一种基于DBN算法的药物靶向蛋白作用预测方法与流程
本发明涉及人工智能、机器学习、深度学习以及精准医疗的技术领域,尤其是指一种基于dbn算法的药物靶向蛋白作用预测方法。
背景技术
蛋白质是生物机体内重要的物质,它是生命活动的主要承担者。绝大多数的药物进行机体后都是通过与蛋白质发生相互作用进而对人体产生作用。药物与生物大分子相互结合、作用的部位即为药物靶点,药物作用靶点包括:酶、离子通道、受体等,这些都是由蛋白质所构成,因此研究药物与蛋白质相互作用的机制,有利于人们的生命健康安全。
传统的药物靶向蛋白作用研究采用生物实验方法确认药物与蛋白质之间是否会发生相互作用,这种方式需要耗费大量的成本与时间。因此使用计算机模拟、模式识别等手段预测药物与蛋白质之间的相互作用成了一项重要的研究工作。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提出了一种基于dbn算法的药物靶向蛋白作用预测方法,能够使得在没有人工干预的情况下,较快速地给出药物-靶向蛋白可能的相互作用对,从而节省药物研发试验成本,加快了药物新功能的挖掘和发现。
为实现上述目的,本发明所提供的技术方案为:一种基于dbn算法的药物靶向蛋白作用预测方法,包括以下步骤:
s1、计算药物的扩展连接连通指纹特征和蛋白质的氨基酸序列的三肽结构特征,并将两者串接起来;
s2、基于受限波尔兹曼机远离对深度置信网络的各层参数进行预训练;
s3、利用反向传播算法对整个网络的参数进行微调;
s4、对测试数据进行作用预测。
在步骤s1中,将药物特征和蛋白特征转化为特征向量,整个整个药物-蛋白质对特征向量为二进制序列,前2048位为药物特征,后8000位为蛋白质特征。
在步骤s2中,基于受限波尔兹曼机远离对深度置信网络的各层参数进行预训练的具体情况如下:
rbm中每一个节点都是二值的,所以它一共具有2n个状态,当x=1时表示当前节点处于打开状态,否则,当x=0时节点处于关闭状态,当前rbm的能量值使用下面能量函数计算:
其中,bi对应节点i的偏置,wi,j为节点i、j连接的边的权值,xi表示rbm中的第i个节点,n表示总共节点个数;能量函数是描述整个系统状态的一种度量方式,当系统越有序或分布越集中,则系统的能量越小,相反,系统越无序或概率分布越近均匀,则能量越大;
基于rbm的训练算法流程为:
2.1)初始化rbm参数,初始化权值矩阵w~n(0,0.01),可见层及隐含层偏置a=b=0;
2.2)逐一个或一批训练样本输入到rbm中,进行gibbs采样;
2.3)根据以下公式更新rbm参数:
wi,*=wi,*+α[p(hi=1|v(0))v(0)-p(hj=1|v′)v′]
a=a+α[v(0)-v′]
b=b+α[p(h=1|v(0))-p(h=1|v′)]
其中,p()表示概率函数,v表示可见层,h表示隐含层,hi和hj分别表示隐含层h中的第i个和第j个元素,当hi=1或hj=1时,表示对应的隐含层元素处于打开状态;v′表示h经解码后数据,v(0)表示不采样时的数据,对应地,v(t)表示迭代了t次采样的数据;nh为隐含层节点个数;矩阵w为权值矩阵,其中,wi,*表示第i行的行向量,α为学习速率,a和b是隐含层偏置值;
2.4)根据以上能量函数公式计算rbm模型能量,若能量函数未收敛或未达到指定训练步数,返回2.2),否则结束训练。
在步骤s3中,利用反向传播算法对整个网络的参数进行微调,具体是:dbn由多个rbm模型堆叠而成,通常在最后添加一层全连接层作为网络输出,dbn中的每一个rbm都能够看作为特征检测器,用于提取上一层的特征,多个rbm逐层堆叠构成具有足够深度的神经网络,最终在最后一个rbm中输出原始输入的深度特征;
dbn的训练过程分为预训练和微调(finetuning)两个阶段,预训练阶段为无监督学习,其利用rbm模型性质逐层训练网络参数,当该层能量稳定后,以该层的输出作为下一层的输入来训练下一层rbm参数,直到到达最后的全连接层时,结束预训练;至此,预训练得到的网络参数已经初始化到更优的值上,各层rbm模型已经尽可能地收敛到输入数据的分布中;dbn训练流程具体如下:
输入:(x,y)=[(x1,y1),(x2,y2),(x3,y3),...,(xm,ym)],xi为网络输入,yi为对应输入的实际分类;
3.1)预训练阶段,设dbn一共有k层rbm模型,将[x1,x2,x3,...,xm]作为第一层rbm的输入,训练第一层rbm直到能量函数收敛,并令
3.2)令k=2,以
3.3)微调阶段,将x输入到dbn中得出预测分类
在步骤s4中,使用步骤s3得到的预测模型进行预测,大于阈值t的为存在相互作用关系,否则不存在相互作用关系,具体如下:
首先,建立药物、蛋白质数据库,从drugbank、chembl和kegg这些公开的药物数据库中收集药物、蛋白质信息进行构建,需要集中收集药物smiles和蛋白质氨基酸序列;之后当需要查询某药物是否与某蛋白质发生反应时,从数据库中查找中对应的记录,再对它们进行预处理、拼接成一特征向量,输入到dbn中,最终网络输出output为一个范围从0到1的浮点数,将output与阈值t比较,当output>t时,则预测为药物与蛋白质会发生相互作用,当output≤t时,则预测为药物与蛋白质不会发生相互作用。
本发明与现有技术相比,具有如下优点与有益效果:
1、本发明基于药物的扩展连通指纹特征和蛋白质的氨基酸序列特征,有效利用了药物和蛋白质的生化特性,从而使得药物和蛋白的作用预测有了较好的生化解释基础。
2、本发明使用了深度学习网络模型作为特征提取器,同时选取层次较深的卷积层的输出作为特征,相对与传统的特征提取方法,能够提取出更加抽象和高阶的特征,从而更好的完成后续操作。
3、本发明实现药物和靶向蛋白的作用预测,相对于传统的实验试剂方法,作用预测过程完全由机器自动完成,过程中不需要人工介入完成操作,从而节省了大量的财力和物力,同时也节省了大量的时间。
附图说明
图1为本发明方法的处理步骤流程图。
图2为药物和蛋白质特征组合起来构成的一个特征向量示意图。
图3为本发明实施例使用的dbn网络结构图。
具体实施方式
下面结合具体实施例对本发明作进一步说明。
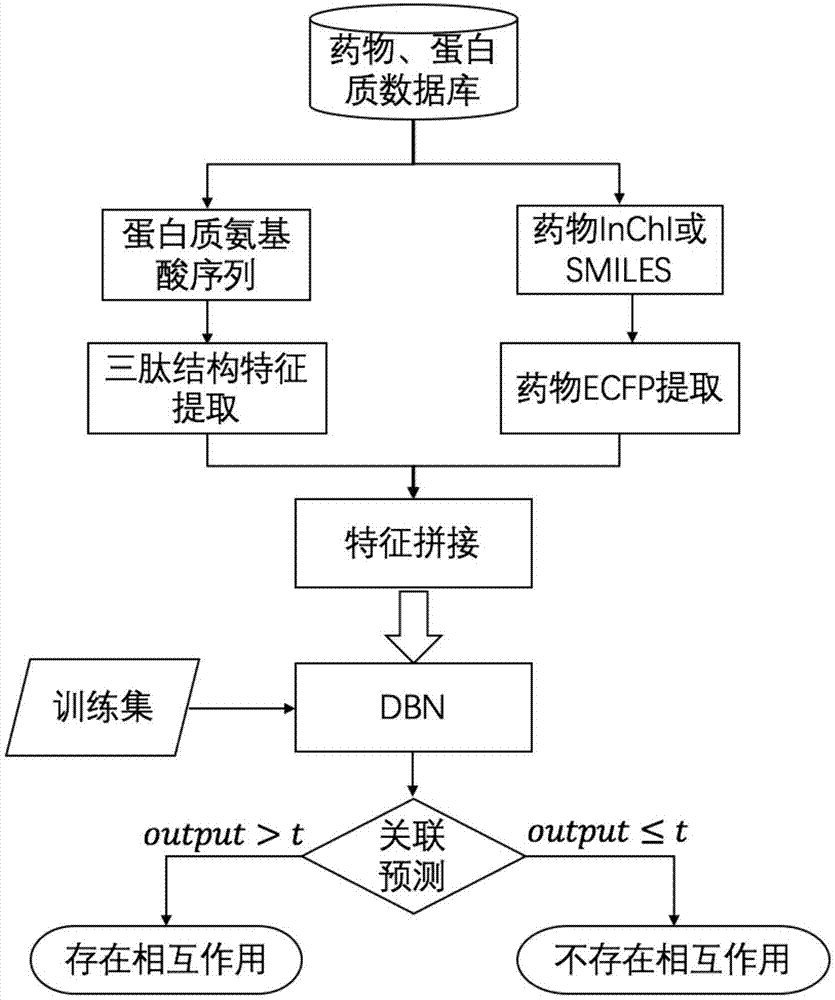
如图1所示,本实施例所提供的基于dbn算法的药物靶向蛋白作用预测方法,包括以下步骤:
步骤s1、计算药物的扩展连接连通指纹特征和蛋白质的氨基酸序列的三肽结构特征,并将两者串接起来。在dti预测中,需要判断药物跟蛋白质是否会相互发生作用,这实际上是一个二分类问题,将药物、蛋白质相互组合起来构成药物-蛋白质对,对其划分为两类:有相互作用和无相互作用。dbn通常用于解决分类问题,它以物体的特征向量作为输入,最终输出分类标签,在dti预测中,分别计算药物、蛋白质的特征向量,然后将它们两两组合作为dbn的数据向量。
将药物和蛋白质特征组合起来构成一个长度为10048的特征向量(药物特征长度:2048,蛋白质特征长度:8000),如图2所示,整个药物-蛋白质对特征向量为二进制序列,前2048位为药物特征,后8000位为蛋白质特征。
s1.1、药物ecfp提取
根据药物由多种化合物构成,不同化合物具有不同的结构、物理性质和化学性质,每种化合物对应的国际化和物标识(inchi)和简化分子线性输入规范(smiles);根据以上两种因素提取ecfp。ecfps是一种圆形拓扑指纹,常用于分子描述、相似度计算,广泛应用于药物研究领域。它的特点在于其指纹是基于分子中原子的圆形邻域计算的,并且计算时设置邻域区域的大小。ecfps中的每一个子结构都有一个标识,同时它使用一串长度固定的二进制序列来保存记录每一个子结构,每一个为表示分子中是否存在某一子结构,其表达形式适合dbn使用。
s1.2、蛋白质三肽结构提取
与药物的smiles相同,字符序列表示蛋白质其表示长度不固定并且使用20个字符表示,不能作为dbn的输入,需要使用描述器对蛋白质进行描述,根据描述特征的不同,描述器分为:氨基酸序列描述器、自相关描述器、ctd、quasi序列描述器和伪氨基酸组成描述器,本文使用氨基酸序列描述器来描述蛋白质特征,使用n元氨基酸描述器的特征长度为20n,n越大就越能保留蛋白质的原始信息,但是特征长度会呈指数形式增长。因此这里使用三肽结构特征(tc)来描述蛋白质特征,这个方法描述了蛋白质序列中的连续三个的氨基酸序列的出现频率,该描述器生成的蛋白质特征长度为8000。
步骤s2、基于受限波尔兹曼机远离对深度置信网络的各层参数进行预训练,rbm中每一个节点都是二值的,所以它一共具有2n个状态,当x=1时表示当前节点处于打开状态,否则,当x=0时节点处于关闭状态,当前rbm的能量值使用下面能量函数计算:
其中,bi对应节点i的偏置,wi,j为节点i、j连接的边的权值,xi表示rbm中的第i个节点,n表示总共节点个数,能量函数是描述整个系统状态的一种度量方式,当系统越有序或分布越集中,则系统的能量越小,相反,系统越无序或概率分布越近均匀,则能量越大;
上面步骤主要是使用rbm进行训练,算法流程为:
s21、初始化rbm参数,一般地,初始化权值矩阵w~n(0,0.01),可见层及隐含层偏置a=b=0;
s22、逐一个或一批训练样本输入到rbm中,进行gibbs采样;
s23、根据以下公式更新rbm参数:
wi,*=wi,*+α[p(hi=1|v(0))v(0)-p(hj=1|v′)v′]
a=a+α[v(0)-v′]
b=b+α[p(h=1|v(0))-p(h=1|v′)]
其中,p()表示概率函数,v表示可见层,h表示隐含层,hi和hj分别表示隐含层h中的第i个和第j个元素,当hi=1或hj=1时,表示对应的隐含层元素处于打开状态;v′表示h经解码后数据,v(0)表示不采样时的数据,对应地,v(t)表示迭代了t次采样的数据;nh为隐含层节点个数;矩阵w为权值矩阵,其中,wi,*表示第i行的行向量,α为学习速率,a和b是隐含层偏置值;
s24、根据以下能量函数公式计算rbm模型能量,若能量函数未收敛或未达到指定训练步数,返回s22,否则结束训练。
步骤s3、利用反向传播算法对整个网络的参数进行微调
dbn的训练过程分为预训练和微调(finetuning)两个阶段。预训练阶段为无监督学习,其利用了rbm模型性质逐层训练网络参数,当该层能量稳定后,以该层的输出作为下一层的输入来训练下一层rbm参数,直到到达最后的全连接层时,结束预训练。至此,预训练得到的网络参数已经初始化到较优的值上,各层rbm模型已经尽可能地收敛到输入数据的分布中。dbn训练流程具体如下:
输入:(x,y)=[(x1,y1),(x2,y2),(x3,y3),...,(xm,ym)],xi为网络输入,yi为对应输入的实际分类。
s31、预训练阶段,设dbn一共有k层rbm模型,将[x1,x2,x3,...,xm]作为第一层rbm的输入,训练第一层rbm直到能量函数收敛,并令
s32、令k=2,以
s33、微调阶段,将x输入到dbn中得出预测分类
图3为本发明使用的dbn网络结构,使用了三层rbm模型,最后输出单元个数为1,从输入到输出的单元个数为10048-500-500-500-1,激活函数均为sigmoid函数。
步骤s4、对测试数据进行作用预测
药物、蛋白质数据库的建立从drugbank、chembl和kegg等公开的药物数据库中收集药物、蛋白质信息进行构建,需要集中收集药物smiles和蛋白质氨基酸序列。之后当需要查询某药物是否与某蛋白质发生反应时,从数据库中查找中对应的记录,再对它们进行预处理、拼接成一特征向量,输入到dbn中,最终网络输出output为一个范围从0到1的浮点数,将output与阈值t比较,当output>t时,则预测为药物与蛋白质会发生相互作用,当output≤t时,则预测为药物与蛋白质不会发生相互作用。
综上所述,本发明方法是从药物的分子结构出发,提取药物的扩展连通指纹,从蛋白质的氨基酸序列出发,提取了蛋白质的三肽结构特征,将药物的扩展连通指纹和蛋白质的三肽结构特征两两拼接,构造成一个药物-蛋白质特征向量,之后输入到深度置信网络中进行训练,网络的输出为网络输入的药物-蛋白质对发生相互作用的概率,最后选择合适的阈值判断这一对关联是否成立。这相比现有技术,本发明方法能够使得在没有人工干预的情况下,较快速地给出药物-靶向蛋白可能的相互作用对,从而节省药物研发试验成本,加快了药物新功能的挖掘和发现,值得推广。
以上所述实施例子只为本发明之较佳实施例子,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!