一种基于树形聚类矢量量化的图像检索方法与流程
本发明属于图像检索领域,特别涉及基于树形聚类的矢量量化算法和深度学习的特征提取方法以及两种方法的结合。
背景技术:
随着移动互联网技术的飞速发展,图像、视频、音频、文本等异构数据每天都在以惊人的速度增长。例如,facebook注册用户超过10亿,每月上传超过10亿的图片;flickr图片社交网站2015年用户上传图片数目达7.28亿,平均每天用户上传约200万的图片;中国最大的电子商务系统淘宝网的后端系统上保存着286亿多张图片。针对这些包含丰富视觉信息的海量图片,如何在这些浩瀚的图像库中方便、快速、准确地查询并检索到用户所需的或感兴趣的图像,成为多媒体信息检索领域研究的热点。
从宏观上对ann(approximatenearestneighbor,此ann非彼ann,artificialneuralnetwork)有下面的认知很有必要:brute-force搜索的方式是在全空间进行搜索,为了加快查找的速度,几乎所有的ann方法都是通过对全空间分割,将其分割成很多小的子空间,在搜索的时候,通过某种方式,快速锁定在某一(几)子空间,然后在该(几个)子空间里做遍历。可以看到,正是因为缩减了遍历的空间大小范围,从而使得ann能够处理大规模数据的索引。在大数据时代,如何快速的进行图像搜索呢,现有图像搜索方法大致可以分为三类:基于树的方法、基于哈希方法、基于矢量量化的方法。
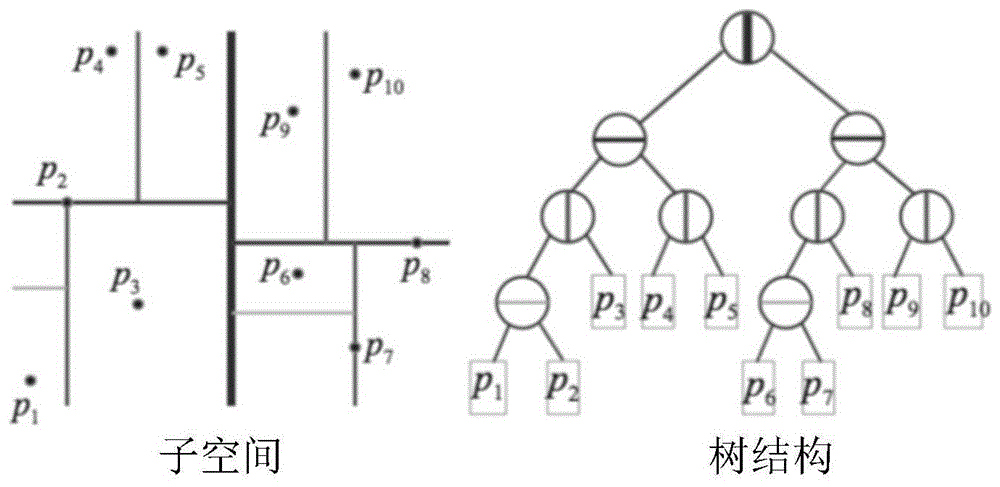
基于树的方法采用树这种数据结构的方法来表达对全空间的划分,其中又以kd树最为经典。图1是kd树对全空间的划分过程,以及用树这种数据结构来表达的一个过程。
一般而言,在空间维度比较低的时候,kd树是比较高效的,当空间维度较高时,可以采用下面的哈希方法或者矢量量化方法。
局部敏感哈希(localsensitivehashing,lsh)。哈希,顾名思义,就是将连续的实值散列化为0、1的离散值。当一个函数(或者更准确的说,哈希函数家族)具有如下属性的时候,我们说该哈希函数是局部敏感的:相近的样本点对比相远的样本点对更容易发生碰撞。lsh划分空间示意图如图2所示。
对于bruteforce搜索,需要遍历数据集中的所有点,而使用哈希则首先找到查询样本落入在哪个cell(即所谓的桶)中,如果空间的划分是在想要的相似性度量下进行分割的,则查询样本的最近邻将极有可能落在查询样本的cell中,如此只需要在当前的cell中遍历比较,而不用在所有的数据集中进行遍历,因此遍历速度非常快,但使用哈希检索也极易发生碰撞,划分粒度不细。
矢量量化方法,即vectorquantization,其具体定义为:将一个向量空间中的点用其中的一个有限子集来进行编码的过程。在矢量量化编码中,关键是码本的建立和码字搜索算法。比如常见的聚类算法,就是一种矢量量化方法。而在ann近似最近邻搜索中,矢量量化方法又以乘积量化(pq,productquantization)最为典型。其主要步骤为:先划分空间,再将子空间分别聚类,计算出查询向量的距离池,最后直接在距离池中查询出子空间向量所对应的距离进行加和再排序。虽然相对于bruteforce搜索速度更快,但还是对所有数据都进行了查找。倒排pq乘积量化(ivfpq)是pq乘积量化的更进一步加速版。采用的是通过聚类的方式实现感兴趣区域的快速定位,具体是在pq乘积量化之前,增加了一个粗量化过程:得到了聚类中心后,针对每一个样本找到其距离最近的类中心后,两者相减得到样本的残差向量,后面剩下的过程,就是针对残差向量的pq乘积量化过程。
使用聚类可以加速查询兴趣区域,但查询空间依然很大,而且不在同一个兴趣区域的无法查找。
技术实现要素:
本发明旨在解决图像检索查找速度和准确度的问题。提出了一种降低了检索时间复杂度并提高准确率和召回率的结合树形聚类矢量量化算法以及基于深度学习的特征抽取方法。
为实现上述目的本发明采用的技术方案是:
一种基于树形聚类矢量量化的图像检索方法,包括训练过程和检索过程,
所述训练过程包括以下步骤:
s11、先将输入的原始图片进行预处理,图像大小缩放到224*224,使用resnet-50cnn模型对图片提取2048维图像特征,保存所有图片的图像特征;
s12、使用k-means++聚类算法对图像特征进行聚类得到聚类模型,聚类数为k,保存该聚类模型到树模型的当前根节点中;
s13、对这k个类中的数据进行递归聚类,聚类数依然为k,以此来将所有数据全部划分到叶子结点上;
s14、当子类中的数量小于n,或者树的深度达到h停止聚类;
s15、保存树模型,对已有图片计算在叶子结点的位置,经过的路径即为该图片指纹,保存所有图片指纹;
所述检索过程包括以下步骤:
s21、对输入的查询图像进行预处理,图像大小缩放到224*224,使用resnet-50cnn模型对图像提取2048维图像特征;
s22、对s21中得到的图像特征进行递归类别预测,从根节点开始,每个聚类模型递归预测该图像特征的类别;
s23、当s22中的图像已经落到叶子节点中时,输出该叶子节点的路径作为图像的指纹;
s24、查找和该指纹相同的所有图像i;
s25、计算该查询图像与图像i中图像矢量的余弦距离,对距离进行排序即可得到相似图像。
步骤s12中所述k-means++聚类算法,按照如下聚类规则选取k个聚类中心:
a)从输入的数据点集合中随机选择一个点作为第一个聚类中心μ1;
b)对于数据集中的每一个点xi,计算它与已选择的聚类中心中最近聚类中心的距离d(x),该距离的计算公式为:
μr为聚类中心、r为选取的聚类中心的个数、kselected选择的聚类中心
c)选择一个新的数据点作为新的聚类中心,选择的原则是d(x)较大的点,被选取作为聚类中心的概率较大;
d)重复b和c直到选择出k个聚类质心。
所述递归聚类建树的过程为:在第一次聚类的时候聚5个类,并对这5个类继续递归的聚类下去,直到叶子节点的样本数少于设定阈值或者分裂的节点不足n个或者树的深度达到h为止。
进一步,s15所述图片指纹生成过程为:对所有样本从根节点开始进行聚类的类别预测,得到预测类别的子树,再进行递归预测直到样本落到叶子节点上,样本所经过的子树编号作为生成的指纹,子树编号即为聚类的类别编号。
步骤s25所述的检索过程中的余弦距离公式为:
其中a、b为图像特征向量。ai、bi为不同的特征向量,n表示向量的个数。
本发明的优点及有益效果如下:
本发明将树形聚类的矢量量化算法和基于深度学习的特征提取方法相结合,利用深度学习对于图像内容和语义的精确与抽象表达能力,将非结构化的图像数据转化为结构化的矢量,然后利用树形聚类的空间划分能力进行快速检索,提升了图像检索的速度和准确率,同时,通过向上以及平行查找来提升召回。
本发明基于树形聚类的矢量量化检索方法可以向上和平行查找,并且可以在多次聚类的同时生成指纹,并缩小查询空间。并且是递归的方式聚类,时间复杂度由o(k*m*n)降到o(log(k)*m*n),其中k是聚类中心数,m、n是数据的行列数。
附图说明
图1为背景技术中kd树对全空间的划分过程;
图2为背景技术中lsh划分空间示意图;
图3为本方法的流程图;
图4为树模型的数据结构;
图5为节点的数据结构;
图6为聚类模型的数据结构;
图7为resnet-50cnn模型中中最主要的结构“抄近道连接”;
图8为整个resnet-50cnn模型的结构图;
图9为指纹编码的示意图;
图10为本发明检索到的子图;
图11为本发明检索到的不同比例的缩放图;
图12为本发明检索到的不同姿势的图像。
具体实施方式
参见图3,一种基于树形聚类矢量量化的图像检索方法,包括训练和检索两个过程,其中训练过程包括以下步骤:
s11、先将图片进行预处理,图像大小缩放到224*224,使用resnet-50cnn模型对图片提取2048维图像向量特征,保存所有图片的向量特征;
s12、使用k-means++聚类算法对图片进行聚类,聚类数为5,保存该聚类模型到该树模型的当前根节点中;
s13、对这5个类中的数据递归的聚类,聚类数依然为5,以此来将所有数据全部划分到叶子结点上;
s14、当子类中的数量小于n,或者数的深度达到h停止聚类;
s15、保存树模型,对已有图片计算在叶子结点的位置,经过的路径即为该图片指纹,保存所有图片指纹。
检索过程包括以下步骤:
s21、对检索的图像进行预处理,图像大小缩放到224*224,使用resnet-50cnn模型对图像提取2048维图像特征;
s22、对s21中得到的矢量进行预测,从根节点开始,每个聚类模型递归预测该矢量的类别;
s23、当s22中的图像已经落到叶子节点中时,输出该叶子节点的路径作为图像的指纹;
s24、查找和该指纹相同的所有图像i;
s25、计算该图像与i中图像矢量的余弦距离,对距离进行排序即可得到相似图像。
树模型和聚类模型,其数据结构如下:
1)树模型的数据结构为:一定数量的节点树模型的数据结构如图4所示,该数据结构中节点分裂的下级节点至多为5个。
2)每个节点的数据结构为:包含5个子节点和聚类模型,如图5所示。
3)聚类模型的数据结构为:包含5个矢量,如6图所示。
resnet-50cnn模型主要解决的问题是:随着网络结构深度加深,梯度消失模型无法训练的现象。其中最主要的结构为“抄近道连接”,如图7所示。
整个结构为一个“基础构造块”,用公式表示为:
y=f(x,{wi})+x
其中y代表输出,x代表输入,wi代表模型权重。
整个resnet-50cnn模型的结构图如图8所示。图中每一个“resiblock”(i=1,2,3,4,5)都由“基础构造块”组成,经过第一种组合模块后,图像大小由224*224变为112*112,通道数从3变为64,经过第二种组合模块后,大小变为56*56,通道数变为256,在经过第五种组合模块后,大小变为7*7,通道数为2048,再对提取出的图像特征进行平均池化,继续接一个全连接层提取出最终的图像特征。
所述的k-means++聚类算法,按照如下聚类规则选取k个聚类中心:
a)从输入的数据点集合中随机选择一个点作为第一个聚类中心μ1;
b)对于数据集中的每一个点xi,计算它与已选择的聚类中心中最近聚类中心的距离d(x),该距离的计算公式为:
c)选择一个新的数据点作为新的聚类中心,选择的原则是d(x)较大的点,被选取作为聚类中心的概率较大;
d)重复b和c直到选择出k个聚类质心。
所述的递归聚类建树的过程为:在第一次聚类的时候聚5个类,并对这5个类继续递归的聚类下去,直到叶子节点的样本数少于设定阈值或者分裂的节点不足n个或者树的深度达到h为止。
对所有样本从根节点开始进行聚类的类别预测,得到预测类别的子树,再进行递归预测直到样本落到叶子节点上,样本所经过的子树编号作为生成的指纹。子树编号即为聚类的类别编号。编码示意图如图9所示,其中红色第三排第二个叶子节点的指纹编码为:01。
所述的检索过程中的余弦距离公式为:
其中a、b为图像特征向量。
采用本发明方法获得的检索结果如图10到图12所示。
- 还没有人留言评论。精彩留言会获得点赞!