一种真实场景图像合成方法及系统与流程
本发明涉及图像合成技术领域,特别是涉及一种真实场景图像合成方法及系统。
背景技术:
在图像合成领域中,基于深度学习的真实场景图像合成技术正逐渐应用的越来越广。真实场景图像合成是基于语义布局图中物体对象分割的信息来合成逼近于真实场景图像的一种视觉图像合成技术。真实场景图像合成方法集成了深度学习、模式识别和数字图像处理等多种专业技术。真实场景图像合成的关键有三点:(1)全局的协调性;(2)网络模型的存储容量;(3)高分辨率。深度学习能够实现图像全局的特征提取,同时也能提高网络模型的参数数量即网络模型的存储容量和生成高分辨率的图像,极大的提高了真实场景图像合成的真实性。真实场景图像合成方法所使用的深度学习网络结构的设计往往会直接影响到真实场景图像合成的效果。因此设计一种合适的深度学习网络结构是提高场景图像合成真实度的重要任务之一。
目前,真实场景图像合成方法包括:(1)使用u-net(u网)作为条件生成对抗网络(generativeadversarialnets,gans)的生成器,并且当将灰度和二值边缘图像转换为彩色图像时,该方法可以实现期望的性能。然而,当该方法将语义图转换为摄影级真实感图像(即真实场景图像)时,其合成速度和视觉质量有待提高。(2)采用用于合成摄影级图像的级联细化网络(cascadedrefinementnetworks,crns),将语义布局转换为摄影级真实感图像。尽管crns具有巨大的存储容量,它可以生成比方法(1)更逼真的图像,但是在训练和预测阶段花费了大量时间,不能实现真实场景图像的快速高效合成。总之,现有的合成方法效率较低,且合成的摄影级真实感图像的真实度和图像的视觉质量也有待于提高。
技术实现要素:
基于此,有必要提供一种真实场景图像合成方法及系统,以快速有效的合成真实感更强的摄影级场景图像,提高合成图像的真实感和视觉质量,扩大应用范围与应用场景。
为实现上述目的,本发明提供了如下方案:
一种真实场景图像合成方法,包括:
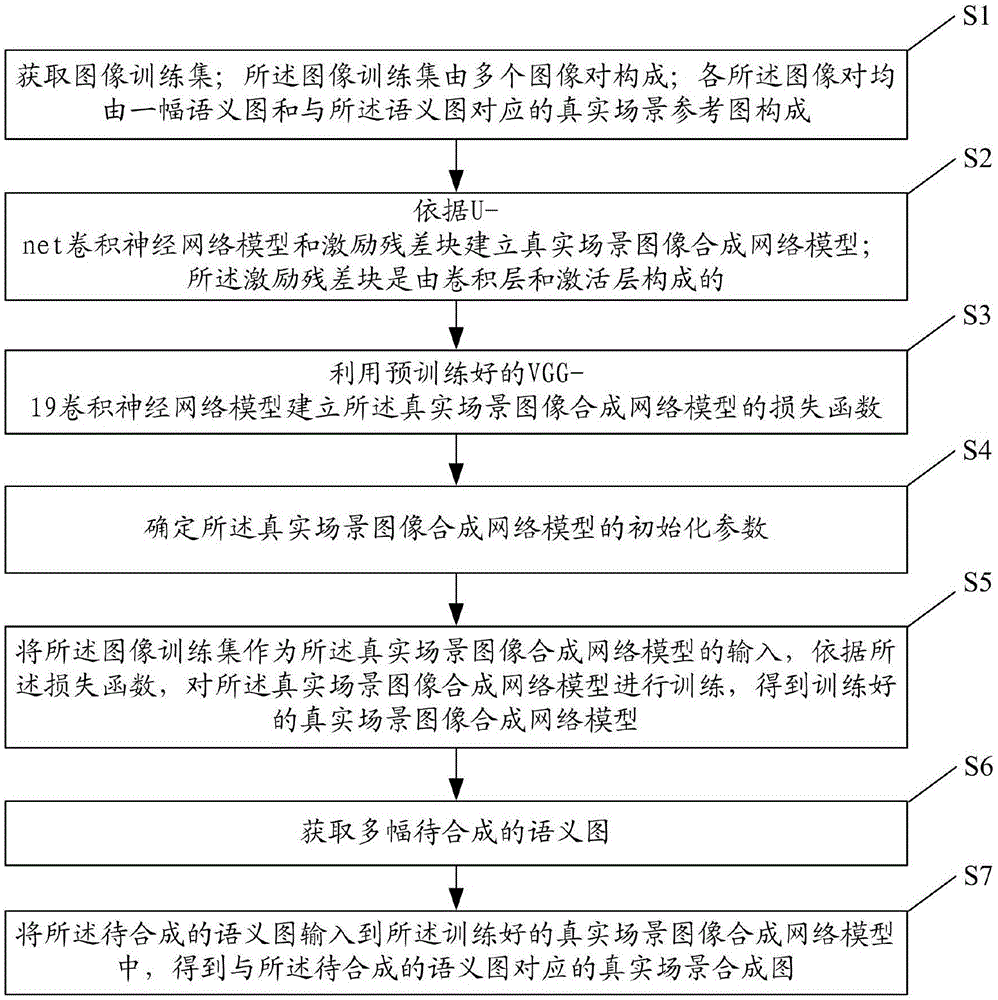
获取图像训练集;所述图像训练集由多个图像对构成;各所述图像对均由一幅语义图和与所述语义图对应的真实场景参考图构成;
依据u-net卷积神经网络模型和激励残差块建立真实场景图像合成网络模型;所述激励残差块是由卷积层和激活层构成的;
利用预训练好的vgg-19卷积神经网络模型建立所述真实场景图像合成网络模型的损失函数;
将所述图像训练集作为所述真实场景图像合成网络模型的输入,依据所述损失函数,对所述真实场景图像合成网络模型进行训练,得到训练好的真实场景图像合成网络模型;
获取多幅待合成的语义图;
将所述待合成的语义图输入到所述训练好的真实场景图像合成网络模型中,得到与所述待合成的语义图对应的真实场景合成图。
可选的,所述依据u-net卷积神经网络模型和激励残差块建立真实场景图像合成网络模型,具体包括:
建立u-net卷积神经网络模型;所述u-net卷积神经网络模型包括多个层级;
建立激励残差块;
在所述u-net卷积神经网络模型的每两个相邻的层级之间嵌入所述激励残差块,构成真实场景图像合成网络模型。
可选的,所述将所述图像训练集作为所述真实场景图像合成网络模型的输入,依据所述损失函数,对所述真实场景图像合成网络模型进行训练,得到训练好的真实场景图像合成网络模型,具体包括:
将所述训练集中的第i张语义图输入到当前的真实场景图像合成网络模型中,得到所述第i幅语义图对应的真实场景合成图;其中i为大于或等于1的整数;所述当前的真实场景图像合成网络模型是第j次训练更新后的真实场景图像合成网络模型;其中j为大于或等于0的整数;
判断j是否小于预设最大训练次数;
若是,则将所述真实场景合成图和所述第i幅语义图对应的真实场景参考图输入到所述损失函数中,得到损失值;
将所述损失值输入到adam优化器中,采用adam优化算法更新所述真实场景图像合成网络模型;再令i=i+1,j=j+1,并返回所述将所述训练集中的第i幅语义图输入到当前的真实场景图像合成网络模型中,得到所述第i幅语义图对应的真实场景合成图;
若否,则将当前的真实场景图像合成网络模型作为训练好的真实场景图像合成网络模型。
可选的,所述激励残差块,具体为:
f(x)=x·sigmoid(β(x))
其中,x表示输入的语义图;sigmoid是一个激活函数,其函数表达式为sigmoid(x)=1/(1+exp(-x));β表示激励残差块中的卷积层;β(x)表示对输入的语义图做卷积操作后的图像。
可选的,所述损失函数,具体为:
其中,lf表示损失值;f表示真实场景图像合成网络模型输出的真实场景合成图,g表示真实场景参考图;φ表示预训练好的vgg-19卷积神经网络模型,φl表示预训练好的vgg-19卷积神经网络模型中的第l层,φl(f)表示将f输入到预训练好的vgg-19卷积神经网络中,第l层卷积层后输出的特征图,φl(g)表示将g输入到预训练好的vgg-19卷积神经网络中,第l层卷积层输出的特征图;l的取值为{0,1,2,3,4,5};φ0表示预训练好的vgg-19网络的输入图,φ1至φ5表示预训练好的vgg-19中五个卷积层对应输出的特征图;λl表示第l层的损失值对应的权重系数,λl的取值为{1/1.6,1/2.3,1/1.8,1/2.8,10/0.8}。
可选的,在所述将所述图像训练集作为所述真实场景图像合成网络模型的输入,依据所述损失函数,对所述真实场景图像合成网络模型进行训练,得到训练好的真实场景图像合成网络模型之前,还包括:
确定所述真实场景图像合成网络模型的初始化参数;所述初始化参数包括学习率、最大训练次数、语义图的个数、语义图的宽度和语义图的高度。
本发明还提供了一种真实场景图像合成系统,包括:
第一获取模块,用于获取图像训练集;所述图像训练集由多个图像对构成;各所述图像对均由一幅语义图和与所述语义图对应的真实场景参考图构成;
合成模型建立模块,用于依据u-net卷积神经网络模型和激励残差块建立真实场景图像合成网络模型;所述激励残差块是由卷积层和激活层构成的;
损失函数建立模块,用于利用预训练好的vgg-19卷积神经网络模型建立所述真实场景图像合成网络模型的损失函数;
训练模块,用于将所述图像训练集作为所述真实场景图像合成网络模型的输入,依据所述损失函数,对所述真实场景图像合成网络模型进行训练,得到训练好的真实场景图像合成网络模型;
第二获取模块,用于获取多幅待合成的语义图;
合成模块,用于将所述待合成的语义图输入到所述训练好的真实场景图像合成网络模型中,得到与所述待合成的语义图对应的真实场景合成图。
可选的,所述合成模型建立模块,具体包括:
第一建立单元,用于建立u-net卷积神经网络模型;所述u-net卷积神经网络模型包括多个层级;
第二建立单元,用于建立激励残差块;
合成模型建立单元,用于在所述u-net卷积神经网络模型的每两个相邻的层级之间嵌入所述激励残差块,构成真实场景图像合成网络模型。
可选的,所述训练模块,具体包括:
合成图获取单元,用于将所述训练集中的第i张语义图输入到当前的真实场景图像合成网络模型中,得到所述第i幅语义图对应的真实场景合成图;其中i为大于或等于1的整数;所述当前的真实场景图像合成网络模型是第j次训练更新后的真实场景图像合成网络模型;其中j为大于或等于0的整数;
判断单元,用于判断j是否小于预设最大训练次数;
更新单元,用于若j小于预设最大训练次数,则将所述真实场景合成图和所述第i幅语义图对应的真实场景参考图输入到所述损失函数中,得到损失值;将所述损失值输入到adam优化器中,采用adam优化算法更新所述真实场景图像合成网络模型;再令i=i+1,j=j+1,并返回所述将所述训练集中的第i幅语义图输入到当前的真实场景图像合成网络模型中,得到所述第i幅语义图对应的真实场景合成图;
合成模型确定单元,用于若j大于或等于预设最大训练次数,则将当前的真实场景图像合成网络模型作为训练好的真实场景图像合成网络模型。
可选的,所述系统还包括:
参数确定模块,用于确定所述真实场景图像合成网络模型的初始化参数;所述初始化参数包括学习率、最大训练次数、语义图的个数、语义图的宽度和语义图的高度。
与现有技术相比,本发明的有益效果是:
本发明提出了一种真实场景图像合成方法及系统,所述方法依据u-net卷积神经网络模型和激励残差块建立真实场景图像合成网络模型,并且利用预训练好的vgg-19卷积神经网络模型建立真实场景图像合成网络模型的损失函数,利用损失函数,对真实场景图像合成网络模型进行训练,得到最终的真实场景图像合成网络模型。本发明的方法或系统,能够快速有效可靠的合成真实感更强的摄影级场景图像,提高合成图像的真实感和视觉质量,扩大应用范围与应用场景。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例一种真实场景图像合成方法的流程图;
图2为本发明实施例激励残差块的结构示意图;
图3为本发明实施例真实场景图像合成网络模型的结构示意图;
图4为采用街景数据集cityscapesdataset中的图像作为待合成的语义图的合成结果图;
图5为采用游戏场景gta5dataset中的图像作为待合成的语义图的合成结果图;
图6为本发明实施例一种真实场景图像合成系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明实施例一种真实场景图像合成方法的流程图。
参见图1,实施例的真实场景图像合成方法,包括:
步骤s1:获取图像训练集;所述图像训练集由多个图像对构成;各所述图像对均由一幅语义图和与所述语义图对应的真实场景参考图构成。
本实施例中,所述图像训练集中的图像可以由代表现实世界真实场景的街景数据集cityscapesdataset中获取,或由代表游戏场景的gta5dataset中获取。
步骤s2:依据u-net卷积神经网络模型和激励残差块建立真实场景图像合成网络模型;所述激励残差块是由卷积层和激活层构成的。
图2为本发明实施例激励残差块的结构示意图,图2(a)为激活层(swishlayer)的结构图,图2(b)为单个激励残差块(swishresidualblock,srb)的结构图。
参见图2,每个矩形框表示网络中的相应数据操作,箭头表示数据流,
所述步骤s2,具体包括:
建立u-net卷积神经网络模型;所述u-net卷积神经网络模型包括多个层级;
建立激励残差块,所述激励残差块,具体为:
f(x)=x·sigmoid(β(x))
其中,x表示输入的语义图,sigmoid是一个激活函数,其函数表达式为sigmoid(x)=1/(1+exp(-x)),β表示激励残差块中的卷积层,β(x)表示对输入的语义图做卷积操作后的图像;
在所述u-net卷积神经网络模型的每两个相邻的层级之间嵌入所述激励残差块,构成真实场景图像合成网络模型。
本实施例中的u-net卷积神经网络模型有左右2个对称的分支构成,在u-net的左右分支中,对不同分辨率的特征图进行卷积操作的若干卷积层构成了不同的u-net级别,本实施例中的u-net卷积神经网络模型包括6个层级,6个层级具有6个不同分辨率的级别。
图3为本发明实施例真实场景图像合成网络模型的结构示意图。参见图3,真实场景图像合成网络模型包括6个级别,从上到下依次为1级到6级,特征图的分辨率依次减半;每个矩形框表示多通道特征图,矩形框顶部的数字表示通道数,例如“20、96、192、384、512、1536”等,“s”表示激励残差块,箭头表示不同的操作,箭头“↓”表示下采样操作,即最大池化操作,箭头“↑”表示上采样操作,本实施例中上采样操作的方法为调整大小-卷积(resize-convolution)的方法,箭头“→”表示卷积层的卷积操作,虚线箭头表示特征图的复制粘贴操作。其中,上采样操作是指将分辨率小的图像以某种方法放大为分辨率大的图像。本实施例中的resize-convolution上采样的过程为:将输入的小分辨率图像首先经过双三次插值的插值算法将图像分辨率扩大一倍,然后再把放大后的图像经过一层卷积层进行卷积操作,之后卷积层输出的特征图即是上采样方法的输出图。
步骤s3:利用预训练好的vgg-19卷积神经网络模型建立所述真实场景图像合成网络模型的损失函数。所述损失函数,具体为:
其中,lf表示损失值;f表示真实场景图像合成网络模型输出的真实场景合成图,g表示真实场景参考图;φ表示预训练好的vgg-19卷积神经网络模型,φl表示预训练好的vgg-19卷积神经网络模型中的第l层,φl(f)表示将f输入到预训练好的vgg-19卷积神经网络中,第l层卷积层后输出的特征图,φl(g)表示将g输入到预训练好的vgg-19卷积神经网络中,第l层卷积层输出的特征图;l的取值为{0,1,2,3,4,5};φ0表示预训练好的vgg-19网络的输入图,φ1至φ5表示预训练好的vgg-19中五个卷积层对应输出的特征图;λl表示第l层的损失值对应的权重系数,λl的取值为{1/1.6,1/2.3,1/1.8,1/2.8,10/0.8}。
步骤s4:确定所述真实场景图像合成网络模型的初始化参数。
具体的,所述初始化参数包括学习率、最大训练次数、语义图的个数、语义图的宽度和语义图的高度。
本实施例中,所述学习率learning_rate=0.0001,所述最大训练次数epoch=100,语义图的宽度width=384,语义图的高度height=192。
步骤s5:将所述图像训练集作为所述真实场景图像合成网络模型的输入,依据所述损失函数,对所述真实场景图像合成网络模型进行训练,得到训练好的真实场景图像合成网络模型。所述步骤s5,具体包括:
将所述训练集中的第i张语义图输入到当前的真实场景图像合成网络模型中,得到所述第i幅语义图对应的真实场景合成图;其中i为大于或等于1的整数;所述当前的真实场景图像合成网络模型是第j次训练更新后的真实场景图像合成网络模型;其中j为大于或等于0的整数;
判断j是否小于预设最大训练次数;
若是,则将所述真实场景合成图和所述第i幅语义图对应的真实场景参考图输入到所述损失函数中,得到损失值;
将所述损失值输入到adam优化器中,采用adam优化算法更新所述真实场景图像合成网络模型;再令i=i+1,j=j+1,并返回所述将所述训练集中的第i幅语义图输入到当前的真实场景图像合成网络模型中,得到所述第i幅语义图对应的真实场景合成图;
若否,则将当前的真实场景图像合成网络模型作为训练好的真实场景图像合成网络模型。
本实施例中,所述损失值的计算过程可以具体描述为:将真实场景合成图与对应的真实场景参考图分别输入到预训练好的预训练好的vgg-19卷积神经网络模型中,然后分别得到预训练好的vgg-19中5个卷积层(分别是conv1_2,conv2_2,conv3_2,conv4_2,conv5_2)输出的特征子图,再计算这5组特征子图的平方绝对误差以得到5组平方绝对误差值,然后计算真实场景合成图与语义图对应的真实参考图之间的平方绝对误差值,最后得到6组平方绝对误差值,将6组平方绝对误差值相加求和即为所述损失值。
步骤s6:获取多幅待合成的语义图。
步骤s7:将所述待合成的语义图输入到所述训练好的真实场景图像合成网络模型中,得到与所述待合成的语义图对应的真实场景合成图。
本实施例采用了代表现实世界真实场景的街景数据集cityscapesdataset中的图像作为训练集和测试集,实现了上述真实场景图像合成方法。图4为采用街景数据集cityscapesdataset中的图像作为待合成的语义图的合成结果图,其中图4(a)为在街景数据集cityscapesdataset中选取的待合成的语义图,图4(b)为与图4(a)对应的真实场景合成图。图5为采用游戏场景gta5dataset中的图像作为待合成的语义图的合成结果图,其中图5(a)为在游戏场景gta5dataset中选取的待合成的语义图,图5(b)为与图5(a)对应的真实场景合成图。
本实施例的真实场景图像合成方法,能够快速有效可靠的合成真实感更强的摄影级场景图像,提高合成图像的真实感和视觉质量,扩大应用范围与应用场景;并且u-net卷积神经网络模型中的上采样方法为调整大小-卷积(resize-convolution)的方法,能够减少合成图像中的棋盘伪影,进一步提高了合成图像的真实感。
本发明还提供了一种真实场景图像合成系统,图6为本发明实施例一种真实场景图像合成系统的结构示意图。
参见图6,实施例的真实场景图像合成系统包括:
第一获取模块601,用于获取图像训练集;所述图像训练集由多个图像对构成;各所述图像对均由一幅语义图和与所述语义图对应的真实场景参考图构成。
合成模型建立模块602,用于依据u-net卷积神经网络模型和激励残差块建立真实场景图像合成网络模型;所述激励残差块是由卷积层和激活层构成的。
所述合成模型建立模块602,具体包括:
第一建立单元,用于建立u-net卷积神经网络模型;所述u-net卷积神经网络模型包括多个层级;
第二建立单元,用于建立激励残差块;
合成模型建立单元,用于在所述u-net卷积神经网络模型的每两个相邻的层级之间嵌入所述激励残差块,构成真实场景图像合成网络模型。
损失函数建立模块603,用于利用预训练好的vgg-19卷积神经网络模型建立所述真实场景图像合成网络模型的损失函数。
参数确定模块604,用于确定所述真实场景图像合成网络模型的初始化参数;所述初始化参数包括学习率、最大训练次数、语义图的个数、语义图的宽度和语义图的高度.
训练模块605,用于将所述图像训练集作为所述真实场景图像合成网络模型的输入,依据所述损失函数,对所述真实场景图像合成网络模型进行训练,得到训练好的真实场景图像合成网络模型。
所述训练模块605,具体包括:
合成图获取单元,用于将所述训练集中的第i张语义图输入到当前的真实场景图像合成网络模型中,得到所述第i幅语义图对应的真实场景合成图;其中i为大于或等于1的整数;所述当前的真实场景图像合成网络模型是第j次训练更新后的真实场景图像合成网络模型;其中j为大于或等于0的整数;
判断单元,用于判断j是否小于预设最大训练次数;
更新单元,用于若j小于预设最大训练次数,则将所述真实场景合成图和所述第i幅语义图对应的真实场景参考图输入到所述损失函数中,得到损失值;将所述损失值输入到adam优化器中,采用adam优化算法更新所述真实场景图像合成网络模型;再令i=i+1,j=j+1,并返回所述将所述训练集中的第i幅语义图输入到当前的真实场景图像合成网络模型中,得到所述第i幅语义图对应的真实场景合成图;
合成模型确定单元,用于若j大于或等于预设最大训练次数,则将当前的真实场景图像合成网络模型作为训练好的真实场景图像合成网络模型。
第二获取模块606,用于获取多幅待合成的语义图。
合成模块607,用于将所述待合成的语义图输入到所述训练好的真实场景图像合成网络模型中,得到与所述待合成的语义图对应的真实场景合成图。
本实施例中的真实场景图像合成系统,能够快速有效可靠的合成真实感更强的摄影级场景图像,提高合成图像的真实感和视觉质量,扩大应用范围与应用场景。
本说明书中对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!