一种人机共融的远程态势智能感知系统的制作方法
本发明属于人工智能和态势感知技术领域,具体涉及一种人机共融的远程态势智能感知系统。
背景技术:
增强现实是指将计算机系统提供的信息或图像与现实世界信息进行叠加呈现给用户,从而提升用户对现实世界的感知能力;其重点是该信息或图像是叠加到现实世界上的,是一种“实中有虚”的表现效果,对用户来说,相当于“增强”了其对现实世界的理解和感知。
随着人工智能技术的发展,各行各业“无人化”设备数量急剧增多,性能也得到了极大提升,可以预见,未来大量的工作将由智能化设备完成,工作场景将形成“人”与智能“机器人”混编的局面。无人设备在很多场景下,例如火灾及地震现场、高海拔地区等有着常人无法企及的优势,同时在未来战场中,无人设备在侦察、分析、打击等方面的有着独特的优势。无人平台通过传感器获取特殊场景下的图像、声音等信息极大的延伸了人的“眼”与“耳”,使人对周边复杂未知环境的感知范围与深度得到极大扩展。
但是,无人设备所采集的信息纷繁复杂,如城市场景中,街面上建筑物错落交织,街面下水管、隧道星罗棋布,大量错综复杂的信息让人“充满着迷雾”。这些复杂的场景特征既扩展了人的感知,同时也影响了人对有效信息的提取,如何在复杂环境下清晰感知整体态势显得十分重要。
技术实现要素:
本发明的目的在于,为解决现有技术存在上述缺陷,本发明提出了一种人机共融的远程态势智能感知系统,通过增强现实设备实现人机协同的态势感知,运用无人机等设备充当“眼”和“耳”获取大范围场景态势信息,经过对多源、多类型的数据融合后汇聚到服务端,并进行三维重构、目标识别、感兴趣信息提取,再经过头戴式增强现实设备与人眼中的真实环境进行高精度配准,最后经过头戴显示设备实现对环境、人体行为、车辆、威胁来源等态势信息的“虚实结合”展示。
为了实现上述目的,本发明提供了一种人机共融的远程态势智能感知系统,将增强现实技术与无人系统技术相结合,将场景感知设备探测到的当前场景的环境与目标信息通过增强现实设备与人的视觉内容进行一致性融合,人机共融,真正成为人的“眼”与“耳”的延伸,使人对周边复杂未知环境的感知范围与深度极大扩展,能够在不干扰人员正常行动的情况下提供穿越障碍、跨视距、超分辨的环境感知与目标认知等应用服务。该系统具体包括:
场景感知设备,其搭载在无人移动平台上,用于获取当前场景中的虚拟场景部分的单目彩色图像、双目彩色图像、深度图像、点云数据、惯性测量数据,基于上述数据,构建初步的三维场景模型;
定位单元,位于场景感知设备上,用于实时获取场景感知设备所处的位置,对当前场景的虚拟场景部分进行定位;
由于场景感知设备搭载在无人平台上,无人平台是实时移动的,如果室外的大部分场景有gps信号,则定位单元可以通过采用gps对场景感知设备所处的位置进行定位;如果室外的场景或者室内的场景没有gps信号,则定位单元依靠视觉定位来实时获取无人平台的位置,进而获得场景感知设备所处的位置,以解决无gps信号环境下的定位问题。其中,所述定位具体包括:
a)通过双目彩色图像融合惯性测量数据来定位场景感知设备所处的位置;
b)通过单目彩色图像、深度图像融合惯性测量数据来定位场景感知设备所处的位置;
c)通过点云数据融合惯性测量数据来定位场景感知设备所处的位置。
场景重建单元,用于基于场景感知设备所获取的初步的三维场景模型和当前场景的虚拟场景部分的定位信息,利用视觉特征,重建当前场景的虚拟场景部分的三维重建模型,形成一个逼真的高精度的三维地图。在重建过程中,采用动静分离,提取、标注动态目标的信息,便于用户认知和识别。
人体识别单元,用于识别当前场景的虚拟场景部分的三维重建模型中的人体姿态;
增强现实设备,用于获取当前场景中的现实场景部分的单目彩色图像、双目彩色图像、深度图像、点云数据、惯性测量数据,构建现实场景部分的三维重建模型;
虚实融合单元,用于将虚拟场景部分的三维重建模型与现实场景部分的三维重建模型进行融合,获得虚实融合后的当前场景的三维重建模型;
可视交互单元,用于展示虚实融合后的当前场景的三维重建模型。
作为上述系统的改进之一,上述场景感知设备进一步包括:
单目相机,用于获取场景感知设备所处当前场景的单目彩色图像;
双目相机,用于获取场景感知设备所处当前场景的特定基线下的双目彩色图像;
深度传感器,用于获取场景感知设备所处当前场景的深度数据;
激光雷达,用于获取场景感知设备所处当前场景的点云数据;
惯性传感器,用于获取场景感知设备所处当前场景的惯性测量数据;
基于获取的当前场景中的虚拟场景部分的单目彩色图像、双目彩色图像、深度图像、点云数据、惯性测量数据,基于上述数据,构建初步的三维场景模型。
其中,所述单目彩色图像为单目相机视场内的rgb图像,所述双目彩色图像为双目相机视场内的左目及右目两幅rgb图像,所述深度图像为深度传感器视场内场景物体到深度传感器距离经过归一化后的灰度图像,所述点云数据为激光雷达视场内的场景物体的rgbd数据,所述惯性测量数据为场景感知设备移动时其姿态变化数据;
其中,场景感知设备可以搭载在无人机或无人车等移动平台上,开展不同区域的数据采集。
作为上述系统的改进之一,所述场景重建单元具体包括:
通过单目彩色图像与深度图像结合、双目彩色图像基于双目相机的基线大小、或激光雷达获取场景点云数据,再结合定位单元所获取的场景感知设备所处的位置,通过不断融合相邻时刻所获取的场景点云数据并进行网格化,结合视觉特征,逐步细化并修正场景感知设备所构建的初步三维场景模型,重建当前场景的虚拟场景部分的三维重建模型,形成一个逼真的高精度的三维地图。
在三维重建模型的场景构建过程中,场景中的动态物体对应的点云数据会影响相邻时刻点云数据的视觉特征匹配,采用基于区域转换矩阵分类的动目标分割方法进行动静分离,对于场景中分离后的静态物体对应的点云数据用于上述三维重建模型的重建,对于场景中分离后的动态物体对应的点云数据则进行动态目标的标注。回环检测优化是用来消除逐步构建三维重建模型时所带来的累积误差,当场景感知设备获取到新的点云数据时,将其与前面所获取的点云数据进行对比,如果发现二者是同一个地方的数据时,则以此时新的点云数据和场景感知设备的定位数据为基准对前面整个过程中所构建的三维重建模型进行精细调整和优化,从而形成全局一致的高精度三维地图。
作为上述系统的改进之一,所述人体识别单元具体包括:
二维姿态估计、姿态预测优化、三维姿态映射;具体地,针对当前场景的虚拟场景部分的三维重建模型中的每一幅彩色图像,基于人体骨骼关节点拓扑结构,通过深度学习的方法,确定人体各肢体在图像中的位置、区域,从而估计人体的二维姿态;由于人体的运动是连续的,其骨骼关节点的运动轨迹也是连续的,因此利用相邻时刻获取的人体的二维姿态信息,对当前时刻所估计的人体的二维姿态进行预测修正,最终得到优化后的人体的二维姿态信息;通过优化后的人体的二维姿态,针对每一个关节点在二维图像中的像素位置来查找其在深度数据所对应的深度信息,从而获取三维人体姿态,并将该三维人体姿态结果与场景重建单元中动静分离后的运动物体点云数据进行匹配,对匹配成功的点云数据进行网格化,完成三维姿态映射,形成最终的三维场景下的人体姿态。
作为上述系统的改进之一,所述虚实融合单元具体包括:
根据每一时刻中的场景感知设备与增强现实设备分别在现实世界中所处的位置和姿态来配准对应时刻的数据内容,从而将虚拟场景部分的三维重建模型与现实场景部分的三维重建模型进行几何一致性渲染,并进行配准定位,达到高精度匹配;通过实时获取场景感知设备所处场景以及增强现实设备所处场景中的光源进行光照一致性渲染,获得渲染融合后的场景光照;将虚拟场景部分的三维重建模型与现实场景部分的三维重建模型,以及渲染融合后的场景光照进行融合,获得虚实融合后的当前场景的三维重建模型。
其中,场景重建单元每个时刻所重建的虚拟场景部分的三维模型网格数量很大,为了提高渲染效率,虚实融合单元对场景更新内容进行优化,即对于静态场景信息只更新实际变化部分,对人体骨骼等动态信息实时更新骨骼点位置,其骨骼关节点的拓扑结构预先约定,这样能有效降低系统负荷提高渲染帧率;几何一致性解决了虚实场景几何一致性如配准定位、透视关系、遮挡关系等问题,光照一致性则是通过实时获取场景感知设备所处场景以及增强现实设备所处场景中的光源来渲染融合后的场景光照。
本发明的优点在于:
1.提出了一种人机共融的远程态势智能感知方法,让无人集群真正成为人的“眼”与“耳”的延伸,使人对周边复杂未知环境的感知范围与深度极大扩展,能够在不干扰人员正常行动的情况下提供穿障碍、跨视距、超分辨的环境感知与目标认知等应用服务;
2.设计了场景智能感知设备,重点解决了在无gps环境下,在微型处理器上基于稀疏地图的快速自主定位、避障问题,并实现了单节点上场景数据的实时压缩与传输,为高精度地图构建、路径规划、协同作业等应用奠定了基础。
附图说明
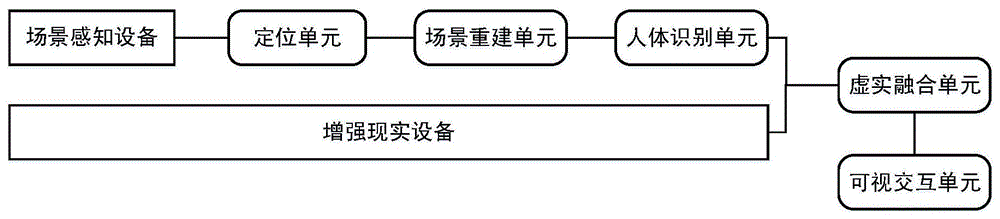
图1是本发明的一种人机共融的远程态势智能感知系统的结构示意图;
图2是本发明的一种人机共融的远程态势智能感知系统的场景重建单元的三维重建场景效果图;
图3是本发明的一种人机共融的远程态势智能感知系统的人体识别单元的人体识别效果图;
图4是本发明的一种人机共融的远程态势智能感知系统的虚实融合单元的虚实融合效果图。
具体实施方式
现结合附图对本发明作进一步的描述。
如图1所示,本发明提供了一种人机共融的远程态势智能感知系统,场景感知设备所获取的原始信息包括很多二维彩色图像、深度图像、点云等等,这些信息是杂乱无章的,通过场景重构单元构建出实际的地形数据并提取感兴趣的实体对象进行标注如车辆、桌子、椅子等,同时通过人体行为识别单元识别出其中的人物及其动作并进行标注,对其中无效的信息或用户不感兴趣的信息,进行剔除,不再显示,从而将用户从大量复杂零碎的数据中解脱出来,一目了然的获知场景的整体态势。另外则是通过系统让用户能够感知视线范围外的信息,达到穿墙透视的效果,这是系统的出发点。
所述人机共融的远程态势智能感知系统包括:
场景感知设备,其搭载在无人移动平台上,用于获取当前场景中的虚拟场景部分的单目彩色图像、双目彩色图像、深度图像、点云数据、惯性测量数据,基于上述数据,构建初步的三维场景模型;
定位单元,位于场景感知设备上,用于实时获取场景感知设备所处的位置,对当前场景的虚拟场景部分进行定位;
由于场景感知设备搭载在无人平台上,无人平台是实时移动的,如果室外的大部分场景有gps信号,则定位单元可以通过采用gps对场景感知设备所处的位置进行定位;如果室外的场景或者室内的场景没有gps信号,则定位单元依靠视觉定位来实时获取无人平台的位置,进而获得场景感知设备所处的位置,以解决无gps信号环境下的定位问题。其中,所述定位具体包括:
a)通过双目彩色图像融合惯性测量数据来定位场景感知设备所处的位置;
b)通过单目彩色图像、深度图像融合惯性测量数据来定位场景感知设备所处的位置;
c)通过点云数据融合惯性测量数据来定位场景感知设备所处的位置。
场景重建单元,用于基于场景感知设备所获取的初步的三维场景模型和当前场景的虚拟场景部分的定位信息,利用视觉特征,重建当前场景的虚拟场景部分的三维重建模型,形成一个逼真的高精度的三维地图。在重建过程中,采用动静分离,提取、标注动态目标的信息,便于用户认知和识别。
人体识别单元,用于识别当前场景的虚拟场景部分的三维重建模型中的人体姿态;
增强现实设备,用于获取当前场景中的现实场景部分的单目彩色图像、双目彩色图像、深度图像、点云数据、惯性测量数据,构建现实场景部分的三维重建模型;
虚实融合单元,用于将虚拟场景部分的三维重建模型与现实场景部分的三维重建模型进行融合,获得虚实融合后的当前场景的三维重建模型;
可视交互单元,用于展示虚实融合后的当前场景的三维重建模型。
作为上述系统的改进之一,上述场景感知设备进一步包括:
单目相机,用于获取场景感知设备所处当前场景的单目彩色图像;
双目相机,用于获取场景感知设备所处当前场景的特定基线下的双目彩色图像;
深度传感器,用于获取场景感知设备所处当前场景的深度数据;
激光雷达,用于获取场景感知设备所处当前场景的点云数据;
惯性传感器,用于获取场景感知设备所处当前场景的惯性测量数据;
基于获取的当前场景中的虚拟场景部分的单目彩色图像、双目彩色图像、深度图像、点云数据、惯性测量数据,基于上述数据,构建初步的三维场景模型。
其中,所述单目彩色图像为单目相机视场内的rgb图像,所述双目彩色图像为双目相机视场内的左目及右目两幅rgb图像,所述深度图像为深度传感器视场内场景物体到深度传感器距离经过归一化后的灰度图像,所述点云数据为激光雷达视场内的场景物体的rgbd数据,所述惯性测量数据为场景感知设备移动时其姿态变化数据;
其中,场景感知设备可以搭载在无人机或无人车等移动平台上,开展不同区域的数据采集。
作为上述系统的改进之一,所述场景重建单元具体包括:
通过单目彩色图像与深度图像结合、双目彩色图像基于双目相机的基线大小、或激光雷达获取场景点云数据,再结合定位单元所获取的场景感知设备所处的位置,通过不断融合相邻时刻所获取的场景点云数据并进行网格化,结合视觉特征,逐步细化并修正场景感知设备所构建的初步三维场景模型,重建当前场景的虚拟场景部分的三维重建模型,形成一个逼真的高精度的三维地图。
在三维重建模型的场景构建过程中,场景中的动态物体对应的点云数据会影响相邻时刻点云数据的视觉特征匹配,采用基于区域转换矩阵分类的动目标分割方法进行动静分离,对于场景中分离后的静态物体对应的点云数据用于上述三维重建模型的重建,对于场景中分离后的动态物体对应的点云数据则进行动态目标的标注。回环检测优化是用来消除逐步构建三维重建模型时所带来的累积误差,当场景感知设备获取到新的点云数据时,将其与前面所获取的点云数据进行对比,如果发现二者是同一个地方的数据时,则以此时新的点云数据和场景感知设备的定位数据为基准对前面整个过程中所构建的三维重建模型进行精细调整和优化,从而形成全局一致的高精度三维地图。如图2所示,图2为三维场景重构及增强现实效果示意图,图中的三角网格是通过场景重建单元对现实场景部分进行三维重构所建立的网格地图,图中的太阳系、展示面板是构建的虚拟对象。
作为上述系统的改进之一,所述人体识别单元具体包括:
二维姿态估计、姿态预测优化、三维姿态映射;具体地,针对当前场景的虚拟场景部分的三维重建模型中的每一幅彩色图像,基于人体骨骼关节点拓扑结构,通过深度学习的方法,确定人体各肢体在图像中的位置、区域,从而估计人体的二维姿态;由于人体的运动是连续的,其骨骼关节点的运动轨迹也是连续的,因此利用相邻时刻获取的人体的二维姿态信息,对当前时刻所估计的人体的二维姿态进行预测修正,最终得到优化后的人体的二维姿态信息;通过优化后的人体的二维姿态,针对每一个关节点在二维图像中的像素位置来查找其在深度数据所对应的深度信息,从而获取三维人体姿态,并将该三维人体姿态结果与场景重建单元中动静分离后的运动物体点云数据进行匹配,对匹配成功的点云数据进行网格化,完成三维姿态映射,形成最终的三维场景下的人体姿态。如图3所示,通过人体识别单元对人体骨骼关键点的提取及其拓扑关系的管理来建立识别后的人体骨骼信息。
作为上述系统的改进之一,所述虚实融合单元具体包括:
根据每一时刻中的场景感知设备与增强现实设备分别在现实世界中所处的位置和姿态来配准对应时刻的数据内容,从而将虚拟场景部分的三维重建模型与现实场景部分的三维重建模型进行几何一致性渲染,并进行配准定位,达到高精度匹配;通过实时获取场景感知设备所处场景以及增强现实设备所处场景中的光源进行光照一致性渲染,获得渲染融合后的场景光照;将虚拟场景部分的三维重建模型与现实场景部分的三维重建模型,以及渲染融合后的场景光照进行融合,获得虚实融合后的当前场景的三维重建模型。如图4所示,图中的立方体表示所构建的墙背后的障碍物,不同灰度级别表示障碍物离人的远近,浅色表示距离近,深色表示距离远;折线表示所构建的人群从墙背后走过时的人体骨骼信息。
其中,场景重建单元每个时刻所重建的虚拟场景部分的三维模型网格数量很大,为了提高渲染效率,虚实融合单元对场景更新内容进行优化,即对于静态场景信息只更新实际变化部分,对人体骨骼等动态信息实时更新骨骼点位置,其骨骼关节点的拓扑结构预先约定,这样能有效降低系统负荷提高渲染帧率;几何一致性解决了虚实场景几何一致性如配准定位、透视关系、遮挡关系等问题,光照一致性则是通过实时获取场景感知设备所处场景以及增强现实设备所处场景中的光源来渲染融合后的场景光照。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!