一种基于图像组协同描述生成的新闻自动配图方法与流程
本发明属于深度学习和计算机视觉技术领域,涉及一种基于图像组协同描述生成的新闻自动配图方法。
背景技术:
图像描述(imagecaptioning)作为图像自动化处理的基础,受到越来越多的关注,被广泛应用于自动配图、图像搜索等方向。
图像描述生成技术的发展经历了早期的典型关联成分分析、传统机器学习方法及当前热门的深度学习方法的变迁。基于深度学习方法,常用cnn+lstm的组合框架,百度团队于2014年提出的基于多模态循环神经网络是使用cnn+rnn结构进行图片描述的开山之作。其后,谷歌的nic模型利用端到端的思想直接产生图像描述,进一步推动了图像描述的发展。然而,图像描述生成方法仍存在许多待改进空间:
(1)缺乏中文训练数据集。现有的图片描述数据集如mscoco、flickr等都为英文标注,图像描述生成的中文训练数据集仍空白。
(2)传统新闻自动配图对文本特征和图片特征独立处理,未考虑深度学习方法对图片特征和文本特征的处理方式不同,缺乏足够的说服力。
(3)现有图像描述生成方法多对图片单独处理,缺乏实体间的相关性及多样性的考量,生成的图片描述过于单一且不够精准。
技术实现要素:
针对现有技术的不足,本发明提供一种基于图像组协同描述生成的新闻自动配图方法。
本发明采用如下技术方案实现:
一种基于图像组协同描述生成的新闻自动配图方法,包括:
s1.制作用于图像描述生成的新闻类中文数据集;
s2.使用新闻类中文数据集,构建及训练图像组协同描述生成模型;
s3.基于训练好的图像组描述生成模型,进行新闻自动配图。
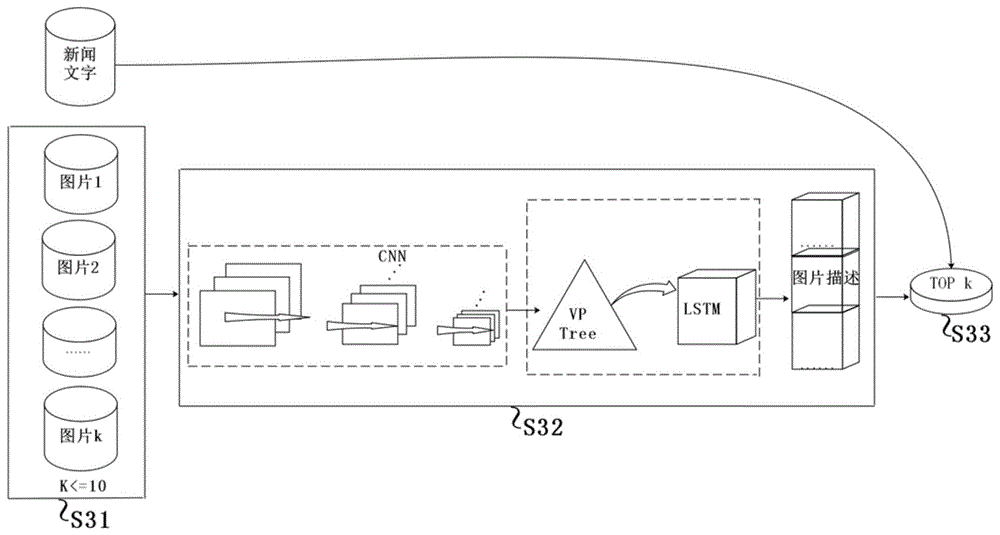
进一步地,s3包括:
s31.输入新闻及备选图片组;
s32.由图像组协同描述生成模型对备选图片生成描述;
s33.计算备选图片的图像描述文本特征向量与新闻文本特征向量之间的距离,输出top-k作为新闻最终的配图。
优选地,新闻类中文数据集每条新闻对应3-10张图片。每张图片标注有三句描述语句,包括:1)新闻标题;2)图片地点或核心人物或人物动作等表现图片内容的描述;3)场景简要说明。
优选地,s2包括:采用cnn进行图像视觉特征的提取及实体的挖掘,构建vptree表示图像组内实体相关性和多样性,lstm结合vptree对图像进行描述生成。
进一步地,vptree的构建过程包括:
①定义:
②基于以上的定义,对于cnn提取的特征g有:
其中:fsem为自定义语义映射函数,将视觉特征映射到图像的实体/关系上,
优选地,lstm生成图像描述过程中损失函数表示为:
其中:i表示目标图像,j表示目标图像内的第j个节点,|s|表示提取的全局特征个数,t表示输出序列的长度,k表示vptree的节点个数,
进一步地,在进行图像描述生成的过程中,l(θt,θc,θl)表示总体loss函数,
优选地,采用cnn进行图像视觉特征的提取及实体的挖掘时,使用3*3的卷积核进行卷积操作,同时卷积步长设置为1,下采样使用最大池化,最大池化的窗口是2*2,步长是2,并在下采样之后采用全连接层处理。
优选地,使用tf-idf规则计算图像描述文本及新闻文本特征向量之间的距离。
本发明相对于现有技术具有如下的优点及效果:
(1)对图像组内的候选图片基于组内图像协同描述生成,自动新闻配图时,对这些图像协同描述生成的文字描述和新闻文本进行特征匹配,以更具体、更丰富的图像描述提高新闻配图的准确率,解决了目前新闻配图方法独立提取图片特征和文字特征以后做匹配,而深度学习对图片特征和文字特征处理存在差异导致的匹配效果不佳的问题。
(2)在生成图像描述时考虑组内的图像,由于组内是一些相关的图像,它们之间存在实体的多样性和相关性关系,以组的方式可使图像描述有弥补和细化的效果。
(3)在lstm生成图像描述中通过vptree将图像组内实体间的多样性及相关性考量在内,使得图像的描述结果更加具体、丰富。
(4)制作的图像描述中文数据集,弥补了训练数据的局限性。
附图说明
图1是本发明一个实施例中基于图像组协同描述生成的新闻自动配图方法流程图;
图2是本发明一个实施例中图像描述新闻类中文训练数据集示例;
图3是本发明一个实施例中实体相关性示例;
图4是本发明一个实施例中实体多样性示例;
图5是本发明一个实施例中的新闻自动配图测试输入示意图;
图6是本发明一个实施例中cnn特征提取及实体挖掘示意图;
图7是本发明一个实施例中构建的vptree及描述输出结果。
具体实施方式
为使本发明的目的、技术方案及实际效果更为清晰,下面将结合附图,对本发明实施例中的技术方案进行完整的流程描述。需要指出的是,本实施例只是本发明的一部分实施例,不包括整个所有适用场景下的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图像描述(imagecaptioning)作为图像自动化处理的基础,受到越来越多的关注,被广泛应用于自动配图、图像搜索等方向。现有图像描述生成方法中文训练数据集缺失,同时由于图像描述生成中对图片进行单独处理,所以生成的图像描述比较单一和模糊,故本发明提供一种基于图像组协同描述生成的新闻自动配图方法。
一种基于图像组协同描述生成的新闻自动配图方法,包括:
s1.制作用于图像描述生成的新闻类中文数据集;
新闻类中文数据集每条新闻对应3-10张图片,每张图片标注有三句描述语句,包括:1)新闻标题;2)图片中地点或核心人物或人物动作等表现图片内容的描述;3)场景简要说明。
本实施例中,新闻类中文数据集每条新闻对应3张图片,该数据集目前主要包括娱乐、金融、体育、社会、生活等类别。新闻类中文训练数据集的一个样例如图2所示,该新闻标题为“小女孩举办5岁生日聚会”,包含3张图片,除标题外,每张图片还有两句描述语句作为图像描述。图2中(a)的图像描述为:“小女孩举办5岁生日聚会”、“男人手棒鲜花蛋糕让小女孩许愿”、“小女孩和大家一起庆祝自己的生日”;(b)的图像描述为:“小女孩举办5岁生日聚会”、“小女孩对着鲜花蛋糕许愿”、“小女孩生日场景”;(c)的图像描述为:“小女孩举办5岁生日聚会”、“两个男人牵着小女孩站在写着5的生日蛋糕前照相”、“小女孩在生日会上和大家合影留念”。
s2.使用s1制作的数据集,构建及训练图像组协同描述生成模型;
图像组协同描述生成模型综合考量图像组内实体相关性及实体多样性,权衡组内图像间的关系,使得图像描述生成结果更加具体和丰富。基于cnn提取的特征构建vptree表示图像组内实体相关度和多样性,并将其纳入lstm中以生成更为精细的图像描述,以优化当前的新闻配图方法。
①实体相关性
设有两幅差不多主题下的图片,如图3所示,格子填充颜色越深表示二者相关性越强,则两幅图中黑格子内的实体(a、c、g)相同,实体相关性大是由于同一组图片内,共同实体或动作一起出现的概率很大,这些实体之间不独立,相互关联,产生延伸,则第一列中有些实体如“蛋糕”虽没检测到,但可以通过实体相关性,从而知道与“生日”场景相关的对象也包括“蛋糕”。
②实体多样性
实体多样性如图4所示,设格子填充颜色越深表示实体多样性强,则在第一列中a使用“小女孩”、g中使用“生日”,而在第二列中a却采用“女人”、g使用“聚会”,上述实体或关系实则是一个组内同一个概念实体,却使用了不同的语义进行表征。实体多样性可以达到组内图像相互间纠正,从而使得图像的描述更加细化。
本实施例中,图像组协同描述生成模型中lstm生成最终图像描述时对实体相关性及实体多样性的考量通过vptree实现。vptree是一种可基于cnn提取特征,构建出图像组内语义实体多样性及相关性的一种结构,具体地,vptree的构建过程如下所示:
①定义:
②基于以上的定义,对于cnn提取的特征g有:
其中:fsem为自定义语义映射函数,将视觉特征映射到图像的实体/关系上,
lstm结合vptree对输入图像进行描述语句的输出,lstm生成图像描述过程中损失函数表示为:
其中:i表示目标图像,j表示目标图像内的第j个节点,|s|表示提取的全局特征个数,t表示输出序列的长度,k表示vptree的节点个数,
在进行图像描述生成的过程中,l(θt,θc,θl)表示总体loss函数,
在图像组协同描述生成模型训练的过程中,通过输入新闻、新闻配图及其对应图片描述,训练图像组协同描述生成模型充分学习如何提取图片特征及进行图片描述,将参数调整到最优。
s3.基于s2训练好的图像组描述生成模型,进行新闻自动配图。
如图1所示,在新闻自动化配图过程中,针对输入新闻及备选图片,基于图像组协同描述生成模型,使用cnn获取实体特征后由图像组内实体间的多样性及相关性构建vptree并输入到lstm中生成对应的图像描述,将图像描述文本特征与新闻特征对比,选出最为契合的top-k作为新闻配图。包括:
s31.输入新闻及备选图片组;
s32.由图像组协同描述生成模型对备选图片生成描述;
图像组协同描述生成模型在生成图像描述过程中,使用cnn模型提取实体特征,并基于vptree构建图像组内的实体多样性及相关性,并在lstm生成描述的过程中,考量图像组内实体间的相关性及多样性。
本实施例中,以图5为例子,输入新闻标题为“家有萌狗”,备选图片为4张,以备选图片(a)的描述生成为例。首先采用cnn进行图像视觉特征的提取及实体的挖掘,如图6所示,输入图像大小为224*224,使用3*3的卷积核进行卷积操作,同时卷积步长设置为1,下采样使用最大池化,最大池化的窗口是2*2,步长是2,并在下采样之后采用全连接层处理并输出最终实体结果,对备选图片(a)最终输出实体属于“狗”、“小狗”、“椅子”、“领带”等实体的概率分布。
然后,构建图像对应的vptree,对应的vptree及输出如图7所示,lstm从vptree中最底层获得最大概率实体为“小狗”、“椅子”及“领带”,从中间层锁定连接词“和”,并在最后一层获得动词“戴”,经过lstm的调整,最终输出的描述语句为“一只白的和灰的小狗戴着领带坐在椅子前”。如果仅仅使用单张图片生成描述模型,生成的描述可能为“一只灰白的狗坐在椅子上”。对比标准输出“戴着领带的灰白相间的狗坐在地毯上”,基于组内协同描述,对狗的细节描述更为具体。对剩余的其它备选图片,基于同样的处理流程输出图像描述。
s33.计算备选图片的图像描述文本特征向量与新闻文本特征向量之间的距离,输出top-k作为新闻最终的配图。
新闻备选图片组内每张图片的图像描述生成之后,使用tf-idf规则计算图像描述文本及新闻文本特征向量之间的距离,输出top-k,并将这些图选作最终的新闻配图。本实施例中,设k=2,最终新闻配图为备选图片(a)和备选图片(b),因为这两张图片的描述更符合新闻标题“家”及“狗”的范畴,至此完成基于图像组协同描述生成的新闻自动配图。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!