一种基于小波变换和联合概率分布的水文预报方法与流程
本发明涉及水文预报技术领域,更具体地,涉及一种基于小波变换和联合概率分布的水文预报方法。
背景技术:
水文预报是水文科学研究中极为重要和棘手的问题之一。提高水文预报的准确性和可靠性,可实现为防汛和水资源管理决策提供更加准确可靠的依据。而探索无资料或资料匮乏区域水文模拟的新方法,提高其预报精度,更是为当前水文预报的研究核心之一。
随着水利、气象、遥感、计算机等专业的发展,水文预报也经历了快速的发展,预报精度也不断的提高。传统的数据驱动模型方法包括多元线性回归模型、成因分析方法、时间序列分析方法等。其中,时间序列分析方法是基于随机理论,将水文时间序列看成为随机成分和确定性成分等项组成,通过对各项模拟并叠加得到水文预报的结果,目前比较常用方法有自回归模型(Autoregressive,AR)、马尔可夫链等。后来,进一步发展为自回归滑动平均(ARMA)模型、分数阶差分自动回归滑动平均模型等各类不同形式的自回归模型。随着技术的进步特别是计算机技术的不断发展,不少国内外学者也不断发展和提出了新的水文预报理论和预报模型,如模糊分析法、ARMA(Auto-Regressive and Moving Average)模型、灰色系统模型、神经网络模型(Artificial Neural Network,ANN)、支持向量机模型(Support Vector Regression,SVR)等。但是上述这些模型在对无资料或资料匮乏区域水文模拟预报时,预报精度仍然需要提高。
技术实现要素:
本发明为实现上述目的,提供一种基于小波变换和联合概率分布的水文预报方法。本发明与常规的预报模型对比,能够实现更优的水文预报。
为解决上述技术问题,本发明采用的技术方案是:一种基于小波变换和联合概率分布的水文预报方法,其中,包括如下步骤:
S1.对于某水文变量的时间序列Qt,提取1个时间lag(如1小时、1日、1月、1年等)、2个时间lag、3个时间lag或更长的n个时间lag的时间序列Qt-1、Qt-2、Qt-3或Qt-n,作为初始的预测变量,而原始的水文变量时间序列Qt作为被预测变量的时间序列;
S2.利用小波变换的分解功能,把预测变量Qt-1、Qt-2、Qt-3或Qt-n各自分解为高频和低频多个不同时间尺度的子序列sub series,这些子序列sub series将作为以下基于Vine copula的预报方法的输入因子;
S3.基于Vine copula联合高维分布函数,构建所有的输入因子以及被预测变量Qt之间的联合概率分布函数;
S4.基于构建的联合概率分布函数,进一步求解被预测变量和预测变量之间的条件分布函数模型,利用该模型实现对被预测变量的预报,并对预报效果进行评估。
进一步的,所述步骤S1中,所述水文变量分为不同种类的水文气象变量和不同时间尺度的水文气象变量,所述不同种类的水文气象变量包括降水、径流、水位及土壤湿度,所述不同时间尺度的水文气象变量的时间尺度包括小时、日、月、年。
进一步的,所述步骤S2中,小波变换的目的是获得在不同时间尺度上发生的局部和瞬态现象的完整时间尺度表示。使用小波函数将信号分解为不同分辨率级别的各种分量,小波函数也称为母小波。与仅提供信号频率信息的经典傅里叶变换相比,小波变换的主要优点是能够同时获得信号的时间,位置和频率信息。通常,小波变换可以使用两种方法来执行:连续小波变换(CWT)和离散小波变换(DWT)。CWT的构造更复杂,需要大量的计算时间;相比之下,DWT需要更少的计算时间,并且比CWT更容易实现;此外,CWT不以时间序列的形式生成信息,而是以二维格式生成信息,这可能产生大量冗余信息。DWT简化了转换过程,减少了工作量,但它仍然可以产生非常有效和准确的分析。因此,所述小波变换采用离散小波变换,所述离散小波变换的函数为:
ψ是小波函数,t是时间,γ是小波在时间序列上的平移因子,s是比例因子;j决定分解次数,为整数;k决定平移步长,为整数;s0是固定步长,大于1;γ0是位置参数,大于零。
参数最常见和最简单的选择是s0=2和γ0=1。由于大多数水文时间序列是以具有离散特点,因此采用DWT来分解本水文气象事件序列。在DWT中,原始时间序列通过高通和低通滤波器并生成不同时间尺度子序列。
进一步的,对于4维随机变量X=[x1,...,x4]T,其对应的概率分布函数(即边缘分布)为F1,…,F4,其4维联合概率分布函数F可以表示为:
F(x1,...,x4)=C(F1(x1),...,F4(x4))=C(u1,...,u4) (2)
式中,C为copula函数,即联合概率分布函数F;简化将Fi(xi)表示为ui(i=1,…,4);如果边缘分布均为连续函数,存在唯一的copula函数满足:
式中,fi(xi)为边缘密度函数,而c为copula密度函数。常规的参数化copula函数主要针对二维联合概率分布,如Gaussian、student t、Clayton、Gumbel和Frank。Vine copula主要针对更高维的联合概率分布问题。该函数的核心思想是将高维的联合概率密度函数进行分解为原变量和其他条件变量的多个二维copula函数来处理,通过“藤”结构将每个二维copula进行连接。所述步骤S3中,Vine copula联合高维分布函数采用C-vine模型,4维C-vine模型有3个tree结构,设j=1,2,3,则treeTj,有4-j+1个节点和4-j条边,而每条边表示一个二维copula密度函数,treeTj中的边构成treeTj+1的节点。
对于随机变量X=[x1,...,x4]T,其对应的C-vine密度函数为:
式中,fk(xk)为边缘密度函数;ci,i+j|1:(i-1)(F(xi|x1,...,xi-1),F(xi+j|x1,...,xi-1))为二维条件密度函数;
具体的Vine copula密度函数的构建步骤如下:
S31.将多维的联合概率密度函数破解开,由多个二维条件密度函数及边缘密度函数的乘积构成;
S32.构建第一层tree结构,确立中心节点,计算各边两两二维copula的参数;
S33.利用条件概率方程将原始数据转为tree 2所需的数据,并计算tree 2中各边对应的copula参数;利用条件概率方程将原始数据转为tree 3所需的数据,并计算tree 3中各边对应的copula参数;
S34.利用公式(4),累乘计算多维联合概率密度函数;一个四维的C-vine copula可以表示为:
f1234=f1·f2·f3·f4·c12·c13·c14·c23|1·c24|1·c34|21 (5)
其由边缘密度、二维联合密度以及条件密度函数累积构成。
S35.将步骤S34得到的多维联合概率密度函数进行积分,即得到多维联合概率分布函数。
进一步的,所述步骤S4中,通过递归地使用条件h方程,4维C-vine中变量x4的条件概率分布可以表示为:
F(u4|u1,u2,u3)=h{h[h(u3|u1)|h(u2|u1)]|h[h(u4|u1)|h(u2|u1)]} (6)
其中h为条件概率方程,如用h方程表示二维条件分布函数的形式为:
再通过计算式(6)条件概率分布的反函数:
Qx4=F-1(u4)=F-1(h-1{h-1[h-1(τ|h(h(u3|u1)|h(u2|u1)))|h(u2|u1)]u1}) (8)
则可以求解得到被预测变量x4。
假设x4为径流,而其他变量(x1–x3)为预测输入因子(如基于小波分解获得的被预测因子的子序列等气象因子)(与径流保持一定步长差),则通过式(8)可以实现对径流的预测。
进一步的,所述步骤S4中,选取一定的统计指标对模型预报效果进行评估,所述统计指标包括Coefficient of determination(R2)、Root-mean-squared error(RMSE)和Nash–Sutcliffe model efficiency coefficient(NSE);并将该模型与常规广泛使用的数据驱动模型做对比,分析其优劣性,所述常规广泛使用的数据驱动模型包括ANN、SVR、ANFIS。
与现有技术相比,本发明的有益效果:
本发明提供的水文预报方法结合了小波变换和联合概率分布二者的优点,使得其与常规的预报模型对比,能够实现更优的水文预报。
附图说明
图1是本发明水文预报方法的流程图。
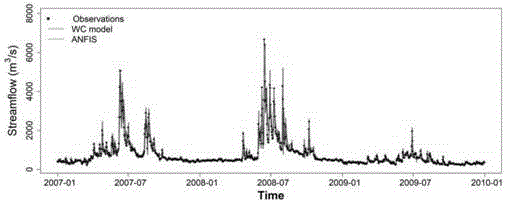
图2(a)是本发明WV模型和ANFIS模型预报的每日流量和实测值的博罗站径流时间序列对比图(2007-2009年)。
图2(b)是本发明WV模型和ANFIS模型预报的每日流量和实测值的博罗站径流时间序列对比图(2010-2011年)。
图3是WV模型和ANFIS模型预报的每日流量(lag=1)和实测值的博罗站径流的FDC对比图。
图4(a)是针对低流量的WV模型和ANFIS模型预报的每日流量(lag=1)和实测值的博罗站径流的FDC对比图。
图4(b)是针对中流量的WV模型和ANFIS模型预报的每日流量(lag=1)和实测值的博罗站径流的FDC对比图。
图4(c)是针对高流量的WV模型和ANFIS模型预报的每日流量(lag=1)和实测值的博罗站径流的FDC对比图。
图5是WV模型和ANFIS模型预报的每日流量(lag=2)和实测值的博罗站径流的FDC对比图。
图6是WV模型和ANFIS模型预报的每日流量(lag=3)和实测值的博罗站径流的FDC对比图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本专利的限制。
如图1所示,一种基于小波变换和联合概率分布的水文预报方法,其中,包括如下步骤:
S1.对于某水文变量的时间序列Qt,提取1个时间lag(如1小时、1日、1月、1年等)、2个时间lag、3个时间lag或更长的n个时间lag的时间序列Qt-1、Qt-2、Qt-3或Qt-n,作为初始的预测变量,而原始的水文变量时间序列Qt作为被预测变量的时间序列。所述水文变量分为不同种类的水文气象变量和不同时间尺度的水文气象变量,所述不同种类的水文气象变量包括降水、径流、水位及土壤湿度,所述不同时间尺度的水文气象变量的时间尺度包括小时、日、月、年。
S2.利用小波变换的分解功能,把预测变量Qt-1、Qt-2、Qt-3或Qt-n各自分解为高频和低频多个不同时间尺度的子序列sub series,这些子序列sub series将作为以下基于Vine copula的预报方法的输入因子。
本实施例中,所述步骤S2中,小波变换的目的是获得在不同时间尺度上发生的局部和瞬态现象的完整时间尺度表示。使用小波函数将信号分解为不同分辨率级别的各种分量,小波函数也称为母小波。与仅提供信号频率信息的经典傅里叶变换相比,小波变换的主要优点是能够同时获得信号的时间,位置和频率信息。通常,小波变换可以使用两种方法来执行:连续小波变换(CWT)和离散小波变换(DWT)。CWT的构造更复杂,需要大量的计算时间;相比之下,DWT需要更少的计算时间,并且比CWT更容易实现;此外,CWT不以时间序列的形式生成信息,而是以二维格式生成信息,这可能产生大量冗余信息。DWT简化了转换过程,减少了工作量,但它仍然可以产生非常有效和准确的分析。因此,所述小波变换采用离散小波变换,所述离散小波变换的函数为:
ψ是小波函数,t是时间,γ是小波在时间序列上的平移因子,s是比例因子;j决定分解次数,为整数;k决定平移步长,为整数;s0是固定步长,大于1;γ0是位置参数,大于零。
参数最常见和最简单的选择是s0=2和γ0=1。由于大多数水文时间序列是以具有离散特点,因此采用DWT来分解本水文气象事件序列。在DWT中,原始时间序列通过高通和低通滤波器并生成不同时间尺度子序列。
S3.基于Vine copula联合高维分布函数,构建所有的输入因子以及被预测变量Qt之间的联合概率分布函数。
对于4维随机变量X=[x1,...,x4]T,其对应的概率分布函数(即边缘分布)为F1,…,F4,其4维联合概率分布函数F可以表示为:
F(x1,...,x4)=C(F1(x1),...,F4(x4))=C(u1,...,u4) (2)
式中,C为copula函数,即联合概率分布函数F;简化将Fi(xi)表示为ui(i=1,…,4);如果边缘分布均为连续函数,存在唯一的copula函数满足:
式中,fi(xi)为边缘密度函数,而c为copula密度函数。常规的参数化copula函数主要针对二维联合概率分布,如Gaussian、student t、Clayton、Gumbel和Frank。Vine copula主要针对更高维的联合概率分布问题。该函数的核心思想是将高维的联合概率密度函数进行分解为原变量和其他条件变量的多个二维copula函数来处理,通过“藤”结构将每个二维copula进行连接。所述步骤S3中,Vine copula联合高维分布函数采用C-vine模型,4维C-vine模型有3个tree结构,设j=1,2,3,则treeTj,有4-j+1个节点和4-j条边,而每条边表示一个二维copula密度函数,treeTj中的边构成treeTj+1的节点。
对于随机变量X=[x1,...,x4]T,其对应的C-vine密度函数为:
式中,fk(xk)为边缘密度函数;ci,i+j|1:(i-1)(F(xi|x1,...,xi-1),F(xi+j|x1,...,xi-1))为二维条件密度函数;
具体的Vine copula密度函数的构建步骤如下:
S31.将多维的联合概率密度函数破解开,由多个二维条件密度函数及边缘密度函数的乘积构成;
S32.构建第一层tree结构,确立中心节点,计算各边两两二维copula的参数;
S33.利用条件概率方程将原始数据转为tree 2所需的数据,并计算tree 2中各边对应的copula参数;利用条件概率方程将原始数据转为tree 3所需的数据,并计算tree 3中各边对应的copula参数;
S34.利用公式(4),累乘计算多维联合概率密度函数;一个四维的C-vine copula可以表示为:
f1234=f1·f2·f3·f4·c12·c13·c14·c23|1·c24|1·c34|21 (5)
其由边缘密度、二维联合密度以及条件密度函数累积构成。
S35.将步骤S34得到的多维联合概率密度函数进行积分,即得到多维联合概率分布函数。
S4.基于构建的联合概率分布函数,进一步求解被预测变量和预测变量之间的条件分布函数模型,利用该模型实现对被预测变量的预报,并对预报效果进行评估。
本实施例中,所述步骤S4中,通过递归地使用条件h方程,4维C-vine中变量x4的条件概率分布可以表示为:
F(u4|u1,u2,u3)=h{h[h(u3|u1)|h(u2|u1)]|h[h(u4|u1)|h(u2|u1)]} (6)
其中h为条件概率方程,如用h方程表示二维条件分布函数的形式为:
再通过计算式(6)条件概率分布的反函数:
Qx4=F-1(u4)=F-1(h-1{h-1[h-1(τ|h(h(u3|u1)|h(u2|u1)))|h(u2|u1)]u1}) (8)
则可以求解得到被预测变量x4。
假设x4为径流,而其他变量(x1–x3)为预测输入因子(如基于小波分解获得的被预测因子的子序列等气象因子)(与径流保持一定步长差),则通过式(8)可以实现对径流的预测。
本实施例中,所述步骤S4中,选取一定的统计指标对模型预报效果进行评估,所述统计指标包括Coefficient of determination(R2)、Root-mean-squared error(RMSE)和Nash–Sutcliffe model efficiency coefficient(NSE);并将该模型与常规广泛使用的数据驱动模型做对比,分析其优劣性,所述常规广泛使用的数据驱动模型包括ANN、SVR、ANFIS。
为了测试本实施例的水文预报方法的预测能力,选择东江流域的博罗站进行水文预报测试:东江位于我国华南地区,流域面积27040平方公里。该流域也是珠江流域的重要子流域。东江流域处于季风主导的气候。年平均温度约为20-22°C,年平均降水量在1500毫米至2400毫米之间。采用的博罗站日径流数据时间跨度为1989年到2011年。
水文预报包括如下步骤:
S1.基于博罗站的日径流时间序列Qt,提取前1天、前2天、前3天或前n天的时间序列Qt-1、Qt-2、Qt-3或Qt-n,作为初始的预测变量,而原始的日径流时间序列Qt作为被预测变量。
S2.利用DWT的分解功能,把预测变量Qt-1、Qt-2、Qt-3、或Qt-n各自分解为高频和低频多个不同时间尺度的子序列sub series,这些子序列将作为以下基于Vine copula的预报方法的输入因子。
S3.利用Vine copula模型,构建所有的输入因子以及被预测变量Qt之间的联合概率分布函数。
S4.利用本发明的条件分布函数建立条件预测模型(WV模型),实现对径流的预测。
在本实例中,博罗水文站1989年至2006年的18年期间的数据用于模型校准或开发,其余数据(2007-2011)随后保留用于验证或评估预测性能。
本实施例中,预报方法预测效果分析如下:
(1)一个时间延迟尺度(Lag1)的预测表现
首先,对比本发明的WV模型与传统的ANFIS机器学习的模型在提前1天的径流预报方面的表现。如图2(a)和图2(b)所示,由时间序列图比较可以看出,两种方法的预报效果都比较好,两种模型模拟值和实测径流量都表现较好的一致性。为了更进一步对比WV模型和传统的ANFIS模型的预测差异,进一步采用流量历时曲线(FDC)比较了每个模型的预测技能,如图3所示。FDC是特定时间段(例如,每天或每月)的流量频率分布的直观表示方法。总体而言,WV模型预测的FDC与实测值径流的FDC比ANFIS模型具有更好地一致,尤其是在低径流量的部分。我们进一步比较了博罗站高(流量>1190m3/s)、中(310<流量<1190m3/s)、低(流量<310m3/s)三个阶段的径流量这两种方法的预测表现。如图4(a)、图4(b)和图4(c)所示,WV模型总体上提供了预测效果优于ANFIS模型。
为了更进一步对比两种模型预测表现,采用上述的R2、RMSE和NSE这三个指标来衡量预测效果。表1中给出了两个模型的性能统计数据。很明显,所提出的WV模型在某种程度上优于ANFIS模型,也就是说具有更低的RMSE值,而更高的NSE和R2值。
表1.ANFIS和WV模型预测表现比较
(2)更长时间延迟(Lags)的预测表现
进一步探讨了建议的WV模型对流量预测的预测能力,其具有较长的提前期,即预测2-3天延迟预报(即,用当天预测2-3天后的径流)。根据FDC,如图5和图6所示,本发明提出的WV模型的预测值总体上与实测径流相比于ANFIS模型具有更好的一致性。为了更进一步定量对比两种模型的预测效果。表1列出了WV模型和ANFIS模型预测博罗站更长时间延迟尺度的预测表现。可见,WV模型更长时间延迟尺度的的预测表现也是优于ANFIS模型的。
显然,本发明的上述实施例仅仅是为了清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!