安全带实时监测方法和系统与流程
本发明涉及安全带的检测技术领域,具体地涉及一种安全带实时监测方法和系统。
背景技术:
目前现有检测安全带的方法多从图像视觉角度,以深度学习方法进行检测。
目前,现有技术中,使用一种新型的反馈增量式卷积神经网络训练方法以及信息多分支最终评估值获取方法提高了卷积神经网络的检测精度,同时借助随机多尺度选取安全带目标候选区域方法,提高了检测操作的灵活性,但是使用的卷积神经网络较为落后,效率还是较为低下,不适合大量的图片训练和使用,同时对于候选区域的选取有很大的误差,不能精确地选择司机的位置,也无法快速的检测出安全带的配带情况。
现有技术中还使用haar特征区间检测人脸,根据人脸区域确定前排位置,将前排位置分为主驾驶和副驾驶进行安全带的检测。这种方法效率低,效果差,当前排较复杂时,便不能检测出人脸区域,造成错误的检测。
现有技术中主要存在以下问题:
1.检测算法庞大,检测涉及车辆、车窗及包括安全带在内的许多车内环境,相对不够专一;
2.依赖驾驶员。基于对驾驶员进行识别后再对安全带进行检测,可能存在过度的依赖性;
3.光照和色彩。车内环境多种多样,夜间行车也常有,在缺少亮光的情况下检测效果往往不能最好;
4.实时性。不少检测系统位于车外,在特定道路上进行检测,满足不了驾驶员实际各种条件驾驶时报警的需要。
技术实现要素:
为了解决上述技术问题,本发明提出了一种安全带实时监测系统和方法,在检测框的置信值满足条件后由位置坐标和图像整体的关系进行判定,可以快速、准确地识别安全带的佩戴情况。
本发明所采用的技术方案是:
一种安全带实时监测方法,包括以下步骤:
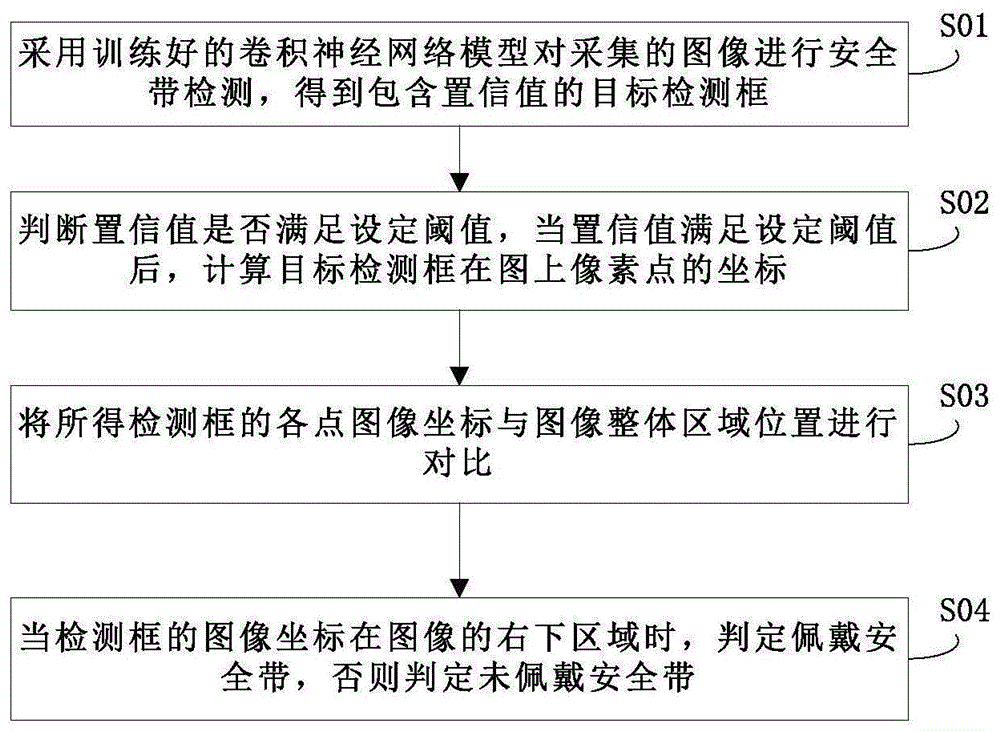
s01:采用训练好的卷积神经网络模型对采集的图像进行安全带检测,得到包含置信值的目标检测框;
s02:判断置信值是否满足设定阈值,当置信值满足设定阈值后,计算目标检测框在图上像素点的坐标;
s03:将所得检测框的各点图像坐标与图像整体区域位置进行对比;
s04:当检测框的图像坐标在图像的右下区域时,判定佩戴安全带,否则判定未佩戴安全带。
优选的技术方案中,所述步骤s03中将图像在像素层面上划分图像整体区域为左上、左下、右上、右下区域。
优选的技术方案中,所述步骤s03中将检测框的右下部分的像素坐标作为检测框在图上像素点的坐标。
优选的技术方案中,所述步骤s04之后还包括,计算检测到目标的次数占检测总次数的比率,当判定未佩戴安全带并且比率低于设定阈值时,进行报警。
本发明还公开了一种安全带实时监测系统,包括:
安全带检测模块,采用训练好的卷积神经网络模型对采集的图像进行安全带检测,得到包含置信值的目标检测框;
检测框坐标计算模块,当判断置信值是否满足设定阈值,当置信值满足设定阈值后,计算目标检测框在图上像素点的坐标;
位置比对模块,将所得检测框的各点图像坐标与图像整体区域位置进行对比;
安全带判定模块,当检测框的图像坐标在图像的右下区域时,判定佩戴安全带,否则判定未佩戴安全带。
优选的技术方案中,所述位置比对模块中将图像在像素层面上划分图像整体区域为左上、左下、右上、右下区域。
优选的技术方案中,所述位置比对模块中将检测框的右下部分的像素坐标作为检测框在图上像素点的坐标。
优选的技术方案中,还包括报警模块,计算检测到目标的次数占检测总次数的比率,当判定未佩戴安全带并且比率低于设定阈值时,进行报警。
与现有技术相比,本发明的有益效果是:
本发明不依赖驾驶员头部识别,依靠多帧累计检测和深度学习模型检测双向保证实时监测,在检测框的置信值满足条件后由位置坐标和图像整体的关系进行判定,可以快速、准确地识别安全带的佩戴情况。
附图说明
下面结合附图及实施例对本发明作进一步描述:
图1为本发明安全带实时监测方法的流程图;
图2为本发明安全带检测的一种示例;
图3为本发明安全带检测的又一种示例;
图4为本发明安全带检测的又一种示例;
图5为本发明安全带检测的又一种示例。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
实施例
如图1所示,一种安全带实时监测方法,包括以下步骤:
s01:采用训练好的卷积神经网络模型对采集的图像进行安全带检测,得到包含置信值的目标检测框;
s02:判断置信值是否满足设定阈值,当置信值满足设定阈值后,计算目标检测框在图上像素点的坐标;
s03:将所得检测框的各点图像坐标与图像整体区域位置进行对比;
s04:当检测框的图像坐标在图像的右下区域时,判定佩戴安全带,否则判定未佩戴安全带。
进行图像识别和目标检测的模型由大量的特殊摄像头捕捉到的合适图片所制成的样本训练而来。在大量含有安全带的样本中依靠检测训练的需求,对黑白图像中的安全带进行标注,区别于未被标注的非安全带部分,以此为卷积神经网络生成用于训练的正负样本的基准。具体的卷积神经网络模型这里并不进行限定,具体的训练方式可以采用现有技术中的训练方式进行训练,这里不再进行赘述。
如图2-5所示,依据深度学习训练出的模型反馈出的包含置信值,反映在图中框上的数值,用以决定该检测目标是否被确认为安全带并进行后续检测,所得检测区域的各点图像坐标与图像整体位置做出对比:具体是根据模型反馈而来的检出目标物体的检测框的在图上像素点的坐标,而得到检测框都为矩形。从检测视野得到的图片从像素层面上将其均分为左上、左下、右上、右下4个涵盖整个图的区域,考虑到驾驶员在驾驶过程的各种实际动作和判断检测到的矩形框因为检测物体特殊而呈现出的多个框并存的情况,本发明选取矩形框的右下部分的像素坐标与整个图的右下区域进行对比,只要检测框右下部分像素坐标处于全图的右下区域,就能决定驾驶员是佩戴安全带的。从而做出是否存在检测目标的最终判定值。
每进行一次单帧的检测,对检测的总次数进行加一。为了实现实时性的同时保证未系安全带的报警正确性,根据检测到目标的次数所占检测总次数的比率的大小保证实时性。通过最终的判断确定是否系上安全带的检测结果,若判定未佩戴安全带并且比率低于设定阈值时,进行报警。在检测完一轮后,无论最终结果如何,对检测次数归零重置,继续下一轮的检测。
图3为阳光照射下的视频采集效果。而图2为夜间无光情况。可以看到采集的图像在有无自然光照下保持一致的检测算法运作。增强了整体系统应用的实际性和普适性。
图4为光照对图像有明显分割差异的示例。只要检测视频中安全带显示在画面中,即可视的。目标或大或小,模型的反馈结果就是客观的。前述以多次检测用比率判断的算法逻辑也保证了监测报警结果最终的正确性。
图5可以看出安全带检测的算法较为单纯,不依赖于先对驾驶员头部进行识别,可以对摄像视野范围内的安全带进行直接的检测。图示中每帧都有多个模型反馈的检测区域,监测算法只要某个区域的置信值和检测框的位置达到设定阈值便可判断该帧的检测结果,继而反馈,支持整个系统的算法。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!