一种图片文字识别方法与流程
本发明涉及文字识别领域,尤其涉及一种图片文字识别方法。
背景技术:
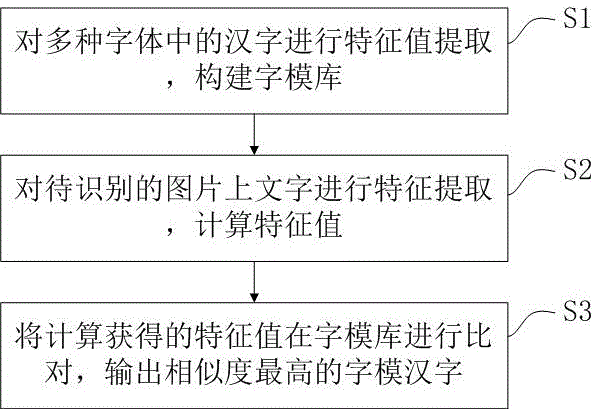
:目前印刷体汉字识别的方法主要有结构模式识别方法和统计模式识别方法。结构模式识别方法和统计模式识别方法主要利用了汉字的笔划特征、结构点特征、投影特征、轮廓特征、直方图特征等特征。。但目前现有技术中采用的结构模式和统计模式存在特征提取困难,部分算法复杂度高、计算量大等问题。技术实现要素:本发明所要解决的技术问题在于,提供一种图片文字识别方法,利用汉字的全局和局部黑白像素的组合特征来对印刷体汉字进行识别,该方法原理简单,计算量小,识别准确率高。本发明提供一种图片文字识别方法,包括步骤:s1、对多种字体中的汉字进行特征值提取,构建字模库;s2、对待识别的图片上文字进行特征提取,计算特征值;s3、将计算获得的特征值在字模库进行比对,输出相似度最高的字模汉字。进一步地,所述步骤1具体包括:s101、对一个汉字进行区域划分,将该汉字划分为n个不同的区域,n为大于2的整数;s102、计算每个区域的特征值,将n个区域的特征值进行存储;s103、根据字库中所有汉字的多种字体以及多种字号所对应的n区域的特征值构建字模库。进一步地,步骤1还包括:s104、根据每个区域的特征值计算单个区域的识别准确率,选取其中的m个作为比较区域,m≤n;进一步地,所述步骤101中n为10,区域具体包括整体、中间部分、上半部分、下半部分、左半部分、右半部分、左上角部分、右上角部分、左下角部分、右下角部分。进一步地,所述步骤2具体包括:s201、以图片形式提取待识别图片中的文字;s202、对提取到的文字图片进行区域划分,将文字图片划分为不同的区域;s203、选取与比较区域对应的m个区域;s204、计算选取的m个区域的特征值。进一步地,所述步骤202中进行区域划分时采用矩形框的形式,除中间部分以外,其余区域的所述矩形框的框线至少与图片的最上端、最左端、最下端、最右端其中之一相切。进一步地,m为6至8。进一步地,所述步骤3中,输出的汉字为可编辑形式。本发明与现有技术相比有益效果在于,进行文字识别时,只采用了图片文字的黑白像素特征,且只用计算区别作用强的6-8个区域进行组合计算,原理简单,计算量小,准确率高。附图说明图1为本发明实施方式中图片文字识别方法流程图;图2为本发明实施方式中汉字进行区域划分的示意图。具体实施方式以下结合实施例,对本发明作进一步具体描述,但不局限于此。本发明的一种图片文字识别方法,如图1所示,包括步骤:s1、对多种字体中的汉字进行特征值提取,构建字模库;s2、对待识别的图片上文字进行特征提取,计算特征值;s3、将计算获得的特征值在字模库进行比对,输出相似度最高的字模汉字。在上述方案的基础上,进一步地,所述步骤1具体包括:s101、对一个汉字进行区域划分,将该汉字划分为n个不同的区域,n为大于2的整数。优选的,n为10,区域划分如图2所示,具体包括汉字的整体f1、中间部分f2、上半部分f3、下半部分f4、左半部分f5、右半部分f6、左上角部分f7、右上角部分f8、左下角部分f9、右下角部分f10。在其他实施方式中,对汉字进行划分的区域不限于这些部分,为了提高准确性还可以增加更多的区域。s102、计算每个区域的特征值,将n个区域的特征值进行存储。具体的以汉字所处平面建立x-y坐标系,横向为x轴,纵向为y轴,(x,y)为像素点的横坐标和纵坐标,则令其中0<x<i,0<y<j,公式(1)其中,i为该区域的图像宽度,j为该区域的图像高度,令该区域的黑白值的集合为t,t={t(x,y)},公式(2)。则该区域的特征值η为,其中η1为t中1的个数,η2=i×j,为t中元素的个数。s103、根据字库中所有汉字的多种字体以及多种字号所对应的n区域的特征值构建字模库。优选的,构建字模库的字体包括宋体、楷体、隶书、仿宋、等线、雅黑等多种字体,字体还可以根据需要进行扩充。字号包括初号(42pt)、小初(36pt)、一号(26pt)、小一(24pt)、二号(22pt)、小二(18pt)、三号(16pt)、小三(15pt)、四号(14pt)、小四(12pt)、五号(10.5pt)、小五(9pt)、六号(7.5pt)、小六(6.5pt)等常用的十四种字号。在上述方案的基础上,进一步地,s104、根据每个区域的特征值计算单个区域的识别准确率,选取其中的m个作为比较区域,m≤n。优选的,m为6至8。具体的,从字库中选取一个或多个汉字作为准确率测试汉字,按步骤101的n个区域对准确率测试汉字进行划分,依次计算各个区域的识别准确率。计算过程如下:δη=(η′n-ηn)2,0<n≤n,公式(4),其中,δη为准确率测试汉字第n个区域的特征值η′n与模板库中某一候选字的对应特征值ηn的差异。对δη进行排序,输出字模库中δη最小值对应的汉字,如果输出的汉字与准确率测试汉字相同,则识别成功,如果不同则认为失败。以宋体为例,设pn为第n个区域n的识别准确率,则各特征区域识别准确率如表1所示,其中表中单位为百分比:表1宋体字各特征区域的识别准确率(单位%)p1p2p3p4p5p6p7p8p9p10六号1.830.690.891.140.961.280.350.520.510.62小五2.761.341.341.541.391.680.540.650.540.69五号3.441.091.602.081.882.200.600.910.821.00小四4.891.972.482.762.393.111.051.291.031.19四号7.031.713.213.683.504.221.511.821.531.65小三7.032.803.615.093.994.621.452.072.022.17三号7.603.454.594.454.674.501.962.101.971.82小二12.534.786.327.877.447.582.943.163.343.34二号18.657.4311.0210.8610.6811.164.615.105.214.65小一18.236.4111.7711.8511.2211.994.995.755.665.09一号22.389.4013.5814.9514.6714.535.866.867.416.36小初41.8715.2926.2430.2428.4029.7912.4814.5515.5214.15初号53.3823.3035.1240.5837.9937.2216.4018.7222.0219.08均值15.516.139.3710.559.9410.304.214.885.204.75从表1我们可以看出各区域的识别准确率随着字号的增大而升高。以区域1为例,六号字体下区域1的识别准确率为1.83%,初号字体下区域1的识别准确率为53.38%。这说明图像质量越高,可获取的特征越准确。宋体单个区域识别率由高到低依次为:f1、f4、f6、f5、f3、f2、f9、f8、f10、f7。如果按照区域的大小进行区域的分组,可以将区域分为三组:f1(占整字识别区域的100%)为第1组,f3、f4、f5和f6(约占整字识别区域的50%)为第2组,f2、f7、f8、f9和区域f10(约占整字识别区域的25%)为第3组。观察多种字体的实验数据表明,分组1的识别率高于分组2的识别正确率,分组2的识别正确率高于分组3的识别正确率。不同字体下,分组内各区域的识别率准确率排名会有所不同,但分组间的准确率排名是一致的。由于常用的字号下,单一区域的识别准确率不足以满足实际应用的需要。所以需要选取多个区域作为比较区域。我们按照特征识别准确率高低依次增加特征数量,逐步提高识别准确率。同时使用n个区域时,待识别汉字与模板库中某一候选字的δη的计算公式为:发明人发现选取的区域在6至8个时识别准确率适合,此时在准确率较高且参与计算的区域较少。以宋体字为例,多个区域组合的识别准确率如表2所示,其中单位为百分比。表2宋体组合区域的识别准确率(单位%)特征p123456p1234569p12345689p12345678910六号49.7862.0962.0962.09小五74.0686.1186.1386.13五号86.2494.2494.2494.24小四96.5998.8398.8398.83四号98.4999.7199.7199.71小三98.9899.7499.7499.74三号99.5899.9899.9899.98小二99.89100.00100.00100.00二号99.9799.9899.9899.98小一99.9899.9899.9899.98一号99.98100.00100.00100.00小初100.00100.00100.00100.00初号100.00100.00100.00100.00进一步进行验证,当选取的区域为f1、f4、f6、f5、f3、f2、f10这7个时,准确率测试汉字在七种字体的五种不同字号的识别准确率如表3所示,其中单位为百分比。表3七种常见字体的识别准确率(单位%)六号小五五号小四四号隶书54.5485.9393.1097.5799.31宋体62.0986.1394.2498.8399.71仿宋69.1882.2392.0897.9599.28楷体72.9287.2796.8799.0699.77黑体80.5894.8896.1699.5199.78幼圆86.6192.8397.5799.2999.88微软雅黑89.8695.9298.4799.8099.95从表3中可以看出当字号为小五号字以后识别准确率逐渐接近100%。在上述方案的基础上,进一步地,所述步骤2具体包括:s201、以图片形式提取待识别图片中的文字;s202、对提取到的文字图片进行区域划分,将文字图片划分为不同的区域;s203、选取与比较区域对应的m个区域;s204、计算选取的m个区域的特征值。在上述方案的基础上,进一步地,所述步骤202中进行区域划分时采用矩形框的形式,除中间部分f2以外,其余区域的所述矩形框的框线至少与图片的最上端、最左端、最下端、最右端其中之一相切。在上述方案的基础上,进一步地,所述步骤3中,输出的汉字为可编辑形式。实施例一下面以“阿”作为例,对文字识别方法的过程进行说明,其中,如图2所示,图片中的“阿”字为宋体、四号字。(1)建立字模库:对字库中的每一个汉字在不同字体、不同字号的情况下进行区域划分。字体包括宋体、仿宋、黑体、楷体、微软雅黑、隶书、幼圆等七种最常用字体。字号包括初号(42pt)、小初(36pt)、一号(26pt)、小一(24pt)、二号(22pt)、小二(18pt)、三号(16pt)、小三(15pt)、四号(14pt)、小四(12pt)、五号(10.5pt)、小五(9pt)、六号(7.5pt)、小六(6.5pt)等常用的十四种字号。区域包括整体f1、中间部分f2、上半部分f3、下半部分f4、左半部分f5、右半部分f6、左上角部分f7、右上角部分f8、左下角部分f9、右下角部分f10这10个区域。对这些区域利用公式(1)进行黑白值转化。利用公式(3)计算各个区域的特征值,并将特征值存储。将不同字体及字号的所有汉字的特征值集合进行存储,构建字模库。在兼顾准确率和计算效率的情况,选取区域f1、f4、f6、f5、f3、f2、f9这7个区域作为比较区域。(2)读取待识别图片,如“阿”,计算其相切区域,根据相切区域,选择尺寸、字体最接近的字模库。计算图片中“阿”字特征:对图片上的“阿”字进行区域划分,包括整体f1、中间部分f2、上半部分f3、下半部分f4、左半部分f5、右半部分f6、左上角部分f7、右上角部分f8、左下角部分f9、右下角部分f10。选取其中的f1、f4、f6、f5、f3、f2、f9这7个区域对这7个区域利用公式(1)进行黑白二值图转换,利用公式(3)获取每个区域的特征值。(3)将计算获得的特征值在字模库进行比对,输出相似度最高的字模汉字。利用公式(5),在字模库中查找与“阿”特征值差异最小的汉字,将汉字以可编辑形式输出。上述实施方式及实施例旨在举例说明本发明可为本领域专业技术人员实现或使用,对上述实施方式进行修改对本领域的专业技术人员来说将是显而易见的,故本发明包括但不限于上述实施方式,任何符合本权利要求书或说明书描述,符合与本文所公开的原理和新颖性、创造性特点的方法、工艺、产品,均落入本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1