一种外存设备的非对称读写方法及NVM外存设备与流程
本发明属于存储技术领域,具体涉及一种外存设备的非对称读写方法及新型pcie口nvm存储设备。主要用于避免写放大问题,减少pcie口nvm存储设备的写数据量,提高pcie口nvm存储设备的使用寿命和i/o性能。
背景技术:
nvm存储设备是解决计算机系统存储墙问题的重要技术手段。dimm和pcie口nvm存储设备是目前主要的两类nvm存储设备,相比dimm口nvm存储设备,pcie口nvm存储设备具有较大的局限性,为了获得较高的传输效率pcie接口以支持块访问方式为主,虽然可以改变每次传输的大小,但在效率和灵活性等方面远低于dimm接口。有研究表明,访问pcie口nvm存储设备时存储系统软件开销也占存储系统访问延迟的63%以上,因此提高相关系统软件的效率是一个关键。当前通过pcie接口接入的存储设备一般均作为块设备管理,在管理和读写时均使用块粒度,不能利用nvm存储设备支持字节粒度读写的优势;而使用块粒度的写方式会带来写放大问题,这会严重降低pcie口nvm存储设备的使用寿命;同时由于增加了实际写入nvm存储设备的数据量,从而降低了pcie口nvm存储设备的i/o性能。而基于局部性原理,通过预读的方法能有效提高存储设备的读性能,同时读操作也不会影响nvm存储设备的使用寿命,因此选取较大粒度的读方式同样是提高pcie口nvm存储设备读性能的有效手段。因此有必要改变管理和访问pcie口nvm存储设备的方式,区分不同访问的特性,同时获得较高的读写性能。
技术实现要素:
本发明的目的在于提供一种外存设备的非对称读写方法及新型nvm存储设备,以减少pcie口nvm存储设备的写数据量,提高pcie口nvm存储设备的使用寿命和i/o性能。
本发明出于降低pcie口nvm存储设备的写数据量、提高pcie口nvm存储设备的使用寿命和i/o性能的考虑,本设计分离读写操作,再通过动态粒度写方法完成写操作,并使用多粒度内外存映射方法完成内外存的多粒度映射。
一种外存设备的非对称读写方法,其特征在于通过分离读写操作并使用非对称读写方法来工作;所述外存设备的非对称读写方法包括分离式的读写方法、动态粒度的写方法和多粒度的内外存映射方法;具体包括以下步骤:首先分离读写操作,再通过动态粒度写方法完成写操作,并使用多粒度内外存映射方法完成内外存的多粒度映射。
分离读写操作能针对pcie口nvm存储设备的特性,在保持以数据块为单位读操作的同时,改变写操作的管理方式,从而使用读写操作不同的特性,提高外存设备的i/o性能。
所述分离式的读写方法具体包括下列步骤:
步骤1,接收文件系统访问外存设备的请求,分析操作类型,为读操作转到步骤2,为写操作转到步骤3;
步骤2,外存设备使用基于数据块的读方法完成读操作,并将读出的数据反馈给文件系统;
步骤3,外存设备使用动态粒度的写方法完成写操作,并将结果反馈给文件系统。
动态粒度的写方法,以需要写入数据块的实际大小为依据传输和写入数据,避免写放大的问题,解决以数据块为单位执行写操作时存在额外传输和写入pcie口nvm存储设备数据的问题,提高写操作的执行效率,延长pcie口nvm存储设备的寿命。
所述的动态粒度的写方法包括下列步骤:
步骤1,分析文件系统发送的写操作,获取写数据块需写入的起始地址write_pos和长度write_len,并比较写数据块与系统数据块的大小,若写数据块小与系统数据块则转到步骤2,否则转到步骤3;
步骤2,根据write_len设置传输给外存设备的数据量,由写入数据、write_pos和write_len构建写入数据包传输给外存设备,并由外存设备根据write_pos和write_len将需要写入数据包写入相应位置,并转到步骤8;
步骤3,按照最大为系统数据块大小将写入数据分成若干个数据包,以实际大小构建最后一个数据包,并将第一个数据包作为当前需写入数据包,转到步骤4;
步骤4,若当前需写入数据包的大小等于系统数据块,则转到步骤5,否则转到步骤6;
步骤5,将write_pos的值设置为-1,采用以数据块为单位写方法,并由外存设备将数据包作为一个数据块写入设备,转到步骤7;
步骤6,从当前需写入数据包中获取write_pos和write_len的信息,设置传输给外存设备的数据量,并发送写入数据包、write_pos和write_len,最后外存设备根据write_pos和write_len将需写入数据包写入相应位置,转到步骤8;
步骤7,判断是否还有下一个未完成的写入数据包,如有则转到步骤4,否则转到步骤8;
步骤8,结束写操作,并向文件系统反馈写入成功信息。
多粒度的内外存映射方法,能不受数据块分割的限制,灵活地将写入数据对应到映射项中,在每个映射项中保存实际需要写入到外存数据的起始地址和长度,避免了在内外存映射时的写放大问题,保证了文件系统能获得实际需要写入pcie口nvm存储设备的数据起始地址和长度,使得动态粒度写算法能避免传输和写入时的数据,为提高pcie口nvm存储设备的使用寿命和i/o性能提供了支撑。
所述的多粒度的内外存映射方法包括下列步骤:
步骤1,在内外存映射表的每个映射项中增加dirty_pos和dirty_len,保存内外存之间多粒度的映射信息,其中dirty_pos表示在该数据块中需要更新到外存数据区的起始地址,dirty_len表示该数据块中需要更新到外存数据区的长度,dirty_pos的值为-1表示该数据块不采用多粒度映射方法,s(s∈n)和l(l∈n)分别表示要写入数据起始逻辑地址与长度,转到步骤2;
步骤2,依据s查找内外存映射表中所对应的映射项,如s与该映射项的起始地址相同且l的值与数据块大小相同,则将该映射项的dirty_pos设置为-1,否则将s对应的物理地址保存到dirty_pos中,转到步骤3;
步骤3,比较l的值是否超出了该映射项对应逻辑块的长度,如未超出,则使用l设置dirty_len的值,并将l的值清零,转到步骤4;否则依据数据块大小和dirty_pos计算出dirty_len的值,并更新s和l,转到步骤4;
步骤4,如果l的值不为0转到步骤2,否则结束整个操作。
新型nvm外存设备,包括读写分离模块、动态粒度的写模块、多粒度的内外存映射模块和具有pcie口的nvm存储设备,其特征在于:使用读写分离模块,分离文件系统对pcie口nvm存储设备的读写操作;使用动态粒度的写模块,获取写数据块的实际大小,动态调整pcie口的传输粒度,仅写入实际需要写入的数据,避免写放大操作;使用多粒度的内外存映射模块,不受数据块分割的限制,灵活地将写入数据对应到映射项中,避免在内外存映射时的写放大问题;使用具有pcie口的nvm存储设备,完成所接收到的文件系统读写操作。
本发明具有有益效果。本发明针对文件系统读写操作的不同特性、以及pcie口nvm存储设备的特点,通过避免写放大,减少完成写操作时实际写入pcie口nvm存储设备的数据量,提高pcie口nvm存储设备的i/o性能、延迟使用寿命。
附图说明
图1是本发明整体结构图;
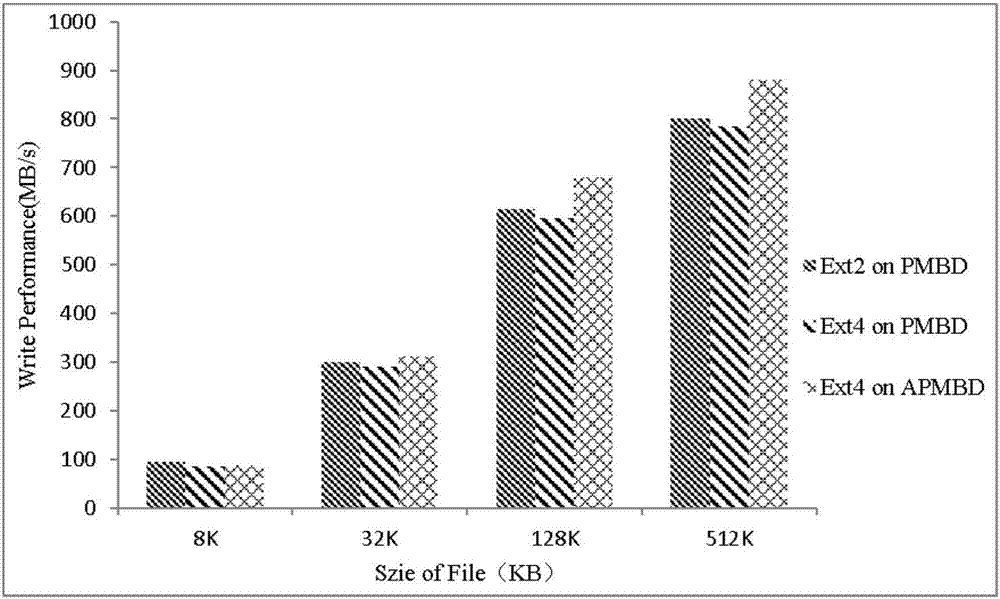
图2是访问不同大小文件时fio顺序写性能的测试结果;
图3是访问不同大小文件时fio顺序读性能的测试结果;
图4是设置不同系统数据块大小时fio顺序写性能的测试结果;
图5是filebench测试的i/o性能结果;
图6是写入数据量小于系统数据块大小时,使用的动态粒度的写方法示意图;
图7是写入数据量大于系统数据块大小时,使用的动态粒度的写方法示意图;
图8是使用多粒度的内外存映射方法,获得写操作计算映射项dirty_pos和dirty_len的示意图;
图9是读操作的示意图。
具体实施方式
下面结合附图和具体实施例,对本发明的技术方案做进一步详细说明。
实施例1
如图1所示,该新型nvm外存设备包括读写分离模块、动态粒度的写模块、多粒度的内外存映射模块和具有pcie口的nvm存储设备。各功能模块的说明如表1所示。
表1新型nvm外存设备中各功能模块
实施例2
为了实现新型nvm外存设备,由于当前没有实用的pcie口nvm存储设备,我们使用pmbd进行模拟,采用缺省配置,增加85ns的读延迟和500ns的写延迟模拟nvm介质;同时修改linux内核,在内核地址尾部预留10g的内核空间并挂载pmbd;
修改pmbd,增加读写分离模块和动态粒度的写模块,在执行写操作时利用nvm字节寻址特性,仅写入实际增加的数据。同时我们修改linux内核中内外存的映射buffer_head结构,增加多粒度的内外存映射模块,增加dirty_pos和dirty_len保存需要实际需要写回外存的数据位置信息,实现多粒度的内外存映射算法;同时修改linux内核与设备驱动交互的bio结构,增加write_pos和write_len保存从buffer_head结构获得的dirty_pos和dirty_len信息,从而将实现写回数据位置信息传递到到pcie口nvm存储设备;构建新型nvm外存设备的原型,我们命名为apmbd。
为了减少网络通信对测试i/o性能的影响,使用一台机器搭建测试环境,配有intel(r)xeon(r)e56062.13ghz处理器和20g内存。使用fio和filebench作为测试工具。
使用fio中的libaio,测试apmbd的i/o性能,并与ext4onpmbd和ext2onpmbd进行对比。设置访问块大小为4kb,测试顺序读写3万个大小分别为8kb、32kb、128kb和512kb文件时的性能,图2是顺序写性能的测试结果,图3是顺序读性能的测试结果;此外设置系统数据块的大小分别为4kb、8kb、16kb和32kb,测试顺序写3万个512kb文件的性能,结果如图4所示。
同时使用filebench来模拟应用服务器的访问情况,选择了copyfile、webserver和fileserver三种类型负载测试i/o性能,设置文件大小为32kb,文件数量为5万个,与ext4onpmbd进行对比,测试结果如图5所示。
实施例3
在实现新型nvm外存设备的原型时,主要包括读写分离线程、动态粒度写线程和多粒度内外存映射线程,它们的工作步骤分别如下所示。
读写分离线程:
步骤1,接收文件系统访问外存设备的请求,分析操作类型,为读操作转到步骤2,为写操作转到步骤3;
步骤2,外存设备使用基于数据块的读方法完成读操作,并将读出的数据反馈给文件系统;
步骤2,外存设备使用动态粒度的写方法完成写操作,并将结果反馈给文件系统。
动态粒度写线程:
步骤1,分析文件系统发送的写操作,获取写数据块需写入的起始地址write_pos(write_pos∈n)和长度write_len(write_len∈n),并比较写数据块与系统数据块的大小,若写数据块小与系统数据块则转到步骤2,否则转到步骤3;
步骤2,根据write_len设置传输给外存设备的数据量,由写入数据、write_pos和write_len构建写入数据包传输给外存设备,并由外存设备根据write_pos和write_len将需要写入数据包写入相应位置,并转到步骤8;
步骤3,按照最大为系统数据块大小将写入数据分成若干个数据包,以实际大小构建最后一个数据包,并将第一个数据包作为当前需写入数据包,转到步骤4;
步骤4,若当前需写入数据包的大小等于系统数据块,则转到步骤5,否则转到步骤6;步骤5,将write_pos的值设置为-1,采用以数据块为单位写方法,并由外存设备将数据包作为一个数据块写入设备,转到步骤7;
步骤6,从当前需写入数据包中获取write_pos和write_len的信息,设置传输给外存设备的数据量,并发送写入数据包、write_pos和write_len,最后外存设备根据write_pos和write_len将需写入数据包写入相应位置,转到步骤8;
步骤7,判断是否还有下一个未完成的写入数据包,如有则转到步骤4,否则转到步骤8;
步骤8,结束写操作,并向文件系统反馈写入成功信息。
多粒度内外存映射线程:
步骤1,在内外存映射表的每个映射项中增加dirty_pos(dirty_pos∈n)和dirty_len(diry_len∈n),保存内外存之间多粒度的映射信息,其中dirty_pos表示在该数据块中需要更新到外存数据区的起始地址,dirty_len表示该数据块中需要更新到外存数据区的长度,dirty_pos的值为-1表示该数据块不采用多粒度映射方法,s(s∈n)和l(l∈n)分别表示要写入数据起始逻辑地址与长度,转到步骤2;
步骤2,依据s查找内外存映射表中所对应的映射项,如s与该映射项的起始地址相同且l的值与数据块大小相同,则将该映射项的dirty_pos设置为-1,否则将s对应的物理地址保存到dirty_pos中,转到步骤3;
步骤3,比较l的值是否超出了该映射项对应逻辑块的长度,如未超出,则使用l设置dirty_len的值,并将l的值清零,转到步骤4;否则依据数据块大小和dirty_pos计算出dirty_len的值,并更新s和l,转到步骤4;
步骤4,如果l的值不为0转到步骤2,否则结束整个操作。
图6给出了写入数据量小于系统数据块大小时,使用的动态粒度的写方法示意图。
图7给出了写入数据量大于系统数据块大小时,使用的动态粒度的写方法示意图。
图8给出了使用多粒度的内外存映射方法,获得写操作计算映射项dirty_pos和dirty_len的示意图。
图9给出了读操作的示意图。
- 还没有人留言评论。精彩留言会获得点赞!