基于项目的评分矩阵预测算法的制作方法
本发明涉及推荐系统和数据分析技术领域,特别是涉及一种基于项目的评分矩阵预测算法。
背景技术:
随着时代的发展与科学技术的进步,网络已慢慢渗透进人们的生活并发展成为人们收集以及获取信息的重要途径,用户更倾向于通过互联网来得到自己所需要的信息与各方面的资料。但是,以web2.0为代表的互联网技术促使网络数据展现出爆炸式增长的现象,它的结构变得越来越复杂,也造成越来越多的信息和服务充斥着整个网络的局面。这大大增加了人们在网络上汲取信息的难度。与此同时,人们对于互联网信息的利用效率也大大降低了,这就出现了"信息过载"的困境。推荐系统(recommendersystem)在这种情境下应运而生。
“推荐系统”使用特定的方法建立起项目与用户之间关系,最常使用的推荐系统的定义为“推荐系统通过电子商务网站给予用户消费建议,代替销售员工对用户导购过程,解决用户购买什么样商品”。这是一个狭义的定义,因为它只定义了在电子商务情境下的推荐系统。2005年,adomavicius等人总结道:通常情况下,“推荐问题”可以简化为“用户对未知的项目如何进行评分的估计问题”,评分估计通常基于对其它项目的评分模拟出当前用户对未购买项目的打分;一旦模拟出当前用户对未购买项目的打分,便可以将打分最靠前的n个项目作为推荐列表给用户。
在上述的评分估计问题中,常用的有协同过滤算法。该算法所存在的缺陷在于它的实现需要对用户的评价信息进行分析处理,但实际上由于电子商务网站的评论信息量巨大、商品信息庞大,导致了信息不对称;同时容易出现许多商品的评论信息极少,而热门商品的评论信息又很多的情况,从而导致评价信息不准确,进而影响到推荐结果的准确性。
技术实现要素:
为了克服现有技术存在的缺陷,本发明提出了一种基于项目的评分矩阵预测算法,该算法包括以下步骤:
步骤101、获取推荐数据集,有两种获取方式:一种是通过用户自定义方式使用爬虫工具爬取互联网上的数据,例如python的scrapy框架;另一种是通过互联网下载相应的互联网数据集;
步骤201、进行数据预处理,至少包括通过处理缺失值、处理噪声、筛选离群点且解决不一致等问题;主要目的是实现数据格式统一化、错误数据清除、重复数据清除;
步骤301、使用newpearsoncorrelationcoefficient(npcc)算法计算项目的相似度,计算公式如下:
其中,ni为项目i具有评分行为的用户数量,nj为项目j具有评分行为的用户数量。rui是用户u给项目i的评分数据,ruj是用户u给项目j的评分数据,ri、rj分别为所有用户对项目i和项目j的平均评分。
步骤(401)、构造关联矩阵:遍历项目集合中任意两项,使用上述步骤的相似度计算方法计算这两项的相似度,基于该相似度构建出项目的关联矩阵。
步骤(501)、构造评分矩阵,进行预测用户对待推荐项目的评分结果,用户对于待推荐项目的评分计算,具体公式如下:
缺失值指的是用户对自己已经购买的部分项目集没有评分,数据集采用赋予默认值的处理方式,论文采用对该项目集用户有效评分的平均数代替,缺失值计算公式如下:
其中,su,i为用户u对项目i的评分,为ni对项目i有评分的用户集合,su’,i为其他项目对项目i的评分,ci表示购买项目i用户的个数。
用户对于待推荐项目的评分计算,采用改进的newitem-basedcollaborativefiltering(nitem-basedcf)算法,计算公式如式(3)所示:
其中,su,i为用户u对项目i的预测评分,iu表示用户u已评分的项目集,rij表示项目i和j的关联度,
步骤601、计算出用户已购买的商品与其它商品之间的相似度大小,根据nitem-basedcf算法利用相似度计算出用户对项目的预测评分,根据预测评分可以构造用户对项目预测评分矩阵。矩阵中每一项为不同用户对不同项目的评分,如
与现有技术相比,本发明使用npcc方法计算项目间相似度效果要好于传统的pcc方法和jaccard方法;以及,使用nitem-basedcf算法提高了预测用户对项目评分的精度。
附图说明
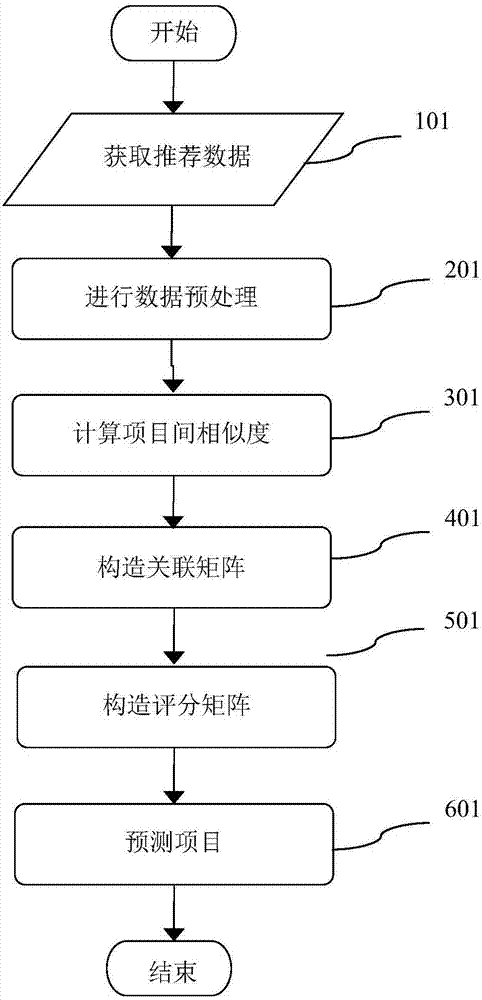
图1为本发明的基于项目的评分矩阵预测算法;
图2为不同比例测试集实验结果对比图。
具体实施方式
下面结合附图对本发明作进一步详细描述。
如图1所示,本发明的基于项目的评分矩阵预测算法整体流程具体包括以下步骤:
步骤101、获取推荐数据集,有两种获取方式:一种是通过用户自定义方式使用爬虫工具爬取互联网上的数据,例如python的scrapy框架;另一种是通过互联网下载相应的互联网数据集;
步骤201、进行数据预处理,至少包括通过处理缺失值、处理噪声、筛选离群点且解决不一致等问题;主要目的是实现数据格式统一化、错误数据清除、重复数据清除。
步骤301、使用newpearsoncorrelationcoefficient(npcc)算法计算项目的相似度,计算公式如下:
其中,ni为项目i具有评分行为的用户数量,nj为项目j具有评分行为的用户数量。rui是用户u给项目i的评分数据,ruj是用户u给项目j的评分数据,ri、rj分别为所有用户对项目i和项目j的平均评分。
步骤(401)、构造关联矩阵:遍历项目集合中任意两项,使用上述步骤的相似度计算方法计算这两项的相似度,基于该相似度构建出项目的关联矩阵。执行关联矩阵构建算法:
输入:项目集i,项目i,项目j,相似度计算方法simcompute
输出:关联矩阵rij
步骤(501)、构造评分矩阵,进行预测用户对待推荐项目的评分结果,用户对于待推荐项目的评分计算,具体公式如下:
缺失值指的是用户对自己已经购买的部分项目集没有评分,数据集采用赋予默认值的处理方式,论文采用对该项目集用户有效评分的平均数代替,缺失值计算公式如下:
其中,su,i为用户u对项目i的评分,为ni对项目i有评分的用户集合,su’,i为其他项目对项目i的评分,ci表示购买项目i用户的个数。
用户对于待推荐项目的评分计算,采用改进的newitem-basedcollaborativefiltering(nitem-basedcf)算法,计算公式如式(3)所示:
其中,su,i为用户u对项目i的预测评分,iu表示用户u已评分的项目集,rij表示项目i和j的关联度,
步骤601、根据上述步骤可以计算出用户已购买的商品与其它商品之间的相似度大小,根据nitem-basedcf算法利用相似度计算出用户对项目的预测评分,根据预测评分可以构造用户对项目预测评分矩阵。矩阵中每一项为不同用户对不同项目的评分,如
如图2所示,不同相似度方法实验对npcc方法进行效果验证。实验结果如表1所示,该实验使用mae对实验进行验证。
本发明的验证中,使用平均绝对误差(mae)作为预测评分的评价标准,与平均误差相比,平均绝对误差由于离差被绝对值化,不会出现正负相抵消的情况,因而,平均绝对误差能更好地反映预测值误差的实际情况。mae的计算公式如公式(5)所示。
其中,k表示预测项目的个数,pi和qi分别为预测评分和项目的实际评分,mae的值越小,表示预测结果越好。
使用均方根误差(rmse)可以很好体现出预测的精准度,该值也是测量预测值与真实值的差异程度,且对于预测值中出现的较大或较小偏差反映较为敏感。rmse的公式如(6)所示。
其中,参数sui为nitem-basedcf算法预测用户评分,rui为用户u对项目i真实评分。参数i表示预测项目编号,n表示预测项目数量。
从图2中可以看到,当训练集为90%的时候,mae值是最低的,说明预测结果与真实值最为接近。并且随着训练集比例的降低,mae值变大,说明预测结果与真实值差距越来越大。实验中,同样采用随机抽取不同比例数据作为训练集的方式进行,随机从数据集中选取90%的数据作为训练集进行建模,然后随机从数据集中选取5%数据进行预测验证。实验结果如表1所示,该实验使用mae对实验进行验证。
表1、不同相似度算法对比实验
从表1中可知,当训练集和测试集的比例固定时,使用pcc方法的mae值要小于使用jaccard方法,npcc方法的mae值小于pcc方法。实验结果证明,使用npcc方法计算项目之间的相似度效果要好于传统的pcc方法和jaccard方法。使用rmse进行验证,结论是npcc方法效果要好于传统的pcc和jaccard方法。综合上述实验结果,专利使用npcc方法计算项目间相似度效果要好于传统的pcc方法和jaccard方法。使用nitem-basedcf算法提高了预测用户对项目评分的精度。
- 还没有人留言评论。精彩留言会获得点赞!