引力搜索RNA‑GA的催化裂化主分馏塔神经网络建模方法与流程
本发明属于化工过程控制领域,具体涉及一种引力搜索rna-ga的催化裂化主分馏塔神经网络建模方法。
背景技术:
催化裂化是石油炼制的重要生产过程之一,是在热和催化剂的作用下使重油发生裂化反应,转变为裂化气、汽油和柴油等的生产过程。催化裂化主分馏塔作为催化裂化装置的主分离设备是实现产品分离的关键单元,是催化裂化过程中重要的一环。建立精确的催化裂化主分馏塔模型有助于实现流化催化裂化装置的先进控制与优化,同时对于降低催化裂化装置能耗和提高产品质量具有重要的意义。
由于催化裂化主分馏塔是一个具有滞后和耦合的非线性系统,传统的机理建模方法难以满足高精度建模的需要,因此神经网络受到人们的关注。神经网络是模拟大脑神经突触联接的结构进行信息处理的计算模型,具有逼近任意非线性函数的能力。但是神经网络也存在易于陷入局部极小、收敛速度慢等问题。
本发明提出一种引力搜索rna遗传算法(rna-ga),在rna-ga中加入基于万有引力定律和牛顿第二定律的引力搜索操作,并将引力搜索rna遗传算法用于催化裂化主分馏塔的神经网络建模,取得了较理想的效果,该方法也适用于其他复杂非线性系统的建模。
技术实现要素:
本发明针对现有技术的不足,提出了一种引力搜索rna-ga的催化裂化主分馏塔神经网络建模方法
引力搜索rna-ga的催化裂化主分馏塔神经网络建模方法,它的步骤如下:
步骤1:获得催化裂化主分馏塔的输入输出数据作为样本数据,其中输入数据为顶循流量q1、一中流量q2和二中流量q3,输出数据为塔顶温度t1、粗汽油干点t2和轻柴油倾点t3;
步骤2:建立催化裂化主分馏塔rbf神经网络模型,模型采用一个三层rbf神经网络结构;
设定t为采样时刻,q1(t)、q2(t)和q3(t)分别为t时刻的顶循流量、一中流量和二中流量数据,t1(t)、t2(t)和t3(t)分别为t时刻的塔顶温度、粗汽油干点和轻柴油倾点数值,rbf神经网络模型输入变量个数为nin,输入向量x为
[q1(t)q2(t)q3(t)t1(t-1)t1(t-2)…t1(t-n)t2(t-1)t2(t-2)…t2(t-n)t3(t-1)t3(t-2)…t3(t-n)]
其中n为整数,设定n=3n+3,输出变量个数为nout=3,输出变量为[t1(t)t2(t)t3(t)],从输入层到输出层映射可用以下函数表示:
其中x为输入向量,||·||表示欧几里得范数,d表示隐层数,w1(i)、w2(i)和w3(i)分别是神经网络输出结点权值向量中的第i个分量,由递推最小二乘法确定;ci是神经网络第i个隐层的径向基函数中心向量,径向基函数φ(·)采用薄板样条函数,表示为:
φ(v)=v2ln(v)
其中v表示任意数;
步骤3:选择样本数据中的一部分数据作为训练样本,将数据输入到步骤2建立的rbf神经网络模型中;
步骤4:设置建立的rbf神经网络模型中的径向基函数中心;
步骤5:利用引力搜索rna遗传算法对步骤2建立的rbf神经网络模型的径向基函数中心进行寻优,获得rbf神经网络的径向基函数中心的最优解;
步骤6:利用步骤5获得的最优解作为催化裂化主分馏塔神经网络模型径向基函数中心,并利用测试样本检验神经网络模型。
催化裂化主分馏塔的输入输出数据可通过现场采集或实验获得。
上述步骤5可采用如下具体步骤实现:
步骤5.1:设定引力搜索rna-ga的参数,包括:种群数s、输入变量个数n、个体编码长度l、最大迭代次数gmax、转位换位概率pc、置换交叉概率pt、自适应变异概率pml和pmh;设定引力搜索rna-ga终止规则为:引力搜索rna-ga迭代次数达到最大迭代次数gmax;
步骤5.2:对神经网络模型的径向基函数中心进行碱基编码,随机生成一个初始种群,种群中包含s个个体,每个参数均由字符集{0,1,2,3}编码为一个长度为l的rna子序列,rbf神经网络模型的参数有n×d个,一个rna序列的编码长度为n×d×l,每个个体代表的参数如下:
其中c(i)表示第i个个体,cd,n表示个体中第d个隐层对应的神经网络径向基函数中心向量中的第n个分量;
步骤5.3:将种群中每个rna序列解码为rbf神经网络模型的参数,并采用最小二乘法计算出相应的神经网络输出结点权值向量,将不同时刻催化裂化主分馏塔神经网络模型的输出值
式中
步骤5.4:根据适应度函数值,利用轮盘赌法来选择个体,并利用适应度函数值选择适应度函数值最优的s/2个个体组成的中性个体集合en与适应度函数值最差的s/2个个体组成的有害个体集合ed构成新的种群e;
步骤5.5:在中性个体集合en中,以转位换位概率pc执行相应的转位操作或换位操作,产生有s/2个个体的集合ec1,具体操作步骤为:
1)在0~1之间随机选择一个数h,若h小于概率pc时,进行转位操作;
2)当h大于等于概率pc时,进行换位操作;
步骤5.6:在中性个体集合en中,以置换交叉概率pt执行置换操作,产生s/2个个体,集合为ec2;
步骤5.7:在集合[ec1;ec2;ed]中,以高位变异概率pmh和低位变异概率pml执行自适应变异操作,得到集合e2,其中自适应变异概率为:
其中,a1是初始变异概率,b1为变异概率变化范围,aa为变异速率,g为当前进化代数,g0为转折点;
步骤5.8:在集合e2中找出适应度函数值最优的个体bests;
步骤5.9:检查迭代次数是否达到终止条件,若满足要求则获得神经网络径向基函数中心,否则到步骤5.10;
步骤5.10:将集合e2进行引力搜索,得到新的种群,回到步骤5.3,进行下一轮迭代。
上述步骤5.10中引力搜索可采用如下具体步骤实现:
1)计算每个个体对应的质量,计算公式如下:
其中m表示个体的质量,worst表示种群中最差个体的适应度函数值,best表示种群中最优个体的适应度函数值,f表示该个体的适应度函数值;
2)计算引力常数,计算公式如下:
其中g0=100,α=20,g表示当前迭代次数,gmax表示最大迭代次数,g为引力常数,e是自然常数;
3)计算引力加速度
其中,ai,k为第i个个体的第k个隐节点对应的引力加速度向量,g为当前迭代中的引力常数,rand为0~1的随机数向量,mj是第j个个体对应的质量,
rk=||ei,k-ej,k||
4)根据加速度和初始速度,每次迭代记为一次移动,由此获得新种群,相关计算公式如下:
e′=e+v
v′表示新的速度矩阵,v表示速度矩阵,rn为随机数矩阵,a表示加速度矩阵,e为种群,e′表示为新的种群。
本发明利用引力搜索rna遗传算法对催化裂化主分馏塔神经网络模型的径向基函数中心进行寻优,获得催化裂化主分馏塔的神经网络模型。后续实施例中数据也表明该建模方法在实际使用时能取得理想的效果,该方法不仅适用于催化裂化主分馏塔,也可用于其他复杂系统的建模。
附图说明
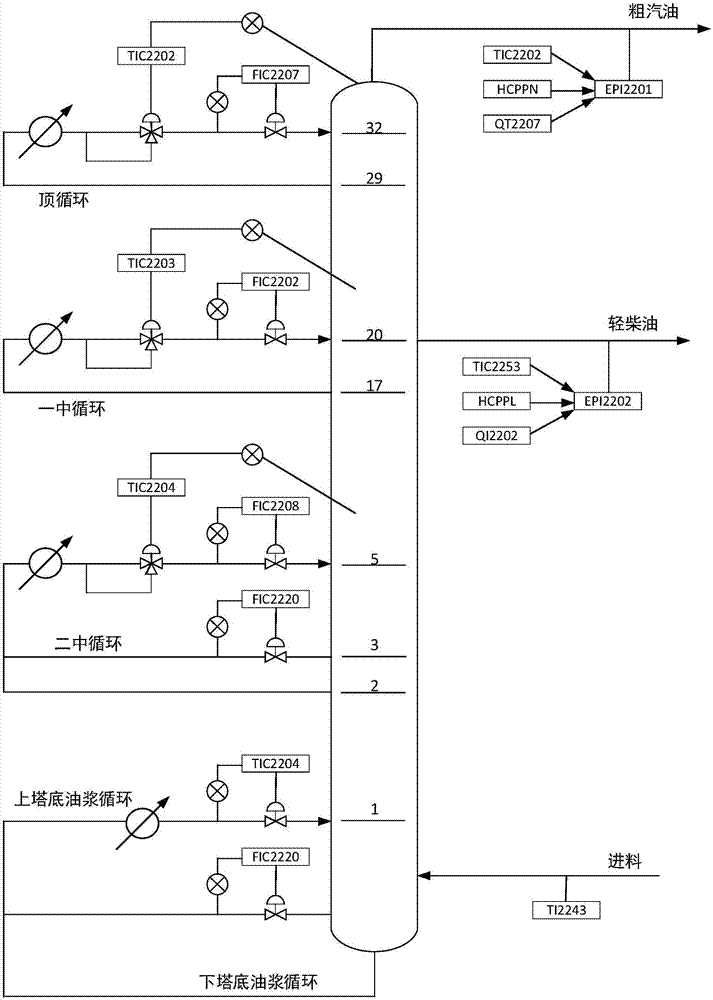
图1为催化裂化主分馏塔系统图;
图2为催化裂化主分馏塔神经网络模型示意图;
图3为基于引力搜索rna-ga流程图;
图4为塔顶温度t1采样输出和神经网络模型输出对比图;
图5为粗汽油干点t2采样输出和神经网络模型输出对比图;
图6为轻柴油倾点t3采样输出和神经网络模型输出对比图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述。
催化裂化主分馏塔的系统流程图如图1所示,催化裂化主分馏塔是一个多输入多输出系统,本发明目的在于建立能够预测塔顶温度t1、粗汽油干点t2和轻柴油倾点t3三个指标的神经网络模型。本发明中引力搜索rna-ga的催化裂化主分馏塔神经网络模型示意图如图2所示,该模型中径向基函数中心的寻优算法如图3所示,建模方法的具体步骤如下:
步骤1:通过采样获得催化裂化主分馏塔的输入输出数据作为神经网络模型的样本数据(采样数据来源于钟璇、张泉灵、王树青催化裂化主分馏塔产品质量的广义预测控制策略[j].控制理论与应用2001(18):134-137中的主分馏塔模型所产生),其中输入数据为顶循流量q1、一中流量q2和二中流量q3,输出数据为塔顶温度t1、粗汽油干点t2和轻柴油倾点t3。以顶循流量q1、一中流量q2和二中流量q3同时分别经历0→0.2→0.6,0→0.5→0.8和0→0.4→0.6共600组数据作为输入数据,相应的变量塔顶温度t1、粗汽油干点t2和轻柴油倾点t3数据作为输出数据;
步骤2:建立催化裂化主分馏塔rbf神经网络模型,模型采用一个三层rbf神经网络结构;
设定t为采样时刻,q1(t)、q2(t)和q3(t)分别为t时刻的顶循流量、一中流量和二中流量数据,t1(t)、t2(t)和t3(t)分别为t时刻的塔顶温度、粗汽油干点和轻柴油倾点数值,rbf神经网络模型输入变量个数为nin,输入向量x为
[q1(t)q2(t)q3(t)t1(t-1)t1(t-2)t1(t-3)t2(t-1)t2(t-2)t2(t-3)t3(t-1)t3(t-2)t3(t-3)]
其中有n=12,输出变量个数为nout=3,输出变量为[t1(t)t2(t)t3(t)],从输入层到输出层映射可用以下函数表示:
其中x为输入向量,||·||表示欧几里得范数,d表示隐层数,具体d=50,w1(i)、w2(i)和w3(i)分别是神经网络输出结点权值向量中的第i个分量,由递推最小二乘法确定,ci是神经网络第i个隐层的径向基函数中心向量,径向基函数φ(·)采用薄板样条函数,表示为:
φ(v)=v2ln(v)
其中v表示任意数;
步骤3:选择样本数据中的400组数据作为训练样本,将数据输入到步骤2建立的rbf神经网络模型中;
步骤4:设置建立的rbf神经网络模型中待寻优参数(径向基函数中心);
步骤5:提出引力搜索rna遗传算法,将其用于对步骤2提出的rbf神经网络的径向基函数中心进行寻优,运行引力搜索rna遗传算法,获得rbf神经网络的径向基函数中心的最优解;该步骤的具体实现方式为:
步骤5.1:设定引力搜索rna-ga的参数:种群数s=30、输入变量个数n=12、个体编码长度l=8、最大迭代次数gmax=20、转位换位概率pc=0.8、置换交叉概率pt=0.8、自适应变异概率pml和pmh,设定引力搜索rna-ga终止规则为:引力搜索rna-ga迭代次数达到最大迭代次数gmax;
步骤5.2:对神经网络模型中待寻优参数(径向基函数中心)进行碱基编码,随机生成一个初始种群,种群中包含s个个体,每个参数均由字符集{0,1,2,3}编码为一个长度为l的rna子序列,rbf神经网络模型的参数有n×d个,则一个rna序列的编码长度为n×d×l,每个个体代表的参数如下:
其中c(i)表示第i个个体,cd,n表示个体中第d个隐层对应的神经网络径向基函数中心向量中的第n个分量;
步骤5.3:将种群中每个rna序列解码为rbf神经网络模型的参数,并采用最小二乘法计算出相应的神经网络输出结点权值向量,将不同时刻催化裂化主分馏塔神经网络模型的输出值
式中
步骤5.4:根据适应度函数值,利用轮盘赌法来选择个体,并利用适应度函数值选择适应度函数值最优的s/2个个体组成的中性个体集合en与适应度函数值最差的s/2个个体组成的有害个体集合ed组成新的种群e;
步骤5.5:在中性个体集合en中,以转位换位概率pc执行相应的转位操作或换位操作,产生有s/2个个体的集合ec1,具体操作步骤为:
1)在0~1之间随机选择一个数h,若h小于概率pc时,进行转位操作;
2)当h大于等于概率pc时,进行换位操作;
步骤5.6:在中性个体集合en中,以置换交叉概率pt执行置换操作,产生s/2个个体,集合为ec2;
步骤5.7:在集合[ec1;ec2;ed](3/2×s个个体)中,以高位变异概率pmh和低位变异概率pml执行自适应变异操作,得到集合e2,其中自适应变异概率为:
其中,a1是初始变异概率,b1为变异概率变化范围,aa为变异速率,g为当前进化代数,g0为转折点;
步骤5.8:在集合e2中找出适应度函数值最优的个体bests;
步骤5.9:检查迭代次数是否达到终止条件,若满足要求则获得神经网络的最优解,作为径向基函数中心,否则到步骤5.10;
步骤5.10:将集合e2进行引力搜索,得到新的种群,回到步骤5.3,进行下一轮迭代。引力搜索的具体步骤如下:
1)计算每个个体对应的质量,相应的计算公式如下:
其中m表示个体的质量,worst表示种群中最差个体的适应度函数值,best表示种群中最优个体的适应度函数值,f表示该个体的适应度函数值;
2)计算引力常数,计算公式如下:
其中g0=100,α=20,g表示当前迭代次数,gmax表示最大迭代次数,g为引力常数,e是自然常数;
3)计算引力加速度
其中,ai,k为第i个个体的第k个隐节点对应的引力加速度向量,g为当前迭代中的引力常数,rand为0~1的随机数向量,mj是第j个个体对应的质量,
rk=||ei,k-ej,k||
4)根据加速度和初始速度,每次迭代记为一次移动,由此获得新种群,相关计算公式如下:
e′=e+v
v′表示新的速度矩阵,v表示速度矩阵(各变量初始速度均为1),rn为随机数矩阵,a表示加速度矩阵,e为种群,e′表示为新的种群;
步骤5.10:对步骤5.3~5.9进行迭代,若当前迭代次数满足要求,则获得神经网络的最优解,作为径向基函数中心,否则回到步骤5.3。
步骤6:利用步骤5获得的最优解作为催化裂化主分馏塔神经网络模型径向基函数中心,并利用测试样本检验神经网络模型,以验证其准确性。
按上述方法将顶循流量q1、一中流量q2和二中流量q3同时分别经历1→0.5→1→0.7,1→0.6→1→0.4和1→0.7→1→0.5共800组数据作为测试输入数据,得到相应的变量塔顶温度t1、粗汽油干点t2和轻柴油倾点t3数据分别为图4、图5和图6。从测试结果图4、图5和图6可以看出,基于引力搜索rna-ga的催化裂化主分馏塔神经网络模型能够准确反映实际系统特性。因此,上述模型可用于准确预测催化裂化主分馏塔中的t1、t2和t3三个变量,作为控制催化裂化系统的依据。
- 还没有人留言评论。精彩留言会获得点赞!