基于卷积神经网络和传统编码相结合的图像压缩方法与流程
本发明属于数字图像处理技术领域,具体涉及一种图像压缩方法。
背景技术:
随着计算机技术和网络通信技术不断地发展,实时视频通信、视频监控等领域越来越受到广泛关注。步入信息化时代后,互联网中的流动数据日益增加,对于当前的硬件技术所能提供的网络带宽以及存储资源来说是非常大的负担。图像数据作为互联网最重要的资源,对其进行有效的压缩无疑是很有意义的。图像压缩技术(imagecompression)是用尽可能少的数据来表示原始图像,同时允许恢复后的重构图像的质量有一定程度的失真,极大地减缓了图像数据存储、传输等过程的压力。
传统的图像编码标准比如jpeg(jointphotographicexpertsgroup),以及能达到更高的压缩比的jpeg2000等都能通过去除图像中的冗余数据来减少用来表示图像的数据量,从而在获取更高的压缩比的同时保持很好的图像质量。
近年来利用深度学习进行图像压缩的研究层出不穷,比如toderici团队[1,2]利用循环神经网络(recurrentneuralnetwork,rnn)对图像进行渐进压缩,从而得到不同的压缩比;结合卷积神经网络(convolutionalneuralnetwork,cnn)来做图像压缩的有很多,如balle等人[3]使用一种加性噪声来代替量化过程中的不可导过程,wangmeng等人人[4]基于权重来对图像的不同位置使用不同的压缩比,mentzer等人[4]使用先验概率来对网络进行训练。这些人提出的方案都取得了很好的效果,而且每一种网络框架都是在神经网络的堆叠下构成的,整个过程都可以进行训练。
同样,也有利用神经网络和传统技术相结合的压缩方法,比如feng等人[5]提出了使用传统技术压缩经cnn处理后的低分辨率图像。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供一种基于卷积神经网络和传统编码相结合的图像压缩方法,以减少在存储、传输图像数据时所需要消耗的资源。
本发明提供的基于卷积神经网络和传统编码相结合的图像压缩方法,具体步骤为:
(1)利用卷积神经网络减少图像的高频信息分量;
(2)使用传统压缩技术对图像进行压缩,得到编码数据,再对其解码得到重构图像;
(3)利用卷积神经网络对解码后的图像进行增强,提升重构效果。
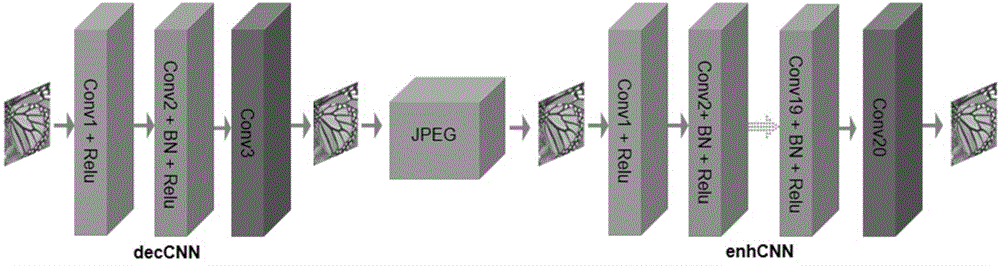
进一步的,步骤(1)中,所述利用卷积神经网络减少图像的高频信息分量,是将图像输入卷积网络deccnn,提取特征,减少图像中的高频信息分量,得到与输入图像相同分辨率的图像。其中,deccnn网络主要包括3个卷积层:conv1,conv2,conv3。
进一步的,步骤(2)中,在经过前处理之后,图像中的高频信息更少,然后使用传统的压缩技术(比如jpeg)将处理后的图像进行压缩。由于传统压缩方法主要是压缩图像中的高频信息,对色彩的信息保留较好,因此处理包含较少高频分量的图像时,其压缩过程中的图像损失会更少。图像经过压缩后得到的编码表示可用于传输以及存储。最后,利用jpeg等技术将得到的编码表示进行解码,得到与输入图像相同分辨率的的重构图像。
进一步的,步骤(3)中,卷积神经网络enhcnn用于将重构图像进行增强,消除重构图像中的block效应等损失。enhcnn由20个卷积模块所构成,第一个卷积块包括一个卷积层conv和一个激活函数层relu,中间的18个卷积模块都是由一个卷积层conv、一个bn层以及一个relu层组成,最后再经过一个卷积层得到最终的输出图像。
由于整个压缩过程包含两个卷积神经网络以及一个传统编码过程,因此要对两段网络分别采取不同的损失函数。enhcnn网络所采用的损失函数是计算网络的输出与解码后的图和输入图像做的差之间的l2损失,这样使得网络的输出近似为解码后图像与输入原图之间的残差,网络最后得到的结果和解码后图像相加就能减小与输入原图之间的误差,从而达到更好的恢复效果;deccnn网络所采用的损失函数是计算网络最终输出与输入原图之间的l2损失和解码后的图与输入原图之间的l2损失相加的和。
进一步的,网络模型的训练方法如下:
采用交替训练,首先固定deccnn网络的参数不变,更新enhcnn网络的参数来最小化enhcnn网络的损失函数;然后固定enhcnn网络的参数,训练deccnn网络,更新其参数用来最小化deccnn网络的损失函数。这样不断交替训练,直到两个网络的损失函数达到平衡。
进一步的,由于在传统编码的过程中有一步很重要的量化操作,用来产生离散的编码值,所以将传统方法结合在卷积网络中会由于其离散型导致网络训练受阻,因此将这个方法中的离散化过程设为输入与输出之间的梯度值不改变,这样使得网络能够正常的训练。
本发明的有益效果在于:本发明设计了一个端到端的图像压缩方法,在传统编码压缩图像前,首先使用cnn对图像进行前处理,减少图像的高频信息分量,降低传统编码压缩的图像失真,最后再利用cnn对解码后的图进行修复,使得最终重构图像更接近输入原图。实验结果表明,在实现相同的视觉效果时,本发明能得到更高的压缩比,将同一张图像压缩得更小。这样在实现更高的压缩比时还能得到更好的图像重构质量,大大降低了图像数据在存储、传输等过程中所需要占据的资源。
附图说明
图1为本发明的网络框架图。
图2为本发明的流程图。
图3为测试图像kodim23.png的压缩r-d曲线图。
图4为测试图像lena.jpg的压缩效果对比图。
具体实施方式
下面通过实施例对本发明进行进一步说明,但是本发明的保护范围不局限于所述实施例。
采用图1中的网络结构,用400张大小为481×321的图像训练神经网络。
具体实施方法是:
(1)训练时,采用[7]所使用的方法,随机裁剪图像到180×180,再把裁剪后的图裁成64张大小为40×40的小图,裁剪时采用步长为20。设初始学习率为0.01,经过80个epoch之后衰减到0.0001。用adam随机梯度下降的方法,最小化损失函数。批的大小设为64;
首先进行交替训练:固定deccnn网络的参数,最小化enhcnn网络的损失函数,让网络学习图像增强任务,再固定enhcnn网络的参数,最小化deccnn网络的损失函数,让网络学习减少高频信息的任务。经过一个epoch之后再次交替训练;
(2)测试时,将图像i调整大小到768×512,输入到训练好的模型中,模型输出当前图像压缩成更小的编码表示以及解码后的最终重构图像。计算重构图像与输入原始图像之间的psnr(peaksignal-to-noiseratio)值作为网络的损失参数,编码表示的bpp(bitperpixel)作为衡量压缩后的比特率。在测试不同的压缩质量因子后,绘制成r-d(rate-distortion)曲线。
图3为测试图像kodim23.png的r-d曲线,可以看到经过本发明中的网络测试的结果要比直接用传统编码进行压缩的效果要好。在相同压缩比下本发明能实现更好的重构质量,在相同图像重构质量下能获得更高的压缩比。
图4为本发明测试图像lena.png在相同的比特率0.156bpp下的压缩效果对比。图4(a)是原始图像,图(b)是直接使用jpeg压缩后的重构图,图(c)是采用本发明中的网络结构所得到的重构图。可以看到图(b)有很多地方存在块效应失真,而图(c)并没有这样的失真。
参考文献
[1]g.toderici,s.m.o’malley,s.j.hwang,d.vincent,d.min[1]nen,s.baluja,m.covell,andr.sukthankar.variablerateimagecompressionwithrecurrentneuralnetworks.internationalconferenceonlearningrepresentations,(2016).
[2]g.toderici,d.vincent,n.johnston,s.j.hwang,d.min[1]nen,j.shor,andm.covell.fullresolutionimagecom[1]pressionwithrecurrentneuralnetworks.ieeeconferenceoncomputervisionandpatternrecognition,(2017).
[3]j.balle,v.laparra,ande.p.simoncelli.end-to-endoptimizedimagecompression.internationalconferenceonlearningrepresentations,(2017).
[4]m.li,w.zuo,s.gu,d.zhao,andd.zhang.learningconvolutionalnetworksforcontent-weightedimagecompression.ieeeconferenceoncomputervisionandpatternrecognition,(2018).
[5]fmentzer,eagustsson,mtschannen,etal.conditionalprobabilitymodelsfordeepimagecompression.ieeeconferenceoncomputervisionandpatternrecognition,(2018).
[6]wtao,fjiang,sliu,etal.anend-to-endcompressionframeworkbasedonconvolutionalneuralnetworks.datacompressionconference,(2017).
[7]y.chenandt.pock,“trainablenonlinearreactiondiffusion:aflexibleframeworkforfastandeffectiveimagerestoration,”arxiv:1508.02848,(2015).。
- 还没有人留言评论。精彩留言会获得点赞!