一种基于协同过滤的优化方法与流程
本发明属于数据处理和数据挖掘领域,具体涉及一种基于奇异值分解和bp神经网络预测未评分项的改进方法。
背景技术:
进入移动互联网时代,各种平台上信息资源的体量越来越大,出现了比传统互联网时代更为严重的“信息过载”现象。面对如此巨大的信息量,用户经常感到无从下手,原因就是很难再通过简单的查找较快的获得自己喜欢的信息,同时也大大增加了人们查询信息的时间,这是“信息过载”现象在电子商务领域的表现。用户也可以通过阿里巴巴提供的搜索指数来选择商品,但是并不一定符合自己个性化需求。因此用户需要一种能根据自己的偏好特点来自动选择其感兴趣信息的技术,推荐算法在这种背景下得到了迅速发展。
推荐系统的研究重点在于如何快速的从海量信息中获取我们感兴趣的内容,省时省力,准确快捷是首要目标。现在是大数据时代,各种信息数据增长速度极快,推荐系统的效率已经成为学者十分重视的问题,各种框架的出现表明了对推荐系统的进一步研究已经迫在眉睫,同时也给各类电商平台带来了很大改变。
根据原理的不同,个性化推荐算法有几种不同的分类,通过不同的推荐策略来进行信息等资源的推荐,大致分为三种推荐方式:基于关联规则、基于内容和协同过滤推荐算法。基于关联规则算法的本质是获取数据与数据之间的关系,在获取到用户的行为之后,使用关联规则技术分析各个产品在用户之间购买的关系,找出各个产品之间的联系,由这些产品的联系推导出来跟其他产品之间的联系,不同规则的相似度不同,这个在每个关联规则中都可以通过两商品同时发生的概率来表示。基于内容的推荐算法是以平台上商品的分类属性来进行推荐的,首先要明确商品类别属性,根据商品本身所具有的属性特点来判断某一未评分产品是否符合用户的期望。协同过滤推荐算法是根据用户的兴趣进行分析的,在用户购买商品的过程中,用户之间和项目之间都会有相似性,通过这些相似性来进行产品的定向推荐,算法的核心是寻找用户和商品的最近邻居。
协同过滤是根据用户的兴趣进行分析的,在用户购买商品的过程中,用户之间和项目之间都会有相似性,通过这些相似性来进行产品的定向推荐,算法的核心是寻找用户和商品的最近邻居。该算法有两种重要的分类,基于用户的协同过滤算法和基于项目的协同过滤算法。最早使用到这两种方法是在信息的过滤时进行筛选的,后来延伸出来各种类型的算法。其实这两者的原理是相似的,都要使用到用户对商品的评分数据来进行分析,前者是整个算法的核心,通过矩阵行数据计算用户相似性,后者是通过列数据计算项目的相似性。
技术实现要素:
本发明的目的是针对现有技术的不足,提出了一种基于奇异值分解和bp神经网络预测未评分项的改进方法。该方法通过奇异值分解用户-项目评分矩阵,有效的降低了矩阵的稀疏性;同时在奇异值分解的基础上,进一步采用bp神经网络来对未评分的目标项目进行分值预测,这样做的好处是避免了用平均分值代替而产生的效果单一性,从而使推荐的准确性有了较大提升。
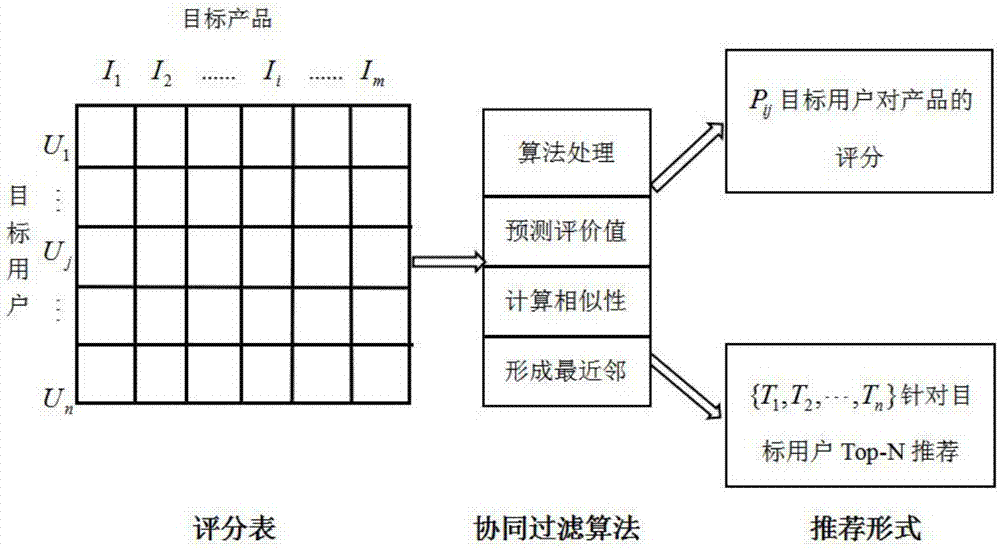
将用户对商品的评分用m×n矩阵r表示,其中,m是用户数量,n是商品数量,矩阵中元素rij是用户i对商品j的偏好,rij为数值。用矩阵r进行表示。
若r是m×n矩阵r的秩,那么对矩阵r进行分解
(1)u是m×m阶酋矩阵,表示用户特征矩阵;s是半正定m×n阶对角矩阵,s还能够用∑r的对角阵来表示;vt是v的共轭转置矩阵,是n×n阶酋矩阵,表示商品的特征矩阵;
(2)rrt的特征值λ1,λ2,…λr也是rtr的特征值;
(3)存在1≤i≤r,
为达到上述目的,本发明采用的技术方案为:
奇异值分解能够用于解决矩阵降维的问题,在电商个性化推荐系统中将其应用到用户-项目评分矩阵上,进行矩阵变换,这一过程是获取矩阵数据的重要特征值来取代整个的稀疏矩阵。为此,通常需要以下步骤。
(1)首先对于用户项目评分矩阵r,采用奇异值分解公式进行分解。
(2)然后把矩阵s中对角线上r-k个最小奇异值置为0,得sk。
(3)最后计算rk=uskvt作为r的重构矩阵。
奇异值分解过程是在进行奇异值分解之前首先对数据进行处理,将用户和商品区别开来,矩阵中的rij即表示所有用户i对商品j的喜好分值,若没有用户评分,则该项设置为0。在结合协同过滤推荐算法中,奇异值分解可以方便快速的处理原始数据,在保证数据集基本不缺失重要数据的情况下,应对当前评分矩阵数据极度稀疏性这一问题。
在协同过滤推荐方法中,目标用户和商品之间的关系影响整个算法推荐流程,利用用户的相似邻居对某一商品的评分来对其他商品进行评估。在获得准确完整的用户评价数据之后即可利用奇异值来进行处理。
下面是利用奇异值分解的步骤:
步骤1)读取用户对项目的行为数据,将用户对项目的评分转变成矩阵格式,将数据直接读入矩阵;
步骤2)计算矩阵大小,选取大小适合的实验训练集;
步骤3)选取合适的测试集数据用来跟训练集数据做对比,并将测试数据集转换为矩阵格式;
步骤4)将训练数据集中对应的矩阵中用户对物品的评分值读入训练集矩阵中;
步骤5)获取用户评分矩阵,将用户所在的第j列和电影所在的第j+1列转换即可;
步骤6)对训练集矩阵进行分解获得结果。
bp神经三层网络结构中元素中,{p1,p2,p3,…,pn-2,pn-1,pn}是输入元素,代表选取商品的特征数据值,获取的特征向量维数即为神经元个数;{w1,w2,w3,w4,w5}为隐层,包含权值的很多分量;{q1,q2,q3,q4,q5}是输出元素,输出产品评分值。
bp神经网络的训练是不断进化迭代的。原始的bp神经网络是net(i),那么假定更新之后的网络是net(i+1)。由于最新的数据实时性最好,那么在进行进化时把最新的n个数据作为样本集进行训练的效果是最好的。
训练步骤如下。
步骤1)算法开始;
步骤2)设定初始的样本集,在原有样本训练集上进行更新得到新的样本集,用新的样本集进行训练;
步骤3)设定并初始化三层网络结构的数据,包括输入参数、学习精度和偏差等。
步骤4)将原始网络的权值和阈值设定更新之后网络的初始值,这样是在原始网络基础进行不断更新;
步骤5)在网络中进行迭代训练,训练次数初始值根据需要进行设定;
步骤6)对网络中的学习精度进行判断是否收敛到最小值,如果符合,进行步骤8),如果不符合,则进行步骤7);
步骤7)判定迭代步数是否超过规定的步数:如果符合,进行步骤8);如果不符合,则进行步骤5);
步骤8)结束算法。
bp神经网络从两个过程来理解,第一个就是工作信号正向传递,第二个是误差信号反向传递。
计算误差函数对输出层的各神经元的偏导数δo(k)。
其中输入层有n个单元,隐含层有p个神经元,输出层有q个神经元,x是输入向量,hi是隐含层输入向量,ho是隐含层输出向量,yi是输出层输入向量,yo是输出层输出向量,do是期望输出向量,wih是输出层与中间层的连接权值,who是隐含层与输出层的连接权值,bh是隐含层各神经元的阈值,bo是输出层各神经元的阈值,f(·)是激活函数,e是误差函数。
计算误差函数对隐含层的各神经单元的偏导数δh(k)。
建立预测的网络结构,对于这个网络参数进行设定,已经给出算法的训练步骤,从中算法流程中发现知道需要进行权值的和阈值初始化,这里三层结构权值初始值依次设定为w1,w2,w3。对网络中的学习精度也要进行设定,用来判断是否收敛于某一值,设定为φ。还有一个最小值学习率设定为μ,设定较小值以保证系统的稳定性。另外,学习偏差设为b。因为bp神经网络处理任意非线性关系,激活函数来加入非线性因素,它的一大特点是处处可求导函数,非常适用于bp神经网络。
涉及到中间层结点数的计算方法,并不需要严格的数学推导来进行计算,选用经验公式nm=sqrt(no+ni)+1来计算最小中间层结点数,在一定范围之内是获得近似结果的。其中,ni表示输入层的结点数,nm表示中间层的结点数,n0表示输出层的结点数,采用不断改变参量寻求目标值方法获得中间层的结点数,这其实是一种试错法,适合用在这个场景中。通过经验公式求得中间结点数目nm分布在区间[ni,2ni]上。
附图说明
图1是推荐系统示意图。
图2是基于协同过滤推荐流程示意图。
图3是推荐引擎框架示意图。
图4是用户建模过程示意图。
图5是推荐模型数据示意图。
图6是用于预测的bp神经网络示意图。
图7是改进算法流程示意图。
具体实施方式
基于奇异值分解和bp神经网络预测未评分项的协同过滤算法改进流程如下:
输入:用户-评分矩阵r、用户i的评分矩阵ri、候选相邻邻居用户集t′(u)及元素个数δ、候选最近邻居用户集最小稀疏度η;
输出:目标用户u的top-n推荐集;
算法流程:
步骤1)对用户-项目评分矩阵运用矩阵分解svd算法,矩阵的稀疏度较小时降低矩阵维度,直到矩阵的稀疏度小于η,得到重构矩阵rk,则rk=uk∑vk,k是用户-项目评分矩阵的秩;
步骤2)在初次分组的基础上,利用向量相似性计算,得到精确的分组结果;
步骤3)对重构矩阵rk用bp神经网络填充未评分项。提取项目的特征值来建立神经网络结构进行训练,预测未评分项目的分值,直到矩阵的稀疏度达到某一数值;
步骤4)按照相关相似性求ri的最近k邻居,得到最近邻居集合t={t1,t2,…,tk};
步骤5)采用预测公式对候选项目集合t′的所有候选项目评分预测,按照分值高低进行排序;
步骤6)选出前n项,形成top-n推荐列表。
算法改进思想是通过选用svd分解用户-项目评分矩阵,这样做可以缓解矩阵的稀疏度;同时在奇异值分解的基础上,进一步选用bp神经网络来对未评分的目标项目进行分值预测,这样做的好处是避免了用平均分值代替而产生的效果单一性,从而使准确性有了较大提高。采用相关相似性公式来计算用户之间的相似性,获取用户最近k邻居。算法的改进核心思想是将评分矩阵降维,有效的缓解数据稀疏性,使得推荐准确率更高。
选用svd分解评分矩阵基于两个方面:一方面是奇异值分解在矩阵降维上有着较大的优势,在不失矩阵重要特征值的情况下降低矩阵的维度,能够简单快速的获取用户偏好的特征向量;另一方面用户-项目矩阵的维度降低使得电子商务推荐系统的计算减少,降低系统开销。
选用bp神经网络对未评分商品预测基于两个方面:一方面是bp神经网络可以通过训练得到稳定的网络结构,不断学习,不断进化;另一方面商品的数量不计其数,很多时候形成的用户评分矩阵中没有被评价的商品占据了绝大多数,这样在计算邻居的时候会存在很大误差,而bp神经网络能够对没有评分的商品进行预测用户偏好,很方便的解决了未知商品没有评分的问题。
- 还没有人留言评论。精彩留言会获得点赞!