一种基于可视化图形的模型构建方法及系统与流程
本发明涉及数据处理技术领域,尤其涉及一种基于可视化图形的模型构建方法及系统。
背景技术:
当今社会计算机技术快速发展,各种数据资源涵盖领域广泛,涉及的数据种类繁杂,针对仅根据源数据难以对领域技术的状态进行全面、系统的评估或数据预测的情况,需要利用数据挖掘技术构建相应的模型以加强对数据资源的分析,通过化繁为简,形成比较完善的数据分析方法。例如医学研究领域,历史的数据资源丰富,但是面对原始的医疗数据却无法获取可靠的借鉴依据,不利于对各类病患的优化治疗,这种情况下就需要基于原始的历史医疗数据进行数据挖掘,构建科学合理的模型。
然而,在实际的数据挖掘技术中,要想对批量数据进行高效运算或者实现数据的预测就需要根据批量数据构建模型,现有的数据挖掘建模方式或工具多为基于已知的自变量、因变量和模型类型进行学习和训练,实现对应模型的构建,尤其是具有多个自变量的模型,现有的技术手段无法直接根据未知变量角色的源数据实现模型的构建,且现有技术若要确保构建的模型有效,须执行者对建模数据和模型特征等知识具有相当程度的了解,实用性有很大的局限。
技术实现要素:
为解决上述问题,本发明提供了一种基于可视化图形的模型构建方法及系统,在一个实施例中,所述方法包括以下步骤:
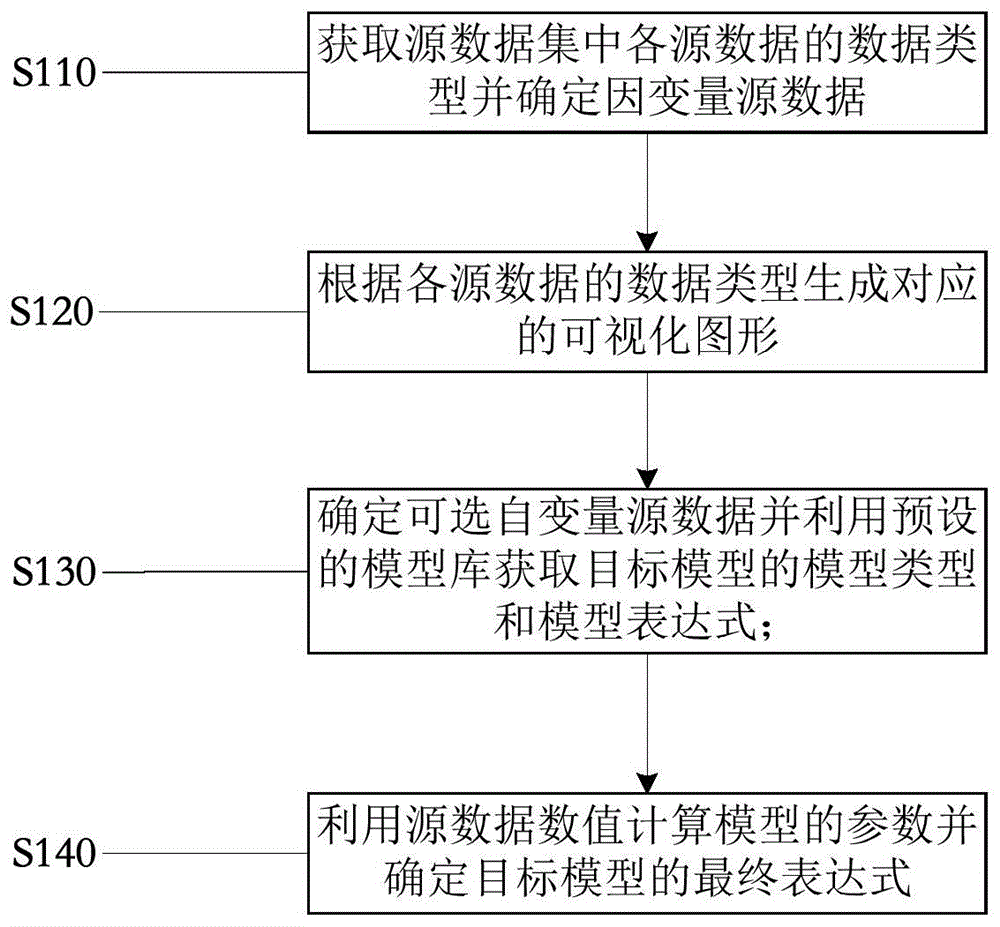
步骤s1、获取需构建模型的源数据集,确定各源数据的数据类型并选取作为因变量的因变量源数据。
步骤s2、根据各源数据的数据类型生成与源数据集对应的可视化图形。
步骤s3、通过所述可视化图形确定至少一个作为可选自变量的可选自变量源数据,并根据所述可选自变量源数据对应的数据类型利用预设的模型库获取目标模型的模型类型和模型表达式。
步骤s4、利用所述因变量源数据和可选自变量源数据对应的数据值计算模型的参数并确定目标模型的最终表达式。
优选地,在所述步骤s2中,按照以下规则根据各源数据数据类型生成对应的可视化图形:
将各个源数据表征为所述可视化图形的散点。
其中,将数值型的因变量源数据表征为所述可视化图形中各散点的纵轴坐标。
将数值型或分类型的可选自变量源数据表征为可视化图形中散点的横轴坐标、散点的颜色类别、散点的尺寸等级、散点的随附文字或者散点的形状种类。
其中,在所述步骤s3中,利用源数据对应的所述可视化视图中各散点的分布情况确定与因变量源数据数值变化相关的可选自变量源数据作为可选自变量;
将所述可选自变量的数据类型输入所述预设的模型库中获取至少一个目标模型的模型类型和模型表达式。
在所述步骤s4中,按照如下步骤计算各目标模型的参数:
根据目标模型的模型类型建立源数据集对应的自变量数据回归设计矩阵。
利用所述自变量数据回归设计矩阵和目标模型的类型计算模型参数向量的估计值。
根据模型参数向量的估计值返回获得目标模型的估计参数值,将所述估计参数值代入目标模型的表达式中确定目标模型的最终表达式。
进一步地,在根据目标模型的模型类型建立源数据集对应的自变量数据回归设计矩阵的步骤中:
若目标模型的类型为多项式回归,则建立源数据集对应的自变量数据回归设计矩阵xi如下:
xi=[1x1x2x3...xn]
否则,建立源数据集对应的自变量源数据回归设计矩阵xj如下;
其中,xab代表第a条记录的第b个自变量的数据值,n为自变量源数据集中记录的条数,p为各条记录具有的自变量的数量。
具体地,在利用所述自变量数据回归设计矩阵和目标模型的类型计算模型参数向量的估计值的步骤中:
若目标模型的模型类型为多项式回归,则按下式计算模型参数向量的估计值
若目标模型的模型类型为指数回归,则按下式计算模型参数向量的估计值
若目标模型的模型类型为对数回归,则按下式计算模型参数向量的估计值
其中,若目标模型的模型类型为对数回归,则要求回归设计矩阵xj中的各元素均大于0,即xab>0;
若目标模型的模型类型为线性回归,则按下式计算模型参数向量的估计值
式中,x'为回归设计矩阵x的转置矩阵,x-1为回归设计矩阵x的逆矩阵,向量y=(y1,y2,...,yn)',表示所有记录的因变量源数据。
另一个实施例中,在所述步骤s4之后还包括:
选取部分源数据作为样本数据,将样本数据中的自变量数据代入各目标模型的最终表达式中计算各目标模型对应的因变量估计值。
根据计算得到的因变量估计值和样本因变量实际值计算各个目标模型的拟合优度和均方误差。
利用计算得到的所述拟合优度和均方误差对所述目标模型进行评估。
其中,在利用所述拟合优度和均方误差评估最适用的目标模型的步骤中,具体包括:
将各目标模型根据其对应的所述拟合优度按照从大到小的顺序排列;
若存在拟合优度相等或拟合优度差值小于预设模糊额度的目标模型,将均方误差值较小的目标模型列于前排;
选取排序位于第一或前n的目标模型作为最终优选的目标模型。
在一个实施例中,本发明还提供一种基于可视化图形的模型构建系统,该系统中各结构独立运行或结合运行执行如上述各实施例中所述的步骤。
与最接近的现有技术相比,本发明具有如下有益效果:
本发明提供的基于可视化图形的模型构建方法采用将明确数据类型的源数据表征为可视化视图,结合可视化视图的信息确定即将进入模型的可选自变量数据,解决了现有技术中对用户专业知识要求高的缺陷;本发明根据自变量数据的数据类型利用预设的模型库向用户推荐对应的适用模型,从很大程度上保证了模型构建结果的可靠性,同时降低了用户的操作复杂度,大大降低了因模型不适用导致建模操作失效的概率,进而根据设计的计算方法确定已知参数的目标模型表达式,适用于构建多种类型和维度的模型,有效提升了建模方案的实用性。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例共同用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明实施例一的基于可视化图形的模型构建方法的流程示意图;
图2是本发明实施例一的基于可视化图形的模型构建方法中的可视化视图;
图3是本发明实施例二的基于可视化图形的模型构建方法的流程示意图;
图4是本发明实施例三的基于可视化图形的模型构建系统的结构示意图。
具体实施方式
以下将结合附图及实施例来详细说明本发明的实施方式,借此本发明的实施人员可以充分理解本发明如何应用技术手段来解决技术问题,并达成技术效果的实现过程并依据上述实现过程具体实施本发明。需要说明的是,只要不构成冲突,本发明中的各个实施例以及各实施例的各个特征可以相互结合,所形成的技术方案均在本发明的保护范围之内。
现有的数据挖掘建模方式多为基于已知的自变量、因变量和模型类型进行学习和训练,实现对应模型的构建,尤其是具有多个自变量的模型,现有的技术手段无法直接根据源数据实现模型的构建,而实际工作中,往往需要多个输入变量,例如同时利用孩子父亲和母亲的身高来预测其未来的身高可靠性更高,这种情况下现有工具(如excel)的图形建模功能并不能发挥作用,且现有技术若要确保构建的模型有效须执行者对建模数据和模型特征等知识具有相当程度的了解,实用性不足。
为解决上述问题,本发明提供一种基于可视化图形的模型构建方法,下面参考附图对本发明各个实施例进行说明。
实施例一
图1示出了本发明实施例一的基于可视化图形的模型构建方法的流程示意图,参照图1可知,该方法包括:
步骤s110、获取需构建模型的源数据集,确定各源数据的数据类型并选取作为因变量的因变量源数据。
在该步骤中,先获取可能进入模型的变量,获取即将构建模型的全部数据作为源数据集,对源数据集中的数据进行初步分析,明确各源数据的基础特征,主要包括源数据的数据类型和数据名称,例如,表征患者钾元素含量的源数据名称为钾含量,其数据类型为数值型,表征患者性别的源数据名称是性别,其数据类型为分类型。上述操作中,用户可以根据自己的需求选择或调整作为因变量的源数据。
步骤s120、根据各源数据的数据类型生成与源数据集对应的可视化图形。
在这个步骤中,在配置生成可视化图形时,以散点的形式代表源数据中的各条数据记录(如一个患者的当前体征数据),旨在将源数据集中的各条数据记录即其中包含的数据用可视化视图中的点及其可视化特征展现出来,即将各个源数据表征为可视化图形的散点。
在该实施例中按照以下规则根据各源数据的名称和数据类型生成对应的可视化图形:
其中,按照以下规则根据各源数据数据类型生成对应的可视化图形:
将各个源数据表征为所述可视化图形的散点;
具体为,将数值型的因变量源数据表征为所述可视化图形中各散点的纵轴坐标,将数值型或分类型的可选自变量源数据表征为可视化图形中散点的横轴坐标、散点的颜色类别、散点的尺寸等级、散点的随附文字或者散点的形状种类。
例如,图2示出了本发明实施例二的基于可视化图形的模型构建方法的可视化视图,如图2所示,将每个患者的数据展示在图形中,每个点代表一个患者的数据,假设现在有n条患者数据记录,即图形中有n个点,该实施例中,将类型为数值型的自选因变量钾元素含量数据作为可视化视图中散点的纵轴坐标,将类型为数值型的钠元素含量数据作为可视化视图中散点的横轴坐标,将类型为数值型的年龄数据表征为可视化图形中散点的颜色类别,如将患者的年龄分为3个阶段,每个年龄阶段对应一个颜色等级,也可以根据需求和喜好设定若干颜色类别,将类型为数值型的血压数据作为可视化视图中散点的尺寸等级,可以将血压数据进行分段,各个血压数据段对应散点的一个大小等级,根据上述方法将四维的关系体现在一张平面图形中展示给用户。
在本发明的实施例中主要以数值型和分类型数据为例展开说明,关于其他适用的数据类型以类似的技术手段实现配置视图或建模的技术方案也属于本发明的保护范围。
步骤s130、通过可视化图形确定至少一个作为可选自变量的可选自变量源数据名称,并根据可选自变量源数据名称对应的数据类型利用预设的模型库获取目标模型的模型类型和模型表达式,该步骤中用到的预设的模型库中预存有各类型的可选模型及对应的模型表达式和适用条件。
根据源数据对应的可视化视图中各散点的分布情况确定与因变量源数据数值变化相关的可选自变量源数据作为可选自变量;
普通用户在上一步骤通过观察视图可以获得视图中各个源数据的分布情况,以及图形中各个自变量与因变量之间的关系,来初步判定哪些自变量进入模型运算。例如观察到年龄大的患者血液中钾的水平比较高,即上图中上方集中深色的点,下方集中浅色的点,则考虑年龄是潜在影响钾水平的因素。
同样的,观察其他源数据相对于这个因变量的分布情况,将与因变量数据分布趋势相关度大的源数据作为自变量;然后根据因变量和自变量的类型和数量来确定即将提供给用户选择的模型类型。
本实施例中采用以下方案:将可选自变量的数据类型输入预设的模型库中获取至少一个适用的目标模型的模型类型和模型表达式。该实施例中提供的模型为用于趋势预测与常用回归分析的模型,包括指数回归模型,线性回归模型,对数回归模型和多项式回归模型,针对可视化视图中自变量和因变量的类型、自变量和因变量的个数,有效地提供适用的模型供用户选择。可选适用模型及适用条件根据如下表格来判断:
表1模型库适用模型及适用条件表格
在本实施例的方案中,用户可以根据在可视化视图中观察到的规律的形态,选择想要使用的模型,同时也可以对用于建模的自变量进行调整,例如增加或者减少自变量。除多项式回归只能选择一个自变量以外,其他模型都可以选择一个或者多个自变量进入模型运算。
根据用户的选择,从模型库中调用该模型和模型对应的默认表达式,但需要计算表达式中参数的值,在这里我们利用可视化视图中所使用的源数据数值进行计算,即利用因变量源数据名称和可选自变量源数据名称对应的数据值计算模型的参数并确定目标模型的最终表达式。
具体分别按照以下步骤计算各目标模型的参数:
步骤a,根据目标模型的模型类型建立源数据集对应的自变量数据回归设计矩阵;
在该步骤中,若目标模型的类型为多项式回归,由于只有一个自变量,则建立源数据集对应的自变量数据回归设计矩阵xi如下:
xi=[1x1x2x3...xn]
否则,建立源数据集对应的自变量源数据回归设计矩阵xj如下;
其中,xab代表第a条记录的第b个自变量的数据值,n为自变量源数据集中记录的条数,p为各条记录具有的自变量的数量。
步骤b,利用自变量数据回归设计矩阵和目标模型的类型计算模型参数向量的估计值;具体的,假设向量y=(y1,y2,...,yn)'是观察到的n个数据点,即n个患者的钾的水平,向量β=(β0,β1,...,βp)'是模型中未知的参数,若目标模型的模型类型为多项式回归,则按下式(1)计算模型参数向量的估计值
若目标模型的模型类型为指数回归,则按下式(2)计算模型参数向量的估计值
若目标模型的模型类型为对数回归,则按下式(3)计算模型参数向量的估计值
其中,若目标模型的模型类型为对数回归,则要求回归设计矩阵xj中的各元素均大于0,即xab>0;
若目标模型的模型类型为线性回归,则按下式(4)计算模型参数向量的估计值
式中,x'为回归设计矩阵x的转置矩阵,x-1为回归设计矩阵x的逆矩阵,即xi'为回归设计矩阵xi的转置矩阵,xi-1为回归设计矩阵xi的逆矩阵,xj'为回归设计矩阵xj的转置矩阵,xj-1为回归设计矩阵xj的逆矩阵,向量y=(y1,y2,...,yn)',表示所有记录的因变量源数据。
运算成功后返回对于模型参数的估计(β0,β1,β2,…等参数),即根据参数值和表1中的模型表达式得到自变量和因变量之间关系的估计。步骤如下:
步骤c,根据模型参数向量的估计值返回获得目标模型的估计参数值,将估计参数值代入目标模型的表达式中确定目标模型的最终表达式。
采用该实施例的技术手段根据源数据的数据类型构建可视化图形,通过观察可视化图形选取可选自变量数据,进而利用预设的模型库根据用户选择的因变量数据和自变量数据的数据类型提供适用的若干目标模型,并计算获得目标模型最终的目标模型表达式。这样设计,有数据挖掘需求的普通用户就可以基于原始的源数据构建可靠性有保障的目标模型,在建模的过程中,先基于自选因变量数据的数据类型和用户多选的自变量数据配置生成可视化视图,能够清楚直观地体现各自变量与因变量之间的关系,为用户选择可靠的自变量提供了保障,且本发明的技术手段是由预设的模型库根据因变量和自变量数据的数据类型直接向用户提供适用性较高的可选模型,用户只需要根据需求选择即可,即使是缺乏数据挖掘专业知识的用户也能够构建适用的目标模型,很大程度上提升了本发明技术方案的实用性。
实施例二
图3示出了本发明实施例二的基于可视化图形的模型构建方法的流程示意图,下面参照图3对基于可视化图形的模型构建方法的流程进行说明。根据图3中透露的信息可知,本发明实施例二的技术方案中在步骤s140之后还可以包括以下步骤,鉴于其他步骤与上述实施例的执行方法类似,此处不再进行赘述,仅对区别进行说明。
本发明实施例在步骤s140之后,还可以包括:
步骤s310,计算目标模型的拟合优度和均方误差并根据拟合优度和均方误差对目标模型进行评估。该步骤通过计算目标模型的拟合优度和均方误差,进而结合当前目标模型的拟合优度和均方误差计算结果对各目标模型进行评估,确定效果最佳的模型。其中,拟合优度用于表征估计出来的模型对于实际观测到数据的解释程度,该指标为0到1之间,且越接近1表示模型拟合的越好,例如r2=0.69。均方误差,是由模型预测得到的因变量预测值与实际观测到的因变量取值之间差异程度的一种度量,也是模型准确度的一种度量,用于评价模型的模拟效果,其取值大于0,且越小表示模型越精准。将估计的模型的数据解释程度与模型的效果评估进行对比,供用户进行模型的选择。具体步骤如下:
步骤s3101,选取部分源数据作为样本数据,将样本数据中的自变量数据代入各目标模型的最终表达式中计算各目标模型对应的因变量估计值。
步骤s3102,根据计算得到的因变量估计值和样本因变量实际值计算各个目标模型的拟合优度和均方误差。
步骤s3103,根据拟合优度和均方误差评估最适用的目标模型。
在步骤s3103中,具体包括以下操作:
将各目标模型根据其对应的所述拟合优度按照从大到小的顺序排列;
若存在拟合优度相等或拟合优度差值小于预设模糊额度的目标模型,将均方误差值较小的目标模型列于前排;
选取排序位于第一或前n的目标模型作为最终优选的目标模型。
其中,n取正整数,其取值根据实际应用设定。
采用该实施例的技术手段,在获得了若干有效目标模型的表达式后,基于样本数据结合目标模型的拟合优度和均方误差计算结果对获得的目标模型进行评估,确定目标模型的适用性,有助于用户获得效果最佳、预测结果精确度最高的模型结果。
实施例三
基于上述实施例中的技术手段,本发明还提供一种基于可视化图形的模型构建系统,该系统用于执行上述实施例一和实施例二中所述的步骤。图4示出了本发明实施例三的基于可视化图形的模型构建系统40的结构示意图,下面结合图4对该模型构建系统的结构进行说明。如图4所示,该系统包括:
数据处理模块402,其用于获取需构建模型的源数据集,确定各源数据的名称、数据类型并选择作为因变量的因变量源数据名称。
可视化图形生成模块404,其用于根据各源数据的数据类型生成与源数据集对应的可视化图形。
目标模型选取模块406,其用于通过可视化图形确定至少一个作为可选自变量的可选自变量源数据名称,并根据可选自变量源数据名称对应的数据类型利用预设的模型库获取目标模型的模型类型和模型表达式。
模型参数计算模块408,其用于利用因变量源数据名称和可选自变量源数据名称对应的数据值计算模型的参数并确定目标模型的最终表达式。
模型评估模块410,其用于选取部分源数据作为样本数据,将样本数据中的自变量数据代入各目标模型的最终表达式中计算各目标模型对应的因变量估计值;
根据计算得到的因变量估计值和样本因变量实际值计算各个目标模型的拟合优度和均方误差;根据拟合优度和均方误差对目标模型进行评估。
本发明实施例提供的基于可视化图形的模型构建系统能够实现基于原始数据快速构建满足用户需求的模型,构建模型的过程中,用户可以选择和调整因变量数据,且能够依据直观的可视化视图选择和调整自变量数据,进而由模型库提供适用的可选模型,避免了用户因缺少数据挖掘领域专业知识导致构建的模型不可用的问题,保证了本发明模型构建系统的实用性。
应该理解的是,本发明所公开的实施例不限于这里所公开的特定结构、处理步骤或材料,而应当延伸到相关领域的普通技术人员所理解的这些特征的等同替代。还应当理解的是,在此使用的术语仅用于描述特定实施例的目的,而不意味着限制。
说明书中提到的“一实施例”意指结合实施例描述的特定特征、结构或特征包括在本发明的至少一个实施例中。因此,说明书通篇各个地方出现的短语“一实施例”并不一定均指同一个实施例。
虽然本发明所揭露的实施方式如上,但所述的内容只是为了便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属技术领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式上及细节上作任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!