一种概率主题计算与匹配的舆情监测方法及系统与流程
本发明涉及一种概率主题计算与匹配的舆情监测方法及系统。
背景技术:
互联网成为继报纸、广播、电视之后的第四媒体,每天会产生大量的类似论坛、博客、微博、微信等媒体数据。网络舆情是指在互联网上流行的对社会问题不同看法的网络舆论,是社会舆论的一种表现形式,是通过互联网传播的公众对现实生活中某些热点、焦点问题所持的有较强影响力、倾向性的言论和观点。随着社交媒体的爆炸性增长,自动化舆情分析与监控可为多个领域或行业提供决策支持。然而,现有技术主要通过文本匹配实现舆情监测,缺乏语义支持,匹配后监测结果的排序并不一定完全准确。
大数据环境下,计算机辅助内容数据自动化分析技术是舆情监测的关键。现有技术主要存在三类内容分析方法:
(1)基于情感词典的内容分析:该方法将搜索关键词与预定义的标准词典进行匹配。然而,由于每个单词组合可以仅具有用于所有文本的一个固定的含义,所以这些手工创建的单词索引通常是不充分且有限的。除此之外,内容匹配不能考虑到语义相似的同义词;
(2)基于头词和修饰符共现的统计方法:不同于能够理解语言细微差别的程序员,该方法从大量内容文本中统计特定关键词隐藏的真实含义。该方法的缺点是不能发现未知知识;
(3)基于分类的内容分析:该方法使用神经网络、支持向量机、朴素贝叶斯、最大熵等建模对文本进行分类。然而,分类方法也不能发现隐藏的主题。
技术实现要素:
本发明的目的就是对互联网媒体内容进行监测,及时发现网络舆情,提供一种概率主题计算与匹配的舆情监测方法及系统,本系统具有实时性,通过数据采集、主题计算与主题匹配实现舆情监测。
为了实现上述目的,本发明采用如下技术方案:
一种概率主题计算与匹配的舆情监测方法,包括:
步骤(1):数据采集:
步骤(101):数据采集解析:利用爬虫集群从数据源中采集页面html,然后爬虫集群依据规则库对采集到的页面html进行解析得到若干条媒体数据;解析出来的每一条媒体数据均被称作一篇文档,每篇文档包括标题、时间与内容;
步骤(102):存储推送:所述爬虫集群采用异步方式将解析得到的文档存储在全文检索系统,采用同步方法将解析得到的文档推送至步骤(3)进行主题匹配;
步骤(2):主题计算:
步骤(201):中文分词:从全文检索系统中读取文档,将每个文档的标题与内容合并,利用条件随机场分词算法对合并后的内容进行分词,分词后去掉停用词;
步骤(202):主题估计:采用gibbs抽样对分词后的内容估计出主题库与历史文档主题集;
步骤(3):主题匹配:将数据采集实时推送的文档推断出实际文档主题集,并将实际文档主题集与用户输入的舆情监测关键词进行匹配,得到有序文档集。
所述步骤(3)包括如下步骤:
步骤(301):文档分发:按轮询模式将数据采集实时推送的文档并行分发下去;
步骤(302):中文分词:将分发得到的每个文档的标题与对应内容合并后,用条件随机场crf算法进行分词,然后去掉停用词;
步骤(303):主题推断:采用gibbs抽样对分词后的内容和主题估计得到的主题库推断出实时文档主题集;
步骤(304):关键词匹配:将实时文档主题集与用户输入的舆情监测关键词进行匹配;
步骤(305):排序:按照文档评分从高到低对匹配后的文档集进行排序形成有序文档集。
一种概率主题计算与匹配的舆情监测方法,还包括:
步骤(4):舆情监测:根据步骤(3)得到的有序文档集中的排序,得出舆情的监控情况,排序越靠前的,越是当前舆情关注的热点。
所述数据源包括:论坛、博客、微博或微信。
所述爬虫集群包括:爬虫1、...、爬虫n。
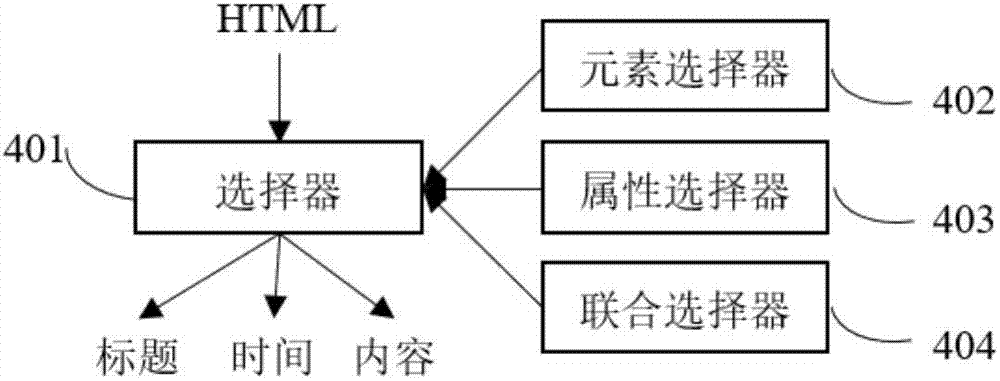
所述规则库包括一组选择器。
所述爬虫集群使用选择器从采集到的页面html解析出包含标题、时间和内容属性的文档。所述选择器包括三种,分别是元素选择器、属性选择器、联合选择器。
所述元素选择器通过html标签名称、html标签id或html标签类名选择相应的元素;
所述属性选择器通过html标签属性值、html标签属性值模糊匹配或html标签属性值正则匹配选择相应的元素;
所述联合选择器通过元素id、元素类名、元素属性、相同祖先元素的子元素或相同父母元素的子元素等选择相应的元素。
主题计算中的主题估计,将主题估计抽象为map任务与reduce任务进行计算,步骤为:
map任务,求解隐变量:为每个关键词随机生成一个主题,为每个文档计算伪频数,计算主题的后验概率;
reduce任务,求解模型参数:将每个主题关键词的伪频数叠加后标准化,计算出每个主题的关键词分布与每个文档的主题分布;
主题存储:由每个主题的关键词分布归纳出后验概率最大的前m个主题,形成主题库。每个文档的主题分布中选择概率最大的前n个,形成文档主题集。
所述文档评分为文档相关度和文档助推值的乘积。
所述文档相关度为舆情监测关键词与文档主题的近似度,先计算舆情监测关键词与实际文档主题中的每个关键词的近似度,然后计算每个近似度与域助推值乘积,然后对所有的乘积进行求和。所述域助推值反映了文档中每个主题的重要程度,其值为该文档主题的后验概率。
所述文档助推值为文档重复次数、情感度、pagerank三者的乘积;
所述文档重复次数为该文档在采集数据出现的重复次数,重复次数越高说明该文档越热门;
所述情感度为该文档的情感评分,情感评分采用递归深度语义组合模型计算,情感评分越高说明该文档越积极,情感评分越低说明该文档越消极;情感评分五级制,-2分表示非常消极、-1表示消极、0表示中性、1表示积极、2表示积极;
所述pagerank反映了该文档的原始网页的链接引用情况,pagerank越高说明该文档的原始网页被引用的次数越高,即该文档越热门。
一种概率主题计算与匹配的舆情监测系统,包括:数据采集模块、主题计算模块和主题匹配模块;
所述数据采集模块,包括:
数据采集解析单元:利用爬虫集群从数据源中采集页面html,然后爬虫集群依据规则库对采集到的页面html进行解析得到若干条媒体数据;解析出来的每一条媒体数据均被称作一篇文档,每篇文档包括标题、时间与内容;
存储推送单元:所述爬虫集群采用异步方式将解析得到的文档存储在全文检索系统,采用同步方法将解析得到的文档推送至主题匹配模块进行主题匹配;
所述主题计算模块,包括:
中文分词单元:从全文检索系统中读取文档,将每个文档的标题与内容合并,利用条件随机场分词算法对合并后的内容进行分词,分词后去掉停用词;
主题估计单元:采用gibbs抽样对分词后的内容估计出主题库与历史文档主题集;
所述主题匹配模块:将数据采集实时推送的文档推断出实际文档主题集,并将实际文档主题集与用户输入的舆情监测关键词进行匹配,得到有序文档集。
所述主题匹配模块包括:
文档分发单元:按轮询模式将数据采集实时推送的文档并行分发下去;
中文分词单元:将分发得到的每个文档的标题与对应内容合并后,用条件随机场crf算法进行分词,然后去掉停用词;
主题推断单元:采用gibbs抽样对分词后的内容和主题估计得到的主题库推断出实时文档主题集;
关键词匹配单元:将实时文档主题集与用户输入的舆情监测关键词进行匹配;
排序单元:按照文档评分从高到低对匹配后的文档集进行排序形成有序文档集。
一种概率主题计算与匹配的舆情监测系统,还包括:
舆情监测模块:根据主题匹配模块得到的有序文档集中的排序,得出舆情的监控情况,排序越靠前的,越是当前舆情关注的热点。
关于专业术语的解释:
爬虫,也称作网页蜘蛛,是一种按照一定的规则自动地获取网页内容的程序或者脚本。
gibbs抽样,吉布斯抽样,已知样本中一个属性在其它所有属性下的条件概率,然后利用这个条件概率来分布产生各个属性的样本值。
流处理是一种实时处理,输入和输出均为数据流。基于流处理的数据缓存即时一致网络拓扑包含多种数据处理,每种数据处理并发运行。
选择器,也称作html选择器,是一种模式,用于从页面html中选择相应的元素。
map任务,mapreduce编程模型中的映射任务,用来把一组键值对映射成一组新的键值对。
reduce任务,mapreduce编程模型中的化简任务,将上述键值对按键进行合并。
条件随机场(conditionalrandomfields,简称crf,或crfs),是一种判别式概率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。
本发明的有益效果:
1、易扩展:文档爬取的规则库基于多种选择器,易扩展;
2、主题估计批处理:主题计算中的主题估计通过调度批量任务来进行映射、化简,实现主题估计批处理;
3、主题匹配具有高实时性:本发明提供的主题匹配基于流处理的网络拓扑实现中文分词、主题推断、主题匹配过程,数据处理不存储中间结果,数据处理具有即时性。
附图说明
图1概率主题计算与匹配的舆情监测系统结构图;
图2基于选择器的文档爬取流程;
图3主题估计流程图。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
如图1-3所示,一种概率主题计算与匹配的舆情监测系统,包括:数据采集、主题计算、主题匹配。
所述数据采集包括数据源、爬虫集群、全文检索系统、规则库。所述数据采集主要是从数据源的页面html中解析出媒体数据。所述数据源可能是论坛、博客、微博、微信等。所述爬虫集群由爬虫1、...、爬虫n等一组爬虫组成。爬虫集群中的爬虫1、...、爬虫n实时采集数据源中媒体数据,采集的一条媒体数据称作一篇文档,包含标题、时间与内容等属性。所述爬虫集群采用异步方式将采集到的文档存储在全文检索系统,采用同步方法将采集到的文档推送至主题匹配。爬虫集群中的爬虫1、...、爬虫n按照规则库解析采集到的页面html,所述规则库由一组选择器构成。
所述主题计算包括中文分词、主题估计、文档主题集、主题库。所述主题计算读取全文检索系统中的文档,计算出所有主题构成主题库,计算出每个文档的主题即文档主题集。所述中文分词将每个文档的标题与内容合并后进行分词,分词算法采用条件随机场(crf),然后去掉常用停用词。所述主题估计采用gibbs抽样对分词后的内容估计出主题库与文档主题集。
所述主题匹配,基于流处理网络进行数据处理,包括文档分发、中文分词、主题推断、主题匹配、有序文档集。所述主题匹配将数据采集实时推送的文档推断出文档主题集,并将该文档主题集与舆情监测关键词进行匹配,得到有序文档集。所述文档分发按轮询模式将数据采集实时推送的文档分发到不同的中文分词。所述中文分词将每个文档的标题与内容合并后进行分词,分词算法采用条件随机场(crf),然后去掉常用停用词。所述主题推断采用gibbs抽样对分词后的内容和主题计算的主题库推断出文档主题集。所述关键词匹配将文档主题集与舆情监测关键词进行匹配,得出匹配的有序文档集合。
所述爬虫集群使用选择器从采集到的页面html解析出包含标题、时间和内容属性的文档。所述选择器有三种,分别是元素选择器、属性选择器、联合选择器。
所述元素选择器通过html标签名称、html标签id、html标签类名等选择相应的元素;
所述属性选择器通过html标签属性值、html标签属性值模糊匹配、html标签属性值正则匹配等选择相应的元素;
所述联合选择器通过元素id、元素类名、元素属性、相同祖先元素的子元素、相同父母元素的子元素等选择相应的元素。
主题计算中的主题估计,将主题估计抽象为map任务与reduce任务进行计算,步骤为:
map任务,求解隐变量:为每个关键词随机生成一个主题,为每个文档计算伪频数,计算主题的后验概率;
reduce任务,求解模型参数:将每个主题关键词的伪频数叠加后标准化,计算出每个主题的关键词分布与每个文档的主题分布;
主题存储:由每个主题的关键词分布归纳出概率最大的前m个主题,形成主题库。每个文档的主题分布中选择概率最大的前n个,形成文档主题集。
主题匹配按照文档评分对匹配后的文档集进行排序形成有序文档集。所述文档评分为文档相关度和文档助推值的乘积。所述文档相关度为舆情监测关键词与文档主题的近似度,即舆情监测关键词与文档主题中的每个关键词的近似度与域助推值乘积的求和。所述域助推值反映了文档中每个主题的重要程度,其值为该文档主题的后验概率。所述文档助推值为文档重复次数、情感度、pagerank三者的乘积。所述文档重复次数为该文档在采集数据出现的重复次数,重复次数越高说明该文档越热门。所述情感度为该文档的情感评分,情感评分采用递归深度语义组合模型计算,情感评分越高说明该文档越积极,情感评分越低说明该文档越消极。情感评分五级制,-2分表示非常消极、-1表示消极、0表示中性、1表示积极、2表示积极。所述pagerank反映了该文档的原始网页的链接引用情况,pagerank越高说明该文档的原始网页被引用的次数越高,即该文档越热门。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!