一种卷积神经网络的建立装置及方法与流程
本发明涉及嵌入式系统的大数据量深度学习计算领域,特别涉及一种采用现场可编程门阵列(fpga)上实现卷积神经网络的建立装置及方法。
背景技术:
卷积神经网络(cnn)是近年发展起来,并引起广泛重视的一种高效识别方法。特别是在模式分类领域,cnn由于避免了对特征图的复杂前期预处理,可以直接输入原始特征图,并得到最终的特征图的分类结果,因而得到了更为广泛的应用。由于cnn涉及运算的特征图的数据量大且运算复杂,一般都采用大型计算机编程实现,这会增加实现的难度及费用。
技术实现要素:
有鉴于此,本发明实施例提供一种cnn的建立装置,该装置采用fpga简单实现cnn的特征图的卷积神经运算。
本发明实施例还提供一种cnn的建立方法,该方法采用fpga简单实现cnn的特征图的卷积神经运算。
本发明实施例是这样实现的:
一种卷积神经网络的建立装置,在现场可编程门阵列fpga设置2~64个卷积计算模块,分别处理不同的输出通道;在每个卷积计算模块中包括:特征图输入缓存单元、特征图加载单元、特征图重排序单元、卷积运算单元、权值缓存单元及权值加载单元、输入通道累加单元及特征图输出缓存单元;其中,
特征图输入缓存单元,用于缓存特征图,将特征图的9个像素并行发送给特征图加载单元;
特征图加载单元,用于并行接收特征图中的9个像素并寄存;
特征图重排序单元,用于从特征图加载单元中接收特征图中的9个像素,并按照卷积计算所采用的像素顺序进行重排序;
权值缓存单元,用于缓存9个像素对应的权值,并行发送给权值加载单元;
权值加载单元,用于并行接收对应9个像素的权值并寄存;
卷积运算单元,用于根据从特征图重排序单元提取的重排序的9个像素,及从权值加载单元接收对应于9个像素的权值,并行进行9个像素的卷积累加运算,得到像素累加后的卷积值,输出到输入通道累加单元;
输入通道累加单元,用于对卷积运算单元输出的像素累加后的卷积值进行输入通道累加,最终得到经过卷积神经运算的特征图;
特征图输出缓存单元,用于接收经过卷积神经运算的特征图,并进行缓存。
一种卷积神经网络的建立方法,包括:
根据特征图的数据量,在fpga上设置了2~64个卷积计算模块,分别处理不同的输出通道;
在每个卷积计算模块中,将特征图的9像素输入到设置的卷积运算单元中;
对于每个像素,由设置的卷积运算单元根据该像素对应的权值进行卷积运算,得到该像素的卷积值后,对9个像素的卷积值进行像素累加;
将像素累加后的卷积值进行输入通道累加,最终得到经过了cnn运算的特征图,输出。
如上可见,本发明实施例根据特征图的数据量,在fpga上设置了2~64个相同的卷积计算模块,分别处理不同的输出通道;在每个卷积计算模块中,将特征图的9个像素输入到设置的卷积运算单元中;对于每个像素,由设置的卷积运算单元根据该像素对应权值进行卷积运算,得到该像素的卷积值;然后对特征图的9个像素的卷积值进行像素累加;再将像素累加后的卷积值进行输入通道累加;最终得到经过了cnn运算的特征图,输出。这样,就采用fpga简单实现了cnn的特征图的卷积神经运算。
附图说明
图1为本发明实施例提供的cnn的建立装置结构示意图;
图2为本发明实施例提供的卷积计算模块结构示意图;
图3为本发明实施例提供的cnn的建立方法流程图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本发明进一步详细说明。
为了简单且容易的情况下,实现cnn的卷积神经运算,本发明实施例采用fpga实现,具体地,根据特征图的数据量,在fpga上设置了2~64个相同的卷积计算模块;在每个卷积计算模块中,将特征图的9个像素输入到设置的卷积运算单元中;对于每个像素,由设置的卷积运算单元根据该像素对应权值进行卷积运算,得到该像素的卷积值;然后对特征图的9个像素的卷积值进行像素累加;再将像素累加后的卷积值进行输入通道累加;最终得到经过了cnn运算的特征图,输出。这样,就采用fpga简单实现了cnn的特征图的卷积神经运算,简单且降低费用。
以下以具体采用32个卷积计算模块对本发明实施例进行详细说明,但是需要注意的是,卷积计算模块的数量范围在2~64个,这里并不限制。
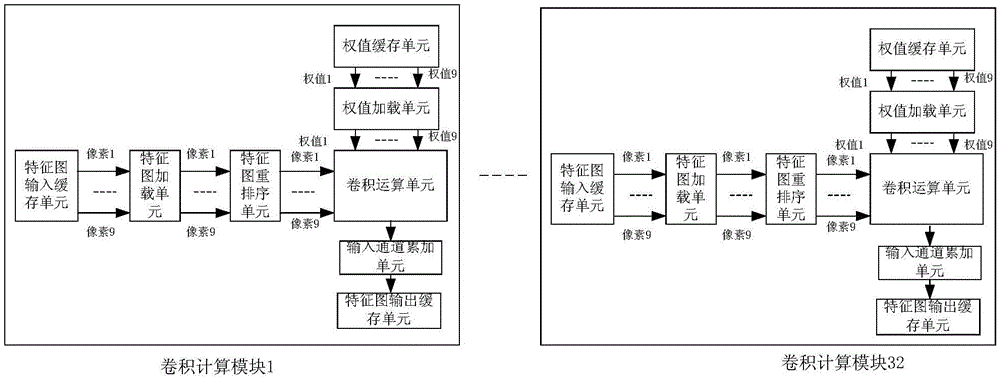
图1为本发明实施例提供的cnn的建立装置结构示意图:在fpga上设置的32个相同的卷积计算模块,分别处理不同的输出通道;在每个卷积计算模块中包括:特征图输入缓存单元、特征图加载单元、特征图重排序单元、卷积运算单元、权值缓存单元及权值加载单元、输入通道累加单元及特征图输出缓存单元;其中,
特征图输入缓存单元,用于缓存特征图,将特征图的9个像素并行发送给特征图加载单元;
特征图加载单元,用于并行接收特征图中的9个像素并寄存;
特征图重排序单元,用于从特征图加载单元中接收特征图中的9个像素,并按照卷积计算所采用的像素顺序进行重排序;
权值缓存单元,用于缓存9个像素对应的权值,并行发送给权值加载单元;
权值加载单元,用于并行接收对应9个像素的权值并寄存;
卷积运算单元,用于根据从特征图重排序单元提取的重排序的9个像素,及从权值加载单元接收对应于9个像素的权值,并行进行9个像素的卷积累加运算,得到像素累加后的卷积值,输出到输入通道累加单元;
输入通道累加单元,用于对卷积运算单元输出的像素累加后的卷积值进行输入通道累加,最终得到经过卷积神经运算的特征图;
特征图输出缓存单元,用于接收经过卷积神经运算的特征图,并进行缓存。
在该装置中,所述特征图输入缓存单元在每个卷积计算模块中有16个,采用在fpga上的块随机存取存储器(bram)实现,特征图加载单元采用fpga上的reg类型的寄存器实现,具体由9个reg类型的寄存器构成。
在该装置中,卷积运算单元采用设置在fpga上的处理元件(pe)构成,所述pe是由数字信号处理(dsp)实现,具体卷积运算单元由9个pe构成。
在该装置中,权值缓存单元采用bram实现,具体由9个bram构成,权值加载单元采用fpga上的reg类型的寄存器实现,具体由9个reg类型的寄存器实现。
在该装置中,特征图输出缓存单元采用bram实现。
图2为本发明实施例提供的卷积计算模块结构示意图,如图所示,其中,特征图输入缓存单元采用ibram表示,含义是特征图的bram,特征图加载单元采用ireg表示,含义是特征图的reg类型的寄存器;权值缓存单元采用wbram,含义是权值的bram,权值加载单元采用wreg表示,表示的是权值的reg类型的寄存器;卷积运算单元采用pe表示。
本发明实施例采用了32个卷积计算模块,同时处理32个输出通道及每个卷积计算模块可同时进行9个像素点的乘加运算,处理能力强大,可以处理任意大小的图片。
图3为本发明实施例提供的cnn的建立方法流程图,其具体步骤为:
步骤301、根据特征图的数据量,在fpga上设置了32个相同的卷积计算模块,分别处理不同的输出通道;
步骤302、在每个卷积计算模块中,将特征图的9像素输入到设置的卷积运算单元中;
步骤303、对于每个像素,由设置的卷积运算单元根据该像素对应的权值进行卷积运算,得到该像素的卷积值后,对9个像素的卷积值进行像素累加;
步骤304、将像素累加后的卷积值进行输入通道累加,最终得到经过了cnn运算的特征图,输出。
在该方法中,在步骤302之前,还包括:所述特征图的9个像素经过缓存后,再发送给fpga的reg类型寄存器寄存及按照卷积计算所采用的像素顺序重排序。
在该方法中,在步骤303之前,还包括获取对应9个像素的权值过程:
9个像素对应的权值经过缓存后,再发送给fpga的reg类型权值寄存器寄存后,提供给卷积运算单元进行卷积运算。
在该方法中,所述卷积运算单元采用设置在fpga上的pe实现,具体是采用dsp实现。
该方法还包括:输出后将经过了cnn运算的特征图进行缓存,具体采用bram进行缓存。
可以看出,本发明实施例采用了fpga实现了特征图的卷积神经网络运算,适用于深度学习芯片场景。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!