用于热控制的机器学习装置、系统和方法与流程
本发明一般性地涉及用于电子设备的热控制,更具体地,涉及用于电子设备的热控制的机器学习装置、系统和方法。
背景技术:
诸如计算机的电子设备包括许多电子组件(例如,存储器、处理器等)。随着电子设备复杂性的不断增加和尺寸的小型化,它们的组件耗散增加的热能,这可能降低电子设备的可靠性和寿命。因此,电子设备通常包括具有一个或多个用于热控制的风扇的冷却系统。
比例-积分-微分(pid)控制器是电子设备的热控制系统中广泛使用的控制回路反馈机制。pid参数或系数根据操作风扇速度自适应地调节。然而,这种传统方案在多个方面存在缺陷。例如,必须针对一个风扇系统调整pid参数,而这种调整过程是耗时的。已调整的pid参数不能转移到其他风扇系统。也就是说,需要针对每个风扇系统分别调整pid参数。此外,由于温度和风扇速度之间的高非线性,这种传统方案受到风扇速度振荡问题的影响。
技术实现要素:
本发明提供用于针对电子设备建立热控制策略的机器学习装置、系统和方法,以克服如上所述的一个或多个现有技术问题。
根据示例性实施例的一个方面,提供了一种用于针对电子设备建立热控制策略的机器学习装置。机器学习装置包括状态观察模块和强化学习模块。状态观察模块被配置为接收与电子设备的热条件相关联的一个或多个状态变量。该一个或多个状态变量以图形形式呈现。强化学习模块被配置为基于奖赏和该一个或多个状态变量来更新动作值表。
根据示例性实施例的另一方面,提供了一种用于针对电子设备建立热控制策略的机器学习系统。该系统包括机器学习装置、温度测量模块、功率测量模块和信号测量模块。机器学习装置包括状态观察模块和强化学习模块。强化学习模块被配置为基于根据与电子设备的热条件相关联的一个或多个状态变量生成的奖赏来更新动作值表。一个或多个状态变量以图形形式呈现在图形中,并且该一个或多个状态变量在图形中的相对位置能够被识别和提取。温度测量模块被配置为测量电子设备的处理器的温度。功率测量模块被配置为测量由电子设备消耗的功率。信号测量模块被配置为测量电子设备的风扇的脉冲宽度调制(pwm)信号的占空比。
根据示例性实施例的另一方面,提供了一种用于针对电子设备建立热控制策略的机器学习方法。该方法提供与电子设备的热条件相关联的一个或多个状态变量,基于该一个或多个状态变量生成奖赏,并基于奖赏和该一个或多个状态变量更新动作值表。该一个或多个状态变量以图形形式呈现在图中。
根据示例性实施例的机器学习装置、系统和方法为电子设备提供改进的热控制策略,并且具有以下优点中的一个或多个:与调节pid参数相比消耗更少的时间、更多的灵活性和可转移性、易于维护和扩展、快速收敛、缓和甚至消除风扇振荡问题。
以下将讨论更多示例性实施例和技术效果。
附图说明
现在将参考附图以示例的方式描述本发明的实施例,其中:
图1示出根据示例性实施例的用于针对电子设备建立热控制策略的机器学习装置。
图2示出根据示例性实施例的图形形式的状态变量。
图3示出根据示例性实施例的用于调节电子设备的风扇的脉冲宽度调制(pwm)信号的占空比的动作。
图4示出根据示例性实施例的用于针对电子设备建立热控制策略的机器学习系统。
图5示出根据示例性实施例的用于针对电子设备建立热控制策略的机器学习方法。
图6示出根据示例性实施例的自我训练过程。
图7示出通过结合dnq模型和图6的瞬态模型以利用风扇速度控制的cpu温度的行为的仿真。
图8a示出根据示例性实施例的通过图6的瞬态模型完成8小时自我训练之后cpu温度的行为的仿真。
图8b示出根据示例性实施例的通过图6的瞬态模型完成24小时自我训练之后cpu温度的行为的仿真。
图9是示出图4的机器学习系统的示例性操作的流程图。
具体实施方式
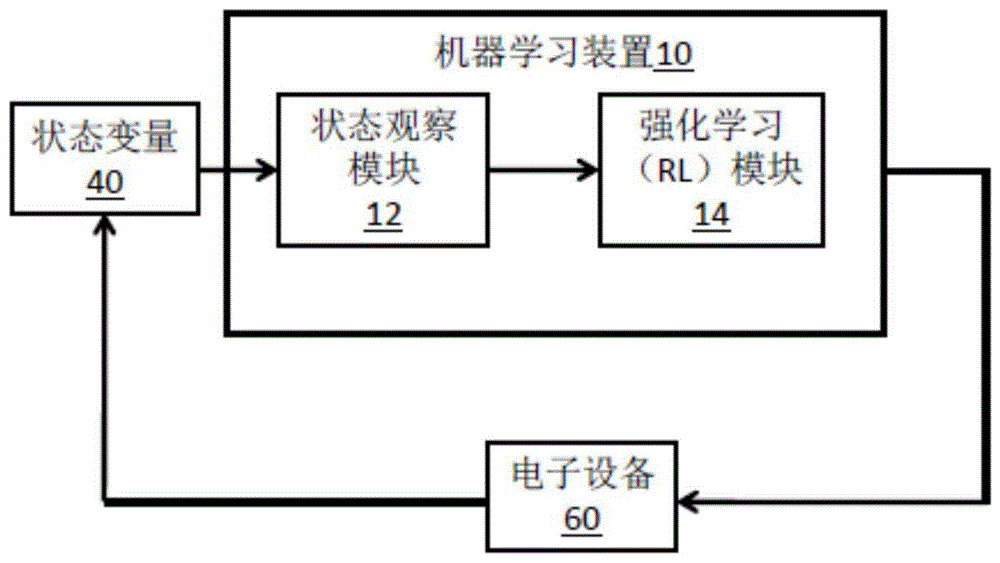
图1示出用于针对电子设备60建立热控制策略的机器学习装置10。机器学习装置10包括状态观察模块12和强化学习(rl)模块14。状态观察模块12接收与电子设备60(例如计算机)的热条件相关联的一个或多个状态变量40。rl模块14基于奖赏(reward)和状态变量40更新动作值表。
热条件表征电子设备60的内部温度和散热以及电子设备60操作的环境条件。状态变量40具有至少部分地反映热条件的值。如图2所示,状态变量40包括环境温度41、由电子设备60的处理器消耗的功率42、用于电子设备60的风扇的脉冲宽度调制(pwm)信号的占空比43、电子设备60的处理器的温度44。状态变量40以图形形式呈现。状态变量40被示为点。这些状态变量40的值由图形中这些点的位置或相对位置表示。它们可以由状态观察模块12识别和提取以进行处理。也就是说,该图形用作机器学习过程的输入,并且这些点的相对位置可以由状态观察模块12观察或接收,然后传送到rl模块14。尽管在图2中示出了四个状态变量41、42、43和44,状态变量40不一定包括所有四个状态变量。而是,状态变量40可以包括四个状态变量中的一个或多个。备选地,状态变量40可包括多于四个状态变量。在那种情况下,状态变量仍然在图形中呈现,只是状态变量之间的相互作用(例如,相对位置)更复杂。
以图形形式呈现状态变量是有利的。图形用作输入,更具体地,图形中的状态变量的相对位置被识别并被读取以进行处理。与使用数值作为输入相比,使用图形形式作为输入降低了算法复杂度并节省了计算时间。此外,状态变量的图形表示使机器学习方法更具可转移性和可扩展性。由于不存在从一个系统到另一个系统不同的数学方程式,所以根据示例性实施例的机器学习方法可以在基本上不需要修改执行算法或代码的情况下,应用于不同的电子系统。
响应于状态变量40的观察结果,rl模块14生成奖赏。取决于图形中状态变量40的相对位置,奖赏可以是正值或负值或零。由此,奖赏指示状态变量40的当前值是否是有利的。基于奖赏和状态变量40,rl模块14更新动作值表。动作值表可以是风扇值表,其指示下一动作中电子设备60的风扇的pwm信号的占空比的增加或减少。例如,图3中的图表30示出了七个可选动作:0、+2%、-2%、+5%、-5%、+9%和-9%。0表示占空比在下一动作中保持不变,而+2%表示占空比在下一动作中将增加2%。可以从由这七个动作组成的组中选择占空比的增加或减少。例如,当电子设备60的处理器的温度高时,这表明当前状态不利,rl模块14生成负的奖赏。相应地,可以更新动作值表以将占空比增加+5%,使得风扇旋转得更快以降低温度。尽管图3示出了七个可选动作,但是根据实际需要可以采取更多动作或更少动作。
图4示出用于针对电子设备60建立热控制策略的机器学习系统100。电子设备60包括处理器62(例如中央处理单元(cpu)、图形处理单元(gpu)、等等)、风扇64、以及被配置成驱动风扇64以冷却处理器62的风扇电机66。风扇64可以表示设置在电子设备60内部的一个或多个风扇。
系统100包括温度测量模块22、功率测量模块24和信号测量模块26。温度测量模块22(例如设置在处理器62的插口内的温度传感器)配置为测量处理器62的温度。功率测量模块24(例如设置在处理器62的插口内的功率计传感器)配置为测量由处理器62消耗的功率。信号测量模块26(例如配置在硬件(例如处理器)内部的一个或多个端口引脚控制定时器或计数器)配置为获得风扇62的pwm信号的占空比。获得的状态变量值,例如温度、功率和占空比,以图形形式处理和呈现。可以用软件通过将获得的值对应或映射到图形上的相应点上,生成图形形式。尽管温度测量模块22、功率测量模块24和信号测量模块26被示出为包括在系统100中,但是根据实际需要可以将它们中的一个或多个设置为电子设备60的一部分。
如所示,系统100包括机器学习装置10。机器学习装置10包括用于训练系统的瞬态模型(transientmodel)模块16。在训练过程期间,瞬态模型模块16与rl模块14通信,并基于状态变量40生成奖赏,其中状态变量40的值由图形形式的相对位置表示。例如,当处理器的温度落入预定目标范围46(参见图2)时(例如目标范围46表示温度从88摄氏度(℃)到92℃的范围),瞬态模型模块16增加奖赏或生成正奖赏值,例如+1。当温度超过第一阈值47(例如92℃)时,瞬态模型模块16减少奖赏或生成负奖赏值(即,第一值),例如-0.5。当温度超过第二阈值48(例如95℃)时,瞬态模型模块16进一步减少奖赏或生成另一个负奖赏值(即,第二值),例如-1。备选地,瞬态模型模块可以根据处理器的温度与预定值之间的距离来确定奖赏。该距离可以定义为处理器温度减去预定值所得运算结果的绝对值。备选地,瞬态模型模块根据处理器的温度与预定范围之间的距离确定奖赏。预定范围具有上端点(例如92℃)和下端点(例如88℃)。如果处理器的温度高于上端点,则距离被定义为处理器温度减去上端点所得运算结果的绝对值。如果处理器的温度低于下端点,则距离被定义为处理器温度减去下端点所得运算结果的绝对值。在任一种情况下,奖赏可以根据这种差异(即,距离)灵活设计。例如,当差异落入预定范围内时,奖赏可以是固定值。奖赏也可以是线性地或非线性地依赖于差异的函数,使得奖赏随着差异的增加而减小。此外,关于用于电子设备60的风扇的pwm信号的稳定性,当占空比的波动落入对应于图表中的特定区域(未示出)的预定范围内时,瞬态模型模块16增加奖赏或生成正值作为奖赏。还可以根据处理器的环境温度和功耗的位置生成奖赏。
在一些实施例中,瞬态模型模块16基于在图形中一个或多个状态变量相对于其他一个或多个状态变量的相对位置来生成奖赏。例如,当功率42和温度44处于图形中的较高位置而占空比43处于较低位置时,表明处理器温度高但风扇旋转较慢。这是不期望的状态,因此生成负奖赏。相应地,更新动作值表以增加占空比的值,使得风扇旋转得更快以降低处理器的温度。
在自我训练之后,机器学习装置10可以操作以响应状态变量40以更新动作值表,如上面参考图1所述。
图5示出用于针对电子设备建立热控制策略的机器学习方法500。例如,机器学习方法500可以由如上所述的机器学习装置10或系统100执行。
框502表示提供与电子设备的热条件相关联的一个或多个状态变量。状态变量以图形形式呈现。例如,可以通过获得电子设备的处理器的温度以及获得电子设备的风扇的pwm信号的占空比来提供状态变量。识别和提取图形中的处理器温度和占空比的相对位置,使得提供的相对位置作为用于生成奖赏的基础或基础的一部分。状态变量还可以包括环境温度和由处理器消耗的功率。环境温度可以通过温度传感器(例如温度计)作为默认输入获得,或者通过实时测量作为系统的输入来获得。
框504表示基于一个或多个状态变量生成奖赏。奖赏可以是正的或负的或零,其取决于图中状态变量的相对位置。奖赏可以由参考图1所述的rl模块14生成,或由参考图4所述的瞬态模型模块16生成。
框506表示基于奖赏和一个或多个状态变量更新动作值表。动作值表指示要对电子设备施加的下一操作。例如,响应于动作值表,将转速信号输出到电子设备的风扇电机,使得风扇的旋转速度改变。通过观察电子设备的行为和奖赏,机器学习系统进行调节并找到或建立适当或最佳的电子设备的热控制策略。
在一些实施例中,瞬态模型模块通过以下进行自我训练:基于在预定时间内从环境和电子设备提取的数据组中随机选择的一个或多个变量的值,生成奖赏值,并且输出动作值。例如,瞬态模型模块通过使用一组实验数据输入来进行自我训练,以加速机器学习过程。实验数据输入可以包括环境温度、由电子设备的处理器消耗的功率、电子设备的处理器的温度、电子设备的风扇的pwm信号的占空比以及风扇中速度的一个或多个。通过这样做,可以加速机器学习方法的收敛。
可以通过尝试更多不同的热条件来改进自我训练,例如通过使用不同组的实验数据输入来进行自我训练。因此,瞬态模型模块例如可以更好地理解电子设备与其操作环境之间的关系以及处理器的温度与风扇速度行为之间的关系。结果,每次响应于状态可以输出或采取更适当的动作,机器学习过程可更快地收敛。
实验数据输入可以是在预定时间内从环境和电子设备提取的数据组,例如通过预先运行真实电子系统一段时间获得的实验数据。该数据组可以预先存储在机器学习装置10的重放存储器(replaymemory)18中(图4)。瞬态模型模块从重放存储器18中随机选择数据或值以进行自我训练。
图6示出根据示例性实施例的自我训练过程。仅出于说明性目的,自我训练过程组合深度q网络(dqn)模型610和瞬态模型620。
q学习是机器学习中使用的强化学习技术。q学习的目的是学习一项政策,以便代理(agent)知道在什么情况下采取什么动作。dnq要做的是结合卷积神经网络(cnn)和q学习。cnn的输入用作状态,输出是对应于每个动作的值函数(即,q值)。
在q学习中,在特定环境状态s中学习动作a的选择的值q(s,a)。也就是说,可以优选地选择在环境状态s中生成最高值q(s,a)的动作a作为最佳动作。然而,在开始时,对于一对状态s和动作a,值q(s,a)是完全未知的。代理选择特定状态s中的各种动作a,并为动作a提供奖赏。通过该操作,代理学习选择更好的动作,即值q(s,a)或q值。
为了最大化由于动作而将来获得的奖赏的总和,最终满足q(s,a)=e[(γt)rt]。该表达式中的期望值是响应于在最佳动作之后的状态变化而采取的,并且是由搜索学习的未知值。这样的值q(s,a)的更新表达式可以由qnew(s,a)=q(s,a)+α(r+γmaxq(s′,a)-q(s,a))给出,其中s是在时间t的环境状态,a是在时间t的动作。在动作a后,状态变为s'。r是状态变更时接收到的奖赏。与max关联的项是当状态s'时选择已知的具有最高q值的动作a时,q值乘以γ的乘积。γ是被称为折扣因子(discountfactor)的参数,满足0<γ≤1。α是满足0<α≤1的学习率(learningrate)。因此,qnew(s,a)的表达式表示基于作为尝试动作a的结果而返回的奖赏r来更新状态s中的动作的评估值q(s,a)的方法。
当执行机器学习时,电子设备在某些压力程序或条件下预运行一段时间,例如几个小时。在这段时间内收集实验数据输入。例如,可以每秒收集30个图形。这些实验数据输入被预先存储在重放存储器616中。当进行自我训练时,从重放存储器616中随机选择并使用数据。因此,并非所有实验数据输入都用于自我训练。由此,训练算法耗时较少并且可以更快地收敛。此外,由于数据是随机选择的而不是有序选择的,因此可以避免在训练过程中放大不利的初始条件并导致不希望的结果,例如陷入无限循环并且不能收敛。
为了提高dnq模型算法的稳定性,采用第一网络评估电子设备的当前状态,采用第二网络评估电子设备的目标状态。采用梯度下降算法来校正第一网络,使得第一网络接近或等于第二网络。
参考图6,例如,第一网络,即主网络(mainnet)612,用于评估对应于当前状态的值函数(即,q值,显示为q(s,a;θ))。主网络612包括来自选自重放存储器616的实验数据输入的状态、与状态对应的动作以及奖赏。对于每个新状态,主网络612以预定概率(例如0.9)输出具有最大奖赏的动作。这样,对于每个新状态,主网络612随机输出具有概率为(1-预定概率)的动作,例如0.1。这是有利的,因为用于训练的数据不限于来自重放存储器616的实验数据输入。也就是说,该策略扩展了用于训练的数据样本。
第二网络,即目标网络(targetnet)614,用于生成目标q值(示出为maxaq(s′,a′;θ-))。目标网络614包括来自从重放存储器616中选择的实验数据输入的状态、与状态对应的动作和奖赏。目标网络614在训练期间响应新状态。也就是说,对于每个新状态,目标网络614遵循从实验数据输入导出的状态、动作和奖励之间的关系。因此,目标网络614输出具有最大奖赏的动作。
因此,主网络612和目标网络614的内容在开始时是相同的,但是随着训练过程的进行而开始发散。损失函数(lossfunction)618,即l=(r+γmaxq(a′)-q(ai))2,用于更新主网络612的参数。损失函数618校正主网络612,使得主网络612接近或理想地等于目标网络614。可以采用梯度下降算法来加速校正过程。每次迭代时,例如每10000次迭代,主网络612的参数被复制到目标网络614。由于q值在一段时间内保持不变,因此当前q值与目标q值之间的相关性被减小,从而提高了算法的稳定性。
参考图6,瞬态模型620的自我训练被示为包括若干步骤。在框622,随机选择实验数据输入并将其输入到瞬态模型620。在框624,瞬态模型620具有默认设置。框626涉及温度输入,例如输入环境温度。在框628,进行人工智能(ai)热控制。这可以组合dqn模型610以生成当前q值和目标q值,并使用损失函数618进行校正,使得当前q值接近或等于目标q值。基于框628处的结果,在框630处更新瞬态模型620。相应地,更新默认设置并开始下一次迭代。
图7示出通过结合dqn模型和图6的瞬态模型来通过风扇速度控制来仿真cpu温度的行为。x轴表示仿真运行的时间(单位:秒),在左侧的y轴或左侧y轴表示温度。在右侧的y轴或右侧y轴表示功率(单位:瓦特)和pwm(即,占空比)。如图所示,环境温度706(映射到左侧y轴的值)是25℃,其在仿真期间保持不变。在该周期结束时,即690秒,cpu功率704(映射到右侧y轴的值)稳定在100瓦特(w)。用于风扇的pwm信号的占空比708(映射到右侧y轴的值)约为30%。cpu温度702(映射到左侧y轴的值)约为82.2℃。
图8a示出在通过图6的瞬态模型完成自我训练8小时之后cpu温度的行为的仿真。图8b示出在完成自我训练24小时之后cpu温度的行为的仿真。两个图都显示了cpu温度802a和802b(映射到左侧y轴的值)、cpu功率804a和804b(映射到右侧y轴的值)、环境温度806a和806b(映射到左侧y轴的值)以及占空比808a和808b(映射到右侧y轴的值)的演变。如图所示,根据本实施例的自我训练过程快速收敛。在24小时自我训练之后,cpu温度快速收敛并且大部分被限制在预定目标范围内,即在本实施例中为88℃-92℃。
图9是示出图4的系统的示例性操作的流程图。如图所示,操作在框902处开始自我训练。自我训练可以由瞬态模型模块利用一组或多组实验数据输入执行。自我训练有助于机器学习方法的收敛,节省开发时间。在自我训练之后,框904确定一个或多个状态变量的值。例如,状态变量可以包括环境温度、由电子设备的处理器消耗的功率、电子设备的处理器的温度、以及用于电子设备的风扇的pwm信号的占空比中的一个或多个。可以通过使用相应的测量设备来获得这些值。
框906比较cpu温度(在本实施例中,电子设备被示为计算机,并且处理器被示为cpu)以确定奖赏或奖赏值。如果cpu温度落在预定目标范围内,则输出+1的奖赏(框908)。如果cpu温度超过第一阈值,例如线上方的相对位置,则输出-0.5的奖赏(框910)。如果cpu温度超过大于第一阈值的第二阈值,则输出-1的奖赏(框912)。奖赏输出被加和到先前的奖赏(框914)。
在框916处,通过比较风扇的pwm信号的占空比来确定奖赏。当占空比的值落入预定范围内(例如,相对位置落在图形中的预定区域内)时,这表明pwm信号是稳定的,输出+0.5的奖赏(方框918)。否则,输出-0.5的奖赏(方框920)。在框922处,将奖赏输出进一步加和到先前奖赏。在框924处,根据奖赏总和更新动作值表,并且通过移动到框904重复相同的过程。
尽管图9仅示出了关于cpu温度和占空比的比较,但是可以使用其他状态变量来确定奖赏。还可以根据其他预定义规则生成奖赏。此外,尽管比较状态变量(例如cpu温度和占空比)的步骤被示为顺序地执行,但是它们可以同时执行。
本领域技术人员将理解,在不脱离本文构建的示例性实施例的精神或范围的情况下,可以对如上所述的示例性实施例进行多种变化和/或修改。因此,示例性实施例在所有方面都被认为是说明性的而非限制性的。
- 还没有人留言评论。精彩留言会获得点赞!