基于粒子群优化BP神经网络的弹药贮存可靠性预测方法与流程
本发明涉及弹药贮存可靠性技术领域,具体涉及一种基于粒子群优化bp神经网络的弹药贮存可靠性预测方法。
背景技术:
贮存寿命是弹药的一个非常重要的技术指标,对弹药贮存寿命的评估也是一项非常重要的工作,为了准确获得弹药贮存可靠性的状况,确保弹药安全贮存和随时提供性能良好的弹药,就必须进行弹药贮存寿命的研究,因此对弹药贮存可靠性进行科学预测是非常必要的。早在70年代初,世界各国就开始了对弹药贮存可靠性的研究;近些年国内外学者对弹药贮存可靠性的预测方法进行了大量研究,包括基于正常应力贮存寿命试验数据评估法、基于加速寿命试验数据评估法、基于马尔可夫过程、基于模型预测法、基于模糊数预测法、基于人工神经网络的评估方法及基于神经网络组合模型的预测方法等,有学者对武器系统的贮存寿命预测方法进行了研究,结果验证了神经网络预测模型更优,但是由于神经网络收敛速度慢,容易陷入局部极小值,提出基于神经网络组合模型的预测方法;同时,有很多学者对bp算法进行了大量的改进,但所得到的收敛速度和精度是有限的,容易陷入局部最优解。
近年来,国内外的许多学者和专家把全局优化性能的群智能优化算法迭代bp神经网络,如遗传算法、粒子群算法等,这些算法可以克服bp算法的缺陷。但是,智能算法本身又有内在的缺陷。比如智能优化方法中研究最成熟的遗传算法,从理论上它可以解决各种复杂问题,事实上遗传算法因具有复杂的遗传操作使得网络训练时间和复杂程度出现指数级增长,同时算法也缺乏局部区域的有效搜索机制,在后期收敛速度缓慢可能有停滞现象出现。
目前,在其他领域中,学者已经提出使用粒子群优化算法与bp神经网络相结合进行预测,pso算法具有只有速度—位移模型简单操作的特性,只要根据自己的速度就可以来决定搜索方向,可以避免遗传算法上的缺陷,并可用于多目标化、任务分配、模式分类和高维复杂的数据处理等优化问题。
由于pso算法发展时间较短,理论基础和应用推广还需要进一步深入研究,国内外将pso算法与bp神经网络相结合应用到贮存可靠性的预测,有关文献还很少;特别是将pso算法优化神经网络模型运用到弹药贮存可靠性预测的这一特殊领域,目前国内外还未查到有关文献。
因此希望有一种基于pso算法优化bp网络对弹药贮存可靠性预测方法,可以克服或至少减轻现有技术的上述缺陷。
技术实现要素:
本发明要解决的技术问题是针对现有技术中的不足,提出了一种基于粒子群优化bp神经网络的弹药贮存可靠性预测方法,在算法中选取全局智能优化算法pso优化具有全局的网络参数,弥补bp神经网络收敛速度慢、易陷入局部极小等缺陷,达到弹药贮存可靠性预测的精度。
为了达到上述目的,本发明的基于一种粒子群优化bp神经网络的弹药贮存可靠性预测方法。首先,利用弹药贮存可靠性数据的变化规律,建立神经网络预测模型;进一步,利用全局智能优化算法pso优化bp神经网络的权值和阈值,进行弹药贮存可靠性预测。具体过程包括如下几个步骤:
1.参数初始化设置,分为两部分:第一部分是bp网络的参数设置,根据输入数据和输出数据,确定bp网络的输入、输出节点数和隐含层数以及其节点数;第二部分是粒子群算法的参数设置,设置粒子个数,粒子初始位置和速度以及它们的范围,最大迭代次数,学习因子c1和c2等参数;惯性权重采用由shi提出的线性递减权重策略,即
式中
2.计算粒子的初始适应度值。网络正向传播过程中得到的误差是均方误差,即粒子群算法的适应度函数为均方误差公式,本发明中只讨论网络输出层节点数为1的情况,其适应度函数形式:
式中,n表示训练的样本组数;
3.将每一个粒子的适应度值与个体最优适应度值和全局最优适应度值作比较,以判断当前位置的优劣,并确定粒子位置的个体最优和全局最优;(1)粒子的适应度值分别与个体最优值pbest、全局最优值gbest相比较,若粒子当前适应度值优于个体最优适应度值,则将当前值作为个体最优适应度值,并用粒子的当前位置代替历史的个体最优位置;(2)若粒子中的当前个体最优适应度值优于历史的全局最优值,则将当前个体最优位置作为该粒子的全局最优位置,即全局最优值是个体最优中的最好值。
4.更新每个粒子在每维度里的速度和位置,更新的方式如下公式所示:
其中,i=1,2,…,n;n是粒子群规模;d=1,2,…,d;
5.将上述粒子群算法更新得到的全局最优映射到bp神经网络的初始权值和阈值,然后进行网络的训练;在bp神经网络反向传播过程中利用pso算法优化的权值和阈值,迭代循环训练进一步调节权值和阈值,当满足迭代次数达到最大值或训练误差小于期望设定值,则结束循环训练,输出结果;否则转到2,继续循环执行上述步骤。
6.利用测试样本进行bp神经网络的测试,输入测试样本,利用上述训练好的网络进行仿真,将输出结果与期望设定值作比较,从而得出测试效果。
本发明的基于粒子群优化bp神经网络的弹药贮存可靠性预测方法针对基本bp神经网络算法存在的问题从以下两点进行了改进:(1)对bp学习算法的训练函数分别采用动量bp法和变学习率bp法,加快bp神经网络的学习速度,提高bp神经网络的学习效率。
(2)利用粒子群优化算法调节和优化具有全局的网络参数,即权值和阈值,用神经网络学习方法优化具有局部性的参数,避免了易陷入局部极小的缺陷,提高收敛速度,以达到预测精度。
附图说明
图1为本发明的基于粒子群优化bp神经网络的弹药贮存可靠性预测方法的流程图;
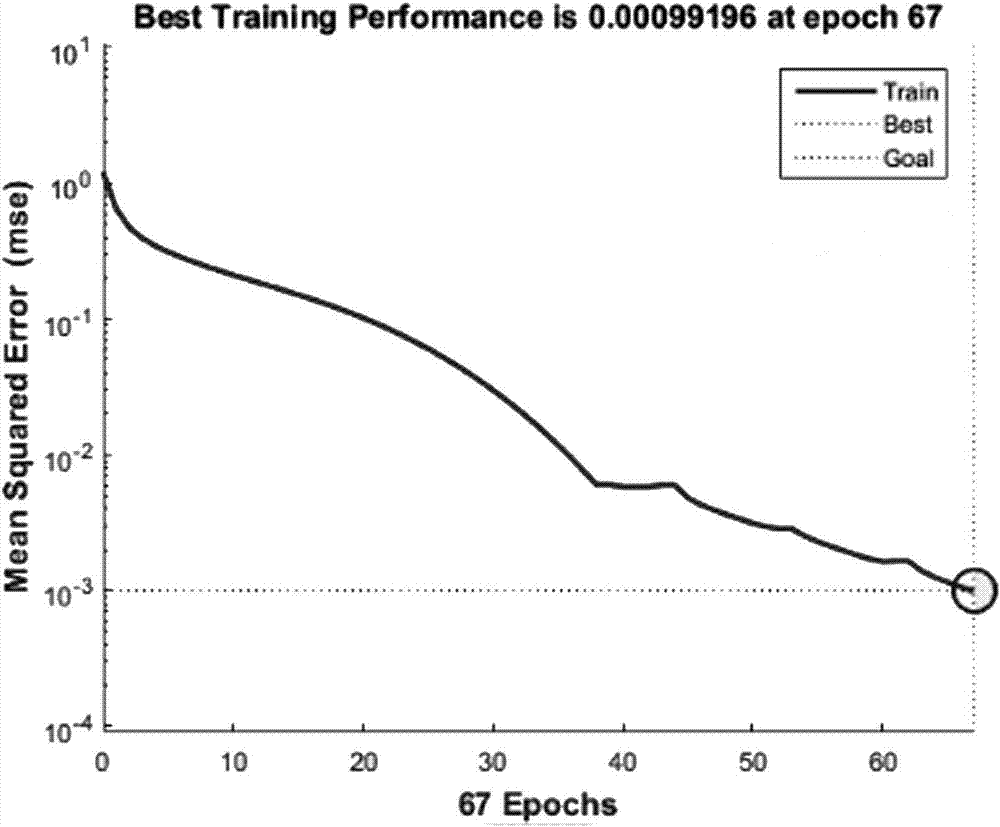
图2为变学习率bp网络误差变化曲线;
图3为pso-变学习率bp网络误差变化曲线;
图4为动量bp网络误差变化曲线;
图5为pso-动量bp网络误差变化曲线;
图6为变学习率bp网络准确率曲线;
图7为pso-变学习率bp网络准确率曲线;
图8为动量bp网络准确率曲线;
图9为pso-动量bp网络准确率曲线;
图10为各网络预测误差值比较曲线。
具体实施方法
为使本发明实施的目的、技术方案和优点更加清楚,下面将结合被发明实施例中的附图,对本发明实施例中的技术方案进行更加详细的描述。本实施例的基于粒子群优化bp神经网络的弹药贮存可靠性预测方法,具体包括以下步骤。
1.参数初始化设置,分两部分:第一部分是bp网络的参数设置,根据输入数据和输出数据,确定bp网络的输入、输出节点数和隐含层数以及其节点数;第二部分是粒子群算法的参数设置,设置粒子个数,粒子初始位置和速度以及它们的范围,最大迭代次数,学习因子c1和c2等参数;惯性权重采用由shi提出的线性递减权重策略,即
2.计算粒子的初始适应度值。网络正向传播过程中得到的误差是均方误差,即粒子群算法的适应度函数为均方误差公式,本发明中只讨论网络输出层节点数为1的情况,其适应度函数形式:
式中,n表示训练的样本组数;
3.将每一个粒子的适应度值与个体最优适应度值和全局最优适应度值作比较,以判断当前位置的优劣,并确定粒子位置的个体最优和全局最优;(1)粒子的适应度值分别与个体最优值pbest、全局最优值gbest相比较,若粒子当前适应度值优于个体最优适应度值,则将当前值作为个体最优适应度值,并用粒子的当前位置代替历史的个体最优位置;(2)若粒子中的当前个体最优适应度值优于历史的全局最优值,则将当前个体最优位置作为该粒子的全局最优位置,即全局最优值是个体最优中的最好值。
4.更新每个粒子在每维度里的速度和位置,更新的方式如下列公式所示:
其中,i=1,2,…,n;n是粒子群规模;d=1,2,…,d;
5.将上述粒子群算法更新得到的全局最优映射到bp神经网络的初始权值和阈值,然后进行网络的训练;在bp神经网络反向传播过程中利用pso算法优化的权值和阈值,迭代循环训练进一步调节权值和阈值,当满足迭代次数达到最大值或训练误差小于期望设定值,则结束循环训练,输出结果;否则转到2,继续循环执行上述步骤。
6.利用测试样本进行bp神经网络的测试,输入测试样本,利用上述训练好的网络进行仿真,将输出结果与期望设定值作比较,从而得出测试效果。
为了验证方法的有效性,本文实现三层神经网络训练函数的加动量bp法‘traingdm’和变学习率bp法‘traingda’,并用pso算法对分别对其进行优化。输入层和输出层的神经元数目是由问题本身直接决定的,隐含层节点数利用“试凑法”确定为11,根据误差和收敛次数确定学习速率为0.1。
由相同的训练样本集进行网络学习,并通过测试样本集对算法进行验证,各模型网络收敛速度比较:由图2~图5可知,期望误差在变学习率bp网络中通过迭代67次后达到;本发明的pso优化后的变学习率bp网络中通过迭代50次就达到了;期望误差在动量的bp网络中通过194多次迭代后达到;本发明的pso优化后的动量bp网络中通过迭代174次就达到;单独bp网络由于易陷入局部极小值、收敛速度慢等问题,在迭代过程中震荡幅度相对较大;经本发明的pso优化的bp网络不但在收敛速度上有所提高,且曲线也较为平滑;各模型预测准确率比较:由图6~图9可知,本发明的pso优化的变学习率bp网络和动量bp网络训练精度达到了99%以上,与单独的变学习率bp网络和动量bp网络相比,经pso优化的bp网络在训练精度上略微提高。
图10测试集下各模型的预测误差值比较,由图可知,不管训练函数选取动量bp法还是变学习率bp法,经pso算法优化后的bp网络模型预测结果都优于两种单独bp网络模型预测的结果,既减小了误差的极值,又减小了误差的变化范围。本发明对标准的bp神经网络所做优化的优势显而易见,优化后的bp神经网络有效的避免了自身固有缺陷,提高了算法的收敛速度和预测精度。
显然,上述实施例仅仅是为清楚地说明本发明所作的举例,并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化或变动,这里无需也无法对所有的实施方式予以穷举。而这些属于本发明的精神所引申出的显而易见的变化或变动仍处于本发明的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!