提升光谱图像监督分类性能的样本扩充与一致性判别方法与流程
本发明涉及高光谱图像监督分类算法中的预处理及后处理技术,具体涉及一种提升光谱图像监督分类性能的样本扩充与一致性判别方法。
技术背景
遥感高光谱图像是由几十甚至上百连续光谱波段组成的三维数据集,由于每个像元的通道数量远远超过普通rgb彩色图像的通道数量,所以在地物识别与分类应用中具有很强的分辨性能。因此,在诸如农业监测、污染监测、矿物识别等领域具有广泛的应用。而利用高光谱图像进行识别与分类是在图像获取后最重要的处理过程,其识别精度决定了高光谱图像对地物鉴别的最终效果。在高光谱图像分类研究中,机器学习相关方法受到了广泛关注。
传统机器学习方法例如极限学习机、支持向量机、贝叶斯等方法在高光谱图像监督分类领域中都有一定的应用,但由于高光谱数据集样本间具有很强的相似性,以及同谱异物、同物异谱等现象的出现,导致分类器性能在一定程度上下降,使得最终分类精度不高。利用遥感图像的空间信息提升分类性能变得尤为重要。而常规的空-谱联合方法常将样本的空间信息与光谱信息进行融合并生成新的样本,例如增加样本属性维度的gabor-svm等方法会使得模型的输入维度增高,从而引入维度扩张带来的额外影响。目前,有许多针对在不改变数据维度的前提下利用预处理及后处理技术提升分类效果的方法,例如慕彩红等人在主动学习方法的基础上提出了利用测试样本邻域高相似像元判别结果来对目标样本的判别结果进行优化的方法(慕彩红,焦李成,王依萍,等.主动学习和邻域信息相结合的高光谱图像分类方法:,cn104182767a[p].2014.),取得了较好的效果。然而,上述方法的判定规则较为复杂,且像元相似度参数固定,无法根据数据自适应调整,因此方法应用范围受限。
技术实现要素:
本发明的目的在于提供一种提升光谱图像监督分类性能的样本扩充与一致性判别方法,通过形状模板匹配有效扩充监督样本,利用模板库与分类预测矩阵一致性判别改善分类结果的局部聚集性,大幅提升监督分类器的精度,提升了小样本监督分类算法的鲁棒性,可适用于任何监督分类器。
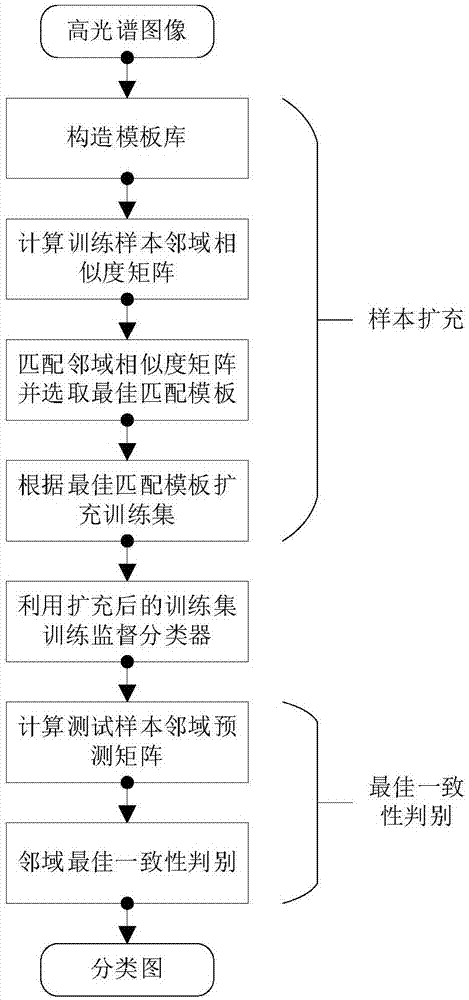
实现本发明目的的技术解决方案为:一种提升光谱图像监督分类性能的样本扩充与一致性判别方法,包括以下步骤:
第一步,构造形状匹配模板库,即构造若干大小为d×d的形状匹配模板,作为模板库;
第二步,计算单个训练样本的邻域相似度矩阵,即截取以该训练样本为中心的d×d邻域像元块,并计算其邻域像元与中心像元的相似度,将相似度顺序排列成矩阵形式作为该训练样本的邻域相似度矩阵;
第三步,使用模板库对相似度矩阵进行匹配,并根据匹配度选取最佳匹配模板;
第四步,根据最佳匹配模板扩充训练样本,即将最佳匹配模板所覆盖的像元划归到与中心像元同类别训练集中;
第五步,使用扩充后的训练集训练监督分类器;
第六步,计算测试样本的邻域预测矩阵,即截取以该测试样本为中心的d×d邻域像元块并分别预测其中每个像元的类别,将预测类别顺序排列成矩阵形式作为该样本的邻域预测矩阵;
第七步,使用模板库对邻域预测矩阵进行匹配,并根据一致性度量计算最佳判别结果,即依次计算邻域预测矩阵与模板库中各模板匹配所对应各类别的一致性度量,选取最大值所对应类别作为该样本的最终判别结果。
本发明与现有技术相比,其显著特点在于:(1)通过形状模板匹配可以有效扩充监督样本,从而有效提升小样本监督学习的性能;(2)通过对邻域预测结果的最佳一致性判别,可以大幅度提升最终分类结果的精度;(3)本发明方法适用于任意监督分类器,具有广泛的应用性;(4)本发明对数据本身特性不敏感,因此拥有较好的自适应性和扩展性,并且在同物异谱和同谱异物问题上进行了改善,大幅度提升了算法的最终分类精度。
附图说明
图1为本发明提升光谱图像监督分类性能的样本扩充与一致性判别方法流程图。
图2为大小为3×3的匹配模板库示例图。
图3为大小为5×5的匹配模板库示例图。
图4(a)为indianpines数据集真实地物分布图。
图4(b)为indianpines数据集采用elm方法的分类效果图。
图4(c)为indianpines数据集采用elm方法配合本发明方法(使用大小为3×3的匹配模板)的分类效果图。
图4(d)为indianpines数据集采用elm方法配合本发明方法(使用大小为5×5的匹配模板)的分类效果图。
图4(e)为indianpines数据集采用svm方法的分类效果图。
图4(f)为indianpines数据集采用svm方法配合本发明方法(使用大小为3×3的匹配模板)的分类效果图。
图4(g)为indianpines数据集采用svm方法配合本发明方法(使用大小为5×5的匹配模板)的分类效果图。
图5(a)为paviacenter数据集真实地物分布图。
图5(b)为paviacenter数据集采用elm方法的分类效果图。
图5(c)为paviacenter数据集采用elm方法配合本发明方法(使用大小为3×3的匹配模板)的分类效果图。
图5(d)为paviacenter数据集采用elm方法配合本发明方法(使用大小为5×5的匹配模板)的分类效果图。
图5(e)为paviacenter数据集采用svm方法的分类效果图。
图5(f)为paviacenter数据集采用svm方法配合本发明方法(使用大小为3×3的匹配模板)的分类效果图。
图5(g)为paviacenter数据集采用svm方法配合本发明方法(使用大小为5×5的匹配模板)的分类效果图。
具体实施方式
结合图1,一种提升光谱图像监督分类性能的样本扩充与一致性判别方法,包括以下步骤:
第一步,构造形状匹配模板库,即构造若干大小为d×d的形状匹配模板,作为模板库;
第二步,计算单个训练样本的邻域相似度矩阵,即截取以该训练样本为中心的d×d邻域像元块,并计算其邻域像元与中心像元的相似度,将相似度顺序排列成矩阵形式作为该训练样本的邻域相似度矩阵;
第三步,使用模板库对相似度矩阵进行匹配,并根据匹配度选取最佳匹配模板;
第四步,将最佳匹配模板所覆盖的像元划归到与中心像元同类别训练集中;
第五步,使用扩充后的训练集训练监督分类器;
第六步,计算测试样本的邻域预测矩阵,即选取以该测试样本为中心的d×d邻域像元块并分别预测其中每个像元的类别,将预测类别顺序排列成矩阵形式作为该样本的邻域预测矩阵;
第七步,使用模板库对邻域预测矩阵进行匹配,并根据一致性度量计算最佳判别结果,即依次计算邻域预测矩阵与模板库中各模板匹配所对应各类别的一致性度量,选取最大值所对应类别作为该样本的最终判别结果。
进一步的,第一步构造l个大小为d×d的形状匹配模板作为模板库,其中l≥8,d≥3且d为奇数;构造匹配模板的基本原则为:
(1)在模板中以像素点为单位,将所有像素分为覆盖与未覆盖,覆盖取1,未覆盖取0;
(2)在模板中所覆盖的像素区域须满足连通性,即模板中值为1的像素可组成满足4-邻接的连同区域,且连通区域须覆盖中心点;
(3)模板中的覆盖区域点个数n须满足n=(d-1)2。
进一步的,第二步计算单个训练样本的邻域相似度矩阵,具体过程为:
(1)对于第i个训练样本xi,在高光谱图像中截取以像元xi为中心的d×d邻域像元块,记为di,表示如下:
1≤i≤n,n为训练样本数;
(2)依次计算中心像元xi与邻域像元块di中的像元
(3)将中心像元xi与邻域像元
进一步的,第三步使用模板库对相似度矩阵进行匹配,并根据匹配度选取最佳匹配模板,计算方法为:
(1)依次计算模板库中第l个模板与训练样本xi的邻域相似度矩阵si的匹配度,记为
其中,运算符
(2)在样本xi与l个模板匹配得到的匹配度
进一步的,第四步根据最佳匹配模板扩充训练样本,即将训练样本xi对应的最佳匹配模板
进一步的,第五步使用扩充后的训练集训练监督分类器,即按照步骤二至步骤四依次对所有原始训练样本进行匹配扩充,并使用扩充后的训练样本训练监督分类器。
进一步的,第六步计算测试样本的邻域预测矩阵,计算方法为:
(1)对于第j个测试样本yj,在高光谱图像中截取以像元yj为中心的d×d邻域像元块,记为kj,表示如下:
1≤j≤m,m为测试样本数量;
(2)使用训练后的分类器依次对像元块kj中的像元
进一步的,第七步使用模板库对邻域预测矩阵进行匹配,并根据一致性度量计算最佳判别结果,具体过程为:
(1)依次计算测试样本yj与模板库中第l个模板tl匹配下属于类别c的一致性度量,记为
其中,运算符
(2)在样本yj与各模板匹配下分别属于各类别的一致性度量中,选取一致性度量最大值所对应类别为最终判别结果,记为
其中,
下面结合实施例和附图对本发明进行详细说明。
实施例
结合图1,一种提升光谱图像监督分类性能的样本扩充与一致性判别方法,步骤如下:
第一步,构造形状匹配模板库,即构造l个大小为d×d的形状匹配模板作为模板库,其中l≥8,d≥3且d为奇数。本实施例d=3,l=16,设计16个满足条件的不同匹配模板作为模板库,记为t1,t2,…,t16,模板库如图2所示。每个模板实为一个矩阵,图2中描述的第一个模板t1表示如下:
同理,其它模板也为矩阵表示形式。大小为5×5的匹配模板库形式如图3所示,模板设计方式按照前述规则进行设计。
第二步,计算单个训练样本的邻域相似度矩阵,在d=3,l=16的条件下,具体过程为:
(1)对于第i个训练样本xi,在高光谱图像中截取以像元xi为中心的3×3邻域像元块,记为di,表示如下:
1≤i≤n,n为训练样本数;
(2)依次计算中心像元xi与邻域像元块di中的像元
(3)将中心像元xi与邻域像元
第三步,使用模板库对相似度矩阵进行匹配,并根据匹配度选取最佳匹配模板。在d=3,l=16的条件下,具体计算过程为:
(1)依次计算模板库中第l个模板与样本xi的邻域相似度矩阵si的匹配度,记为
其中,运算符
(2)在样本xi对应的所有模板匹配度
假设
第四步,根据最佳匹配模板扩充训练样本,即将样本xi对应的最佳匹配模板
第五步,使用扩充后的训练集训练监督分类器,即按照步骤二至步骤四依次对所有训练样本进行匹配扩充,并使用扩充后的训练样本训练监督分类器,记分类器为q=classify(y),其中y为测试样本,q为测试样本y通过分类器得到的类别。
第六步,计算测试样本的邻域预测矩阵,在d=3,l=16的假设条件下,具体过程为:
(1)对于第j个测试样本yj,在高光谱图像中截取以像元yj为中心的3×3邻域像元块,记为kj,表示如下:
1≤j≤m,m为测试样本数;
(2)使用训练后的分类器依次对像元块kj中的像元
第七步,使用模板库对邻域预测矩阵进行匹配,并根据一致性度量计算最佳判别结果,在d=3,l=16,样本类别数c=9的条件下,具体过程为:
(1)依次计算测试样本yj与模板库中第l个模板tl匹配下属于类别c的一致性度量,记为
其中,运算符°表示哈达玛积,
(2)在样本yj对应的各模板匹配下分别属于各类别的一致性度量中,选取一致性度量最大值所对应类别为最终判别结果,记为
其中
下面通过仿真实验说明本发明的效果:
仿真实验采用两组真实高光谱数据:indianpines数据集和paviacenter数据集。indianpines数据集为机载可见红外成像光谱仪(aviris)在美国印第安纳州indianpines实验区采集的高光谱遥感图像。该图像共包含220个波段,空间分辨率为20m,图像大小为145×145。去除20个水汽吸收和低信噪比波段后(波段号为104-108,150-163,220),选择剩下的200个波段作为研究对象。该地区共包含16种已知地物共10366个样本。paviacenter数据集是由帕维亚的rosis传感器采集,共包含115个波段,图像大小为1096×490,在去除噪声波段之后,选择剩下的102个波段作为研究对象。每类样本均随机取10%作为训练样本,其余90%作为测试样本,并分别进行十次实验计算平均结果,并给出oa(overallaccuracy)以及aa(averageaccuracy)评价指标。在实验前,两组数据集均采用mh预测方法进行平滑处理。仿真实验均在windows10操作系统下采用python3.6与matlabr2016a完成。
本发明采用的评价指标是常规精度的评价方法,包括平均精度(aa)和总体精度(oa)。由于本发明的用途是提升任意分类器的分类精度,在仿真实验中我们分别采用elm和svm作为基础分类器进行实验,为了显示该方法对分类器性能的提升,每组数据集均会使用elm、tm-elm(3x3)、tm-elm(5x5)、svm、tm-svm(3x3)、tm-svm(5x5)进行实验,并进行结果对比。其中tm-elm(3x3)表示使用3x3大小的模板匹配(templatematching)结合elm的分类方法,tm-elm(5x5)表示使用5x5大小的模板匹配结合elm的分类方法,同理,tm-svm(3x3)、tm-svm(5x5)表示含义类似。大小为3x3的模板库样式如图2所示,大小为5x5的模板库样式如图3所示。
表1为本发明方法对indianpines与paviacenter数据集进行仿真实验的分类精度(%)。
表1
从实验结果可以发现,在不改变原始elm和svm分类模型的前提下,仅通过使用本发明方法对数据进行训练样本扩充与预测结果最佳一致性判别,便可以大幅度提升分类精度。在indianpines数据集上,本发明方法可以将原始elm模型96.27%的总体精度提升至98.85%(使用5x5大小模板匹配方法),将原始svm模型90.33%的总体精度提升至98.99%(使用5x5大小模板匹配方法)。在paviacenter数据集上,本发明方法可以将原始elm模型97.46%的分类精度提升至98.08%(使用5x5大小模板匹配方法),将原始svm模型98.87%的总体精度提升至99.79%(使用5x5大小模板匹配方法)。显然,本发明方法在使用3x3模板和5x5模板进行匹配后对分类结果均有明显提升,并且随着模板大小的扩大,分类精度也会随之提升,充分表明了本发明方法具有较高的稳定性和扩展性。本发明方法在两组数据集上的结果效果图如图4、图5所示。以上两组真实数据集的仿真实验结果表明了本发明方法的有效性。
- 还没有人留言评论。精彩留言会获得点赞!