基于遗传算法的流体机械并行仿真程序进程映射方法与流程
本发明属于计算流体力学与计算机交叉领域,特别涉及基于遗传算法的流体机械并行仿真程序进程映射方法。
背景技术:
计算流体力学(cfd,computationalfluiddynamics)是一门采用数值计算方法直接求解流动主控方程来解释各种流动现象的学科,是典型的高性能数值计算应用领域。随着cfd技术的不断进步以及超级计算机计节点规模的不断扩大,需要模拟的流体机械应用领域的物理过程和几何模型越来越复杂,涉及的网格规模也更庞大,已有流体机械并行仿真程序使用十万核进行模拟计算。在流体机械并行仿真程序中,计算区域被划分为很多网格,这些计算网格被分配到位于不同的计算核心上的进程进行计算,而位于不同计算核心之间的进程通过消息传递接口mpi(messagepassinginterface)进行通信。为了满足高性能互连网络大规模,低延迟,高吞吐率的要求,超级计算机多采用胖树(fattree)网络拓扑结构,在这种网络拓扑结构中,计算节点位于树的叶子节点上,路由节点位于树的中间节点上,负责链接不同层次的节点,进行节点之间消息的传输和发送。这种多层次的网络拓扑架构导致了mpi进程在不同层次的计算节点间进行消息传递的通信代价差异较大。当流体机械并行仿真程序的进程数量达到一定规模后,进程间的通信开销将成为程序性能提升的瓶颈。因此,寻找一种映射策略,将流体机械并行仿真程序的各个mpi进程合理分配到超级计算机的计算节点上,对解决大规模流体机械并行仿真程序的通信瓶颈问题有重要的意义。
mpi进程映射是一个np难的问题,目前已有研究人员通过图论方法、启发式算法和数学规划方法来寻求接近最优的进程映射方法。但是这些方法存在容易陷入局部最优解、搜索效率低的问题,当并行程序的进程规模增大时,求解最优映射的时间开销过长。
技术实现要素:
本发明的目的在于提供基于遗传算法的流体机械并行仿真程序进程映射方法,以解决上述问题。
为实现上述目的,本发明采用以下技术方案:
基于遗传算法的流体机械并行仿真程序进程映射方法,包括以下步骤:
步骤1,在流体机械并行仿真程序中,不同进程之间使用消息传递接口mpi进行通信。收集流体机械并行仿真程序各个mpi进程间的通信亲和度信息,并记录到日志文件中;
步骤2,从步骤1得到的日志文件中整理各个mpi进程间的通信亲和度,建立一个进程通信模式矩阵g∈rn×n,n表示流体机械并行仿真程序中mpi进程个数,其中的元素g(i,j)(i∈n,j∈n)表示进程i和进程j的通信亲和度。
步骤3,pingpong是测试任意两个计算单元之间进行发送ping并接收消息pong来回所需时间的程序。通过pingpong测试对用户申请到的计算单元间的通信带宽和通信延迟数据进行收集,对收集到的数据进行正规化整合,得到不同计算单元间的通信距离;
步骤4,定义流体机械并行仿真程序的通信开销模型z;如公式1所示,g为步骤2提到的进程通信模式矩阵,h为步骤3提到的计算单元通信距离矩阵,π为mpi进程和计算单元间的一对一映射,g(i,j)为进程i和进程j的通信亲和度,h(π(i),π(j))表示进程i和进程j所在计算单元之间的通信距离,通过计算得到流体机械并行仿真程序在进程映射π下的通信总开销z;
步骤5,将步骤2得到的进程通信模式矩阵g和步骤3得到的计算单元通信距离矩阵h整理到一个文件中,使用混合并行遗传算法根据该文件中的数据求解最优的进程映射策略;将流体机械并行仿真程序的进程映射方案定义为个体,利用迭代的方式对种群中的个体进行选择、交叉、变异、模拟退火操作,生成使得通信开销z最小的进程映射方案;
步骤6,根据步骤5中得到的进程映射策略,静态绑定mpi进程到指定计算节点,重新运行流体机械并行仿真程序。
进一步的,步骤3中,建立一个计算单元通信距离矩阵h∈rn×n,n表示计算单元的个数,与流体机械并行仿真程序中的mpi进程个数相同,其中的元素h(p,q)(p∈n,q∈n)为计算单元p和计算单元q的通信距离。
进一步的,步骤1中,对mpi进程间传输消息的大小和通信的频次进行正规化整合,得到mpi进程间通信亲和度;通过在流体机械并行仿真程序编译时链接进程通信插桩库,将程序中mpi函数的调用过程引导到进程通信插桩库中,从而利用进程通信插桩库中的相应函数捕获程序运行过程中mpi进程的通信亲和度,并记录到日志文件中。
进一步的,步骤5具体包括以下步骤:
1)编码;对混合并行遗传算法中的个体采用实数编码,定义一个长度为n的实数编码序列tp,n表示进程数目和计算单元的数目;序列tp中,进程号所在的位置表示该进程所对应的计算单元;tp(k)=pi表示将流体机械并行仿真程序中的进程pi(i∈n)映射到计算单元k上,其中k为计算单元的编号,pi表示进程编号,k∈[0,n-1],pi∈[0,n-1];在混合并行遗传算法中,一个个体表示一种进程编号序列,对应一种进程映射方案;实数编码表示流体机械模拟程序中进程号和计算单元的映射关系;
2)建立适应度函数;选择步骤4提到的公式1作为适应度函数;适应度函数越小的个体表示其对应的进程映射策略通信开销越小,在混合并行遗传算法运行结束时,适应度函数最小的个体就是要求的最优个体,对应使得通信开销最小的进程映射方案;
3)初始化;在混合并行遗传算法中将0号进程称为主进程,其他进程称为从进程;用户在算法运行前,在配置文件中设置遗传算法的配置参数,包括种群规模、最大进化代数、交叉概率、选择概率、变异概率和模拟退火算法的初始温度t0和终止温度ts;算法初始时主进程读入配置文件,并将其中的配置参数通过mpi依次发送给其它从进程;从进程在接收到配置参数后,独立地在本进程内产生初始种群;
4)在从进程中生成多个线程;openmp是一个针对共享内存架构的多线程编程标准,是基于显示编译指导语句的多线程程序编程接口。各从进程调用openmp编译指导语句生成多个线程,这些线程并行执行5)~9),在主线程中保留当前种群中适应度函数最小的个体;
5)选择操作;采用精英保留和轮盘赌选择两种方法进行选择操作;精英选择是指在算法执行过程中,每一次迭代时,当前种群中的最优个体不参与遗传及模拟退火操作,而是用它来替换本次迭代结束后种群中适应度最大的个体;轮盘赌选择能保证当前种群中适应度函数值较小的个体有更大的概率被遗传到下一代;
6)交叉操作;在种群中随机选择两个个体s1和s2进行交叉操作:随机选择一个交叉点r,r∈(0,n-1),n为个体的长度,对应于流体机械并行仿真程序的mpi进程个数;以此交叉点r将s1和s2分别划分为两部分:前一部分长度为r,后一部分长度为n-r;将s1的后部分基因与s2的后部分基因进行交换,然后重新调整,保证两个个体中的基因没有重复出现,得到两个新的个体s1’和s2’,将它们放到种群中;
7)变异操作;在种群中随机选择一个个体s,在s的序列中随机选择两个位置的基因,将它们的位置进行交换,得到一个新的个体s’,将它放到种群中;
8)模拟退火操作;根据3)中的初始温度t0和终止温度ts,在每次迭代的最后一步,根据公式(2)计算当前的温度ti,其中k表示总的迭代步数,i表示当前迭代代数;
ti=0.6×(1+cos(i×π÷k))×(t0-ts)+ts(2)
模拟退火的主要实现方式为:对于当前迭代产生的种群中的个体,依次计算它们的适应度函数值并进行比较;具体流程为,记最小的适应度函数值为z_best,对于新的个体,其适应度函数值为z_new,根据公式(3)计算适应度函数变化量δ,当δ<0时,令z_best=z_new,接受该个体,并将其加入到种群中;当δ>0时,以概率p接受该个体,p的计算方式如公式(4)所示;
δ=z_new-z_best(3)
p=exp(δ/ti)(4)
9)各个进程执行优秀个体迁移操作;在主进程中设置一个优秀个体接收缓冲区,每隔一定的进化代数d,各个从进程就调用mpi的发送函数,向主进程的优秀个体接收缓冲区发送当前种群中的最优个体;主进程在接收到各个从进程发送的最优个体后,根据它们的适应度函数值进行排序,将适应度函数值最小的个体以广播的方式发送给各个从进程;从进程接收到主进程发送的最优个体后,用最优个体替换掉当前种群中的适应度函数值最大的个体;
10)判断混合并行遗传算法是否结束;判断当前进化代数i,当i等于3)中设置的最大进化代数时,算法结束,由主进程输出求解得到的最优个体,即最优的进程号序列,否则转到4)继续执行。
与现有技术相比,本发明有以下技术效果:
本发明提供的基于遗传算法的流体机械并行仿真程序进程映射方法,首先考虑到目前超级计算机中节点的使用方式多为独占式,计算节点分配给用户后,不能为其他用户使用。因此用户可以利用已经申请到的节点资源,在流体机械并行仿真程序正式运行之前,通过本发明提出的进程映射方法在非常短的时间内求得一种最优的进程映射策略。在流体机械并行仿真程序正式运行时,根据这种进程映射策略将mpi进程静态绑定到已经申请到的计算节点上,减小了流体机械并行仿真程序在运行期间的通信开销,提升了程序的执行效率。
其次,本发明通过mpi+openmp混合编程的方式设计了求解进程映射策略时用到的遗传算法,实现了进程和线程的两级并行,能够充分利用超级计算机中不同层次的计算资源,同时也充分挖掘了遗传算法的内在并行性,从根本上提升了进程映射问题的求解质量和求解速度,使得进程映射方法能更好地应用于大规模流体机械并行仿真程序中,有效解决了大规模流体机械并行仿真程序的通信瓶颈问题。
最后通过在混合并行遗传算法的每次进化中引入模拟退火算法,使得算法能够以一定的概率接受进化过程中产生的较差个体,保证了种群的多样性,进一步解决了传统遗传算法容易陷入早熟的不足,使得混合并行遗传算法的求解质量更高。
本发明在引入进程映射方法解决流体机械并行仿真程序通信瓶颈问题的同时,通过设计混合并行遗传算法,引入模拟退火算法等方式,优化了映射算法求解进程映射策略时的求解质量和求解速度,能够在短时间内求到高质量的进程映射策略,将这种进程映射策略应用到流体机械并行仿真程序中,有效减少了流体机械并行仿真程序的通信开销,实现了通信优化的效果。
附图说明
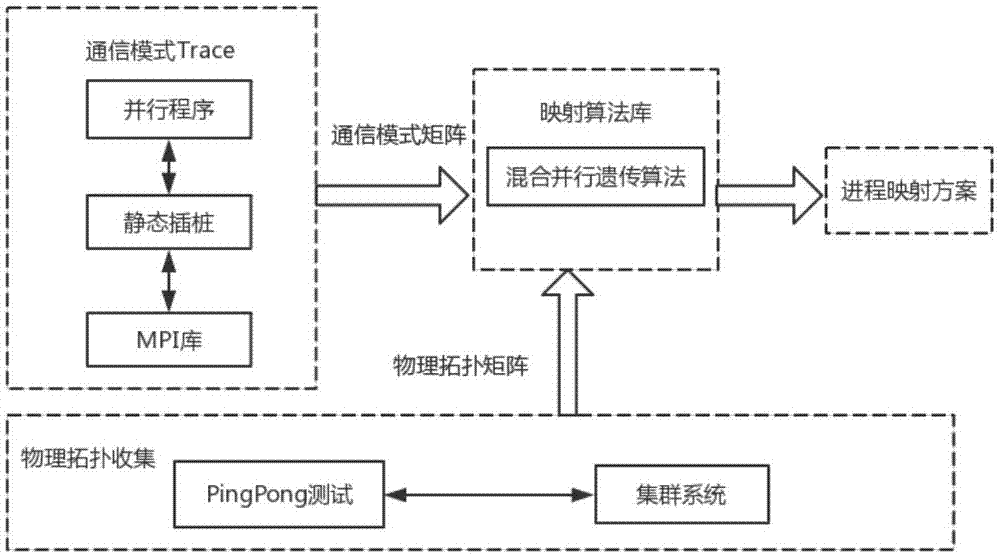
图1为进程映射方法的框架示意图
图2为混合并行遗传算法的流程图
具体实施方式
以下结合附图对本发明进一步说明:
请参阅图1和图2,基于遗传算法的流体机械并行仿真程序进程映射方法,其特征在于,包括以下步骤:
步骤1,在流体机械并行仿真程序中,不同进程之间使用消息传递接口mpi(messagepassinginterface)进行通信。收集流体机械并行仿真程序各个mpi进程间的通信亲和度信息,并记录到日志文件中;
步骤2,从步骤1得到的日志文件中整理各个mpi进程间的通信亲和度,建立一个进程通信模式矩阵g∈rn×n,n表示流体机械并行仿真程序中mpi进程个数,其中的元素g(i,j)(i∈n,j∈n)表示进程i和进程j的通信亲和度。
步骤3,pingpong是测试任意两个计算单元之间进行发送(ping)并接收消息(pong)来回所需时间的程序。通过pingpong测试对用户申请到的计算单元间的通信带宽和通信延迟数据进行收集,对收集到的数据进行正规化整合,得到不同计算单元间的通信距离;
步骤4,定义流体机械并行仿真程序的通信开销模型z;如公式1所示,g为步骤2提到的进程通信模式矩阵,h为步骤3提到的计算单元通信距离矩阵,π为mpi进程和计算单元间的一对一映射,g(i,j)为进程i和进程j的通信亲和度,h(π(i),π(j))表示进程i和进程j所在计算单元之间的通信距离,通过计算得到流体机械并行仿真程序在进程映射π下的通信总开销z;
步骤5,将步骤2得到的进程通信模式矩阵g和步骤3得到的计算单元通信距离矩阵h整理到一个文件中,使用混合并行遗传算法根据该文件中的数据求解最优的进程映射策略;将流体机械并行仿真程序的进程映射方案定义为个体,利用迭代的方式对种群中的个体进行选择、交叉、变异、模拟退火操作,生成使得通信开销z最小的进程映射方案;
步骤6,根据步骤5中得到的进程映射策略,静态绑定mpi进程到指定计算节点,重新运行流体机械并行仿真程序。
2、根据权利要求1所述的基于遗传算法的流体机械并行仿真程序进程映射方法,其特征在于,步骤3中,建立一个计算单元通信距离矩阵h∈rn×n,n表示计算单元的个数,与流体机械并行仿真程序中的mpi进程个数相同,其中的元素h(p,q)(p∈n,q∈n)为计算单元p和计算单元q的通信距离。
3、根据权利要求1所述的基于遗传算法的流体机械并行仿真程序进程映射方法,其特征在于,步骤1中,对mpi进程间传输消息的大小和通信的频次进行正规化整合,得到mpi进程间通信亲和度;通过在流体机械并行仿真程序编译时链接进程通信插桩库,将程序中mpi函数的调用过程引导到进程通信插桩库中,从而利用进程通信插桩库中的相应函数捕获程序运行过程中mpi进程的通信亲和度,并记录到日志文件中。
4、根据权利要求1所述的基于遗传算法的流体机械并行仿真程序进程映射方法,其特征在于,步骤5具体包括以下步骤:
1)编码;对混合并行遗传算法中的个体采用实数编码,定义一个长度为n的实数编码序列tp,n表示进程数目和计算单元的数目;序列tp中,进程号所在的位置表示该进程所对应的计算单元;tp(k)=pi表示将流体机械并行仿真程序中的进程pi(i∈n)映射到计算单元k上,其中k为计算单元的编号,pi表示进程编号,k∈[0,n-1],pi∈[0,n-1];在混合并行遗传算法中,一个个体表示一种进程编号序列,对应一种进程映射方案;实数编码表示流体机械模拟程序中进程号和计算单元的映射关系;
2)建立适应度函数;选择步骤4提到的公式1作为适应度函数;适应度函数越小的个体表示其对应的进程映射策略通信开销越小,在混合并行遗传算法运行结束时,适应度函数最小的个体就是要求的最优个体,对应使得通信开销最小的进程映射方案;
3)初始化;在混合并行遗传算法中将0号进程称为主进程,其他进程称为从进程;用户在算法运行前,在配置文件中设置遗传算法的配置参数,包括种群规模、最大进化代数、交叉概率、选择概率、变异概率和模拟退火算法的初始温度t0和终止温度ts;算法初始时主进程读入配置文件,并将其中的配置参数通过mpi依次发送给其它从进程;从进程在接收到配置参数后,独立地在本进程内产生初始种群;
4)在从进程中生成多个线程;openmp是一个针对共享内存架构的多线程编程标准,是基于显示编译指导语句的多线程程序编程接口。各从进程调用openmp编译指导语句生成多个线程,这些线程并行执行5)~9),在主线程中保留当前种群中适应度函数最小的个体;
5)选择操作;采用精英保留和轮盘赌选择两种方法进行选择操作;精英选择是指在算法执行过程中,每一次迭代时,当前种群中的最优个体不参与遗传及模拟退火操作,而是用它来替换本次迭代结束后种群中适应度最大的个体;轮盘赌选择能保证当前种群中适应度函数值较小的个体有更大的概率被遗传到下一代;
6)交叉操作;在种群中随机选择两个个体s1和s2进行交叉操作:随机选择一个交叉点r,r∈(0,n-1),n为个体的长度,对应于流体机械并行仿真程序的mpi进程个数;以此交叉点r将s1和s2分别划分为两部分:前一部分长度为r,后一部分长度为n-r;将s1的后部分基因与s2的后部分基因进行交换,然后重新调整,保证两个个体中的基因没有重复出现,得到两个新的个体s1’和s2’,将它们放到种群中;
7)变异操作;在种群中随机选择一个个体s,在s的序列中随机选择两个位置的基因,将它们的位置进行交换,得到一个新的个体s’,将它放到种群中;
8)模拟退火操作;根据3)中的初始温度t0和终止温度ts,在每次迭代的最后一步,根据公式(2)计算当前的温度ti,其中k表示总的迭代步数,i表示当前迭代代数;
ti=0.6×(1+cos(i×π÷k))×(t0-ts)+ts(2)
模拟退火的主要实现方式为:对于当前迭代产生的种群中的个体,依次计算它们的适应度函数值并进行比较;具体流程为,记最小的适应度函数值为z_best,对于新的个体,其适应度函数值为z_new,根据公式(3)计算适应度函数变化量δ,当δ<0时,令z_best=z_new,接受该个体,并将其加入到种群中;当δ>0时,以概率p接受该个体,p的计算方式如公式(4)所示;
δ=z_new-z_best(3)
p=exp(δ/ti)(4)
9)各个进程执行优秀个体迁移操作;在主进程中设置一个优秀个体接收缓冲区,每隔一定的进化代数d,各个从进程就调用mpi的发送函数,向主进程的优秀个体接收缓冲区发送当前种群中的最优个体;主进程在接收到各个从进程发送的最优个体后,根据它们的适应度函数值进行排序,将适应度函数值最小的个体以广播的方式发送给各个从进程;从进程接收到主进程发送的最优个体后,用最优个体替换掉当前种群中的适应度函数值最大的个体;
10)判断混合并行遗传算法是否结束;判断当前进化代数i,当i等于3)中设置的最大进化代数时,算法结束,由主进程输出求解得到的最优个体,即最优的进程号序列,否则转到4)继续执行。
实施例:
步骤a、编译流体机械并行仿真程序时链接进程通信插桩库,在程序运行期间收集并记录mpi进程间的通信信息,包括进程间传输消息的大小和通信的频次,得到一个日志文件。
步骤b、从步骤a得到的日志文件中整理各个进程间的通信信息,建立一个进程通信模式矩阵g∈rn×n,其中的元素g(i,j)表示进程i和进程j的通信亲和度,是进程间通信总量和通信频率的组合。本实施例中为了方便计算通信开销,将进程间的通信亲和度定义为公式(5),其中volumei,j为进程i和进程j间的通信总量,pi,j为进程i和进程j的通信次数。
步骤c、对用户申请到的计算资源建立一个计算单元通信距离矩阵h∈rn×n,其中的元素h(π(i),π(j))表示进程i和进程j所在计算单元之间的通信距离,通信距离由pingpong测试得到的通信带宽和延迟数据整合得到。
步骤d、将步骤b得到的进程通信模式矩阵g和步骤c得到的计算单元通信距离矩阵h整理到一个文件中,使用混合并行遗传算法根据该文件求解最优的进程映射策略。
步骤d1、编码。本实施例中对混合并行遗传算法中的个体采用实数编码,定义一个长度为36的实数编码序列tp,36为本实施例中流体机械并行仿真程序的进程数目和计算单元的数目。如序列(0,35,8,9,4,21,25,31,…)表示将流体机械并行仿真程序中的进程0、35、8、9、4、21、25、31分别映射到编号为0、1、2、3、4、5、6、7的计算单元上。
步骤d2、初始化。用户在算法运行前,在配置文件中设置遗传算法的配置参数,本实施例中设置的种群规模为1000、最大进化代数为5000、交叉概率为0.9、变异概率为0.05,模拟退火算法的初始温度为1000,终止温度为0.0001。算法初始时主进程读入配置文件,并将其中的配置参数通过mpi依次发送给其它从进程。从进程在接收到配置参数后,独立地在本进程内产生个体数量为1000的初始种群,种群中的个体随机产生,其形式为d1提到长度为36的实数编码序列tp。
步骤d3、在从进程中生成多个线程。如图2所示,各从进程调用openmp编译指导语句生成多个线程,这些线程并行执行选择、交叉、变异、模拟退火操作并计算适应度函数值,在主线程中保留当前种群中适应度函数值最小的个体。
步骤d4、各个进程执行迁移操作。为了保持种群的多样性,本实施例在混合遗传算法运行中,在主进程中设置一个优秀个体接收缓冲区,每隔10代进行一次种群间优秀个体的迁移,各个从进程调用mpi的发送函数,向主进程的优秀个体接收缓冲区发送当前种群中的最优个体。主进程在接收到各个从进程发送的最优个体后,根据它们的适应度函数值进行排序,将适应度函数值最小的个体以广播的方式发送给各个从进程。从进程接收到主进程发送的最优个体后,用最优个体替换掉当前种群中的适应度函数值最大的个体。在算法技术时,主进程中始终保留着进化过程中最好的35个个体。
步骤d5、判断混合并行遗传算法是否结束。判断当前进化次数i,当i等于最大进化代数5000时,算法结束,由主进程输出求解得到的最优个体,即最优的进程号序列,否则转到d3继续执行。
步骤e、根据步骤d中得到的最优进程映射策略,将36个mpi进程静态绑定到36个计算单元上,重新运行流体机械并行仿真程序。实验结果表明,该基于进程映射的流体机械并行仿真程序的通信优化方法,通过综合考虑流体机械并行仿真程序的进程间通信模式和超级计算机不同计算单元间的通信代价,建立了一种通信开销模型,同时充分利用超级计算机丰富的计算资源,使用混合并行遗传算法在非常短的时间内求得了使得通信开销最小的进程映射策略,将这种进程映射策略运用到流体机械并行仿真程序上后,程序的通信开销和执行时间减少20%以上,达到了对程序进行通信优化的目标。
- 还没有人留言评论。精彩留言会获得点赞!