恶意PDF检测方法、系统、数据存储设备和检测程序与流程
本发明应用于信息安全中的恶意pdf文件的检测领域。特别是涉及一种恶意pdf检测方法、系统、数据存储设备和检测程序。
背景技术
便携式文件格式(pdf)是一种电子文档格式,由adobe系统公司于1993年发布。由于pdf受欢迎程度高、结构灵活、功能多样,越来越多的网络犯罪分子通过pdf文件进行信息窃取、恶意敲诈等网络犯罪行为。并且近年来,对商业组织和政府机构的高级持续性威胁(apt)攻击时有发生,而恶意pdf文件是apt攻击的重要载体,通过执行嵌入在文件内部的恶意代码完成攻击过程。尽管软件供应商努力进行预防、解决,但pdf软件仍经常容易遭受零日攻击,特别是这种攻击利用pdf文件格式与第三方技术(如javascript或flash),从而造成创建临时补丁变得越来越困难。另外,由于pdf文件的体系结构复杂,攻击者使用各种代码混淆技术,使防病毒软件很难提供针对新型恶意pdf文件检测。
通过对恶意pdf文件的分析,针对现有的pdf漏洞,主要攻击方式是基于javascript的攻击和基于非javascript的攻击。基于javascript的攻击方式利用pdf阅读器的漏洞,将执行流程转移到嵌入的恶意javascript代码上。基于非javascript攻击主要利用许多pdf功能:如“/launch”、“/goto”和“/url”等,自动打开远程资源,增加互联网对客户端的威胁。
目前大部分杀毒软件采用基于启发式或字符串匹配的方法进行查杀病毒,但这些方式无法有效地处理多态攻击的问题。为了解决该问题,最近的研究主要集中在两个方面:
(1)利用pdf文件中嵌入的javascript,经过静态、动态分析提取其javascript特征,再经过机器学习进行分类。这类方法可应对基于恶意javascript的攻击,但易受到代码混淆的影响。
(2)利用pdf文件的结构信息来检测恶意pdf文件,其特点是不分析其携带的攻击代码或漏洞,并且这种方法相对于javascript分析的优点在于它们能够检测到非javascript攻击,并且不会受代码混淆的影响。但是如何增强模型的健壮性是基于结构信息的恶意文件检测方法所面临的大挑战。
基于以上方法进行恶意pdf文件检测,通常只能检测到基于单一方式的恶意攻击,并且模型时间消耗较高。
技术实现要素:
为了解决上述问题,本发明的目的在于提供一种恶意pdf检测方法、系统、数据存储设备和检测程序。
为了达到上述目的,本发明的技术方案为:
一种恶意pdf检测方法,至少包括如下步骤:
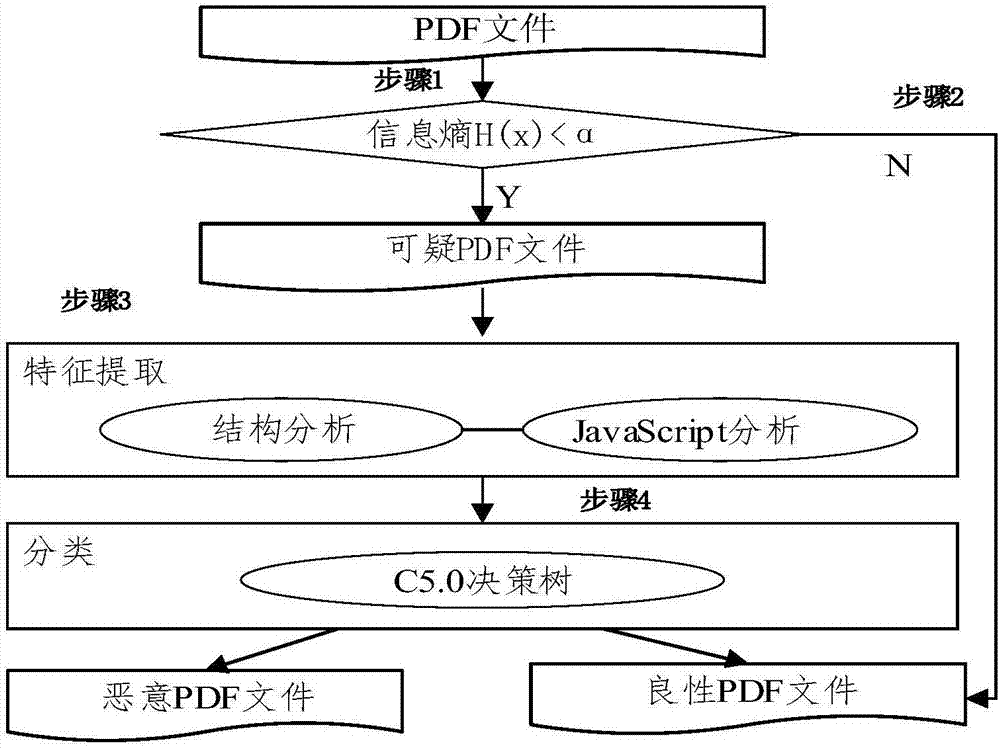
步骤一、将待检pdf文件转换成字节序列,计算每个pdf件的信息熵;
步骤二、根据统计的恶意pdf文件和良性pdf文件的信息熵值的最大值、最小值和平均值以及经验值设置阈值α,将每个pdf文件的信息熵与阈值α比较,把信息熵高于α的pdf文件作为正常文件,把信息熵低于α的pdf文件作为可疑文件;
步骤三、利用origami分析提取可疑文件中常用于恶意攻击的javascript和结构特征;
步骤四、利用c5.0决策树算法进行分类。
进一步:上述步骤一具体为:首先用pdfparser将待检pdf文件转换成二进制字节文件,然后计算每个pdf文件的信息熵。
进一步:上述步骤三具体为:首先利用origami分析可疑文件的结构并搜索恶意特征和结构的一般特征,然后再分析可疑文件的javascript代码并搜索恶意特征。
进一步:上述步骤四具体为:首先把每个pdf文件用一个向量表示,该向量由结构的一般特征、结构的动态特征和javascript特征组成;然后将向量、类别输入到c5.0决策树进行分类。
本发明的另一目的为:提供一种恶意pdf检测系统,包括:
信息熵计算模块,将待检pdf文件转换成字节序列,计算每个pdf件的信息熵;
甄别模块、根据统计的恶意pdf文件和良性pdf文件的信息熵值的最大值、最小值和平均值以及经验值设置阈值α,将每个pdf文件的信息熵与阈值α比较,把信息熵高于α的pdf文件作为正常文件,把信息熵低于α的pdf文件作为可疑文件;
分析模块、利用origami分析提取可疑文件中常用于恶意攻击的javascript和结构特征;
分类模块、利用c5.0决策树算法进行分类。
本发明的另一目的为:提供一种数据存储设备,包括指令,当其在计算机上运行时,使得计算机执行上述恶意pdf检测方法。
本发明的另一目的为:提供一种实现上述恶意pdf检测方法的检测程序。
本发明具有的优点和积极效果为:
本发明将pdf文件的信息熵、javascript特征和结构特征相结合利用c5.0决策树算法进行分类,该方法具有较高的检测精度,并且大大减少了检测时间,增强了实用性。
附图说明
图1为本发明优选实施例的流程图;
具体实施方式
为能进一步了解本发明的发明内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下:
如图1所示,一种恶意pdf检测方法:包括下列步骤:
步骤一、将数据集中的pdf文件转换成字节序列,计算每个pdf文件的信息熵;
具体步骤如下:
(1)首先用pdfparser将数据集中的pdf文件转换成二进制。
(2)然后利用公式1计算文件的信息熵。
其中,x代表文件;n代表文件转换成字节序列后不同字节的总数;i代表文件中第i个字节序列中的字节;pi表示字节i出现的概率。
步骤二、将每个文件的信息熵与阈值α比较,把信息熵高于α的文件作为正常文件,把信息熵低于α的文件作为可疑文件;
具体步骤如下:
(1)根据多次试验模拟,设置信息熵阈值α为7.74。
(2)把步骤一得到的信息熵h(x)和阈值α代入公式2,从而得到他们的差值。若差值大于0,则将该pdf文件作为可疑文件进行步骤三,否则作为正常文件输出。
δh=α-h(x)(2)
δh:阈值α与待测pdf文件的信息熵h(x)的差值。
步骤三、利用origami分析提取可疑文件中常用于恶意攻击的javascript和结构特征;
具体步骤如下:
(1)首先利用origami分析pdf文件的结构并搜索恶意特征和结构的一般特征。其中恶意特征包括’/js','/javascript',‘/goto’,’gotor’,’gotoe’,’openaction’,'/submitform’);结构的一般特征包括文件的大小、间接对象的数量。
(2)然后分析pdf文件的javascript代码并搜索恶意特征。恶意特征包括substring,fromcharcode,stringcount,document.write,document.createelement,eval,settimeout,eval_length,max_string。
步骤四、选取c5.0决策树算法进行分类;
具体步骤如下:
(1)s是特征样本集合,包括结构特征集合s1和javascript特征集合s2。以结构特征为例,元数据类型变量c有k类,属于ci类的样本数为freq(ci,s1),利用公式3计算结构特征集合s1的信息熵info(s1):
其中,|s1|是结构特征集合s1中的元素个数。
(2)特征属性t,有n类,利用公式4计算属性t的条件熵info(t):
其中,ti是第i类特征属性。
(3)利用公式5计算属性变量t的信息增益gain(t):
gain(t)=info(s1)-info(t)(5)
(4)利用信息增益率来生成结点,即公式6:
gainration(a)=gain(a)/info(a)(6)
其中,gain(a)表示a情况下时,其产生的子节点信息增益;info(a)表示情况a下生成的子结点个数指标,分割后的子结点越多,info(a)越大。
(5)树生成后,采用基于树规则的方法实现剪枝。
一种恶意pdf检测系统,包括:
信息熵计算模块,将待检pdf文件转换成字节序列,计算每个pdf件的信息熵;
甄别模块、根据统计的恶意pdf文件和良性pdf文件的信息熵值的最大值、最小值和平均值以及经验值设置阈值α,将每个pdf文件的信息熵与阈值α比较,把信息熵高于α的pdf文件作为正常文件,把信息熵低于α的pdf文件作为可疑文件;
分析模块、利用origami分析提取可疑文件中常用于恶意攻击的javascript和结构特征;
分类模块、利用c5.0决策树算法进行分类。
一种数据存储设备,包括指令,当其在计算机上运行时,使得计算机执行下面的恶意pdf检测方法;
步骤一、将待检pdf文件转换成字节序列,计算每个pdf件的信息熵;
步骤二、根据统计的恶意pdf文件和良性pdf文件的信息熵值的最大值、最小值和平均值以及经验值设置阈值α,将每个pdf文件的信息熵与阈值α比较,把信息熵高于α的pdf文件作为正常文件,把信息熵低于α的pdf文件作为可疑文件;
步骤三、利用origami分析提取可疑文件中常用于恶意攻击的javascript和结构特征;
步骤四、利用c5.0决策树算法进行分类。
作为优选:上述步骤一具体为:首先用pdfparser将待检pdf文件转换成二进制字节文件,然后计算每个pdf文件的信息熵。
作为优选:上述步骤三具体为:首先利用origami分析可疑文件的结构并搜索恶意特征和结构的一般特征,然后再分析可疑文件的javascript代码并搜索恶意特征。
作为优选:上述步骤四具体为:首先把每个pdf文件用一个向量表示,该向量由结构的一般特征、结构的动态特征和javascript特征组成;然后将向量、类别输入到c5.0决策树进行分类。
一种实现下面恶意pdf检测方法的检测程序;
步骤一、将待检pdf文件转换成字节序列,计算每个pdf件的信息熵;
步骤二、根据统计的恶意pdf文件和良性pdf文件的信息熵值的最大值、最小值和平均值以及经验值设置阈值α,将每个pdf文件的信息熵与阈值α比较,把信息熵高于α的pdf文件作为正常文件,把信息熵低于α的pdf文件作为可疑文件;
步骤三、利用origami分析提取可疑文件中常用于恶意攻击的javascript和结构特征;
步骤四、利用c5.0决策树算法进行分类。
作为优选:上述步骤一具体为:首先用pdfparser将待检pdf文件转换成二进制字节文件,然后计算每个pdf文件的信息熵。
作为优选:上述步骤三具体为:首先利用origami分析可疑文件的结构并搜索恶意特征和结构的一般特征,然后再分析可疑文件的javascript代码并搜索恶意特征。
作为优选:上述步骤四具体为:首先把每个pdf文件用一个向量表示,该向量由结构的一般特征、结构的动态特征和javascript特征组成;然后将向量、类别输入到c5.0决策树进行分类。
实施例:
为了验证本方法的效果,本发明人设计了相应的实施例,一方面实验设计了不同参数对模型检测效果的影响,另一方面与目前采用较多的恶意pdf文件检测模型:基于javascript的检测模型(pjscan)和基于结构特征的检测模型(pdfms)进行比较。
检测数据集采用于contagiodump,共11207个恶意文件和9745个正常文件,其中有10310个恶意样本中嵌入javascript,占恶意样本的92%。正式检测通过10折交叉验证重复10次。
对比一:为验证本发明在基于不同攻击方式下的检测性能,借此来评价基于信息熵下javascript和结构特征的恶意pdf检测方法是否有利于提高恶意检测的检测精度。实验结果如表1所示。由表1可知,本文方法使检测率达到98.73%,误检率为1.8%。pjscan的检测率(tpr)为71.94%,误检率(fpr)为1.1%。pdfms的检测率为99.55%,误检率为2.5%。虽然本文提出的方法误检率高于pdfm,但是检测率比pjscan高26.79%。由此可知,本文提出的方法合理有效,并且在有效地检测出基于恶意javascropt攻击的恶意pdf文件的同时,又能够有效检测出基于非javascropt攻击的恶意pdf文件。
表1不同算法检测精度与检测时间比较
对比二:为验证本发明在基于不同攻击方式的检测时间,借此来评价利用pdf的javascript特征与结构特征进行恶意检测的方法是否有利于减少恶意检测的时间消耗。表1给出了本文方法与pdfms和pjscan的准确率(tpr)、误检率(fpr)和检测时间(t(s))的比较。由表1可以看出,pdfms耗费的检测时间是最多的为2330s;pjscan耗费的检测时间居中,为2247s;本发明所提的方法耗费检测时间最少,为1857s,比pdfms少473s,比pjscan少390s,综上为本发明所提方法在检测时间上均优于pdfms和pjscan。
本发明提供的基于信息熵下javascript和结构特征的恶意pdf检测方法基本原理如下:为了减少时间消耗,首先利用信息熵筛选出可疑文件和正常文件,然后只针对可疑文件进行检测;然后,为了扩大检测范围,在检测时,提取结构特征和javascript特征;最后使用c5.0决策树算法进行分类。
以上对本发明的实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
- 还没有人留言评论。精彩留言会获得点赞!