对用户分类的方法和装置与流程
本说明书一个或多个实施例涉及计算机领域,尤其涉及对用户分类的方法和装置。
背景技术:
当前,在互联网服务中常常会涉及到对用户分类,根据用户的类别确定是否向该用户提供服务,或者根据用户的类别确定向该用户提供的服务等级。例如,小额贷款业务中,为了尽量减少逾期带来的资损,在向用户发放贷款前,确定该用户的类别,以便尽可能准确地预测出该用户是否存在逾期还款的风险。
现有技术中,常常通过用户的历史行为数据对用户分类,上述历史行为数据可以包括用户的购物习惯、理财习惯等,但是当无法获取用户的历史行为数据时,就无法实现对用户准确的分类。
因此,希望能有改进的方案,能够准确的对用户分类。
技术实现要素:
本说明书一个或多个实施例描述了一种对用户分类的方法和装置,能够准确的对用户分类。
第一方面,提供了一种对用户分类的方法,方法包括:
获取目标用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合;
将所述标识集合、所述分词集合和所述标签集合输入预先训练的神经网络模型,其中,所述神经网络模型包括嵌入层、注意力层和分类层;
在所述嵌入层,获取所述标识集合中各应用标识分别对应的第一嵌入向量,获取所述分词集合中各分词分别对应的第二嵌入向量,获取所述标签集合中各类别标签分别对应的第三嵌入向量;
在所述注意力层,根据预先确定的应用标识权重向量,确定各应用标识对应的各第一权重,并基于各第一权重对各所述第一嵌入向量进行加权处理得到第四嵌入向量;根据预先确定的分词权重向量,确定各分词对应的各第二权重,并基于各第二权重对各所述第二嵌入向量进行加权处理得到第五嵌入向量;根据预先确定的类别标签权重向量,确定各类别标签对应的各第三权重,并基于各第三权重对各所述第三嵌入向量进行加权处理得到第六嵌入向量;
在所述分类层,根据所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量,确定所述目标用户对应的用户类别。
在一种可能的实施方式中,所述确定各应用标识对应的各第一权重,包括:
基于各所述第一嵌入向量和所述应用标识权重向量的点积,确定各第一权重。
在一种可能的实施方式中,所述各应用标识以one-hot编码的形式输入所述神经网络模型,用于根据该one-hot编码确定所述各应用标识分别对应的第一嵌入向量。
在一种可能的实施方式中,所述各分词以one-hot编码的形式输入所述神经网络模型,用于根据该one-hot编码确定所述各分词分别对应的第二嵌入向量。
在一种可能的实施方式中,所述各类别标签以one-hot编码的形式输入所述神经网络模型,用于根据该one-hot编码确定所述各类别标签分别对应的第三嵌入向量。
在一种可能的实施方式中,所述神经网络模型采用如下方式训练:
获取第一时间周期内的样本数据,所述第一时间周期包括第一子时间周期和第二子时间周期,所述第一子时间周期在所述第二子时间周期之前;
采用所述第一子时间周期中第一预设比例的样本数据对所述神经网络模型进行训练,采用所述第一子时间周期中所述第一预设比例的样本数据之外的样本数据对训练后的所述神经网络模型进行测试,以及采用所述第二子时间周期中的样本数据对训练后的所述神经网络模型进行验证。
在一种可能的实施方式中,所述用户类别包括:正常还款用户和逾期还款用户;所述神经网络模型根据样本数据进行训练,所述样本数据包括:样本输入和样本标签;
所述样本标签采用如下方式确定:
对于逾期还款的时间小于或等于预设时间阈值的用户确定该用户的样本标签为正常还款用户;
对于逾期还款的时间大于所述预设时间阈值的用户确定该用户的样本标签为逾期还款用户。
在一种可能的实施方式中,所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量通过如下方式确定:
在训练所述神经网络模型的过程中,通过反向回传更新所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量,在所述神经网络模型训练结束后得到确定的所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量。
在一种可能的实施方式中,所述分类层包括映射子层和分类子层;在所述映射子层,对所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量进行融合,得到综合嵌入向量;在所述分类子层,利用softmax函数对所述综合嵌入向量进行分类,得到所述目标用户的用户类别。
第二方面,提供了一种对用户分类的装置,装置包括:
获取单元,用于获取目标用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合;
输入单元,用于将所述获取单元获取的所述标识集合、所述分词集合和所述标签集合输入预先训练的神经网络模型,其中,所述神经网络模型包括嵌入层、注意力层和分类层;
嵌入单元,用于在所述嵌入层,获取所述输入单元输入的所述标识集合中各应用标识分别对应的第一嵌入向量,获取所述输入单元输入的所述分词集合中各分词分别对应的第二嵌入向量,获取所述输入单元输入的所述标签集合中各类别标签分别对应的第三嵌入向量;
注意力单元,用于在所述注意力层,根据预先确定的应用标识权重向量,确定各应用标识对应的各第一权重,并基于各第一权重对所述嵌入单元获取的各所述第一嵌入向量进行加权处理得到第四嵌入向量;根据预先确定的分词权重向量,确定各分词对应的各第二权重,并基于各第二权重对所述嵌入单元获取的各所述第二嵌入向量进行加权处理得到第五嵌入向量;根据预先确定的类别标签权重向量,确定各类别标签对应的各第三权重,并基于各第三权重对所述嵌入单元获取的各所述第三嵌入向量进行加权处理得到第六嵌入向量;
分类单元,用于在所述分类层,根据所述注意力单元得到的所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量,确定所述目标用户对应的用户类别。
第三方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面的方法。
第四方面,提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现第一方面的方法。
通过本说明书实施例提供的方法和装置,首先获取目标用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合;然后将所述标识集合、所述分词集合和所述标签集合输入预先训练的神经网络模型,其中,所述神经网络模型包括嵌入层,注意力层和分类层;先在所述嵌入层,获取所述标识集合中各应用标识分别对应的第一嵌入向量,获取所述分词集合中各分词分别对应的第二嵌入向量,获取所述标签集合中各类别标签分别对应的第三嵌入向量;接着在所述注意力层,根据预先确定的应用标识权重向量,确定各应用标识对应的各第一权重,并基于各第一权重对各所述第一嵌入向量进行加权处理得到第四嵌入向量;根据预先确定的分词权重向量,确定各分词对应的各第二权重,并基于各第二权重对各所述第二嵌入向量进行加权处理得到第五嵌入向量;根据预先确定的类别标签权重向量,确定各类别标签对应的各第三权重,并基于各第三权重对各所述第三嵌入向量进行加权处理得到第六嵌入向量;最后在所述分类层,根据所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量,确定所述目标用户对应的用户类别。由上可见,本说明书实施例,通过获取目标用户安装的应用信息,基于应用信息对目标用户分类,由于应用和用户之间构成二部图,信息可以在用户和应用之间传递,通过神经网络模型能够学习到群体信息,从而能够准确的对用户分类。
此外,在神经网络模型的嵌入层,通过嵌入的方式将高维特征映射到更容易分类的低维空间,使得模型能够更加容易学到特征之间的相关性,也可以提高分类的准确率;另外,通过引入注意力机制,根据各应用对风险预估的重要性,使得对用户分类具备可解释性。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1为本说明书披露的一个实施例的实施场景示意图;
图2示出根据一个实施例的对用户分类的方法流程图;
图3为本说明书实施例提供的一种神经网络模型结构示意图;
图4示出根据一个实施例的神经网络模型的训练方法流程图;
图5示出根据一个实施例的对用户分类的装置的示意性框图。
具体实施方式
下面结合附图,对本说明书提供的方案进行描述。
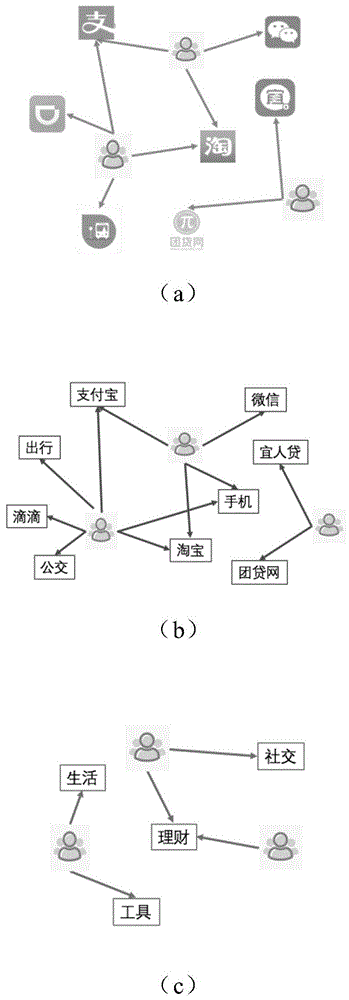
图1为本说明书披露的一个实施例的实施场景示意图。该实施场景涉及对用户的分类,具体地,基于用户安装的各应用的应用信息对用户进行分类。其中,上述应用信息可以包括应用标识、应用的名字的分词和应用的类别标签,这些应用信息均可与用户构成二部图。在图1中的(a)表示用户和应用标识构成的二部图;在图1中的(b)表示用户和应用的名字的分词构成的二部图,如应用的名字“手机公交”和“手机淘宝”经过分词处理后,可分别被处理为分词“手机”和“公交”、“手机”和“淘宝”,则该用户会和‘手机’、‘公交’、‘淘宝’三个字段构成一个二部图;在图1中的(c)表示用户和应用的类别标签构成的二部图。可以理解的是,应用与应用标识之间通常是一一对应的关系,应用与应用的名字的分词之间通常是一对一或一对多的关系,应用与应用的类别标签之间通常是多对一的关系,也就是说,多个应用对应同一类别。
本说明书实施例,通过将应用信息和用户之间构成的二部图建模为神经网络模型,该神经网络模型用于对用户进行分类,从而使得类别可以在用户和应用信息之间传递,安装同一个应用的多个用户可能拥有相似的类别,这种对用户分类的方法有利于学到群体信息。其中,上述神经网络模型也可以称为图模型。
图2示出根据一个实施例的对用户分类的方法流程图,该方法可以基于图1所示的实施场景。如图2所示,该实施例中对用户分类的方法包括以下步骤:步骤21,获取目标用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合;步骤22,将所述标识集合、所述分词集合和所述标签集合输入预先训练的神经网络模型,其中,所述神经网络模型包括嵌入层、注意力层和分类层;步骤23,在所述嵌入层,获取所述标识集合中各应用标识分别对应的第一嵌入向量,获取所述分词集合中各分词分别对应的第二嵌入向量,获取所述标签集合中各类别标签分别对应的第三嵌入向量;步骤24,在所述注意力层,根据预先确定的应用标识权重向量,确定各应用标识对应的各第一权重,并基于各第一权重对各所述第一嵌入向量进行加权处理得到第四嵌入向量;根据预先确定的分词权重向量,确定各分词对应的各第二权重,并基于各第二权重对各所述第二嵌入向量进行加权处理得到第五嵌入向量;根据预先确定的类别标签权重向量,确定各类别标签对应的各第三权重,并基于各第三权重对各所述第三嵌入向量进行加权处理得到第六嵌入向量;步骤25,在所述分类层,根据所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量,确定所述目标用户对应的用户类别。下面描述以上各个步骤的具体执行方式。
首先在步骤21,获取目标用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合。可以理解的是,上述预设历史时间周期可以出于不同的考虑灵活设定,例如,设定为10个月或3个月或6个月等。
本说明书实施例,上述目标用户安装应用的行为可以具体针对一个设备,也可以针对多个设备,也就是说,步骤21中,可以是针对目标用户的1个或多个设备来获取应用信息的。
在一个示例中,为了便于对应用的名字进行分词处理,可以获取应用的中文名字,或者,当一个应用仅有英文名字时,将该英文名字翻译成中文名字。
然后在步骤22,将所述标识集合、所述分词集合和所述标签集合输入预先训练的神经网络模型,其中,所述神经网络模型包括嵌入层、注意力层和分类层。可以理解是,可以将所述标识集合、所述分词集合和所述标签集合分别进行序列化处理为稀疏特征,将稀疏特征输入预先训练的神经网络模型。
在一个示例中,所述标识集合中的各应用标识以one-hot编码的形式输入所述神经网络模型,用于根据该one-hot编码确定所述各应用标识分别对应的第一嵌入向量。
在一个示例中,所述分词集合中的各分词以one-hot编码的形式输入所述神经网络模型,用于根据该one-hot编码确定所述各分词分别对应的第二嵌入向量。
在一个示例中,所述标签集合中的各类别标签以one-hot编码的形式输入所述神经网络模型,用于根据该one-hot编码确定所述各类别标签分别对应的第三嵌入向量。
图3为本说明书实施例提供的一种神经网络模型结构示意图。参照图3,所述标识集合中的各应用标识、所述分词集合中的各分词和所述标签集合中的各类别标签分别经过嵌入层、注意力层和分类层的处理后,得到目标用户的用户类别。
接着在步骤23,在所述嵌入层,获取所述标识集合中各应用标识分别对应的第一嵌入向量,获取所述分词集合中各分词分别对应的第二嵌入向量,获取所述标签集合中各类别标签分别对应的第三嵌入向量。可以理解的是,通过嵌入层可以高维特征映射到更容易分类的低维空间,使得模型能够更加容易学到特征之间的相关性,也可以提高模型的准确率。
在一个示例中,所述各应用标识以one-hot编码的形式输入所述神经网络模型,在所述嵌入层根据该one-hot编码,通过lookup-embedding的嵌入方式确定所述各应用标识分别对应的第一嵌入向量。
类似地,可以采取同样的方式获取所述分词集合中各分词分别对应的第二嵌入向量,获取所述标签集合中各类别标签分别对应的第三嵌入向量。
再在步骤24,在所述注意力层,根据预先确定的应用标识权重向量,确定各应用标识对应的各第一权重,并基于各第一权重对各所述第一嵌入向量进行加权处理得到第四嵌入向量;根据预先确定的分词权重向量,确定各分词对应的各第二权重,并基于各第二权重对各所述第二嵌入向量进行加权处理得到第五嵌入向量;根据预先确定的类别标签权重向量,确定各类别标签对应的各第三权重,并基于各第三权重对各所述第三嵌入向量进行加权处理得到第六嵌入向量。可以理解的是,应用标识权重向量、分词权重向量和类别标签权重向量可以在对神经网络模型的训练过程中确定。
本说明书实施例中,可以基于各所述第一嵌入向量和所述应用标识权重向量的点积,确定各第一权重。类似地,可以基于各所述第二嵌入向量和所述分词权重向量的点积,确定各第二权重。可以基于各所述第三嵌入向量和所述类别标签权重向量的点积,确定各第三权重。
在一个示例中,定义应用标识权重向量为ωapp、分词权重向量为ωapp-name、类别标签权重向量为ωapp-tag;计算权重向量weighti=softmax(embi·wi),其中,i∈{app,app-name,app-tag},可以理解的是,当i为app时,embi为第一嵌入向量,wi为应用标识权重向量,weighti为各第一权重,每个app的权重体现了该app对用户分类的重要性;再通过对权重向量
本说明书实施例,还包括对神经网络模型的训练过程。图4示出根据一个实施例的神经网络模型的训练方法流程图,主要包括:数据采集、样本定义、特征处理和模型训练四个主要的阶段。
在数据采集部分,主要包括获取用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合。
在样本定义部分,主要包括定义用户标签、训练集和测试集。
在一个示例中,所述用户类别包括:正常还款用户和逾期还款用户;所述神经网络模型根据样本数据进行训练,所述样本数据包括:样本输入和样本标签;所述样本标签采用如下方式确定:对于逾期还款的时间小于或等于预设时间阈值的用户确定该用户的样本标签为正常还款用户;对于逾期还款的时间大于所述预设时间阈值的用户确定该用户的样本标签为逾期还款用户。例如,定义逾期用户标签为1,正常还款用户标签为0。
在一个示例中,所述神经网络模型采用如下方式训练:获取第一时间周期内的样本数据,所述第一时间周期包括第一子时间周期和第二子时间周期,所述第一子时间周期在所述第二子时间周期之前;采用所述第一子时间周期中第一预设比例的样本数据对所述神经网络模型进行训练,采用所述第一子时间周期中所述第一预设比例的样本数据之外的样本数据对训练后的所述神经网络模型进行测试,以及采用所述第二子时间周期中的样本数据对训练后的所述神经网络模型进行验证。例如,共有十个月的样本数据,取前五个月的70%做训练集,另外30%做测试集,后五个月做面向对象的测试(object-orientedtest,oot)验证。
在特征处理部分,主要包括对用户的各应用标识、各分词、各类别标签分别序列化为稀疏特征。例如,转换为one-hot编码。
在模型训练部分,根据样本数据对神经网络模型进行训练,以获得最优的参数。
在一个示例中,所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量通过如下方式确定:
在训练所述神经网络模型的过程中,通过反向回传更新所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量,在所述神经网络模型训练结束后得到确定的所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量。可以理解的是,定义损失函数,计算梯度,可以回传更新前述各嵌入向量以及各权重向量。
最后在步骤25,在所述分类层,根据所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量,确定所述目标用户对应的用户类别。可以理解的是,可以对所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量进行融合后,再进行分类。
在一个示例中,所述分类层包括映射子层和分类子层;在所述映射子层,对所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量进行融合,得到综合嵌入向量;在所述分类子层,利用softmax函数对所述综合嵌入向量进行分类,得到所述目标用户的用户类别。
例如,所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量各自通过多层非线性映射后(损失函数为relu)合并,得到融合的综合嵌入向量。利用softmax函数对融合的综合嵌入向量进行分类,得到用户逾期的概率。
在一个示例中,所述用户类别包括:正常还款用户和逾期还款用户;在对神经网络模型进行训练求得最优的参数后,在全量样本上使用前向传播算法(forwardpropagation)执行上述流程,计算用户逾期的概率。业务中可以将该神经网络模型的输出结果作为特征参与其他已有模型的训练,也可以直接用作线上决策,根据业务经验定义阈值(threshold),用户逾期的概率大于该阈值的用户直接作为高风险用户处理。
针对风险评估场景,通过应用信息和用户之间构成的二部图,利用一个具有可解释型的图模型对应用和用户的关系进行挖掘,为风险评估提供了可解释且更准确的预估结果。
通过本说明书实施例提供的方法,首先获取目标用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合;然后将所述标识集合、所述分词集合和所述标签集合输入预先训练的神经网络模型,其中,所述神经网络模型包括嵌入层,注意力层和分类层;先在所述嵌入层,获取所述标识集合中各应用标识分别对应的第一嵌入向量,获取所述分词集合中各分词分别对应的第二嵌入向量,获取所述标签集合中各类别标签分别对应的第三嵌入向量;接着在所述注意力层,根据预先确定的应用标识权重向量,确定各应用标识对应的各第一权重,并基于各第一权重对各所述第一嵌入向量进行加权处理得到第四嵌入向量;根据预先确定的分词权重向量,确定各分词对应的各第二权重,并基于各第二权重对各所述第二嵌入向量进行加权处理得到第五嵌入向量;根据预先确定的类别标签权重向量,确定各类别标签对应的各第三权重,并基于各第三权重对各所述第三嵌入向量进行加权处理得到第六嵌入向量;最后在所述分类层,根据所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量,确定所述目标用户对应的用户类别。由上可见,本说明书实施例,通过获取目标用户安装的应用信息,基于应用信息对目标用户分类,由于应用和用户之间构成二部图,信息可以在用户和应用之间传递,通过神经网络模型能够学习到群体信息,从而能够准确的对用户分类。
此外,在神经网络模型的嵌入层,通过嵌入的方式将高维特征映射到更容易分类的低维空间,使得模型能够更加容易学到特征之间的相关性,也可以提高分类的准确率;另外,通过引入注意力机制,根据各应用对风险预估的重要性,使得对用户分类具备可解释性。
根据另一方面的实施例,还提供一种对用户分类的装置,该装置用于执行本说明书实施例提供的对用户分类的方法。图5示出根据一个实施例的对用户分类的装置的示意性框图。如图5所示,该装置500包括:
获取单元51,用于获取目标用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合;
输入单元52,用于将所述获取单元51获取的所述标识集合、所述分词集合和所述标签集合输入预先训练的神经网络模型,其中,所述神经网络模型包括嵌入层、注意力层和分类层;
嵌入单元53,用于在所述嵌入层,获取所述输入单元52输入的所述标识集合中各应用标识分别对应的第一嵌入向量,获取所述输入单元输入的所述分词集合中各分词分别对应的第二嵌入向量,获取所述输入单元输入的所述标签集合中各类别标签分别对应的第三嵌入向量;
注意力单元54,用于在所述注意力层,根据预先确定的应用标识权重向量,确定各应用标识对应的各第一权重,并基于各第一权重对所述嵌入单元53获取的各所述第一嵌入向量进行加权处理得到第四嵌入向量;根据预先确定的分词权重向量,确定各分词对应的各第二权重,并基于各第二权重对所述嵌入单元53获取的各所述第二嵌入向量进行加权处理得到第五嵌入向量;根据预先确定的类别标签权重向量,确定各类别标签对应的各第三权重,并基于各第三权重对所述嵌入单元53获取的各所述第三嵌入向量进行加权处理得到第六嵌入向量;
分类单元55,用于在所述分类层,根据所述注意力单元54得到的所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量,确定所述目标用户对应的用户类别。
可选地,作为一个实施例,所述注意力单元54,具体用于基于各所述第一嵌入向量和所述应用标识权重向量的点积,确定各第一权重。
可选地,作为一个实施例,所述输入单元52,具体用于将所述各应用标识以one-hot编码的形式输入所述神经网络模型;
所述嵌入单元53,具体用于根据所述输入单元52输入的该one-hot编码确定所述各应用标识分别对应的第一嵌入向量。
可选地,作为一个实施例,所述输入单元52,具体用于将所述各分词以one-hot编码的形式输入所述神经网络模型;
所述嵌入单元53,具体用于根据所述输入单元52输入的该one-hot编码确定所述各分词分别对应的第二嵌入向量。
可选地,作为一个实施例,所述输入单元52,具体用于将所述各类别标签以one-hot编码的形式输入所述神经网络模型;
所述嵌入单元53,具体用于根据所述输入单元52输入的该one-hot编码确定所述各类别标签分别对应的第三嵌入向量。
可选地,作为一个实施例,所述神经网络模型采用如下方式训练:
获取第一时间周期内的样本数据,所述第一时间周期包括第一子时间周期和第二子时间周期,所述第一子时间周期在所述第二子时间周期之前;
采用所述第一子时间周期中第一预设比例的样本数据对所述神经网络模型进行训练,采用所述第一子时间周期中所述第一预设比例的样本数据之外的样本数据对训练后的所述神经网络模型进行测试,以及采用所述第二子时间周期中的样本数据对训练后的所述神经网络模型进行验证。
可选地,作为一个实施例,所述用户类别包括:正常还款用户和逾期还款用户;所述神经网络模型根据样本数据进行训练,所述样本数据包括:样本输入和样本标签;
所述样本标签采用如下方式确定:
对于逾期还款的时间小于或等于预设时间阈值的用户确定该用户的样本标签为正常还款用户;
对于逾期还款的时间大于所述预设时间阈值的用户确定该用户的样本标签为逾期还款用户。
可选地,作为一个实施例,所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量通过如下方式确定:
在训练所述神经网络模型的过程中,通过反向回传更新所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量,在所述神经网络模型训练结束后得到确定的所述应用标识权重向量、所述分词权重向量和所述类别标签权重向量。
可选地,作为一个实施例,所述分类层包括映射子层和分类子层;所述分类单元55,具体用于在所述映射子层,对所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量进行融合,得到综合嵌入向量;在所述分类子层,利用softmax函数对所述综合嵌入向量进行分类,得到所述目标用户的用户类别。
通过本说明书实施例提供的装置,首先获取单元51获取目标用户在预设历史时间周期内安装的各应用的应用标识构成的标识集合、所述各应用的名字分词后得到的分词集合,和所述各应用的类别标签构成的标签集合;然后输入单元52将所述标识集合、所述分词集合和所述标签集合输入预先训练的神经网络模型,其中,所述神经网络模型包括嵌入层,注意力层和分类层;先由嵌入单元53在所述嵌入层,获取所述标识集合中各应用标识分别对应的第一嵌入向量,获取所述分词集合中各分词分别对应的第二嵌入向量,获取所述标签集合中各类别标签分别对应的第三嵌入向量;接着由注意力单元54在所述注意力层,根据预先确定的应用标识权重向量,确定各应用标识对应的各第一权重,并基于各第一权重对各所述第一嵌入向量进行加权处理得到第四嵌入向量;根据预先确定的分词权重向量,确定各分词对应的各第二权重,并基于各第二权重对各所述第二嵌入向量进行加权处理得到第五嵌入向量;根据预先确定的类别标签权重向量,确定各类别标签对应的各第三权重,并基于各第三权重对各所述第三嵌入向量进行加权处理得到第六嵌入向量;最后分类单元55在所述分类层,根据所述第四嵌入向量、所述第五嵌入向量和所述第六嵌入向量,确定所述目标用户对应的用户类别。由上可见,本说明书实施例,通过获取目标用户安装的应用信息,基于应用信息对目标用户分类,由于应用和用户之间构成二部图,信息可以在用户和应用之间传递,通过神经网络模型能够学习到群体信息,从而能够准确的对用户分类。
此外,在神经网络模型的嵌入层,通过嵌入的方式将高维特征映射到更容易分类的低维空间,使得模型能够更加容易学到特征之间的相关性,也可以提高分类的准确率;另外,通过引入注意力机制,根据各应用对风险预估的重要性,使得对用户分类具备可解释性。
根据另一方面的实施例,还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行结合图2所描述的方法。
根据再一方面的实施例,还提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现结合图2所描述的方法。
本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!