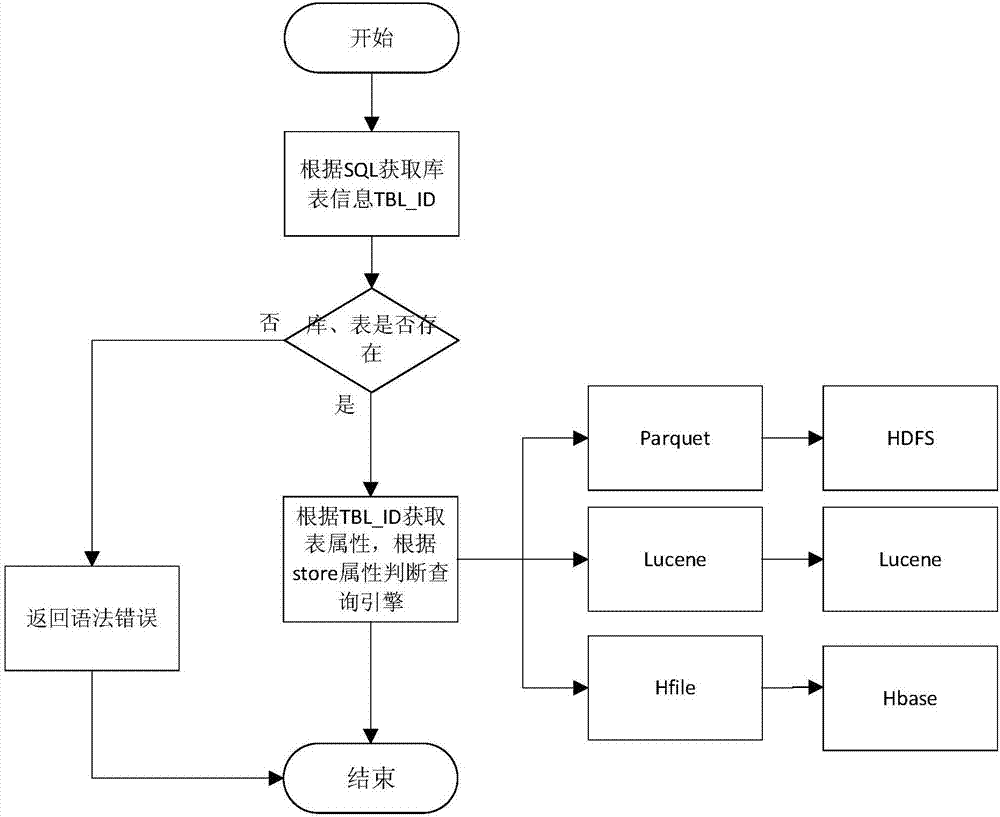
进一步地,步骤2)通过库表信息获取系统内库表唯一标识,通过标识符获取文件存储属性,从而识别不同的文件格式。
进一步地,步骤2)所述不同文件格式包括hdfs中的parquet文件;本地磁盘中lucene索引文件;hbase中hfile文件;其中,parquet文件提供离线统计分析功能,parquet格式支持多层嵌套和多种格式压缩;lucene文件提供在线系统的实时统计功能和海量数据的索引查找,lucene文件本身包含内部索引文件并记录数据在文件中的位置信息,加快检索速度,lucene文件默认采用压缩存储以有效降低存储空间;hfile文件提供精确查询功能,通过key/value存储模式实现实时查询,通过mapreduce进行离线处理或者批处理。
进一步地,步骤2)中若解析失败,则返回语法错误。
进一步地,步骤4)中若各分节点查询成功则将数据返回给全局节点,若查询失败且没有超过重查次数,则进行重查,若超过重查次数,则返回查询失败。
进一步地,步骤4)中若数据传输成功,则结束本次查询,若传输失败且没有超过重传次数,则进行重传,否则返回传输失败。
进一步地,步骤5)中若全局节点在规定时间内接收到所有分节点回传的数据,则进行下一步关联统计,否则返回查询错误。
本发明的创新点和有益效果如下:
1)在sql统一入口方面,将传统标准sql与新型全文检索sql相结合(lucene文件支持全文检索),既兼容sql92标准,又加入全文检索和跨地域功能关联统计功能。保证了语法相对稳定的情况下,提高系统的可靠性。
2)在多文件格式自动识别方面,本发明屏蔽了底层文件格式的差异,使用户或上层应用程序与底层文件系统解耦合,提高了程序和系统的健壮性。
3)在跨地域方面,既保证各数据分中心的相对独立性,又能将数据进行全局统计,提高了数据的实际价值。
附图说明
图1为多文件格式系统架构模型示意图;
图2为场景自动识别模型示意图;
图3为关联统计流程图;
图4-1为跨地域关联统计全局节点查询流程图;
图4-2为跨地域关联统计数据分节点查询流程图。
具体实施方式
下面通过具体实施例和附图,对本发明做进一步说明。
本发明的内容主要包括以下几个方面。
第一,在多文件格式支持上,本发明使用统一的检索引擎实现了针对不同文件格式和检索引擎的统一调度和管理。具体来讲,支持hdfs中的parquet文件;支持本地磁盘中lucene索引文件;支持hbase中hfile文件。离线数据采用hdfs中的parquet文件存储,在线数据采用lucene索引文件存储,同时支持模糊检索,精确检索数据由hbase中的hfile文件存储。其中,parquet文件提供离线统计分析功能,如海量数据的分组、排序等,parquet格式支持多层嵌套,支持多种格式压缩,减少磁盘存储空间,同时提高文件传输速率;lucene文件可提供在线系统的实时统计功能和海量数据的索引查找,lucene文件本身包含内部索引文件并记录数据在文件中的位置信息,加快检索速度,lucene文件默认采用压缩存储,有效降低存储空间;hfile文件可提供精确查询功能,通过key/value存储模式实现实时查询,通过mapreduce进行离线处理或者批处理。因此,可以突破文件格式的限制,应用场景更加广阔。
第二,场景自动识别,本发明提供统一sql查询入口,针对不同查询条件自动判断并优化。本查询系统支持多种过滤条件,如数值类型的判定(相等、不等、范围判定)、逻辑表达式、模糊匹配、正则匹配等,而且可以将不同文件格式中的数据进行关联。在过滤条件中可以任意组合,不必指定条件对应的文件格式,在sql语句解析中,本发明会自动识别各种场景对应的文件格式,例如对离线数据进行每日统计,对在线和离线数据中同一业务对象进行关联分组统计等。这样可以简化sql查询语句,使查询更加灵活。具体地,sql解析组件通过库表信息获取系统内库表唯一标识,通过标识符获取文件存储属性,从而实现了此处所说的场景自动识别。另外,sql还可以通过检索的具体语句来进行优化,在保证返回值的正确的情况下,优先选择更合适的文件格式。比如,统计场景会选择parquet,简单检索会选择lucene,精确查找会选择hfile等。
第三,关联统计,本发明通过关联条件并优化执行流程将相关数据进行高效快速的关联统计,支持多表关联,分组,排序等。其中,关联包括全关联、左关联、右关联。在执行关联统计时,优化查询计划,优先进行条件过滤,避免传输和计算大量无效数据。所述多表关联、分组、排序、全关联、左关联、右关联来自标准sql定义,多表关联指的是sql的join语法、分组是指groupby语法、排序是指orderby语法、全关联是指fulljoin、左关联leftjoin、右关联是rightjoin。
第四,跨地域。目前,在实际应用中单一数据中心已经无法满足需求,更多的系统采用多数据中心模式,即一个全局点(国家中心点),多个数据分节点(省点)模式。为了能够将多个数据中心的数据进行统一关联查询,本发明支持由全局点下发跨地域查询任务,由全局点进行sql解析,并将查询任务下发到各个分节点,将各个数据中心的相关数据拉取到本地,再进行关联统计。在拉取各分中心数据时,采用多种优化方式,包括将sql查询语句中的过滤条件下发到所有数据中心,只传输符合条件的数据,大大降低传输的数据量,加快查询效率。
在基于多文件格式自动识别多跨地域关联统计技术的设计上,本发明将多种sql语句进行统一定制,兼容sql92标准,在查询不同文件格式时,采用统一sql入口,自动识别查询场景,同时支持跨地域关联统计。
图1给出了多文件系统架构模型,包括接口层、解析层、分发层和存储层。其中接口层提供统一sql查询入口;解析层包含sql解析组件,用于解析sql查询请求,自动识别各种场景对应的文件格式;分发层包含数据传输组件,在sql查询请求解析成功后,全局节点通过数据传输组件将相应请求发送到对应的分节点;底层的存储层是多种存储引擎和检索引擎,其中包含多种文件格式。底层存储引擎和检索引擎的数量和规模可根据实际应用做不同调整,本发明为上层应用屏蔽底层的文件格式差异,实现透明查询和透明传输。此处的接口层、解析层、分发层和存储层是一个抽象,在全局点部署接口层、解析层、分发层;在分节点部署解析层、分发层和存储层。虽然有交叉,但是交叉部分在不同的地点的作用是不同的。解析层在全局点是处理全局语句的解析;在分节点则只是处理本地语句的解析。分发层在全局点用于数据的汇集,在分节点则是用于收集本地的数据,并发送至全局点。
图2给出了自动识别模型结构。本发明具有自动识别文件格式功能,因此采用统一sql入口,最大程度上减少系统复杂性。系统中的sql解析组件通过库表信息获取系统内库表唯一标识,通过标识符获取文件存储属性,并进行相应查询。图2中tbl_id表示一个表的唯一标识,store属性表示该表的存储方式。
图3给出了关联统计查询流程图,如图所示,主要包括以下核心步骤:
(1)全局节点在接收所有分节点(即数据分中心,如图3中的数据中心1、2、3)返回的数据后,将数据存入存储引擎;
(2)调用检索引擎进行关联统计;
(3)若查询成功则将数据返回结果,若查询失败且没有超过重查次数,则进行重查,若超过重查次数,则返回查询失败。
图4-1给出了跨区域关联统计全局节点查询流程图,如图所示,全局节点主要包括以下核心步骤:
(1)全局节点在接收sql查询请求后,由sql解析组件进行解析。
(2)若解析成功,则将相应请求发送到对应的分节点,并等待回传数据。若解析失败,则返回语法错误。
(3)若在规定时间内接收到所有分节点回传的数据,则进行下一步关联统计,否则返回查询错误。
(4)在正确接收到所需数据后,根据关联条件,对数据进行关联统计,并返回统计结果。此处的关联统计主要是指通过sql的方式由用户撰写并提交,只要符合sql92的关联统计语法都是支持的。本发明的重点不是对关联统计进行优化,而是关注于使用多种文件格式,并在多种文件格式之间支持关联统计的操作。
下面提供一个关联统计的例子:
用户提交一个sql语句:selectt1.id,count(t1.income)fromtest1t1jointest2t2ont1.id=t2.idwheret1.id>10;
本案例中,支持针对上述语句在多个数据中心的统一执行,并支持将各个分中心的统计结果返回,在全局点统一汇总。
本程序会识别出表test1和test2的存储类型,如果一个是parquet、一个是lucene和parquet都有,则优先选择parquet进行join操作(关联操作);如果一个表的parquet文件损坏或异常,依然可以使用lucene进行join操作(关联操作)。
图4-2给出了跨区域关联统计数据分节点查询流程图,如图所示,数据分节点主要包括以下核心步骤:
(1)在接受全局节点的查询请求后,进行查询操作。
(2)由sql解析组件解析sql语句,可以自动识别文件格式,并进行相应查询。
(3)若查询成功则将数据返回给全局节点,若查询失败且没有超过重查次数,则进行重查,若超过重查次数,则返回查询失败。
(4)若数据传输成功,则结束本次查询,若传输失败且没有超过重传次数,则进行重传,否则返回传输失败。
本发明中重查次数、重传次数可以使用配置文件设定,即在配置文件中预先设定合适的值。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!