基于数据融合的人员辨识方法与流程
本发明涉及人员辨识,特别涉及基于数据融合的人员辨识。
背景技术:
现有的人员辨识系统多是撷取未知人员的输入特征(如指纹或储存于rfid标签的识别码),再将未知人员的输入特征与数据库的所有范本(如合法人员预先注册的指纹或识别码)逐一进行比对以辨识当前的未知人员是否为合法人员。现有的人员辨识系统的缺失在于,当数据库的范本的数量过多时必须花费大量辨识时间来逐一比对未知人员的输入特征与各范本,这使得人员辨识效率低落,而降低了使用者体验。
此外,当使用接触式输入装置来接收未知人员的输入特征时(如人员可经由指纹感测器按压指纹或经由键盘输入识别码),由于必须频繁按压接触式输入装置,而造成接触式输入装置的使用寿命过短,这会增加人员辨识系统的维护成本。
此外,当使用无线输入装置来接收未知人员的输入特征时(如人员可持rfid标签/蓝牙装置来接近rfid读卡机/蓝牙收发器以输入rfid标签/蓝牙装置的识别码),由于人员必须额外携带辨识物件(如rfid标签或蓝牙装置),而存在人员忘记携带辨识物件及无法进行身份辨识的问题。
有鉴于此,目前亟待一种可解决上述问题的人员辨识技术被提出。
技术实现要素:
本发明的目的在于提供一种基于数据融合的人员辨识方法,可使用一种输入特征作为索引来减少比对的范本数量,并使用另一种输入特征来比对减少数量后的范本以进行身份确认。
于一实施例中,一种基于数据融合的人员辨识方法,用于一人员辨识系统,该人员辨识系统包括一影像撷取装置及一收音装置,该基于数据融合的人员辨识方法包括以下步骤:
a)经由该收音装置接收一人员的语音以产生一输入语音;
b)解析该输入语音以获得一输入文本;
c)依据该输入文本于多个范本影像中选择部分;
d)经由该影像撷取装置拍摄该人员的脸部以获得一输入脸部影像;及
e)比对该输入脸部影像及所选择的该范本影像以辨识该人员。
于一实施例中,该步骤b)是于感测该语音的音量大于一音量临界值时解析该输入语音来获得该输入文本。
于一实施例中,该步骤c)包括以下步骤:
c1)比较该输入文本与多个范本文本,其中该多个范本文本分别对应该多个范本影像;及
c2)于该输入文本符合任一该范本文本时,选择对应的该范本影像。
于一实施例中,该多个范本影像分别对应多个人员数据;该步骤e)是于该输入脸部影像符合所选择的该范本影像时,以对应的该人员数据作为该人员的身份。
于一实施例中,该影像撷取装置包括一彩色影像撷取装置及一红外线影像撷取装置;各该范本影像包括一彩色范本影像与一红外线范本影像;该步骤d)包括以下步骤:
d1)经由该彩色影像撷取装置拍摄该人员的脸部以获得一彩色脸部影像;及
d2)经由该红外线影像撷取装置拍摄该人员的脸部以获得一红外线脸部影像;
该步骤e)是比对该彩色脸部影像及所选择的该彩色范本影像并比对该红外线脸部影像及所选择的该红外线范本影像以辨识该人员。
于一实施例中,该步骤e)包括以下步骤:
e1)将该步骤c)所选择的各该彩色范本影像与该彩色脸部影像进行比对以决定各该彩色范本影像与各该彩色脸部影像之间的一彩色相似度;
e2)将该步骤c)所选择的各该红外线范本影像与该红外线脸部影像进行比对以决定各该红外线范本影像与各该红外线脸部影像之间的一红外线相似度;
e3)依据各该范本影像的该彩色相似度及该红外线相似度计算各该范本影像的一相似度;及
e4)于任一该范本影像的该相似度不小于一相似度临界值时以所对应的该人员数据作为该人员的身份。
于一实施例中,各该人员数据对应该多个范本影像;该步骤e)包括以下步骤:
e5)将该步骤c)所选择的该多个范本影像分别与该输入脸部影像进行比对以决定各该范本影像与该输入脸部影像之间的一相似度;
e6)于任一该范本影像的该相似度不小于一相似度临界值时以所对应的该人员数据作为该人员的身份;及
e7)于所有该范本影像的该相似度小于该相似度临界值时执行该步骤d)。
于一实施例中,该步骤d)是获得同一该人员的该多个输入脸部影像;该步骤e5)是将该步骤c)所选择的各该范本影像分别与各该输入脸部影像进行比对以决定各该范本影像与各该输入脸部影像之间的该相似度。
于一实施例中,该基于数据融合的人员辨识方法更包括以下步骤:
f1)依据该输入文本于多个范本声纹中选择部分;
f2)解析该输入语音以获得一输入声纹;及
f3)比对该输入声纹及所选择的该范本声纹以辨识该人员。
于一实施例中,该多个范本影像分别对应多个人员数据,该多个范本声纹分别对应该多个人员数据;该步骤e)是于该输入脸部影像符合所选择的该范本影像时,选择对应的该人员数据;该步骤f3)是于该输入声纹符合所选择的该范本输入声纹时,选择对应的该人员数据;该基于数据融合的人员辨识方法更包括一步骤g)于该步骤e)所选择的任一该人员数据与该步骤f3)所选择的任一该人员数据重复时,以重复的该人员数据作为该人员的身份。
于一实施例中,一种基于数据融合的人员辨识方法,用于一人员辨识系统,该人员辨识系统包括一影像撷取装置及一收音装置,该基于数据融合的人员辨识方法包括以下步骤:
a)经由该影像撷取装置拍摄该人员的脸部以获得一输入脸部影像;
b)依据该输入脸部影像于多个范本语音特征中选择部分;
c)经由该收音装置接收一人员的语音以产生一输入语音;
d)解析该输入语音以获得一输入语音特征;及
e)比对该输入语音特征及所选择的该范本语音特征以辨识该人员。
于一实施例中,该多个范本语音特征分别对应多个人员数据,各该范本语音特征包括一范本文本,该步骤d)是解析该输入语音以获得一输入文本;该步骤e)是于该输入文本符合所选择的该范本文本时,以对应的该人员数据作为该人员的身份。
于一实施例中,该多个范本语音特征分别对应多个人员数据,各该范本语音特征包括一范本声纹,该步骤d)是解析该输入语音以获得一输入声纹;该步骤e)是于该输入声纹符合所选择的该范本声纹时,以对应的该人员数据作为该人员的身份。
于一实施例中,该多个范本语音特征分别对应多个人员数据,各该范本语音特征包括一范本文本及一范本声纹,该步骤d)是解析该输入语音以获得一输入文本及一输入声纹;该步骤e)是于该输入文本符合所选择的该范本文本且该输入声纹符合所选择的该范本声纹时,以对应的该人员数据作为该人员的身份。
于一实施例中,该步骤d)是于感测该语音的音量大于一音量临界值时解析该输入语音来获得该输入语音特征。
于一实施例中,该步骤b)包括以下步骤:
b1)比较该输入脸部影像与多个范本影像,其中该多个范本影像分别对应该多个范本语音特征;及
b2)于该输入脸部影像符合任一该范本影像时,选择对应的该范本语音特征。
于一实施例中,该影像撷取装置包括一彩色影像撷取装置及一红外线影像撷取装置;各该范本影像包括一彩色范本影像与一红外线范本影像;该步骤a)包括以下步骤:
a1)经由该彩色影像撷取装置拍摄该人员的脸部以获得一彩色脸部影像;及
a2)经由该红外线影像撷取装置拍摄该人员的脸部以获得一红外线脸部影像;
该步骤b1)是比对该彩色脸部影像及所选择的该彩色范本影像并比对该红外线脸部影像及所选择的该红外线范本影像。
于一实施例中,该步骤b1)包括以下步骤:
b11)将各该彩色范本影像与该彩色脸部影像进行比对以决定各该彩色范本影像与各该彩色脸部影像之间的一彩色相似度;
b12)将各该红外线范本影像与该红外线脸部影像进行比对以决定各该红外线范本影像与各该红外线脸部影像之间的一红外线相似度;及
b13)依据各该范本影像的该彩色相似度及该红外线相似度计算各该范本影像的一相似度;
该步骤b2)是于任一该范本影像的该相似度不小于一相似度临界值时判定该输入脸部影像符合该范本影像。
于一实施例中,各该人员数据对应该多个范本影像;该步骤b1)将该多个范本影像分别与该输入脸部影像进行比对以决定各该范本影像与该输入脸部影像之间的一相似度;该步骤b2)是于任一该范本影像的该相似度不小于一相似度临界值时判定该输入脸部影像符合该范本影像;
该步骤b)更包括一步骤:b3)于所有该范本影像的该相似度小于该相似度临界值时执行该步骤a)。
于一实施例中,该步骤a)是获得同一该人员的该多个输入脸部影像;该步骤b2)是将各该范本影像分别与各该输入脸部影像进行比对以决定各该范本影像与各该输入脸部影像之间的该相似度。
本发明可有效减低人员辨识系统损坏机率,可供人员不需配戴识别物件,还可有效缩短辨识时间。
以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
附图说明
图1为本发明的第一实施例的人员辨识系统的架构图;
图2为本发明的第二实施例的人员辨识系统的示意图;
图3为本发明的第三实施例的人员辨识系统的示意图;
图4为本发明的第一实施例的人员辨识方法的流程图;
图5为本发明的第二实施例的人员辨识方法的流程图;
图6为本发明的第三实施例的人员辨识方法的流程图;
图7为本发明的第四实施例的语音比对处理的流程图;
图8为本发明的第五实施例的影像比对处理的流程图;
图9为本发明的第六实施例的相似度计算的流程图;
图10为本发明的第七实施例的设定范本影像的流程图;及
图11为本发明的第八实施例的人员辨识方法的流程图。
其中,附图标记
1…人员辨识系统
10…控制装置
11…影像撷取装置
110…彩色影像撷取装置
111…红外线影像撷取装置
12…收音装置
13…储存装置
130…电脑程序
14…人机界面
15…通讯装置
20…电脑装置
21…门锁
30…输入文本
31…输入脸部影像
s10-s13…第一人员辨识步骤
s20-s23…第二人员辨识步骤
s30-s33…第三人员辨识步骤
s40-s47…语音比对步骤
s50-s54…影像比对步骤
s60-s64…相似度计算步骤
s70-s74…设定范本影像步骤
s80-s85…第四人员辨识步骤
具体实施方式
下面结合附图和具体实施例对本发明技术方案进行详细的描述,以更进一步了解本发明的目的、方案及功效,但并非作为本发明所附权利要求书的保护范围的限制。
本发明公开一种基于数据融合的人员系统(下称人员辨识系统),所述人员辨识系统用来执行一种人员辨识方法。本发明可取得人员的第一种输入特征(如语音或脸部影像的其中之一),以第一种输入特征作为索引来对所有范本数据进行筛选以减少要比对的范本数据的数量。接着,本发明取得人员的第二种输入特征(如语音或脸部影像的另一),并使用第二种输入特征来与减少数量后的范本数据进行比对以辨识人员身份。
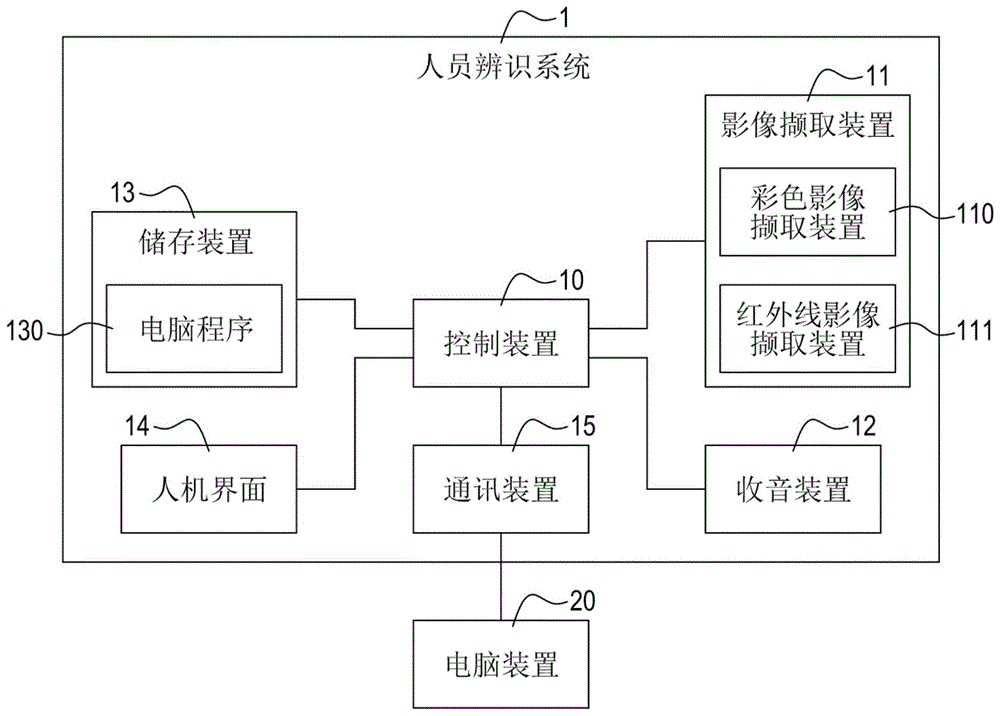
请参阅图1,为本发明的第一实施例的人员辨识系统的架构图。本发明的人员辨识系统1主要包括影像撷取装置11(如摄影机)、收音装置12(如麦克风)、储存装置13及电性连接(如经由传输线、内部线路或网路)上述装置的控制装置10(如处理器或控制主机)。
影像撷取装置11用以拍摄人员并产生电子数据形式的人员的脸部影像(输入脸部影像)。收音装置12用以感测人员的声音并将所感测到的声音转换为电子数据形式的语音(输入语音)。
储存装置13用以储存数据。具体而言,储存装置13储存有多个范本数据(如后述的范本影像、范本语音特征及/或范本文本)。控制装置15用以控制人员辨识系统1。
于一实施例中,影像撷取装置11包括彩色影像撷取装置110(如rgb摄影机)与红外线影像撷取装置111(如设置有红外线滤镜的摄影机或未设置低通滤镜(infraredcutfilter,icf)的摄影机,前述红外线滤镜是用来滤除可见光,前述低通滤镜是用来滤除红外线)。
彩色影像撷取装置110用以感测环境的可见光并产生对应的彩色影像,即可用以拍摄人员的彩色脸部影像。
红外线影像撷取装置111用以感测环境的红外线并产生对应的红外线影像(一般而言,为黑白影像),即可用以拍摄人员的红外线脸部影像。
于一实施例中,人员辨识系统1可包括电性连接控制装置10的人机界面14(如键盘、滑鼠、显示器、触控屏幕等输入装置与输出装置的任意组合)。人机界面14用以接受人员操作并产生对应的数据。
于一实施例中,人员辨识系统1可包括电性连接控制装置10的通讯装置15(如usb模块或以太网路模块等有线通讯模块、wi-fi模块或蓝牙模块等无线网路模块、闸道器或路由器等等)。通讯装置15用以连接外部的电脑装置20。
于一实施例中,储存装置13包括数据库(图未标示),数据库用以储存前述范本数据,但不以此限定。
于另一实施例中,数据库亦可储存外部的电脑装置20,人员辨识系统1是经由通讯装置15自电脑装置20接收前述范本数据。
于一实施例中,储存装置13包括非暂态储存媒体,并储存电脑程序130。电脑程序130包括电脑可执行程序码。当控制装置10执行前述电脑可执行程序码时,可控制人员辨识系统1执行本发明的人员辨识方法的各步骤。
值得一提的是,本发明的人员辨识系统1的各装置可整合设置于同一设备中(如图2所示整合于移动装置,或图3所示整合于门口机),或分开设置于不同地点(如图3所示影像撷取装置11’与门口机分离设置),不加以限定。
请一并参阅图2,为本发明的第二实施例的人员辨识系统的示意图。于本实施例中,人员辨识系统1可为移动装置(图2以智能型手机为例),电脑程序130可为相容于此移动装置的应用程序(app)。移动装置上设置有影像撷取模块11、收音装置12与人机界面14(于此为触控屏幕)。
请一并参阅图3,为本发明的第三实施例的人员辨识系统的示意图。于本实施例中,人员辨识系统1可为固定设置位置的门禁系统(图3以门禁系统包括门口机与门锁21为例),电脑程序130可为相容于此门禁系统的应用程序(app)、操作系统或固件。门口机上设置有影像撷取模块11、收音装置12与人机界面14(于此为显示器)。
门禁系统可于使用本发明的人员辨识方法而辨识当前的人员的身份为合法时自动解锁门锁21以使人员可进入管制区域,藉以达成门禁管制的功能。
于一实施例中,影像撷取装置是与门口机分开设置(如设置于墙上高处的影像撷取装置11’)。藉此,影像撷取装置11’可获得较宽广的拍摄范围,并可降低被破坏的机率。
续请一并参阅图4,为本发明的第一实施例的人员辨识方法的流程图。本发明各实施例的人员辨识方法可由图1-3所示的任一人员辨识系统1来加以实现。本实施例的人员辨识方法主要包括以下步骤。
步骤s10:控制装置10取得人员的第一输入数据。
举例来说,控制装置10是经由影像撷取装置11对人员进行拍摄以获得一或多张输入影像来做为第一输入数据(如人员的脸部影像、手势影像或其他可供辨识的影像)。
于另一例子中,控制装置10是经由收音装置12感测人员的声音以获得输入语音来做为第一输入数据(如语音所对应的文本,或者声纹)。
步骤s11:控制装置10依据所获得的第一输入数据来于多个范本数据中选择部分。具体而言,数据库中可储存多个范本数据,多个范本数据分别对应不同人员。并且,各范本数据包括与第一输入数据相同类型(如影像或语音的其中之一)的第一范本数据及与后述的第二输入数据相同类型(如影像或语音的另一)的第二范本数据。
值得一提的是,前述第一范本数据是用以作为索引,来对大量的范本数据进行分群,即各范本数据的第一范本数据可彼此不同或部分不同。
举例来说,若有一百个范本数据,各范本数据的第一范本数据可彼此不同,即有一百种第一范本数据,范本数据分为一百群。或者,五十个范本数据的第一范本数据彼此相同,另外五十个范本数据的第一范本数据彼此相同,即有两种第一范本数据,范本数据分为两群。
并且,前述第二范本数据是用以对人员身份进行辨识验证。为达成上述目的,各范本数据的第二范本数据是被设定为彼此不同,即一百个范本数据会有一百种第二范本数据。
于步骤s11中,控制装置10是将所获得的第一输入数据与各范本数据的第一范本数据进行比对,决定第一范本数据与第一输入数据相符的范本数据,并于多个范本数据选择相符的一或多个范本数据。
步骤s12:控制装置10取得人员的第二输入数据。具体而言,若控制装置10于步骤s10中是取得输入影像做为第一输入数据,则于步骤s12中是经由收音装置12感测人员的声音以获得输入语音来做为第二输入数据。
反之,若控制装置10于步骤s10中是取得输入语音做为第一输入数据,则于步骤s12中是经由影像撷取装置11对人员进行拍摄以获得输入影像来做为第二输入数据。
步骤s13:控制装置10比对第二输入数据及所选择的范本数据。具体而言,控制装置10是比对第二输入数据及所选择的各范本数据的第二范本数据。若第二输入数据与任一范本数据的第二范本数据,则辨识当前的人员为合法人员,即通过验证。
于一实施例中,人员辨识系统1可进一步决定当前的人员的身份。具体而言,多个范本数据分别对应不同人员的身份数据。控制装置10是以相符的范本数据所对应的身份数据来做为当前人员的身份。
本发明经由使用第一输入数据来减少需比对的范本数据的数量可有效提升辨识速度。
并且,本发明由于使用人员的影像及语音作为输入特征,人员可不需另外携带辨识物件,而可增进使用者体验。
并且,本发明所使用的影像撷取装置与收音装置由于是以非接触方式撷取人员的输入数据,具有较长的使用寿命过短,而可减低维护成本。
续请一并参阅图5,为本发明的第二实施例的人员辨识方法的流程图。本实施例的人员辨识方法是依据人员的输入语音(即前述第一输入数据)的语意内容(文本,即人员所说出的文字、语句或其组合)来选择部分范本影像(即前述范本数据的第二范本数据),并经由比对人员的输入脸部影像(即前述第二输入数据)与所选择的范本影像来辨识人员的身份。具体而言,本实施例的人员辨识方法包括以下步骤。
步骤s20:控制装置10经由收音装置12接收人员的语音以产生输入语音,并对输入语音执行语音比对处理。
于一实施例中,各范本数据包括范本文本与范本影像(即多个范本文本分别对应多个范本影像),前述语音比对处理是文本比对处理。具体而言,人员可对收音装置12说出一段文本(如人员的部门、姓名或身份辨识码等等),控制装置10可经由收音装置12撷取人员的语音作为输入语音,并对输入语音进行解析(如执行语音文字解析处理)以获得输入文本,逐一比对输入文本与各范本文本,并选择符合的范本数据的范本文本作为比对结果。
更进一步地,于一实施例中,如图2所示,控制装置10可将解析获得的输入文本30显示于人机界面14,以供人员知悉所输入的语音是否符合期待,即供人员判断所说的文本是否与控制装置10所解析的输入文本30相同。
于一实施例中,各范本数据包括范本声纹与范本影像(即多个范本声纹分别对应多个范本影像),前述语音比对处理是声纹比对处理。具体而言,人员可对收音装置12说出任意文字,控制装置10可对人员所输入的输入语音进行解析(如执行声纹解析处理)以获得输入声纹,逐一比对输入声纹与各范本声纹,并选择符合的范本数据的范本声纹作为比对结果。
并且,若输入声纹与所有范本声纹皆不符或输入文本与所有范本文本皆不符时,控制装置10不选择任何范本数据。
步骤s21:控制装置10依据比对结果于多个范本影像中选择部分范本影像。
于一实施例中,各范本数据包括范本文本与范本影像。控制装置10是决定范本文本与输入文本相符的部分的范本数据,并选择相符的范本数据的范本影像。
于一实施例中,各范本数据包括范本声纹与范本影像。控制装置10是决定范本声纹与输入声纹相符的部分的范本数据,并选择相符的范本数据的范本影像。
于一实施例中,若控制装置10判断人员不符合所有范本数据(如于步骤s20中没有选择任一范本数据)时,则可经由人机界面14发出警示。
步骤s22:控制装置10经由影像撷取装置11拍摄人员的脸部以获得输入脸部影像,并依据所选择的部分的范本影像对输入脸部影像执行影像比对处理。具体而言,控制装置10是分别比对输入脸部影像与所选择的各范本影像,并选择相符的范本影像做为比对结果。
于一实施例中,控制装置10是分别计算输入脸部影像与所选择的各范本影像之间的相似度,并选择相似度最高且不小于相似度临界值的范本影像做为比对结果。并且,若输入脸部影像与所有范本影像之间的相似度皆小于相似度临界值时,控制装置10不选择任何范本影像。
更进一步地,于一实施例中,如图2所示,控制装置10可将所拍摄的输入脸部影像31显示于人机界面14,以供人员知悉所拍摄的脸部影像是否符合期待,即供人员判断控制装置10所拍摄的输入脸部影像31是否正确且清楚地呈现自己的脸部样貌。
步骤s23:控制装置10依据比对结果辨识人员。具体而言,若控制装置10判断人员符合任一范本影像(如于步骤s22中有选择任一范本影像)时,则辨识当前的人员为合法人员。若控制装置10判断人员不符合所有范本影像(如于步骤s22中没有选择任一范本影像)时,则辨识当前的人员为非法人员。
于一实施例中,人员辨识系统1可进一步决定当前的人员的身份。具体而言,多个范本影像分别对应不同人员的身份数据。控制装置10是以相符的范本影像所对应的身份数据来做为当前人员的身份。
值得一提的是,由于文本的比对速度远快于声纹的比对速度,当依据输入文本来选择部分范本数据时,本发明可大幅减少比对所需时间,进而缩短辨识人员身份的时间。
更进一步地,当所有范本文本之间皆没有重复时,本发明可大幅减少后续影像比对的范本数,而可大幅提升后续影像比对的准确性与比对速度。
此外,由于声纹具有独特性,当依据输入声纹来选择部分范本数据时,本发明经由预先过滤声纹不符的范本数据,可大幅减少后续影像比对的范本数,而可大幅提升后续影像比对的准确性与比对速度。
续请一并参阅图6,为本发明的第三实施例的人员辨识方法的流程图。本实施例的人员辨识方法是依据人员的输入脸部影像(即前述第一输入数据)来选择部分范本语音特征(即前述范本数据),并经由比对人员的输入语音(即前述第二输入数据)与所选择的范本语音特征来辨识人员的身份。具体而言,本实施例的人员辨识方法包括以下步骤。
步骤s30:控制装置10经由影像撷取装置11拍摄人员的脸部以获得输入脸部影像,并依据所选择的部分的范本影像对输入脸部影像执行影像比对处理。步骤s30的影像比对处理可与图5的步骤s22所述的影像比对处理相同或相似。
具体而言,各范本数据包括范本语音特征(如范本文本或范本声纹)与范本影像(即多个范本语音特征分别对应多个范本影像)。控制装置10是分别比对输入脸部影像与各范本影像,并选择符合的(如相似度不小于相似度临界值,此处的相似度临界值可小于图5的步骤s22的相似度临界值)范本影像做为比对结果。
并且,若输入脸部影像与所有范本影像皆不符时,控制装置10不选择任何范本数据。
步骤s31:控制装置10依据比对结果于多个范本语音特征中选择部分范本语音特征。
于一实施例中,各范本数据包括范本语音特征与范本影像。控制装置10是决定范本影像相符的部分的范本数据,并选择相符的范本数据的范本语音特征。
于一实施例中,若控制装置10判断人员不符合所有范本数据(如于步骤s30中没有选择任一范本数据)时,则可经由人机界面14发出警示。
步骤s32:控制装置10经由收音装置12接收人员的语音以产生输入语音,并依据所选择的部分的范本语音特征对输入语音执行语音比对处理。步骤s32的语音比对处理可与图5的步骤s20所述的语音比对处理相同或相似。
于一实施例中,各范本数据包括范本语音特征与范本影像。人员可对收音装置12说出任意或指定语音,控制装置10可对人员所输入的输入语音进行解析以获得输入语音特征(如输入声纹或输入文本),逐一比对输入语音特征与所选择的各范本语音特征,并选择最符合的范本数据的范本语音特征作为比对结果。
并且,若输入语音特征与所有范本语音特征皆不符时,控制装置10不选择任何范本数据。步骤s33:控制装置10依据比对结果辨识人员。具体而言,若控制装置10判断人员的语音符合任一范本语音特征(如于步骤s32中有选择任一范本语音特征)时,则辨识当前的人员为合法人员。若控制装置10判断人员的语音不符合所有范本语音特征(如于步骤s32中没有选择任一范本语音特征)时,则辨识当前的人员为非法人员。
于一实施例中,人员辨识系统1可进一步决定当前的人员的身份。具体而言,多个范本语音特征分别对应不同人员的身份数据。控制装置10是以相符的范本语音特征所对应的身份数据来做为当前人员的身份。
续请一并参阅图7,为本发明的第四实施例的语音比对处理的流程图。本实施例提出一种语音比对处理的具体实施方式,可运用于图4至图7所示的任一人员辨识方法,如运用于图5的步骤s20的语音比对处理或图6的步骤s32的语音比对处理。具体而言,本实施例的语音比对处理包括用以实现语音比对功能的以下步骤。
步骤s40:控制装置10经由收音装置12感测环境的语音以产生输入语音。
步骤s41:控制装置10判断输入语音的音量是否大于音量临界值。若音量大于音量临界值,控制装置10判定所产生输入语音包括人员的语音,并执行步骤s42。否则,控制装置10判定所产生输入语音不包括人员的语音,并再次执行步骤s40。
步骤s42:控制装置10对输入语音执行解析处理(如文本解析处理(接续执行步骤s43)或声纹解析处理(接续执行步骤s46)。
若控制装置1执行文本解析处理而获得输入文本,则控制装置10执行步骤s43:控制装置10对输入文本与范本数据的范本文本执行前述的文本比对处理以选择文本数据相符的范本数据。
若控制装置1执行声纹解析处理而获得输入声纹,则控制装置10执行步骤s46:控制装置10对输入声纹与范本数据的范本声纹执行前述的声纹比对处理以选择声纹数据相符的范本数据。
步骤s44:控制装置10判断是否输入语音特征(如输入文本或输入声纹)是否符合任一范本语音特征,如判断步骤s43与步骤s46中是否选择任何范本数据。
若输入语音特征符合任一范本语音特征,则控制装置10执行步骤s45。若输入语音特征不符合所有范本语音特征,则控制装置10执行步骤s47。
步骤s45:控制装置10判定辨识成功。
于一实施例中,控制装置10对输入语音同时执行文本解析处理及声纹解析处理,并于输入文本符合任一范本数据的范本文本且输入声纹符合相同范本数据的范本声纹时,判定辨识成功,并以此范本数据所对应的人员数据作为人员的身份。
步骤s47:控制装置10判定本次语音比对处理的比对结果为辨识失败,并计算语音比对处理因失败(如连续失败)而重新执行的次数。接着,控制装置10判断前述重新执行的次数是否超过预设次数(如三次)。
若重新执行的次数超过预设次数,则不再重新执行语音比对处理,以避免遭有心人士以暴力法破解人员辨识系统1。
若重新执行的次数未超过预设次数,则重新感测同一人员的输入语音(步骤s40)以重新执行语音比对处理。
续请一并图8,为本发明的第五实施例的影像比对处理的流程图。本实施例提出一种影像比对处理的具体实施方式,可运用于图4至图7所示的任一人员辨识方法,如运用于图5的步骤s22的影像比对处理或图6的步骤s30的影像比对处理。具体而言,本实施例的影像比对处理包括用以实现影像比对功能的以下步骤。
步骤s50:控制装置10经由影像撷取装置11对人员的脸部进行拍摄以获得输入脸部影像。
于一实施例中,控制装置10可控制影像撷取装置11对人员的脸部进行多次拍摄以获得同一人员的多个输入脸部影像。
步骤s51:控制装置10计算输入脸部影像与各范本数据的范本影像之间的相似度。
于一实施例中,各范本数据可包括一或多个范本影像,控制装置10计算(一或多个)各输入脸部影像与同一范本数据的各范本影像进行比对(如比对像素值或影像特征)以决定各范本影像与各输入脸部影像之间的相似度。
步骤s52:控制装置10判断是否任一相似度不小于相似度临界值。
若控制装置10判断任一输入脸部影像的相似度不小于相似度临界值,则执行步骤s53。若控制装置10判断所有输入脸部影像的相似度皆不小于相似度临界值,则执行步骤s54。
于一实施例中,控制装置10是于所有或过半数的输入脸部影像的相似度不小于相似度临界值时,才执行步骤s53。
步骤s53:控制装置10判定辨识成功。
步骤s54:控制装置10判定本次影像比对处理的比对结果为辨识失败,并计算影像比对处理因失败(如连续失败)而重新执行的次数。接着,控制装置10判断前述重新执行的次数是否超过预设次数(如三次)。
若重新执行的次数超过预设次数,则不再执行影像比对处理,以避免遭有心人士以暴力法破解人员辨识系统1。
若重新执行的次数未超过预设次数,则重新拍摄同一人员的输入脸部影像(步骤s50)以重新执行影像比对处理。
续请一并参阅图8及图9,图9为本发明的第六实施例的相似度计算的流程图。本实施例提出一种相似度计算的具体实施方式,可运用于图8所示的相似度计算(如运用于图8的步骤s50至s51)。
具体而言,于本实施例中,影像撷取装置11包括彩色影像撷取装置110与红外线影像撷取装置111,各范本影像包括一或多张彩色范本影像及一或多张红外线范本影像。本实施例主要是依据彩色影像间的彩色相似度与红外影像间的红外线相似度来决定最终的相似度,即经由比对彩色脸部影像及彩色范本影像并比对红外线脸部影像及红外线范本影像辨识人员。
本实施例的相似度计算包括以下步骤。
步骤s60:控制装置10经由彩色影像撷取装置110拍摄人员的脸部以获得一或多张彩色脸部影像。
步骤s61:控制装置10将所拍摄的红外线脸部影像与各范本影像的红外线范本影像进行影像比对以决定各红外线脸部影像与各红外线范本影像之间的红外线相似度。
步骤s62:控制装置10经由红外线影像撷取装置111拍摄人员的脸部以获得一或多张红外线脸部影像。
步骤s63:控制装置10将所拍摄的彩色脸部影像与各范本影像的彩色范本影像进行影像比对以决定各彩色脸部影像与各彩色范本影像之间的彩色相似度。
步骤s64:控制装置10依据属于同一范本影像的彩色相似度及红外线相似度计算此范本影像的相似度。值得一提的是,由于彩色影像比对处理容易因环境色温变化而造成误判,本发明经由结合红外线影像(环境的热辐射影像)比对处理可有效避免因色温变化所造成的误判,进而提升辨识正确率。
续请一并参阅图8及图10,图10为本发明的第七实施例的设定范本影像的流程图。本实施例提出一种设定范本影像功能,可建立合法的人员的范本影像,以用于前述影像比对处理。具体而言,本实施例的人员辨识方法包括以下于进行人员辨识前被执行以实现设定范本影像功能的步骤。
步骤s70:控制装置10经由影像撷取装置11拍摄同一人员的多张范本影像(如拍摄五张范本影像)。
于一实施例中,控制装置10可控制彩色影像撷取装置110拍摄同一人员的一或多张彩色范本影像,并控制红外线影像撷取装置111拍摄同一人员的一或多张红外线范本影像。
步骤s71:控制装置10计算各范本影像之间的相似度(如依据彩色相似度与红外线相似度计算相似度)。
步骤s72:控制装置10判断是否所有范本影像与其他范本影像之间的相似度皆不小于预设的相似度临界值。
若所有范本影像的相似度皆不小于相似度临界值,则执行步骤s73。若任一范本影像的相似度小于相似度临界值,则执行步骤s74。
步骤s73:控制装置10储存所有彼此相符的范本影像,并完成范本影像的设定。
步骤s74:控制装置10删除与其他范本影像之间的相似度小于相似度临界值的范本影像,并再次执行步骤s70以重拍所删除的不相似的范本影像,并继续设定范本影像。
举例来说,拍摄三张范本影像(分别为第一张范本影像、第二张范本影像与第三张范本影像),相似度临界值为95%。第一张范本影像与第二张范本影像之间的相似度为80%,第一张范本影像与第三张范本影像之间的相似度为75%,第二张范本影像与第三张范本影像之间的相似度为98%。
由此可知,第一张范本影像与其他范本影像不相似(相似度小于95%)。人员控制系统1可删除第一张范本影像并重拍新的范本影像(第四张范本影像),并计算第四张范本影像、第二张范本影像与第三张范本影像之间的相似度,以此类推。
本发明所设定的多张范本影像之间具有高相似度,而可有效提升影像比对的准确性,进而提升人员辨识的准确性。
续请一并参阅图5及图11,图11为本发明的第八实施例的人员辨识方法的流程图。相较于图5所示的人员辨识方法,本实施例的人员辨识方法于依据人员的输入语音的文本来选择部分范本数据(如范本影像与范本声纹)后,可选择仅执行影像比对处理来辨识人员的身份,仅执行声纹比对处理来辨识人员的身份,或执行影像比对处理与声纹比对处理来辨识人员的身份。并且,于本实施例中,各范本数据包括范本文本、范本声纹与范本影像,多个范本数据分别对应至不同人员的身份数据。具体而言,本实施例的人员辨识方法包括以下步骤。
步骤s80:控制装置10经由收音装置12接收人员的语音以产生输入语音,并对输入语音执行语音比对处理(如文本比对处理)。
接着,控制装置10可执行步骤s81及步骤s82的影像比对处理。
步骤s81:控制装置10决定范本文本与输入文本相符的部分的范本数据,并选择相符的范本数据的范本影像。
步骤s82:控制装置10经由影像撷取装置11拍摄人员的脸部以获得输入脸部影像,并依据所选择的部分的范本影像对输入脸部影像执行影像比对处理。
并且,控制装置10还可执行步骤s84及步骤s85的声纹比对处理。
步骤s84:控制装置10决定范本文本与输入文本相符的部分的范本数据,并选择相符的范本数据的范本声纹。
步骤s85:控制装置10解析输入语音以获得输入声纹,并依据所选择的部分的范本声纹对输入声纹执行声纹比对处理。
步骤s83:控制装置10依据影像比对处理的比对结果及/或声纹比对处理的处理结果来辨识人员。
于一实施例中,控制装置10是以影像比对处理相符的范本影像所对应的身份数据来做为当前人员的身份。
于一实施例中,控制装置10是以声纹比对处理相符的范本声纹所对应的身份数据来做为当前人员的身份。
于一实施例中,控制装置10是于相符的范本影像所对应的身份数据与相符的范本声纹所对应的身份数据重复时,以重复的身份数据来做为当前人员的身份。
本发明经由结合影像比对处理与声纹比对处理可有效提升人员辨识的准确性。
当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本发明所属技术领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求书的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!