双向语音翻译系统、双向语音翻译方法和程序与流程
本公开涉及双向语音翻译系统,双向语音翻译方法和程序。
背景技术:
专利文献1描述了具有增强的单手的可操作性的翻译器。专利文献1中描述的翻译器将包括输入声学模型、语言模型和输出声学模型的翻译程序和翻译数据存储在包括在设置在壳体上的翻译单元中的存储器中。
在专利文献1中描述的翻译器中,包括在翻译单元中的处理单元使用输入声学模型和语言模型,将通过麦克风接收到的第一语言的语音转换为第一语言的文本信息。处理单元使用翻译模型和语言模型将第一语言的文本信息翻译或转换为第二语言的文本信息。处理单元使用输出声学模型将第二语言的文本信息转换为语音,并且通过扬声器输出第二语言的语音。
专利文献1中描述的翻译器对每个翻译器预先确定第一语言和第二语言的组合。
引文列表
专利文献
专利文献1:jp2017-151619a
技术实现要素:
技术问题
然而,在讲第一语言的第一说话者和讲第二语言的第二说话者之间的双向对话中,在专利文献1中描述的翻译器不能顺利地交替将第一说话者的语音翻译成第二语言并且将第二说话者的语音翻译成第一语言。
专利文献1中描述的翻译器使用存储的给定翻译数据来翻译任何接收到的语音。因此,例如,即使存在更适用于翻译前语言或翻译后语言的语音识别引擎或翻译引擎,也不可能使用这样的引擎执行语音识别或翻译。此外,例如,即使存在适于再现诸如年龄和性别的说话者属性的翻译引擎或语音合成引擎,也不可能使用这样的引擎执行翻译或语音合成。
鉴于上述情况做出了本公开,并且本公开的目的是提供一种双向语音翻译系统、双向语音翻译方法和程序,其通过使用适合于接收的语音或该语音的语言的语音识别引擎、翻译引擎和语音合成引擎的组合,来执行语音翻译。
解决问题的方案
为了解决上述问题,根据本公开的双向语音翻译系统,执行用于响应于由第一说话者输入第一语言语音,通过将第一语言语音翻译成第二语言来合成语音的处理、以及用于响应于第二说话者输入第二语言语音,通过将第二语言语音翻译成第一语言来合成语音的处理。所述双向语音翻译系统包括:第一确定单元,其基于第一语言、第一说话者输入的第一语言语音、第二语言、和第二说话者输入的第二语言语音中的至少一个,确定第一语音识别引擎、第一翻译引擎、和第一语音合成引擎的组合,第一语音识别引擎是多个语音识别引擎的一个,第一翻译引擎是多个翻译引擎的一个,第一语音合成引擎是多个语音合成引擎的一个;第一语音识别单元,其响应于由第一说话者输入第一语言语音,执行由第一语音识别引擎实现的语音识别处理,以生成作为第一语言语音的识别结果的文本;第一翻译单元,其执行由第一翻译引擎实现的翻译处理,以通过将由第一语音识别单元生成的文本翻译成第二语言来生成文本;第一语音合成单元,其执行由第一语音合成引擎实现的语音合成处理,以合成表示由第一翻译单元翻译的文本的语音;第二确定单元,其基于第一语言、第一说话者输入的第一语言语音、第二语言、和第二说话者输入的第二语言语音中的至少一个,确定第二语音识别引擎、第二翻译引擎、和第二语音合成引擎的组合,第二语音识别引擎是多个语音识别引擎的一个,第二翻译引擎是多个翻译引擎的一个,第二语音合成引擎是多个语音合成引擎的一个;第二语音识别单元,其响应于由第二说话者输入第二语言语音,执行由第二语音识别引擎实现的语音识别处理,以生成作为第二语言语音的识别结果的文本;第二翻译单元,其执行由第二翻译引擎实现的翻译处理,以通过将由第二语音识别单元生成的文本翻译成第一语言来生成文本;以及第二语音合成单元,其执行由第二语音合成引擎实现的语音合成处理,以合成表示由第二翻译单元翻译的文本的语音。
在本公开的一个方面中,第一语音合成单元根据基于由第一说话者输入的语音的特征量估计的第一说话者的年龄、世代、和性别中的至少一个来合成语音。
在本公开的一个方面中,第一语音合成单元根据基于由第一说话者输入的语音的特征量估计的第一说话者的情绪来合成语音。
在本公开的一个方面中,第二语音合成单元根据基于由第一说话者输入的语音的特征量估计的第一说话者的年龄、世代、和性别中的至少一个来合成语音。
在本公开的一个方面中,第二翻译单元,确定包括在由第二语音识别单元生成的文本中的翻译目标词的多个翻译候选,检查多个翻译候选以查看每个翻译候选是否被包括在由第一翻译单元生成的文本中,以及将翻译目标词翻译成被确定为包括在由第一翻译单元生成的文本中的词。
在本公开的一个方面中,第一语音合成单元合成具有根据第一说话者的第一语言语音的输入速度的速度的语音,或具有根据第一说话者的第一语言语音的音量的音量的语音。
在本公开的一个方面中,第二语音合成单元合成具有根据第一说话者的第一语言语音的输入速度的速度的语音,或具有根据第一说话者的第一语言语音的音量的音量的语音。
在本公开的一个方面中,双向语音翻译系统包括终端,该终端接收由第一说话者进行的第一语言语音的输入,输出通过将第一语言语音翻译成第二语言获得的语音,接收由第二说话者进行的第二语言语音的输入,并输出通过将第二语言翻译成第一语言获得的语音。第一确定单元基于终端的位置确定第一语音识别引擎、第一翻译引擎、和第一语音合成引擎的组合。第二确定单元基于终端的位置确定第二语音识别引擎、第二翻译引擎、和第二语音合成引擎的组合。
根据本公开的双向语音翻译方法,执行用于响应于由第一说话者输入第一语言语音,通过将第一语言语音翻译成第二语言来合成语音的处理、以及用于响应于第二说话者输入第二语言语音,通过将第二语言语音翻译成第一语言来合成语音的处理。所述双向语音翻译方法包括:第一确定步骤,其基于第一语言、第一说话者输入的第一语言语音、第二语言、和第二说话者输入的第二语言语音中的至少一个,确定第一语音识别引擎、第一翻译引擎、和第一语音合成引擎的组合,第一语音识别引擎是多个语音识别引擎的一个,第一翻译引擎是多个翻译引擎的一个,第一语音合成引擎是多个语音合成引擎的一个;第一语音识别步骤,其响应于由第一说话者输入第一语言语音,执行由第一语音识别引擎实现的语音识别处理,以生成作为第一语言语音的识别结果的文本;第一翻译步骤,其执行由第一翻译引擎实现的翻译处理,以通过将在第一语音识别步骤中生成的文本翻译成第二语言来生成文本;第一语音合成步骤,其执行由第一语音合成引擎实现的语音合成处理,以合成表示在第一翻译步骤中翻译的文本的语音;第二确定步骤,其基于第一语言、第一说话者输入的第一语言语音、第二语言、和第二说话者输入的第二语言语音中的至少一个,确定第二语音识别引擎、第二翻译引擎、和第二语音合成引擎的组合,第二语音识别引擎是多个语音识别引擎的一个,第二翻译引擎是多个翻译引擎的一个,第二语音合成引擎是多个语音合成引擎的一个;第二语音识别步骤,其响应于由第二说话者输入第二语言语音,执行由第二语音识别引擎实现的语音识别处理,以生成作为第二语言语音的识别结果的文本;第二翻译步骤,其执行由第二翻译引擎实现的翻译处理,以通过将在第二语音识别步骤中生成的文本翻译成第一语言来生成文本;以及第二语音合成步骤,其执行由第二语音合成引擎实现的语音合成处理,以合成表示在第二翻译步骤中翻译的文本的语音。
根据本公开的程序,使计算机执行用于响应于由第一说话者输入第一语言语音,通过将第一语言语音翻译成第二语言来合成语音的处理、以及用于响应于第二说话者输入第二语言语音,通过将第二语言语音翻译成第一语言来合成语音的处理。所述程序使所述计算机执行:第一确定处理,其基于第一语言、第一说话者输入的第一语言语音、第二语言、和第二说话者输入的第二语言语音中的至少一个,确定第一语音识别引擎、第一翻译引擎、和第一语音合成引擎的组合,第一语音识别引擎是多个语音识别引擎的一个,第一翻译引擎是多个翻译引擎的一个,第一语音合成引擎是多个语音合成引擎的一个;第一语音识别处理,其响应于由第一说话者输入第一语言语音,执行由第一语音识别引擎实现的语音识别处理,以生成作为第一语言语音的识别结果的文本;第一翻译处理,其执行由第一翻译引擎实现的翻译处理,以通过将在第一语音识别处理中生成的文本翻译成第二语言来生成文本;第一语音合成处理,其执行由第一语音合成引擎实现的语音合成处理,以合成表示在第一翻译处理中翻译的文本的语音;第二确定处理,其基于第一语言、第一说话者输入的第一语言语音、第二语言、和第二说话者输入的第二语言语音中的至少一个,确定第二语音识别引擎、第二翻译引擎、和第二语音合成引擎的组合,第二语音识别引擎是多个语音识别引擎的一个,第二翻译引擎是多个翻译引擎的一个,第二语音合成引擎是多个语音合成引擎的一个;第二语音识别处理,其响应于由第二说话者输入第二语言语音,执行由第二语音识别引擎实现的语音识别处理,以生成作为第二语言语音的识别结果的文本;第二翻译处理,其执行由第二翻译引擎实现的翻译处理,以通过将在第二语音识别处理中生成的文本翻译成第一语言来生成文本;以及第二语音合成处理,其执行由第二语音合成引擎实现的语音合成处理,以合成表示在第二翻译处理中翻译的文本的语音。
附图说明
图1是示出了根据本公开的实施例的翻译系统的整体配置的示例的图;
图2是示出了根据本公开的实施例的翻译终端的配置的示例的图;
图3是示出了根据本公开的实施例的在服务器中实现的功能的示例的功能框图;
图4a是表示分析对象数据的示例的图;
图4b是表示分析对象数据的示例的图;
图5a是表示日志数据的示例的图;
图5b是表示日志数据的示例的图;
图6是表示语言引擎对应管理数据的示例的图;
图7是表示属性引擎对应管理数据的示例的图;
图8是示出了根据本公开的实施例的在服务器中执行的处理的示例的流程图。
具体实施方式
以下将参考附图描述本公开的实施例。
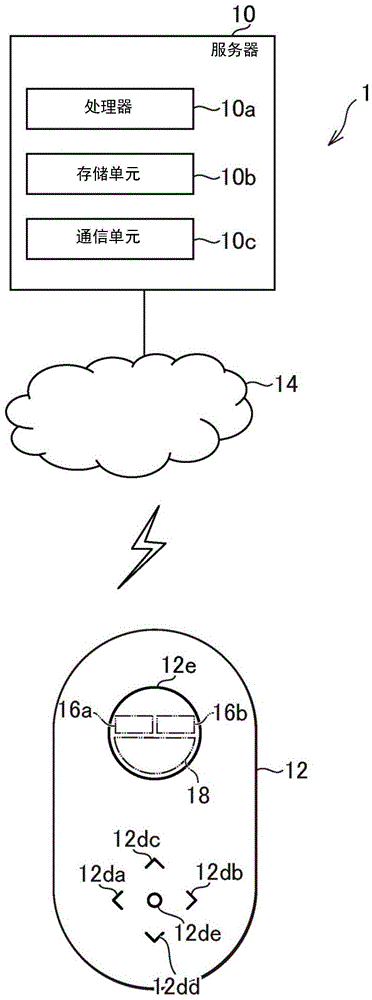
图1示出作为本公开中提出的双向语音翻译系统的示例的翻译系统1的整体配置的示例。如图1所示,本公开中提出的翻译系统1包括服务器10和翻译终端12。服务器10和翻译终端12连接到诸如因特网的计算机网络14。服务器10和翻译终端12因此可以经由诸如因特网的计算机网络14彼此进行通信。
如图1所示,根据本实施例的服务器10包括例如处理器10a,存储单元10b和通信单元10c。
处理器10a是程序控制装置,例如根据安装在服务器10中的程序进行操作的微处理器。存储单元10b是例如诸如rom和ram,的存储元件或硬盘驱动器。例如,存储单元10b存储由处理器10a执行的程序。例如,通信单元10c是用于经由计算机网络14向/从翻译终端12发送/接收数据的通信接口,例如网络板。服务器10经由通信单元10c向翻译终端12发送数据/从翻译终端12接收数据。
图2图示了在图1中示出的翻译终端12的配置的示例。如图2所示,根据本实施例的翻译终端12包括:例如,处理器12a、存储单元12b、通信单元12c、操作部12d、显示部12e、麦克风12f和扬声器12g。
处理器12a是例如程序控制装置,诸如根据安装在翻译终端12中的程序进行操作的微处理器。存储单元12b是诸如rom和ram的存储元件。存储单元12b存储由处理器12a执行的程序。
例如,通信单元12c是用于经由计算机网络14向/从服务器10发送/接收数据的通信接口。通信单元12c可以包括诸如3g模块的无线通信模块,用于通过包括基站的移动电话线路与诸如因特网的计算机网络14进行通信。通信单元12c可以包括无线lan模块,用于经由例如wi-fi(注册商标)路由器与诸如因特网的计算机网络14进行通信。
例如,操作部12d是将用户的操作输出到处理器12a的操作部件。如图1所示,本实施例的翻译终端12在其下前侧具有5个操作部12d(12da,12db,12dc,12dd,12de)。操作部12da,操作部12db,操作部12dc,操作部12dd以及操作部12de分别相对设置在翻译终端12的下前部的左侧、右侧、上侧、下侧和中央。操作部12d在这里被描述为触摸传感器,但是操作部12d可以是除了触摸传感器之外的诸如按钮的操作部件。
例如,显示部12e包括诸如液晶显示器、有机el显示器的显示器,显示由处理器12a生成的图像。如图1所示,根据本实施例的翻译终端12在其上前侧具有圆形显示部12e。
例如,麦克风12f是将接收到的语音转换为电信号的语音输入装置。麦克风12f可以是具有噪声消除功能的双麦克风,其被嵌入在翻译终端12中并且即使在人群中也有利于识别人类语音。
例如,扬声器12g是输出语音的音频输出装置。扬声器12g可以是嵌入在翻译终端12中的动态扬声器,并且可以用在嘈杂的环境中。
根据本实施例的翻译系统1可以在第一说话者和第二说话者之间的双向会话中交替地翻译第一说话者的语音和第二说话者的语音。
在根据本实施例的翻译终端12中,对单元12d执行预定操作以设置语言,从而从例如五十个给定的语言中确定第一说话者的语音的语言和第二说话者的语音的语言。在下文中,第一说话者的语音被称为第一语言,而第二说话者的语音被称为第二语言。在本实施例中,例如,显示部12e的左上方的第一语言显示区域16a显示表示第一语言的图像,诸如使用第一语言的国家的国旗的图像。此外,在本实施例中,例如,显示部分12e的右上方的第二语言显示区域16b显示使用第二语言的国家的国旗。
例如,假定第一说话者执行语音输入操作,其中第一说话者在翻译终端12中以第一语言输入语音。例如,第一说话者的语音输入操作可以是一系列操作,包括:第一说话者敲击操作部12da、在敲击操作部12da的同时输入第一语言的语音、和释放操作部12da的敲击状态。
随后,设置在显示部12e下方的文本显示区域18显示文本,该文本是由第一说话者输入的语音的语音识别结果。根据本实施例的文本是表示一个或多个从句、短语、词或句子的字符串。之后,文本显示区域18显示将显示的文本翻译成第二语言而获得的文本,并且扬声器12g输出表示翻译后文本的语音,即将由第一说话者输入的第一语言的语音翻译成第二语言所得到的语音。
随后,例如,假定第二说话者在翻译终端12中执行第二说话者以第二语言输入语音的语音输入操作。例如,第二说话者的语音输入操作可以是一系列操作,包括:第二说话者敲击操作部12db、在敲击操作部12db的同时输入第二语言的语音、和释放操作部12db的敲击状态。
随后,设置在显示部12e下方的文本显示区域18显示文本,该文本是由第二说话者输入的语音的语音识别结果。之后,文本显示区域18显示将显示的文本翻译成第一语言而获得的文本,并且扬声器12g输出表示翻译后文本的语音,即,将由第二说话者输入的第二语言的语音翻译成第一语言所得到的语音。
随后,在根据本实施例的翻译系统1中,每当交替执行第一说话者的语音输入操作和第二说话者的语音输入操作时,输出通过将输入的语音翻译成另一种语言而获得的语音。
以下将描述根据本实施例的服务器10中执行的功能和处理。
根据本实施例的服务器10执行用于响应于由第一说话者输入第一语言的语音,通过将输入的语音翻译成第二语言来合成语音的处理,以及用于响应于第二说话者以第二语言输入语音,通过将输入的语音翻译成第一语言来合成语音的处理。
图3是示出根据本实施例的在服务器10中实现的功能的示例的功能框图。根据该实施例的服务器10不一定要实现在图3中示出的所有功能,并且可以实现除了在图3中示出的功能之外的功能。
如图3所示,根据本实施例的服务器10在功能上包括:例如,语音数据接收单元20、多个语音识别引擎22、语音识别单元24、翻译前文本数据发送单元26、多个翻译引擎28、翻译单元30、翻译后文本数据发送单元32、多个语音合成引擎34、语音合成单元36、语音数据发送单元38、日志数据生成单元40、日志数据存储单元42、分析单元44、引擎确定单元46、和对应管理数据存储单元48。
语音识别引擎22、翻译引擎28、和语音合成引擎34主要由处理器10a和存储单元10b实现。语音数据接收单元20、翻译前文本数据发送单元26、翻译后文本数据发送单元32、和语音数据发送单元38主要由通信单元10c实现。语音识别单元24、翻译单元30、语音合成单元36、日志数据生成单元40、分析单元44、和引擎确定单元46主要由处理器10a实现。日志数据存储单元42和对应管理数据存储单元48主要由存储单元10b实现。
当处理器10a执行安装在是计算机的服务器10中并且包含对应于这些功能的命令的程序时,实现上述功能。该程序经由因特网或诸如光盘、磁盘、磁带、磁光盘和闪存的计算机可读信息存储介质提供给服务器10。
在根据本实施例的翻译系统1中,当由说话者执行语音输入操作时,翻译终端12生成在图4a和图4b中示出的分析目标数据。翻译终端12然后将生成的分析目标数据发送到服务器10。图4a示出了当第一说话者执行语音输入操作时生成的分析目标数据的示例。图4b示出了当第二说话者执行语音输入操作时生成的分析目标数据的示例。图4a和图4b示出了当第一语言是日语并且第二语言是英语时的分析目标数据的示例。
如图4a和图4b所示,分析目标数据包括翻译前语音数据和元数据。
例如,翻译前语音数据是表示通过麦克风12f输入的说话者的语音的语音数据。这里,翻译前语音数据例如可以是通过对通过麦克风12f输入的语音进行编码和量化而生成的语音数据。
例如,元数据包括终端id、输入id、说话者id、时间数据、翻译前语言数据、和翻译后语言数据。
例如,终端id是翻译终端12的标识信息。在该实施例中,例如,向用户提供的每个翻译终端12被分配唯一的终端id。
例如,输入id是通过单个语音输入操作输入的语音的标识信息。在该实施例中,输入id例如是分析目标数据的标识信息。在该实施例中,根据在翻译终端12中执行的语音输入操作的顺序来分配输入id的值。
例如,说话者id是说话者的标识信息。在本实施例中,例如,当第一说话者进行语音输入操作时,将1设置为说话者id的值,并且当第二说话者进行语音输入操作时,将2设置为说话者id的值。
例如,时间数据表示进行语音输入操作的时间。
例如,翻译前语言数据表示由说话者输入的语音的语言。在下文中,说话者输入的语音的语言被称为翻译前语言。例如,当第一说话者进行语音输入操作时,表示被设置为第一语言的语言的值被设置为翻译前语言数据的值。例如,当第二说话者进行语音输入操作时,表示被设置为第二语言的语言的值被设置为翻译前语言数据的值。
翻译后语言数据表示例如作为由会话伙伴(即,执行语音输入操作的说话者的听众)捕获的语音的语言被设置的语言。在下文中,被听众捕获的语音的语言被称为翻译后语言。例如,当第一说话者进行语音输入操作时,表示被设置为第二语言的语言的值被设置为翻译后语言数据的值。例如,当第二说话者进行语音输入操作时,表示被设置为第一语言的语言的值被设置为翻译后语言数据的值。
在本实施例中,语音数据接收单元20例如接收表示在翻译终端12中输入的语音的语音数据。这里,语音数据接收单元20可以接收分析目标数据,其包括表示如上所述输入到翻译终端12中的语音的语音数据作为翻译前语音数据。
在该实施例中,每个语音识别引擎22是其中例如执行用于生成作为语音的识别结果的文本的语音识别处理的程序。语音识别引擎22具有不同的规格,诸如可识别的语言。在本实施例中,例如,每个语音识别引擎22被预先分配有语音识别引擎id,语音识别引擎id是对应的语音识别引擎22的标识信息。
在本实施例中,例如,响应于由说话者输入语音,语音识别单元24生成文本,该文本是语音的识别结果。语音识别单元24可以生成文本,该文本是由语音数据接收单元20接收的语音数据所表示的语音的识别结果。
语音识别单元24可以执行语音识别处理,该语音识别处理由稍后描述的引擎确定单元46确定的语音识别引擎22执行,以生成作为语音的识别结果的文本。例如,语音识别单元24可以调用由引擎确定单元46确定的语音识别引擎22,使语音识别引擎22执行语音识别处理,并且从语音识别引擎22接收作为语音识别处理的结果的文本。
以下,响应于第一说话者的语音输入操作而由引擎确定单元46确定的语音识别引擎22被称为第一语音识别引擎22。此外,响应于第二说话者的语音输入操作而由引擎确定单元46确定的语音识别引擎22被称为第二语音识别引擎22。
在该实施例中,例如,翻译前文本数据发送单元26将表示由语音识别单元24生成的文本的翻译前文本数据发送到翻译终端12。例如,当从翻译前文本数据发送单元26接收到由接收翻译前文本数据表示的文本时,翻译终端12如上所述在文本显示区域18上显示文本。
在该实施例中,例如,每个翻译引擎28是其中执行翻译文本的翻译处理的程序。翻译引擎28具有不同的规格,诸如可翻译的语言和用于翻译的字典。在该实施例中,例如,每个翻译引擎28被预先分配有翻译引擎id,其是对应的翻译引擎28的标识信息。
在该实施例中,例如,翻译单元30通过翻译由语音识别单元24生成的文本来生成文本。翻译单元30可以执行由稍后描述的引擎确定单元46确定的翻译引擎28实现的翻译处理,并且通过翻译由语音识别单元24生成的文本来生成文本。例如,翻译单元30可以调用由引擎确定单元46确定的翻译引擎28,使翻译引擎28执行翻译处理,并从翻译引擎28接收作为翻译处理的结果的文本。
在下文中,响应于第一说话者的语音输入操作而由引擎确定单元46确定的翻译引擎28被称为第一翻译引擎28。此外,响应于第二说话者的语音输入操作而由引擎确定单元46确定的翻译引擎28被称为第二翻译引擎28。
在该实施例中,例如,翻译后文本数据发送单元32将表示由翻译单元30翻译的文本的翻译后文本数据发送到翻译终端12。例如,当从翻译后文本数据发送单元32接收到翻译后文本数据所表示的文本时,翻译终端12如上所述在文本显示区域18上显示文本。
在本实施例中,例如,每个语音合成引擎34是其中实现用于合成表示文本的语音的语音合成处理的程序。语音合成引擎34具有不同的规格,例如要合成的语音的音调或类型。在该实施例中,例如,每个语音合成引擎34被预先分配有语音合成引擎id,其是用于对应的语音合成引擎34的标识信息。
在该实施例中,例如,语音合成单元36合成表示由翻译单元30翻译的文本的语音。语音合成单元36可以生成翻译后的语音数据,翻译后的语音数据是通过合成表示由翻译单元30翻译的文本的语音而获得的语音数据。语音合成单元36可以执行由稍后描述的引擎确定单元46确定的语音合成引擎34实现的语音合成处理,并且合成表示由翻译单元30翻译的文本的语音。例如,语音合成单元36可以调用由引擎确定单元46确定的语音合成引擎34,使得语音合成引擎34执行语音合成处理,并且从语音合成引擎34接收作为语音合成处理的结果的语音数据。
在下文中,响应于第一说话者的语音输入操作而由引擎确定单元46确定的语音合成引擎34被称为第一语音合成引擎34。此外,响应于第二说话者的语音输入操作而由引擎确定单元46确定的语音合成引擎34被称为第二语音合成引擎34。
在该实施例中,例如,语音数据发送单元38将表示由语音合成单元36合成的语音的语音数据发送到翻译终端12。在从语音数据发送单元38接收到翻译后的语音数据时,翻译终端12例如如上所述将由翻译后的语音数据表示的语音输出到扬声器12g。
在本实施例中,例如,日志数据生成单元40生成如图5a和图5b所示的表示关于说话者的语音的翻译的日志的日志数据,并且将该日志数据存储在日志数据存储单元42中。
图5a示出了响应于第一说话者的语音输入操作而生成的日志数据的例子。图5b示出了响应于第二说话者的语音输入操作而生成的日志数据的例子。
日志数据例如包括终端id、输入id、说话者id、时间数据、翻译前文本数据、翻译后文本数据、翻译前语言数据、翻译后语言数据、年龄数据、性别数据、情绪数据、主题数据、和场景数据。
例如,由语音数据接收单元20接收的分析目标数据中包括的元数据的终端id、输入id、和说话者id的值可以分别被设置为要生成的日志数据的终端id、输入id、和说话者id的值。例如,可以将语音数据接收单元20接收到的分析目标数据中包括的元数据的时间数据的值设置为要生成的日志数据的时间数据的值。例如,由语音数据接收单元20接收的分析目标数据中包括的元数据的翻译前语言数据和翻译后语言数据的值可以被设置为包括在要生成的日志数据中的翻译前语言数据和翻译后语言的值。
例如,执行语音输入操作的说话者的年龄或世代的值可以被设置为包括在要产生的日志数据中的年龄数据的值。例如,表示进行语音输入操作的说话者的性别的值可以被设置为包括在将要生成的日志数据中的性别数据的值。例如,表示进行语音输入操作的说话者的情绪的值可以被设置为包括在要生成的日志数据中的情绪数据的值。例如,当执行语音输入操作时,表示诸如医学、军事、it和旅行的会话的主题(类型)的值可以被设置为包括在要生成的日志数据中的主题数据的值。例如,当执行语音输入操作时,表示诸如会议、商务谈话、聊天和演讲的会话场景的值可以被设置为包括在将要生成的日志数据中的场景数据的值。
如稍后讨论的,分析单元44可以对由语音数据接收单元20接收的语音数据执行分析处理。然后,可以将与分析处理的结果相对应的值设置为包括在要生成的日志数据中的年龄数据、性别数据、情绪数据、主题数据、和场景数据的值。
例如,表示由语音数据接收单元20接收到的语音数据的由语音识别单元24的语音识别结果的文本可以被设置为包括在要生成的日志数据中的翻译前文本数据的值。例如,表示由翻译单元30翻译文本的结果的文本可以被设置为包括在要生成的日志数据中的翻译后文本数据的值。
尽管未在图5a和图5b中示出,但是日志数据可以附加地包括数据,例如表示进行语音输入操作的说话者的语音的输入速度的输入速度数据、表示语音的音量的音量数据、和表示语音的音调或类型的声音类型数据。
在本实施例中,例如,日志数据存储单元42存储由日志数据生成单元40生成的日志数据。以下,存储在日志数据存储单元42中并且包括具有与由语音数据接收单元20接收到的分析目标数据中包括的元数据的终端id的值相同的值的终端id的日志数据,将被称为终端日志数据。
可以预先确定存储在日志数据存储单元42中的终端日志数据的记录的最大数量。例如,对于某个终端id,可以在日志数据存储单元42中存储最多20个终端日志数据的记录。如上所述,在日志数据存储单元42中存储了最大数量的终端日志数据的记录的情况下,在将终端日志数据的新记录存储在日志数据存储单元42中时,日志数据生成单元40可以删除包括表示最早时间的时间数据的终端日志数据的记录。
在该实施例中,例如,分析单元44对由语音数据接收单元20接收的语音数据和作为翻译单元30的翻译结果的文本执行分析处理。
例如,分析单元44可以生成由语音数据接收单元20接收的语音数据所表示的语音的特征量的数据。特征量的数据可以包括例如基于频谱包络的数据、基于线性预测分析的数据、诸如倒谱的关于声道的数据、诸如基频和有声/无声判定信息的关于声源的数据、和频谱图。
在该实施例中,例如,分析单元44可以执行分析处理,诸如已知的声纹分析处理,从而估计执行语音输入操作的说话者的属性,诸如说话者的年龄、世代、和性别。例如,可以基于由语音数据接收单元20接收到的语音数据表示的语音的特征量的数据来估计执行语音输入操作的说话者的属性。
例如,分析单元44可以基于作为翻译单元30的翻译结果的文本来估计执行语音输入操作的说话者的属性,诸如年龄、世代、和性别。例如,使用已知的文本分析处理,可以基于作为翻译结果的文本中包括的词来估计执行语音输入操作的说话者的属性。这里,如上所述,日志数据生成单元40可以将表示估计的说话者的年龄或世代的值设置为包括在要生成的日志数据中的年龄数据的值。此外,如上所述,日志数据生成单元40可以将估计的说话者的性别的值设置为包括在要生成的日志数据中的性别数据的值。
在该实施例中,例如,分析单元44执行分析处理,例如已知的语音情绪分析处理,从而估计进行语音输入操作的说话者的情绪(例如愤怒、喜悦、和平静)。例如,可以基于由语音数据接收单元20接收的语音数据表示的语音的特征量的数据来估计输入语音的说话者的情绪。如上所述,日志数据生成单元40可以将表示说话者的估计的情绪的值设置为包括在要生成的日志数据中的情绪数据的值。
分析单元44可以指定例如由语音数据接收单元20接收到的语音数据所表示的语音的输入速度和音量。此外,分析单元44可以例如指定由语音数据接收单元20接收的语音数据表示的语音的声调或类型。日志数据生成单元40可以将表示估计的语音输入速度、音量、和语音的声调或类型的值设置为包括在要生成的日志数据中的输入速度数据、音量数据、和声音类型数据的各个值。
例如,分析单元44可以估计进行语音输入操作时的会话主题或场景。这里,分析单元44可以基于例如由语音识别单元24生成的文本或包括在文本中的词来估计主题或场景。
当估计主题和场景时,分析单元44可以基于终端日志数据来估计它们。例如,可以基于由包含在终端日志数据中的翻译前文本数据表示的文本或包含在文本中的词,或者由翻译后文本数据表示的文本或包含在文本中的词,估计主题和场景。话题和场景可以基于由语音识别单元24生成的文本和终端日志数据来估计。这里,日志数据生成单元40可以将表示估计的主题和场景的值设置为包括在要生成的日志数据中的主题数据和场景数据的值。
在该实施例中,例如,引擎确定单元46确定用于执行语音识别处理的语音识别引擎22、用于执行翻译处理的翻译引擎28、和用于执行语音合成处理的语音合成引擎34的组合。如上所述,引擎确定单元46可根据第一说话者的语音输入操作确定第一语音识别引擎22、第一翻译引擎28、和第一语音合成引擎34的组合。引擎确定单元46可根据第二说话者的语音输入操作确定第二语音识别引擎22、第二翻译引擎28、和第二语音合成引擎34的组合。例如,可以基于第一语言、由第一说话者输入的语音、第二语言、和由第二说话者输入的语音中的至少一个来确定组合。
如上所述,语音识别单元24可响应于第一说话者以第一语言输入语音,执行由第一语音识别引擎22实现的语音识别处理,从而以第一语言生成文本,这是识别语音的结果。翻译单元30可以执行由第一翻译引擎28实现的翻译处理,以通过翻译由语音识别单元24生成的第一语言的文本,生成第二语言的文本。语音合成单元36可以执行由第一语音合成引擎34实现的语音合成处理,以合成表示由翻译单元30以第二语言翻译的文本的语音。
语音识别单元24可以响应于第二说话者以第二语言输入语音,执行由第二语音识别引擎22实现的语音识别处理,以生成文本,该文本是第二语言的语音的识别结果。翻译单元30可以执行由第二翻译引擎28执行的翻译处理,以通过翻译由语音识别单元24生成的第二语言的文本,生成第一语言的文本。语音合成单元36可以执行由第一语音合成引擎34实现的语音合成处理,以合成表示由翻译单元30以第一语言翻译后文本的语音。
例如,当第一说话者输入语音时,引擎确定单元46可以基于翻译前语言和翻译后语言的组合来确定第一语音识别引擎22、第一翻译引擎28、和第一语音合成引擎34的组合。
这里,例如,当第一讲话者输入语音时,引擎确定单元46可基于图6所示的语言引擎对应管理数据确定第一语音识别引擎22、第一翻译引擎28、和第一语音合成引擎34的组合。
如图6所示,语言引擎对应管理数据包括:翻译前语言数据、翻译后语言数据、语音识别引擎id、翻译引擎id、和语音合成引擎id。图6示出了语言引擎对应管理数据的多个记录。例如,可以在语言引擎对应管理数据中预先设置适用于翻译前语言和翻译后语言的组合的语音识别引擎22、翻译引擎28、和语音合成引擎34。语言引擎对应管理数据可以预先存储在对应管理数据存储单元48中。
这里,例如,可以预先指定语音识别引擎22的语音识别引擎id,该语音识别引擎22能够对由翻译前语言数据的值表示的语言的语音进行语音识别处理。或者,可以预先指定具有识别语音的最高准确度的语音识别引擎22的语音识别引擎id。然后可以将指定的语音识别引擎id设置为与语言引擎对应管理数据中的翻译前语言数据相关联的语音识别引擎id。
例如,引擎确定单元46可以指定当第一说话者输入语音时由语音数据接收单元20接收到的分析目标数据中包括的元数据的翻译前语言数据的值和翻译后语言数据的值的组合。引擎确定单元46然后可以指定具有翻译前语言数据的值和翻译后语言数据的值的相同组合的语言引擎对应管理数据的记录作为指定组合。引擎确定单元46可以指定包括在语言引擎对应管理数据的指定记录中的语音识别引擎id、翻译引擎id、和语音合成引擎id的组合。
引擎确定单元46可以指定具有相同组合的翻译前语言数据的值和翻译后语言数据的值的语言引擎对应管理数据的多个记录作为指定组合。在这种情况下,例如,引擎确定单元46可以基于给定的标准指定包括在语言引擎对应管理数据的任何一个记录中的语音识别引擎id、翻译引擎id、和语音合成引擎id的组合。
引擎确定单元46可以确定由包括在指定组合中的语音识别引擎id所标识的语音识别引擎22作为第一语音识别引擎22。引擎确定单元46可以确定由包括在所确定的组合中的翻译引擎id所标识的翻译引擎28作为第一翻译引擎28。引擎确定单元46可以将由所确定的组合中包括的语音合成引擎id所标识的语音合成引擎34确定为第一语音合成引擎34。
类似地,当第二说话者输入语音时,引擎确定单元46可以基于翻译前语言和翻译后语言的组合,来确定第二语音识别引擎22、第二翻译引擎28、和第二语音合成引擎34的组合。
以这种方式,可以根据翻译前语言和翻译后语言的组合,使用语音识别引擎22、翻译引擎28、和语音合成引擎34的适当组合来执行语音翻译。
引擎确定单元46可以仅基于翻译前语言来确定第一语音识别引擎22或第二语音识别引擎22。
这里,分析单元44可以分析由语音数据接收单元20接收的分析目标数据中包括的翻译前语音数据,以指定由翻译前语音数据表示的语音的语言。然后引擎确定单元46可以基于由分析单元44指定的语言来确定语音识别引擎22和翻译引擎28中的至少一个。
引擎确定单元46可以基于例如当语音输入时翻译终端12的位置来确定语音识别引擎22、翻译引擎28、和语音合成引擎34中的至少一个。这里,例如,可以基于翻译终端12所在的国家来确定语音识别引擎22、翻译引擎28、和语音合成引擎34中的至少一个。例如,当由引擎确定单元46确定的翻译引擎28在翻译终端12所在的国家中不可用时,执行翻译处理的翻译引擎28可以从剩余的翻译引擎28中确定。在这种情况下,例如,可以基于包括表示国家的国家数据的语言引擎对应管理数据来确定语音识别引擎22、翻译引擎28、和语音合成引擎34中的至少一个。
可以基于从翻译终端12发送的分析目标数据的头部的ip地址来指定翻译终端12的位置。例如,如果翻译终端12包括gps模块,则翻译终端12可以向服务器10发送包括表示诸如由gps模块测量的纬度和经度的翻译终端12的位置的数据作为元数据的分析目标数据。然后可以基于表示包括在元数据中的位置的数据来指定翻译终端12的位置。
引擎确定单元46可以基于例如由分析单元44估计的主题或场景来确定执行翻译处理的翻译引擎28。这里,引擎确定单元46可以基于例如包括在终端日志数据中的主题数据的值或场景数据的值来确定执行翻译处理的翻译引擎28。在这种情况下,例如,可以基于包括表示主题的主题数据和表示场景的场景数据的属性引擎对应管理数据来确定执行翻译处理的翻译引擎28。
例如,当第一说话者输入语音时,引擎确定单元46可以基于第一说话者的属性确定第一翻译引擎28和第一语音合成引擎34的组合。
这里,例如,引擎确定单元46可以基于在图7中示出的属性引擎对应管理数据来确定第一翻译引擎28和第一语音合成引擎34的组合。
图7示出了其中翻译前语言是日语并且翻译后语言是英语的属性引擎对应管理数据的示例。如图7所示,属性引擎对应管理数据包括年龄数据、性别数据、翻译引擎id、和语音合成引擎id。可以在属性引擎对应管理数据中预先设置用于再现诸如说话者的年龄、世代、和性别的说话者的属性的翻译引擎28和语音合成引擎34的适当组合。属性引擎对应管理数据可以预先存储在对应管理数据存储单元48中。
例如,可以预先指定能够再现诸如由年龄数据表示的年龄或世代和由性别数据表示的性别的讲话者属性的翻译引擎28。或者,可以预先指定具有讲话者属性再现的最高准确度的翻译引擎28的翻译引擎id。指定的翻译引擎id可以被设置为与属性引擎对应管理数据中的年龄数据和性别数据相关联的翻译引擎id。
例如,可以预先指定能够再现诸如由年龄数据所表示的年龄或世代和由性别数据所表示的性别的说话者属性的语音合成引擎34。或者,可以预先指定具有讲话者属性再现的最高准确度的语音合成引擎34的语音合成引擎id。指定的语音合成引擎id可以被设置为与属性引擎对应管理数据中的年龄数据和性别数据相关联的语音合成引擎id。
例如,假定当第一说话者输入语音时,引擎确定单元46指定日语是翻译前语言而英语是翻译后语言。此外,假定引擎确定单元46基于分析单元44的分析结果来指定表示说话者的年龄或世代的值与表示说话者的性别的值的组合。在这种情况下,引擎确定单元46可以在图7中所示的属性引擎对应管理数据的记录中指定具有与指定的组合相同的年龄数据和性别数据的值的组合的记录。引擎确定单元46可以指定包括在属性引擎对应管理数据的指定记录中的翻译引擎id和语音合成引擎id的组合。
在图7中所示的属性引擎对应管理数据的记录中,引擎确定单元46可以指定具有与指定的组合相同的年龄数据和性别数据的值的组合的多个记录。在这种情况下,例如,引擎确定单元46可以基于给定标准来指定包括在属性引擎对应管理数据的任何一个记录中的翻译引擎id和语音合成引擎id的组合。
引擎确定单元46可以确定由包括在指定组合中的翻译引擎id所标识的翻译引擎28作为第一翻译引擎28。此外,引擎确定单元46可确定由包括在指定组合中的语音合成引擎id所标识的语音合成引擎34作为第一语音合成引擎34。
引擎确定单元46可以基于图6中所示的语言引擎对应管理数据来指定语音识别引擎id、翻译引擎id、和语音合成引擎id的多个组合。在这种情况下,引擎确定单元46可基于图7中所示的属性引擎对应管理数据将指定的组合缩小范围为一个组合。
在上面的例子中,基于第一说话者的年龄或世代和说话者的性别的组合进行确定,尽管第一翻译引擎28和第一语音合成引擎34的组合可以基于第一说话者的其他属性来确定。例如,表示说话者情绪的情绪数据的值可以被包括在属性引擎对应管理数据中。引擎确定单元46可以基于例如由分析单元44估计的说话者的情绪和包括情绪数据的属性引擎对应管理数据来确定第一翻译引擎28和第一语音合成引擎34的组合。
类似地,当第二说话者输入语音时,引擎确定单元46可基于第二说话者的属性确定第二翻译引擎28和第二语音合成引擎34的组合。
如所描述的,与第一说话者的性别和年龄相对应的语音被输出到第二说话者。此外,与第二说话者的性别和年龄相对应的语音被输出到第一说话者。以这种方式,可以根据说话者的诸如说话者的年龄或世代、性别和情绪的属性,利用翻译引擎28和语音合成引擎34的适当组合来执行语音翻译。
引擎确定单元46可以基于第一说话者的属性来确定第一翻译引擎28和第一语音合成引擎34中的一个。引擎确定单元46可以基于第二说话者的属性来确定第二翻译引擎28和第二语音合成引擎34中的一个。
引擎确定单元46可以基于存储在日志数据存储单元42中的终端日志数据来确定语音识别引擎22、翻译引擎28、和语音合成引擎34的组合。
例如,当第一说话者输入语音时,引擎确定单元46可以基于其中说话者id的值为1的终端日志数据的年龄数据、性别数据、和情绪数据,估计第一说话者的属性,诸如年龄、世代、性别、和情绪。基于估计的结果,可以确定第一翻译引擎28和第一语音合成引擎34的组合。在这种情况下,可以以从具有最新时间数据的记录起的顺序,基于预定数量的终端日志数据的记录来估计第一说话者的属性,诸如年龄或世代、性别和情绪。在这种情况下,根据第一说话者的性别和年龄的语音被输出至第二说话者。
当第二说话者输入语音时,引擎确定单元46可以基于其中说话者id的值为1的终端日志数据的年龄数据、性别数据、和情感数据估计第一说话者的属性,诸如年龄或世代、性别、和情绪。引擎确定单元46可以基于估计的结果确定第二翻译引擎28和第二语音合成引擎34的组合。在这种情况下,响应于第二说话者输入语音,语音合成单元36根据第一说话者的诸如年龄或世代、性别、和情绪的属性合成语音。在这种情况下,可以以从具有最新时间数据的记录起的顺序,基于预定数量的终端日志数据的记录来估计第二说话者的诸如性别和年龄的属性。
以这种方式,响应于第二说话者的语音输入操作,根据作为第二说话者的会话伙伴的第一说话者的诸如年龄或世代、性别、情绪的属性的语音被输出到第一说话者。
例如,假设第一说话者是说英语的女孩,第二说话者是说日语的成年男性。在这种情况下,对于第一说话者而言,如果将女孩而不是成年男性的声音类型和音调的语音输出到第一说话者,可能是期望的。例如,在这种情况下,如果其中合成包括女孩可能知道的相对简单的文字的文本的语音被输出到第一说话者,那么可能是期望的。例如,在上述情况下,响应于第二说话者的语音输入操作,根据第一说话者的诸如年龄或世代、性别、和情绪的属性向第一说话者输出语音会更加有效。
引擎确定单元46可以基于终端日志数据和分析单元44的分析结果的组合来确定语音识别引擎22、翻译引擎28、和语音合成引擎34的组合。
当第一说话者输入语音时,引擎确定单元46可以基于第一说话者的语音输入速度来确定第一翻译引擎28和第一语音合成引擎34中的至少一个。当第一说话者输入语音时,引擎确定单元46可以基于第一说话者的语音的音量来确定第一翻译引擎28和第一语音合成引擎34中的至少一个。当第一说话者输入语音时,引擎确定单元46可以基于第一说话者的语音的声音类型或音调来确定第一翻译引擎28和第一语音合成引擎34中的至少一个。在这方面,可以基于例如分析单元44的分析结果或者具有1作为说话者id的值的终端日志数据来确定第一说话者的语音的输入速度、音量、声音类型、和音调。
当第一说话者输入语音时,语音合成单元36可以以根据第一说话者的语音的输入速度的速度合成语音。例如,语音合成单元36可合成通过采用等于或多倍于第一说话者的语音输入时间的时间段输出的语音。这样,根据第一说话者的语音的输入速度的速度的语音被输出到第二说话者。
当第一说话者输入语音时,语音合成单元36可以以根据第一说话者的语音的音量的音量合成语音。例如,可以合成第一说话者的语音的相同或预定倍数音量的语音。这使得能够以根据第一说话者的语音的音量的音量向第二说话者输出语音。
当第一说话者输入语音时,语音合成单元36可以合成具有根据第一说话者的声音类型或音调的声音类型或音调的语音。这里,例如,可以合成具有与第一说话者的语音相同的声音类型或音调的语音。例如,可以合成具有与第一说话者的语音相同的频谱的语音。这样,具有根据第一说话者的语音的声音类型或音调的声音类型或音调的语音被输出到第二说话者。
当第二说话者输入语音时,引擎确定单元46可以基于第一说话者的语音的输入速度来确定第二翻译引擎28和第二语音合成引擎34中的至少一个。当第二说话者输入语音时,引擎确定单元46可以基于第一说话者的语音的音量来确定第二翻译引擎28和第二语音合成引擎34中的至少一个。这里,可以基于例如具有1作为说话者id的值的终端日志数据来确定第一说话者语音的输入速度或音量。
当第二说话者输入语音时,语音合成单元36可以以根据第一说话者的语音的输入速度的音量合成语音。在这方面,例如,语音合成单元36可以合成通过采用等于或多倍于第一说话者的语音输入时间的时间段输出的语音。
以这种方式,响应于第二说话者的语音输入操作,不管第二说话者的语音的输入速度,根据作为第二说话者的会话伙伴的第一说话者的语音的输入速度的速度的语音被输出到第一说话者。换句话说,第一说话者能够以根据第一说话者自己的语音的速度的速度听到语音。
当第二说话者输入语音时,语音合成单元36可以以根据第一说话者的语音的音量的音量合成语音。这里,例如,可以合成与第一说话者的语音的相同或预定倍数音量的语音。
以这种方式,响应于第二说话者的语音输入操作,不管第二说话者的语音的音量,根据作为第二说话者的会话伙伴的第一说话者的语音的音量的音量的语音被输出到第一说话者。换句话说,第一说话者可以以根据第一说话者自己的语音的音量的音量听到语音。
当第二说话者输入语音时,语音合成单元36可以合成具有根据第一说话者的语音的声音类型或音调的声音类型或音调的语音。这里,例如,可以合成具有与第一说话者的语音相同的声音类型或音调的语音。例如,可以合成具有与第一说话者的语音相同的频谱的语音。
这样,响应于第二说话者的语音输入操作,不管第二说话者的语音的声音类型或音调,根据作为第二说话者的会话伙伴的第一说话者的声音类型或音调的声音类型或音调的语音被输出到第一说话者。换句话说,第一说话者能够听到具有根据第一说话者自己的语音的声音类型或音调的声音类型或音调的语音。
响应于第二说话者的语音输入操作,翻译单元30可以确定用于语音识别单元24所生成的文本中包括的翻译目标词的多个翻译候选。翻译单元30可以检查确定的翻译候选的每个,以查看是否存在包含在响应于第一说话者的语音输入操作而生成的文本中的词。这里,例如,翻译单元30可以检查确定的翻译候选的每个,以查看是否存在包含在具有1作为说话者id值的终端日志数据中的翻译前文本数据或翻译后的文本数据所表示的文本中的词。翻译单元30可以将翻译目标词翻译成被确定为包括在响应于第一说话者的语音输入操作而生成的文本中的词。
以这种方式,由第二说话者的会话伙伴的第一说话者在最近的会话中语音输入的一个词被语音输出,因此会话可以顺利进行而不会不自然。
翻译单元30可以基于由分析单元44估计的主题或场景来确定是否使用技术术语字典来执行翻译处理。
在以上描述中,第一语音识别引擎22、第一翻译引擎28、第一语音合成引擎34、第二语音识别引擎22、第二翻译引擎28、和第二语音合成引擎34不一定一对一地对应于软件模块。例如,第一语音识别引擎22、第一翻译引擎28、和第一语音合成引擎34中的一些可以由单个软件模块来实现。此外,例如,第一翻译引擎28和第二翻译引擎28可以由单个软件模块来实现。
以下,参照图8中的流程图,将描述当第一说话者输入语音时在根据本实施例的服务器10中执行的处理的示例。
语音数据接收单元20从翻译终端12接收分析目标数据(s101)。
随后,分析单元44对在s101中接收到的分析目标数据中包括的翻译前语音数据执行分析处理(s102)。
引擎确定单元46基于例如终端日志数据或者如在s102中描述的执行分析处理的结果来确定第一语音识别引擎22、第一翻译引擎28、和第一语音合成引擎34的组合(s103)。
然后,语音识别单元24执行由在s103中确定的第一语音识别引擎22实现的语音识别处理,以生成表示作为由包括在s101中接收到的分析对象数据中的翻译前语音数据表示的语音的识别结果的文本的翻译前文本数据(s104)。
翻译前文本数据发送单元26将在s104中生成的翻译前文本数据发送到翻译终端12(s105)。这样发送的翻译前文本数据被显示在翻译终端12的显示部12e上。
翻译单元30执行由第一翻译引擎28实现的翻译处理,以生成表示通过将由在s104中生成的翻译前文本数据所表示的文本翻译成第二语言而获得的文本的翻译后文本数据(s106)。
语音合成单元36执行由第一语音合成引擎34实现的语音合成处理,以合成表示由在s106中产生的翻译后文本数据表示的文本的语音(s107)。
日志数据生成单元40然后生成日志数据并将生成的数据存储在日志数据存储单元42中(s108)。这里,例如,可以基于s101中接收到的分析目标数据中包括的元数据、s102中的处理中的分析结果、s104中生成的翻译前文本数据、以及s106中生成的翻译后文本数据来生成日志数据。
然后,语音数据发送单元38将表示在s107中合成的语音的翻译后语音数据发送到翻译终端12,并且翻译后文本数据发送单元32将在s106中生成的翻译后文本数据发送到翻译终端12(s109)。这样发送的翻译后文本数据被显示在翻译终端12的显示部12e上。此外,表示由此发送的翻译后语音数据的语音从翻译终端12的扬声器12g被语音输出。本例中描述的处理过程终止。
当第二说话者输入语音时,在根据本实施例的服务器10中也执行与在图8中的流程图中表示的处理类似的处理。然而,在这种情况下,在s103的处理中确定第二语音识别引擎22、第二翻译引擎28、和第二语音合成引擎34的组合。此外,在s104中,执行由在s103中确定的第二语音识别引擎22实现的语音识别处理。此外,在s106中,执行由第二翻译引擎28实现的翻译处理。此外,在s107中,执行由第二语音合成引擎34实现的语音合成处理。
本发明不限于上述实施例。
例如,服务器10的功能可以由单个服务器来实现或由多个服务器来实现。
例如,语音识别引擎22、翻译引擎28、和语音合成引擎34可以是由服务器10以外的外部服务器提供的服务。引擎确定单元46可以确定其中分别实现语音识别引擎22、翻译引擎28、和语音合成引擎34的一个或多个外部服务器。例如,语音识别单元24可以向由引擎确定单元46确定的外部服务器发送请求,并从外部服务器接收语音识别处理的结果。此外,例如,翻译单元30可以向由引擎确定单元46确定的外部服务器发送请求,并且从外部服务器接收翻译处理的结果。此外,例如,语音合成单元36可以向由引擎确定单元46确定的外部服务器发送请求,并且从外部服务器接收语音合成处理的结果。这里,例如,服务器10可以调用上述服务的api。
例如,引擎确定单元46不需要基于如图6和图7所示的表来确定语音识别引擎22、翻译引擎28、和语音合成引擎34的组合。例如,引擎确定单元46可以使用已学习的机器学习模型来确定语音识别引擎22、翻译引擎28、和语音合成引擎34的组合。
应该注意的是,上述特定字符串和数值以及附图中示出的特定字符串和数值仅仅是示例,并且本发明不限于这些字符串或数值。
- 还没有人留言评论。精彩留言会获得点赞!