一种基于集合卡尔曼滤波的对无资料地区径流量推求方法与流程
本发明涉及水文模拟技术领域,尤其涉及一种基于集合卡尔曼滤波的对无资料地区径流量推求方法。
背景技术:
自然界中有不少区域因雨量或水文站早期建设少、历史径流资料序列短,无法满足预报需求;同时,因人类活动等影响,导致流域产汇流特性发生较大变化,历史资料无法反映当前来水特性,历史资料不可用。因此对无资料地区的研究也是亟待解决的。
目前,对无资料地区径流预报常用的方法为区域化方法,即通过某种途径,利用有资料流域的模型参数推求无资料流域的模型参数,从而对无资料流域进行预报。常用的区域化方法有属性相似法、空间相近法和回归法。其中,属性相似法指找出与研究流域属性如地形、土壤和气候等相似的流域,并把其参数作为研究流域的参数,属性相似法研究根据为同一区域的物理和气候属性相对一致,因此相邻流域的水文行为相似。空间相近法指找出与研究流域(如无资料流域)距离上相近的一个或者多个有资料流域,并把有资料流域参数作为研究流域的参数。回归法指根据有资料流域的模型参数和流域属性,建立二者之间的多元回归方程,从而利用无资料流域的流域属性推求其模型参数。
但是,现有技术存在如下缺点:
一、未考虑不同参数的区别:目前,无资料地区参数确定通常采用移用或回归分析的方法。现有,确定移用时通常先找到参照流域,而后所有参数统一移用或回归分析。可是实际上,水文模型中每个参数代表的物理意义不同,因每个流域都有其独特性,很难找到与模型中所有参数的相关特征均相似的流域,虽现今已有研究仅依据一种或几种相关特征寻找参照流域,而所有参数统一移用或采用同一些流域,但这种方式很明显无法反映参数的独特性。
二、相似流域的选取缺乏全面性和客观性:现有研究通常选用一种或几种地形、地貌特征参数的综合指数如地形指数作为属性判别寻找相似流域,而后进行参数的移用或分析。因为不同水文模型其参数的物理意义不同,仅仅依据一种或几种流域特征参数进行判别是不够全面和客观的,很难反映真正的流域相似,并且采用所有流域特征进行分析存在信息量大、分类复杂以及无法判断的问题。
三、主观判别和效率低:现有技术均采用人工判别处理的方式,解决无资料地区的洪水预报问题,此技术难以大量推广,并且其中包含人为的主观性和效率低下的问题,寻找其他有效简便的方法是目前急需解决的。
技术实现要素:
本发明的目的在于提供一种基于集合卡尔曼滤波的对无资料地区径流量推求方法,从而解决现有技术中存在的前述问题。
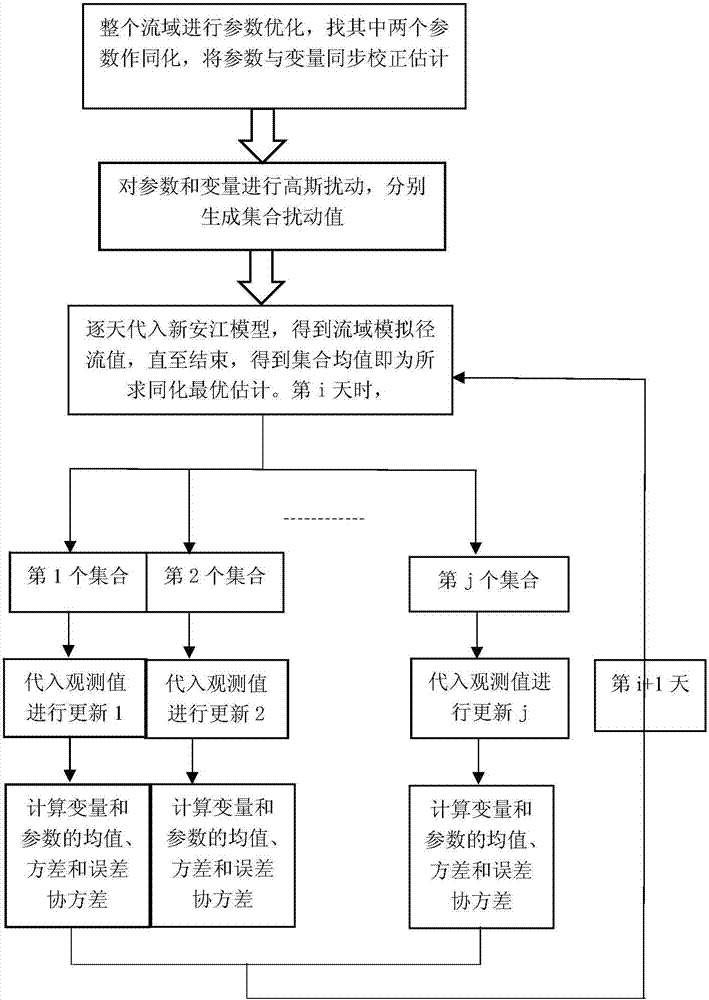
为了实现上述目的,本发明所述基于集合卡尔曼滤波的对无资料地区径流量推求方法,所述方法包括:
s1,计算全流域的优化参数值
全流域中存在至少一个无水文资料子流域和至少一个有水文资料子流域,所述无水文资料的子流域的上游流域和下游流域均为全流域中子流域;
对全流域进行参数优化,得到参数最优值,选取任意两个参数的最优值进行数据同化处理;两个参数分别为参数β和参数γ;
s2,计算子流域a的出口的估计流量及其分布规律
设定无水文资料子流域为子流域a,子流域a的出口点为c点,子流域a的下游流域为有水文资料子流域b,子流域b中的出口点为水文站d;
子流域b出口对应的径流量是已知的,记为qd;
然后,通过公式(1)计算子流域a的出口点c点的初始估计流量qc′;
qc′=qd×(sa/sa+b)(1);
其中,sa为子流域a的面积,sa+b为子流域a和子流域b的面积之和;
s3,计算变量和参数的集合扰动值
将初始估计流量qc′的均值和方差作为c点径流量qc初始设定的符合高斯分布的均值与方差;以参数β和参数γ的最优值为参考,对c点径流量qc、参数β和参数γ分别进行高斯扰动,分别得到变量、参数β和参数γ的高斯扰动值集合;
s4,计算下游有水文资料水文站d的径流量预报集合
在实测降水和蒸发数据的基础上,逐天运行水文模型,将s3中得到的c点径流量qc、参数β和参数γ的高斯扰动集合值逐一代入水文模型,并得到每个时间步长上的水文站d的径流量预报集合,每个时间步长上的水文站d的径流量预报集合数量大于等于1;
s5,对水文站d实测径流值进行高斯扰动,并将得到的高斯扰动集合作为观测数据集合;
s6,融入观测数据集合
在已知观测算子的条件下,计算卡尔曼增益,将每个所述水文站d的径流量预报集合融入观测数据集合进行更新;
s7,重复进行s4至s6,直到水文模型计算结束,最终得到c点径流量qc的最优估计值,所述最优估计值即为上游无资料子流域a出口点c点的径流量值。
优选地,s1中,对全流域进行参数优化采用的优化算法为所述粒子群算法。
优选地,所述水文模型为新安江模型。
优选地,步骤s3中,所述高斯扰动,按照公式(2)实现:
ea=ea+ε(2);
其中,ea表示增加高斯扰动后的模型状态变量或者观测值;ea表示初始模型状态变量或者观测值;ε为符合高斯分布的扰动值,即ε~n(0,1)。
优选地,步骤s6中,计算卡尔曼增益,具体按照下述计算:
kt=ptht(hptht+rt)-1(9);
其中,m表示集合样本的总数;
优选地,步骤s6中,对每一个集合进行更新,采用公式(10)进行更新:
其中,
本发明的有益效果是:
本发明利用集合卡尔曼滤波推求无资料地区径流量的研究,为无资料地区的研究展开了新思路和新方法。
集合卡尔曼滤波的基本思想即是利用montecarlo方法设计预测状态的一个集合,该集合的平均可作为最佳估计,该集合的样本协方差即作为预测误差协方差的近似,该集合通过不断向前滤波,每个样本分别更新分析变量,而对变量的最佳估计即为各更新分析变量的样本平均。本发明提出的基于集合卡尔曼滤波的对无资料地区径流量推求方法,基于集合统计的思想,无须对非线性系统进行线性化,避免了jacobian矩阵的繁冗计算,更简化了滤波同化过程。
本发明利用一种扩展模型状态变量方法,即将模型参数和变量置于联合的向量中,将上游无资料地区径流量看作变量,利用下游已知流域的参数并将其径流量作为观测值,同时实现变量与参数的同化,其中变量同化的均值即为无资料地区的径流量。基于集合统计的思想,无须对非线性系统进行线性化,避免了jacobian矩阵的繁冗计算,并且同化过程中同时考虑输入降雨误差、模型误差以及观测误差,较好的提高了同化精度。同时也避免了常规方法对无资料地区求径流量的缺陷,如相似流域选取缺乏全面、客观性,现有技术未考虑不同参数的区别,主观判别、效率低等,该方法将会对无资料地区预报完善洪水预报理论、提高预报精度、水库大坝建设和调度设计等具有理论价值和指导意义。
附图说明
图1是全流域子流域分布及水文站位置简图;
图2是基于集合卡尔曼滤波的对无资料地区径流量推求方法的流程示意图;
图3是参数优化后出口点水文站d的径流模拟值与真实径流值对比示意图;
图4是基于集合卡尔曼滤波下的同化估计上游无资料地区的径流量与真实径流量对比示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
实施例
本实施例所述基于集合卡尔曼滤波的对无资料地区径流量推求方法,所述方法包括:
s1,计算全流域的优化参数值
全流域中存在至少一个无水文资料子流域和一个有水文资料子流域,所述无水文资料的子流域的上游流域和下游流域均为全流域中子流域;
对全流域进行参数优化,得到参数最优值,选取任意两个参数的最优值进行数据同化处理;两个参数分别为参数β和参数γ;
s2,计算子流域a的出口的估计流量及其分布规律,所述分布规律包括估计流量的均值和方差
设定无水文资料子流域为子流域a,子流域a的出口为c,子流域a的下游流域为有水文资料子流域b,子流域b中的水文站为水文站d;
子流域b出口对应的径流量是已知的,记为qd;
然后,通过公式(1)计算子流域a的出口的初始估计流量qc′;
qc′=qd×(sa/sa+b)(1);
其中,sa为子流域a的面积,sa+b为子流域a和子流域b的面积之和;
s3,计算变量和参数的集合扰动值
将初始估计流量qc′的均值和方差作为c点径流量qc初始设定的符合高斯分布的均值与方差;以参数β和参数γ的最优值为参考,对c点径流量qc、参数β和参数γ分别进行高斯扰动,分别得到变量、参数β和参数γ的高斯扰动值集合;
s4,计算下游有水文资料水文站d的径流量预报集合
在实测降水和蒸发数据的基础上,逐天运行水文模型,将s3中得到的c点径流量qc、参数β和参数γ的高斯扰动值集合中的值逐一代入水文模型,并得到每个时间步长上的水文站d的径流量预报集合,每个时间步长上的水文站d的径流量预报集合数量大于等于1;
s5,对水文站d的实测径流值进行高斯扰动,并将得到高斯扰动集合作为观测数据集合;
s6,融入观测数据集合
在已知观测算子的条件下,计算卡尔曼增益,将每个所述水文站d的径流量预报集合融入观测数据集合进行更新;
s7,重复进行s4至s6,直到水文模型计算结束,最终得到c点径流量qc的最优估计值即为上游无资料子流域a出口点c点的径流量值。
更详细的解释说明为:
(一)s1中,对全流域进行参数优化采用的优化算法为所述粒子群算法。通过迭代的形式求得最优解。此次实施例选取种群规模为200,种群进化迭代次数为3000。
(二)所述水文模型为新安江模型。新安江模型适用性较广。本实施例中的两个参数为imp(流域不透水面积)、kg(地下水出流系数)。
在本实施例中利用一种扩展模型状态变量方法,即将模型参数和变量置于联合的向量中,此次我们的实施例选取的流域,上游a无资料地区为雅砻江流域的甘孜水文站(假设其径流量未知,最后将真实径流值与同化估计值作对比,来验证同化结果的好坏),下游b地区为雅江。将上游a无资料地区甘孜站的径流量看作变量,记作q,选取下游已知流域的两个参数,则状态变量的形式为x=(q,q,imp,kg),从实际理论中得知甘孜站的径流量q加上b流域的产流记为rb,将总产流(q+rb)代入新安江模型的汇流模块得到下游雅江站的径流量q。同时,初始给定状态变量符合高斯分布的均值与方差。其中imp~n(0.3,0.22),kg~n(0.4,0.22)。q的均值和方差可根据上下游面积比例法求得,因为下游b雅江的径流量d是已知的,则得到上游a无资料地区甘孜站的初始估计流量q为d×(a/(a+b)),并由此推求q的分布规律(均值、方差),即得q~n(390,102)。本次发明中还考虑了模型误差以及观测误差,并用缩放因子的形式展现在程序中,更简便实用,模型及观测误差同样满足高斯分布,即服从n(0,0.012),n(0,0.12)来表示模型和观测的不确定性。
步骤s2,实施例选取了三年日降雨蒸发数据,共计1095天,第一年作为预热期,第二年与第三年进行同化。逐天运行新安江模型,利用步骤s1得到的参数最优值,代入新安江模型中,得到模拟径流值,并将实际测量的径流量作为观测值,为之后进行更新同化模拟径流量数据。其中图3为参数优化后全流域的径流模拟值与真实径流值对比图。
(三)步骤s3中,所述高斯扰动,按照公式(2)实现:
ea=ea+ε(2);
其中,ea表示增加高斯扰动后的模型状态变量或者观测值;ea表示初始模型状态变量或者观测值;ε为符合高斯分布的扰动值,即ε~n(0,1)。
在步骤s3中,根据初始设定的符合高斯分布的均值与方差,得到变量及两参数的集合高斯扰动值,并对高斯扰动值进行范围设定,保证同化的精确。
(四)步骤s4中,逐天运行新安江模型,每运行一天即产生100个随机集合,将步骤s3得到的变量和参数的集合扰动值以及实测降水与蒸发数据代入水文模型中,计算得到下游已知站点的径流量预报集合。考虑模型误差,使用者还可对径流量预报集合进行高斯扰动,得到径流量预报的扰动集合。
(五)步骤s6中,考虑符合高斯分布的观测误差,又已知观测算子,此次观测算子h=(0,1,0,0)t,计算卡尔曼增益,将上一步骤(5)得到的径流量扰动集合融入观测值,对每一个集合进行更新,得到c点径流量qc的最优估计值即为上游无资料子流域a出口点即甘孜站的径流量值。
具体按照下述计算:
kt=ptht(hptht+rt)-1(9);
其中,m表示集合样本的总数;
同时,步骤s6中,对每一个集合进行更新,采用公式(10)进行更新:
其中,
本实施例中的时间步长为2年,共730天,每计算一天都会算出100个集合数的径流量,更新时对100个集合分别进行更新,得到的均值就为该天的最优估计值。同样依次类推,下一天同样计算出100个集合。同化更新完一天的数据后,再重复运行下一天,产生100个预报集合,再进行更新求得变量最优估计值,以此类推,直到730天结束。在同化过程中,每个集合成员均为独立进行的。
经过整个同化更新过程后,可以得到图4。其中图4为基于集合卡尔曼滤波下的同化估计上游无资料地区的径流量与真实径流量对比图。
由图4基于集合卡尔曼滤波下的求解的同化估计上游无资料地区的径流量与真实径流量对比图,可以看出同化估计后的径流值基本与真实值吻合一致,其两者的相对误差均小于1,验证了同化估计的可行性。
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
本发明所述基于集合卡尔曼滤波的对无资料地区径流量推求方法,利用一种扩展模型状态变量方法,即将模型参数和变量置于联合的向量中,将上游无资料地区径流量看作变量,利用下游已知流域的参数并将其径流量作为观测值,同时实现变量与参数的同化,其中变量同化的均值即为无资料地区的径流量。基于集合统计的思想,无须对非线性系统进行线性化,避免了jacobian矩阵的繁冗计算,并且同化过程中同时考虑输入降雨误差、模型误差以及观测误差,较好的提高了同化精度。同时也避免了常规方法对无资料地区求径流量的缺陷,如相似流域选取缺乏全面、客观性,现有技术未考虑不同参数的区别,主观判别、效率低等。
本发明所述方法将会对无资料地区预报完善洪水预报理论、提高预报精度、水库大坝建设和调度设计等具有理论价值和指导意义。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!