基于矩阵分解与网络嵌入联合模型的社会化推荐方法与流程
本发明涉及计算机应用技术领域,尤其涉及一种基于矩阵分解与网络嵌入联合模型的社会化推荐方法。
背景技术:
互联网时代,如何有效调节多元化信息呈现出的丰富性与人们注意力的局限性之间的矛盾,已然成为当下信息产业亟需解决的技术难题。在此背景下,推荐系统应运而生,以应对大数据所引起的信息过载问题。
协同过滤(collaboritivefiltering)是推荐系统背后的核心技术,其通过分析“用户-物品”交互历史,预测未观测的“用户-物品”相关性。矩阵分解(matrixfactorization)模型是目前最为主流的协同过滤手段,矩阵分解的核心思想是:通过分解“用户-物品”交互矩阵(简称ui矩阵),将用户和物品映射到同一个低维向量空间,进而可通过计算用户特征向量与物品特征向量内积的方式预测“用户-物品”相关性。但该方法的效果严重受限于数据稀疏问题,通常情况下已观测“用户-物品”交互记录仅占ui矩阵的1%左右。为此,一些学者建议在矩阵分解模型中引入用户社交关系,以期缓解ui矩阵的数据稀疏问题。
现有社会化推荐技术大致分为两类:共享表示学习和修正表示学习。共享表示学习的代表性工作如sorec模型,该方法同时分解“用户-物品”交互矩阵和“用户-用户”社交矩阵,其间共用同一组用户特征变量,以期用户特征变量可同时保有用户的个性化喜好及其社会属性;修正表示学习的代表性工作如soreg模型,该模型将用户社交关系作为约束信息,以修正“用户-物品”矩阵分解过程,以期那些社交连接强度大的用户可获得相似的特征向量。
目前,基于(深度)神经网络的网络嵌入技术发展迅猛,被广泛用于各类社交网络分析任务。网络嵌入首先借助随机游走获取每个结点的高阶近邻关系,然后借助神经网络强大的特征转换和抽象能力,将复杂的社交拓扑结构嵌入到低维向量空间中。近年来,一些工作尝试将网络嵌入模型与矩阵分解模型相结合,获得了比传统社会化推荐方法更佳的效果。例如,cune模型首先对用户社交网络进行节点嵌入,然后利用嵌入结果修正“用户-物品”矩阵分解过程。
上述现有技术中的社会化推荐方法的缺点为:经典社会化推荐系统(如sorec模型和soreg模型)多以启发式方法使用社交信息,难以深度挖掘社交网络的复杂拓扑结构。近年来,尽管一些社会化推荐系统尝试在社会化推荐系统中使用网络嵌入模型(如cune模型),以期更好地挖掘和利用社交信息。但是由于技术原理不同,矩阵分解模型与网络嵌入模型很难整合,故而目前业界多采用两阶段学习方式:首先利用网络嵌入模型从“用户-用户”社交网络中学习用户的社会化向量表示;据此作为修正信息,再利用矩阵分解模型从“用户-物品”交互矩阵中学习用户特征和物品特征。这种两阶段方式存在两方面的弊端:
1)常规的网络嵌入模型采用无监督学习方式,其目的是通用的,而非为推荐任务订制的;而社交网络是复杂多面的,若没有监督信号加以引导,网络嵌入模型难以挖掘出那些有助于推荐系统的社交属性。
2)由于分离式的两阶段设计,网络嵌入模型与矩阵分解模型的目标函数不统一,这样第一阶段产生的最优结果,对第二阶段推荐任务而言未必最优;此外,网络嵌入模型含有大量参数,使得两个模型联合调参具有很大难度。
技术实现要素:
本发明的实施例提供了一种基于矩阵分解与网络嵌入联合模型的社会化推荐方法,以克服现有技术的问题。
为了实现上述目的,本发明采取了如下技术方案。
一种基于矩阵分解与网络嵌入联合模型的社会化推荐方法,包括:
构建用户-物品评分矩阵,所述评分矩阵中的行和列分别表示用户和物品,所述评分矩阵中的元素值表示用户对物品的评分;
构建用户-用户社交网络,所述社交网络中的结点表示用户,连接表示用户之间的某种社交关系,根据所述用户-用户社交网络生成社交语料;
利用所述用户-物品评分矩阵和用户社交语料训练矩阵分解与网络嵌入联合模型,得到用户特征矩阵和物品特征矩阵;
根据所述用户特征矩阵和所述物品特征矩阵预测出未观测评分;将评分数值较高的若干物品推荐给相应用户。
优选的,所述用户-物品评分矩阵中的行和列分别表示用户和物品,所述评分矩阵中的元素值表示用户对物品的评分,包括:
利用已有的数据集构建用户-物品评分矩阵,所述评分矩阵中的行和列分别表示用户和物品,所述评分矩阵中的元素值表示用户对物品的评分,并对评分数据进行归一化处理,获得评分矩阵
优选的,所述的构建用户-用户社交网络,所述社交网络中的结点表示用户,连接表示用户之间的某种社交关系,根据所述用户-用户社交网络生成社交语料,包括:
利用已有的数据集构建用户-用户社交网络,该社交网络中的连接用于记录用户间的社交关系;若两用户之间存在某种社交联系,则相应连接被标记为1;若没有社交联系,则标记为0;通过对所述用户-用户社交网络进行截断式随机游走,得到每个用户的上下文用户集合,通过对所述用户-用户社交网络进行负采样,得到每个用户的负样本集合,全部用户的上下文用户集合和负样本集合构成了所述社交语料。
优选的,所述的通过对所述用户-用户社交网络进行截断式随机游走处理,得到每个用户的上下文用户集合,包括:
从每个节点出发,在用户-用户社交网络上运行截断式随机游走,在随机游走过程中,从用户u跳转到用户υ的概率定义如下:
其中,co(u,υ)代表用户u和用户υ共同评价过的物品数目,d+(u)代表用户u在社交网络中的节点出度,
设截断式随机游走序列长度为l,对于用户u而言,根据概率转移公式计算从用户u转移到其朋友的概率,然后选择概率最大的朋友υ作为其下一跳的节点,以此类推,直到产生长度为l的节点序列;
利用滑动窗口从每个节点序列中为每个用户寻找上下文用户集合;当滑动窗口停在节点序列中的某个位置时,处于中间位置的用户称为中心用户u,处于窗口内其它位置的用户构成了用户u的上下文用户集合
优选的,所述的通过对所述用户-用户社交网络进行负采样,得到每个用户的负样本集合,包括:
对任意用户u来说,根据其非上下文用户在社交语料中的出现频率,及其在评分数据中的活跃程度,获取用户u的负样本集合
其中,f(υ)表示用户υ在社交语料中出现的频率,r(υ)表示用户υ在评分数据中评价过的物品数量,u表示全体用户集合,超参数a为经验值;
设用户u的上下文用户集合
优选的,全部用户的上下文用户集合连同负样本集合一起构成了社交语料
优选的,所述矩阵分解与网络嵌入联合模型的目标函数定义如下:
其中
矩阵分解模型的损失函数定义如下:
其中,ω是由已观测评分对应的(u,i)索引对组成的集合,
用户特征矩阵p在矩阵分解模型和网络嵌入模型间共享,其中网络嵌入模型实为一个三层的神经网络,其输入层与隐层之间的连接权重矩阵即为
其中,激活函数σ(z)=1/(1+e-z),
正则项用于降低模型过拟合的风险,具体定义如下:
合并各项后,所述矩阵分解与网络嵌入联合模型的目标函数表示如下:
其中,α>0为超参数,用于调控矩阵分解模型与网络嵌入模型之间的比重,超参数λu,λi,λw用于调节正则项各分项的比重。
优选的,所述的利用所述用户-物品评分矩阵
本发明提出的基于矩阵分解与网络嵌入联合模型的社会化推荐方法通过设计统一的目标函数,无缝整合了矩阵分解模型与网络嵌入模型;基于统一的优化框架,矩阵分解模型所使用的监督信号可间接地引导网络嵌入模型发现适合推荐任务的社会化属性;同时“恰当”的社会化约束也会反向作用于矩阵分解模型,以获得更优的用户和物品特征,从而可以实现高效、准确地向用户推荐其所喜欢的物品。
本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
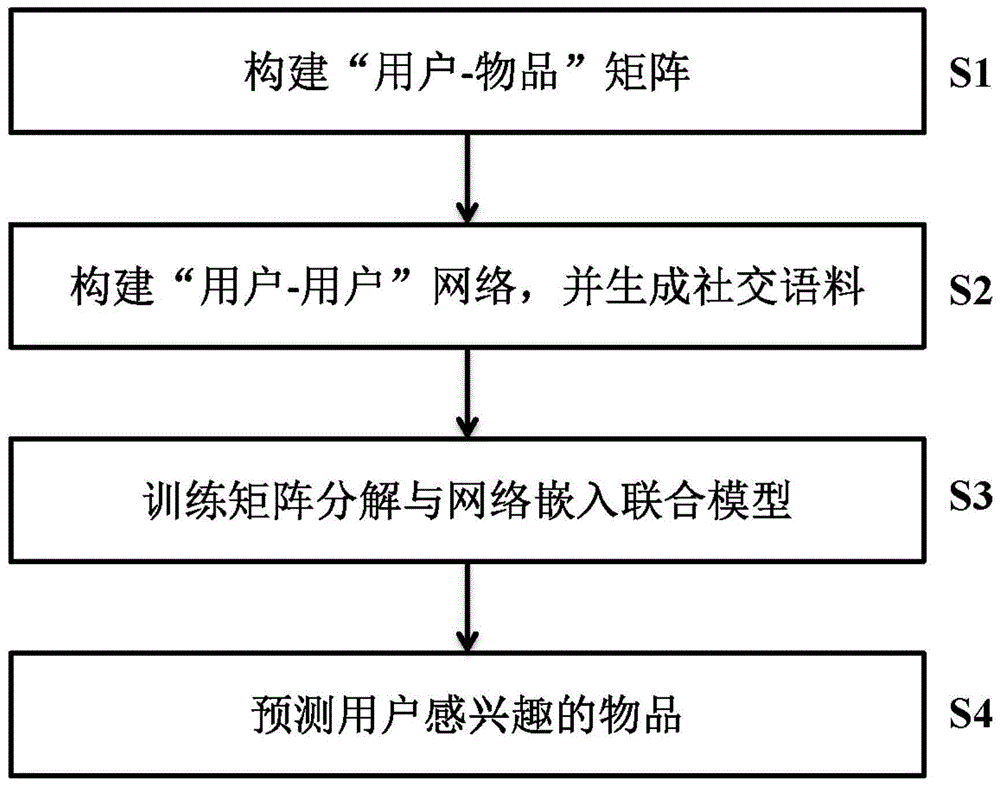
图1为本发明实施例提供的一种基于矩阵分解与网络嵌入联合模型的社会化推荐方法的处理流程图;
图2为本发明实施例提供的一种的模型训练工作流程图;
图3为本发明方法与现有社会化推荐方法的实验效果对比图。
具体实施方式
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当我们称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的任一单元和全部组合。
本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
为便于对本发明实施例的理解,下面将结合附图以几个具体实施例为例做进一步的解释说明,且各个实施例并不构成对本发明实施例的限定。
矩阵分解为基于已观测的“用户-物品”(其中“物品”指代社交平台各类信息产品)交互历史,对“用户-物品”相关性进行统计建模;然后利用该模型预测未观测的“用户-物品”相关性,并根据相关性大小为用户推荐其可能感兴趣物品。
网络嵌入为将网络结构嵌入到低维的连续空间,同时保留网络结构的内在结构属性。在本发明中,网络指的是社交网络,结点代表用户,连接代表用户间的社交关系,如好友关系(用户a关注了用户b)、转发关系(用户a转发了用户b的帖子)、评论关系(用户a评论了用户b的帖子)等等。借助网络嵌入模型,可获得用户的向量表示,该表示保留了用户的社交结构信息。
本发明实施例提出了一种基于矩阵分解与网络嵌入联合模型的社会化推荐方法,该方法通过设计统一的目标函数,无缝整合了矩阵分解模型与网络嵌入模型;基于统一的优化框架,矩阵分解模型所使用的监督信号可间接地引导网络嵌入模型发现适合推荐任务的社会化属性;同时“恰当”的社会化约束也会反向作用于矩阵分解模型,以获得更优的用户和物品特征;从而实现两个模型间的双向促进与协同优化。此外,统一的目标函数大大降低了两个模型联合调参的难度。
本发明实施例提供了一种基于矩阵分解与网络嵌入联合模型的社会化推荐方法,该方法的处理流程如图1所示,具体包括以下步骤:
步骤s1、利用已有的数据集构建“用户-物品”评分矩阵,所述评分矩阵中的行和列分别表示用户和物品,所述评分矩阵中的元素值表示用户对物品的评分,并对评分数据进行归一化处理,获得评分矩阵
步骤s2、利用已有的数据集构建“用户-用户”社交网络,所述社交网络中的结点代表用户、结点间的连接用于记录用户间的社交关系;若两用户之间有联系(比如为好友关系),则相应的连接被标记为1;若没有联系,则标记为0。通过对所述用户-用户社交网络进行截断式随机游走处理,得到每个用户的上下文用户集合,同时通过对所述用户-用户社交网络进行负采样处理,得到每个用户的负样本集合,全体用户的上下文用户集合和负样本集合构成所述社交语料
为用户生成上下文用户集合(正样本集合)的过程包括:从每个节点出发,在用户-用户社交网络上运行截断式随机游走,在随机游走过程中,从用户u跳转到用户υ的概率定义如下:
其中,co(u,υ)代表用户u和用户υ共同评价过的物品数目,d+(u)代表用户u在社交网络中的节点出度,
然后,利用滑动窗口从每个节点序列中为每个用户寻找上下文用户集合。当滑动窗口停在节点序列中的某个位置时,处于中间位置的用户称为中心用户u,处于窗口内其它位置的用户构成了用户u的上下文用户集合
为用户u生成负样本集合的过程包括:根据其非上下文用户在社交语料中的出现频率,及其在评分数据中的活跃程度,获取用户u的负样本集合
其中,f(υ)表示用户υ在社交语料中出现的频率,r(υ)表示用户υ在评分数据中评价过的物品数量,u表示全体用户集合,超参数a为经验值,通常设为0.75。
设用户u的上下文用户集合
全部用户的上下文用户集合连同负样本集合一起构成了社交语料
步骤s3、设定矩阵分解与网络嵌入联合模型的目标函数,利用所述评分矩阵
本发明所述矩阵分解与网络嵌入联合模型框架包括:
1、模型的目标函数:矩阵分解的损失项(p、q的函数)、网络嵌入的损失项(p、w的函数)、正则项(p、q、w的函数);其中为了模型联合训练,p为共享标量;最终推荐仅需要p、q即可,w可视为模型训练过程中的辅助变量。
2、模型的参数优化:根据准备好的训练样本(用户-物品矩阵
所述的矩阵分解与网络嵌入联合模型的目标函数定义为:
其中
矩阵分解模型的损失函数定义如下:
其中,ω是由已观测评分对应的(u,i)索引对组成的集合(本发明仅对观测到的“用户-物品”评分建模),
网络嵌入模型实际上是一个神经网络,为了简化问题表述,此处假设神经网络仅包括一个隐层。由于用户特征矩阵p在两个模型间共享,神经网络输入层与隐层之间的连接权重矩阵即为
其中,激活函数σ(z)=1/(1+e-z),
正则项用于降低模型过拟合的风险,具体定义如下:
合并各项后,联合模型的目标函数可表示如下:
其中,α>0为超参数,用于调控矩阵分解与网络嵌入模型之间的比重;另几个超参数λu,λi,λw用于调节正则项中各子项的比重。
本发明实施例提供的一种矩阵分解与网络嵌入联合模型的训练与优化的过程包括:首先随机初始化模型参数p,q,w,进入迭代训练过程:固定q,w,计算目标函数关于p的梯度,利用随机梯度下降法更新p;再固定p,w,计算目标函数关于q的梯度,利用随机梯度下降法更新q;再固定p,q,计算目标函数关于w的梯度,利用随机梯度下降法更新w;重复上述步骤,不断交替更新p,q,w,直到满足迭代停止条件,例如目标函数值小于某个预设定阈值或迭代轮数达到一定量级,输出最终的用户特征矩阵
本发明实施例提供的一种矩阵分解与网络嵌入联合模型的训练与优化的工作流程如图2所示。包括如下步骤:
s3-1:随机初始化矩阵p,q,w,进入迭代训练过程;
s3-2:固定矩阵q,w,计算目标函数关于p的梯度,利用随机梯度下降法更新矩阵p;
s3-3:固定矩阵p,w,计算目标函数关于q的梯度,利用随机梯度下降法更新矩阵q;
s3-4:固定矩阵p,q,计算目标函数关于w的梯度,利用随机梯度下降法更新矩阵w;
s3-5:重复s3-1到s3-4,不断交替更新p,q,w,直到满足收敛条件,例如目标函数值小于某个预设定阈值或迭代轮数达到一定量级,最后输出参数模型。
值得注意的是,矩阵p被矩阵分解模型和网络嵌入模型所共享,因此两个模型可以在交替迭代更新过程中被协同优化。
步骤s4、根据用户和物品的特征矩阵预测未观测物品的评分:
本发明实施例在两个数据集上进行了实验,并对比了本发明所述方法与目前主流的社会化推荐方法的效果。对比方法包括两个经典的社会化推荐方法sorec和soreg(分别发表于数据挖掘领域主流会议cikm2008和wsdm2011),以及目前性能最好方法cune(发表于数据挖掘领域主流会议sdm2017)。
第一个数据集是影评相关的数据集filmtrust,其ui矩阵的行代表观影人,列代表电影,评分范围:0.5-4.0分;另有用户社交关系(关注vs被关注)作为辅助信息。该数据集包括1,508个用户、2,071个物品、35,497个用户关注连接;“用户-物品”交互数据的稠密度为1.14%、“用户-用户”社交数据的稠密度为0.42%。
第二个数据集是书评相关的数据集“豆瓣”数据集,其ui矩阵的行代表读书人,列代表图书,评分范围:1-5分;另有用户社交关系(关注vs被关注)作为辅助信息。该数据集包括2,963个用户、39,694个物品、894,887个好友连接;“用户-物品”交互数据的稠密度为0.76%、“用户-用户”社交数据的稠密度为0.48%。
图3为本发明方法与现有社会化推荐方法的实验效果对比图,如图3所示,斜条纹柱状图代表四种算法在filmtrust数据集上的测试结果,网格柱状图代表四种算法在豆瓣数据集上的测试结果,评价指标为平均绝对误差(meanabsoluteerror,mae),两组实验结果均表明:本发明所述方法较之对比方法性能有很大改进(mae越低越好)。
综上所述,本发明实施例提出的基于矩阵分解与网络嵌入联合模型的社会化推荐方法,该方法通过设计统一的目标函数,无缝整合了矩阵分解模型与网络嵌入模型;基于统一的优化框架,矩阵分解模型所使用的监督信号可间接地引导网络嵌入模型发现适合推荐任务的社会化属性;同时“恰当”的社会化约束也会反向作用于矩阵分解模型,以获得更优的用户和物品特征,实现两个模型间的双向促进与协同优化,从而可以实现高效、准确地向用户推荐其所喜欢的物品。
本发明提供了一种推荐系统融合社交信息的联合学习范式,将矩阵分解模型与网络嵌入模型进行无缝拼接,进而达到协同优化的目的。此外,统一的目标函数大大降低了两个模型联合调参的难度。
本领域普通技术人员可以理解:附图只是一个实施例的示意图,附图中的模块或流程并不一定是实施本发明所必须的。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!