一种文本输出方法、装置、计算机设备和存储介质与流程
本发明涉及人工智能技术领域,具体涉及一种文本输出方法、装置、计算机设备和存储介质。
背景技术:
机器阅读理解技术作为近年来人工智能领域热点的研究方向,可以从给定的文档中提取一段文字作为用户所提问题的回答,拥有比传统自动问答技术更加灵活的应用场景,目前已在网页搜索、问答机器人、智能语音助手等互联网产品和服务中得到了广泛的应用。
在现有机器阅读理解技术中,可以采用预训练语言模型的语义表示能力来实现文本预测或输出,比如,结合神经网络来实现文本预测或输出。例如,可以基于预训练语言模型和神经网络在特定文本中预测或输出某个问题对应的答案文本。
在对现有技术的研究和实践过程中,本发明的发明人发现,现有的预训练语言模型实现文本输出的精准度不够高。
技术实现要素:
本申请实施例提供一种文本输出方法、装置、计算机设备和存储介质,可以提高文本输出的精准度。
本申请实施例提供一种文本输出方法,包括:
获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;
构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;
分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;
分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;
根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;
基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。
相应的,本申请实施例还提供了一种文本输出装置,包括:
获取单元,用于获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;
特征构建单元,用于构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;
处理单元,用于分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;
特征提取单元,用于分别对所述处理后第一特征向量、处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;
预测单元,用于根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;
确定单元,用于基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。
可选的,在一些实施例中,所述特征构建单元,包括:
切分子单元,用于分别对所述问题文本和所述检测子文本进行字单元切分,得到所述问题文本的第一字单元、所述检测子文本的第二字单元;
编码子单元,用于分别对所述问题文本的第一字单元和所述检测子文本的第二字单元进行编码,得到第一字单元的第一字单元向量、第二字单元的第二字单元向量;
融合子单元,用于将所述第一字单元向量和第二字单元向量分别与预设匹配特征进行融合,得到所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量。
在一些实施例中,所述融合子单元,用于:
获取预设匹配特征,所述预设匹配特征包括子领域特征、词性特征和词汇重叠特征;
将所述预设匹配特征使用向量进行表示,得到子领域特征向量、词性特征向量和词汇重叠特征向量;
将所述第一字单元向量和第二字单元向量分别与子领域特征向量、词性特征向量和词汇重叠特征向量进行融合,得到所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量。
在一些实施例中,所述处理单元,用于:
采用高速路神经网络对所述第一特征向量和所述第二特征向量进行非线性变换,得到变换后第一特征向量、变换后第二特征向量;
采用高速路神经网络对所述第一特征向量和所述第二特征向量进行比例更新,得到更新后第一特征向量、更新后第二特征向量;
采用高速路神经网络将变换后第一特征向量与更新后第一特征向量进行融合,得到处理后第一特征向量;将变换后第二特征向量与更新后第二特征向量进行融合,得到处理后第二特征向量。
在一些实施例中,所述特征提取单元,用于:
采用循环神经网络分别对所述处理后第一特征向量和所述处理后第二特征向量进行正向传递操作,得到所述第一字单元的第一正向传递结果向量、所述第二字单元的第二正向传递结果向量;
采用循环神经网络分别对所述处理后第一特征向量和所述处理后第二特征向量进行反向传递操作,得到所述第一字单元的第一反向传递结果向量、所述第二字单元的第二反向传递结果向量;
采用循环神经网络将所述第一字单元的第一正向传递结果向量与所述第一字单元的第一反向传递结果向量进行连接,得到所述第一字单元的第一目标特征向量;将所述第二字单元的第二正向传递结果向量与所述第二字单元的第二反向传递结果向量进行连接,得到所述第二字单元的第二目标特征向量。
在一些实施例中,所述预测单元,用于:
使用全连接网络对所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量进行线性变换,得到变换后第一目标特征向量、变换后第二目标特征向量;
基于变换后第一目标特征向量和变换后第二目标特征向量,使用全连接网络对所述第一字单元和所述第二字单元进行分类,得到所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率。
在一些实施例中,所述确定单元,包括:
确定子单元,用于根据所述第一概率和所述第二概率,从所述第一字单元和所述第二字单元中,确定答案起始字单元和答案终止字单元;
本文构建子单元,用于根据答案起始字单元和答案终止字单元,构建所述问题文本对应的答案文本,并输出所述答案文本。
在一些实施例中,所述获取单元,包括:
文本获取子单元,用于获取问题文本和检测文本;
文本划分子单元,用于将所述检测文本划分为多个检测子文本。
在一些实施例中,所述文本划分子单元,用于:
在所述检测文本上构建文本窗口;
按照预设步长对文本窗口进行滑动,以将所述检测文本划分为多个检测子文本。
相应的,本申请还提供一种计算机设备,包括存储器和处理器;所述存储器存储有应用程序,所述处理器用于运行所述存储器内的应用程序,以执行本申请实施例提供的任一种文本输出方法中的步骤。
此外,本申请实施例还提供一种存储介质,所述存储介质存储有多条指令,所述指令适于处理器进行加载,以执行本申请实施例提供的任一种文本输出方法中的步骤。
本申请实施例可以获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。由于该方案通过引入一系列匹配特征与原有输入融合作为输入信息的增强,并对引入匹配特征后的输入信息进行非线性处理以及特征提取,从而使得文本输出的精准度大大提高。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1a是本申请实施例提供的文本输出方法的场景示意图;
图1b是本申请实施例提供的文本输出方法的流程示意图;
图1c是本申请实施例提供的人工神经网络模型结构示意图;
图1d是本申请实施例提供的高速路神经网络结构示意图;
图2a是本申请实施例提供的文本输出方法的另一流程示意图;
图2b是本申请实施例提供的文本输出方法中“搜索”的场景示意图;
图2c是本申请实施例提供的文本输出方法中“智能助手”的场景示意图;
图2d是本申请实施例提供的文本输出方法中“构建文本窗口”的场景示意图;
图3a是本申请实施例提供的文本输出装置的结构示意图;
图3b是本申请实施例提供的文本输出装置的另一结构示意图;
图3c是本申请实施例提供的文本输出装置的另一结构示意图;
图3d是本申请实施例提供的文本输出装置的另一结构示意图;
图4是本申请实施例提供的计算机设备的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本申请实施例提供一种文本输出方法、装置、计算机设备和存储介质。其中,该文本输出装置可以集成在计算机设备中,该计算机设备可以是服务器,也可以是终端等设备。
本申请实施例提供的文本输出方案涉及人工智能的自然语言处理(nlp,naturelanguageprocessing)。可以通过人工智能的自然语言处理技术实现从问题文本和特定文本中提取并输出问题文本对应的答案文本。
其中,自然语言处理技术(nlp,naturelanguageprocessing)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括文本处理、机器阅读理解、机器翻译、机器人问答、知识图谱等技术。
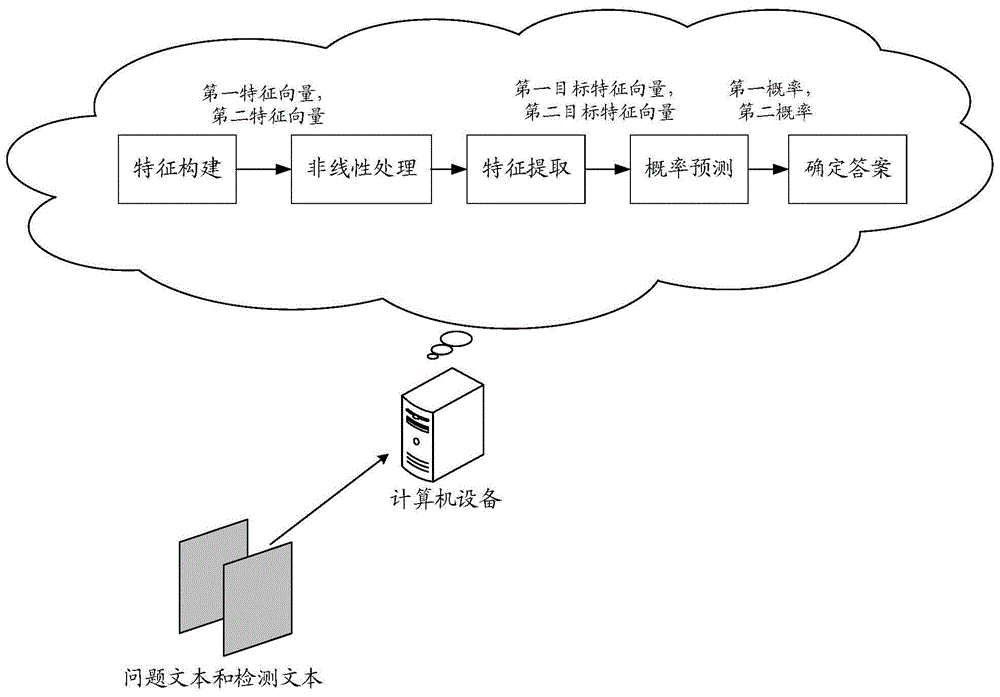
例如,参见图1a,以该文本输出装置集成在计算机设备中为例,该计算机设备可以获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。
以下分别进行详细说明。需说明的是,以下实施例的描述顺序不作为对实施例优选顺序的限定。
在本实施例中,将从文本输出装置的角度进行描述,该文本输出装置具体可以集成在计算机设备中,该计算机设备可以是服务器,也可以是终端等设备;其中,该终端可以包括平板电脑、笔记本电脑、个人计算机(pc,personalcomputer)、微型处理盒子、或者其他设备等。
如图1b所示,该文本输出方法的具体流程可以如下:
101、获取问题文本和检测文本,将检测文本划分为多个检测子文本。
其中,问题文本是指包含有问题信息的文本,是将用户所提问的问题采用文本进行表示,检测文本是指需要从中提取该问题所对应的答案的参考文本,为已给定的文本,可以通过用户自身指定。
其中,获取问题文本和检测文本的方式可以有多种,例如,具体可以是通过用户在智能搜索场景下的搜索操作得到,譬如网页搜索、应用程序(app)内搜索等,也可以是通过在自动问答场景下对用户的语音提问进行语音识别得到,譬如智能语音助手,等等。
其中,通过用户的搜索操作获取到问题文本和检测文本,可以是通过直接搜索(即直接在搜索控件中输入问题和检测文本名)获取到问题文本和检测文本,或者是通过搜索结果增强(即在已给定检测文本的情况下,在搜索控件中输入问题)获取到检测文本和问题文本。
可选的,通过对用户的语音提问进行语音识别获取到问题文本和检测文本,可以是在已给定检测文本的情况下,通过对用户的语音提问进行语音识别从而得到问题文本。
其中,为了应对检测文本长度超过预设阈值的情况,可以将检测文本划分为多个检测子文本,例如,具体可以通过在检测文本上构建文本窗口(文本窗口长度小于预设阈值),按照预设步长(预设步长小于文本窗口长度)对文本窗口进行滑动(滑动方向为预设方向),每滑动一个步长,便可得到一个检测子文本,从而将检测文本划分为多个检测子文本。
其中,该预设阈值、预设步长和预设方向均可以根据实际应用的需求进行设置,比如,可以将预设阈值设置为512,文本窗口长度为400,预设步长设置为200,预设方向为向右,等等,在此不再赘述。
102、构建问题文本中第一字单元的第一特征向量、检测子文本中第二字单元的第二特征向量。例如,具体可以如下:
(1)分别对问题文本和检测子文本进行字单元切分,得到问题文本的第一字单元、检测子文本的第二字单元。
其中,字单元可以为文本在中文表示下的每个字或是每一个词,在本申请实施例中对问题文本和检测子文本进行字单元切分,是为获取问题文本和检测子文本中的每一个字。
例如,具体可以分别对问题文本和检测子文本中的每一个字为单元进行切分,得到问题文本中的每一个字,组成问题文本的第一字单元,和检测子文本中的每一个字,组成检测子文本的第二字单元。
(2)分别对问题文本的第一字单元和检测子文本的第二字单元进行编码,得到第一字单元的第一字单元向量、第二字单元的第二字单元向量。
本申请实施例可以通过预训练语言模型来对问题文本的第一字单元和检测子文本的第二字单元进行编码,从而得到问题文本的第一字单元中每个字的向量表示和检测子文本的第二字单元中每个字的向量表示。
在本申请实施例中,为了提升文本输出的准确性,可以通过bert模型对问题文本的第一字单元和检测子文本的第二字单元分别进行编码,从而得到第一字单元向量和第二字单元向量。
其中,bert模型是一种利用海量文本获取语言的预训练语言模型,拥有较强的语义表示能力,可以取得更高的精准度。通过bert模型对问题文本的第一字单元和检测子文本的第二字单元进行编码,得到第一字单元向量和第二字单元向量。参见图1c,第一字单元中的每一个字为tokq1、tokq2……tokqn,第二字单元中的每一个字为tokd1、tokd2……tokdn,将第一字单元中的每一个字采用向量表示为eq1、eq2……eqn,将第二字单元中的每一个字采用向量表示为ed1、ed2……edn。使用bert模型对采用向量表示后的第一字单元和第二字单元分别进行编码,得到第一字单元中每个字的输出向量tq1、tq2……tqn,和第二字单元中每个字的输出向量td1、td2……tdn。
其中,为对第一字单元和第二字单元进行分类标志,可以在二者的首尾和中间位置加入特殊符号(如[cls]和[sep])进行拼接,共同作为bert模型的输入,如图1c所示,bert模型的输入为[cls]、第一字单元(tokq1、tokq2……tokqn)、[sep]、第二字单元(tokd1、tokd2……tokdn)和[sep]。
(3)将第一字单元向量和第二字单元向量分别与预设匹配特征进行融合,得到问题文本中第一字单元的第一特征向量、检测子文本中第二字单元的第二特征向量。例如,具体可以如下:
获取预设匹配特征,该预设匹配特征包括子领域特征、词性特征和词汇重叠特征;
将预设匹配特征使用向量进行表示,得到子领域特征向量、词性特征向量和词汇重叠特征向量;
将第一字单元向量和第二字单元向量分别与子领域特征向量、词性特征向量和词汇重叠特征向量进行融合,得到问题文本中第一字单元的第一特征向量、检测子文本中第二字单元的第二特征向量,参见图1c。
其中,子领域特征用来标志问题文本和检测子文本所属领域的子领域特征,比如,以法律裁判文书为例,所属领域为司法领域,司法领域中又可以分为民法、刑法和行政法等子领域。词性特征用来标志问题文本和检测子文本中字单元的词性,包括名词、动词和形容词等20个类别。词汇重叠特征用来标志第一字单元中的字是否出现在第二字单元中,或第二字单元中的字是否出现在第一字单元中。对子领域特征、词性特征和词汇重叠特征使用向量进行表示,得到子领域特征向量、词性特征向量和词汇重叠特征向量。将第一字单元向量和第二字单元向量分别与子领域特征向量、词性特征向量和词汇重叠特征向量进行首尾拼接,得到第一特征向量和第二特征向量。
103、分别对第一特征向量、第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量。
在本申请实施例中,为了提高文本输出的精准度,在构建第一特征向量和第二特征向量的基础上,可以采用高速路神经网络(highwaynetworks)对第一特征向量和第二特征向量进行非线性处理,参见图1c,具体可以包括:
采用高速路神经网络对第一特征向量和第二特征向量进行非线性变换,得到变换后第一特征向量、变换后第二特征向量;
采用高速路神经网络对第一特征向量和第二特征向量进行比例更新,得到更新后第一特征向量、更新后第二特征向量;
采用高速路神经网络将变换后第一特征向量与更新后第一特征向量进行融合,得到处理后第一特征向量;将变换后第二特征向量与更新后第二特征向量进行融合,得到处理后第二特征向量。
例如,参见图1d,将第一特征向量和第二特征向量共同作为高速路神经网络的输入fi,首先对第一特征向量和第二特征向量进行非线性变换:
trans(fi)=relu(wtr·fi)
使用高速路神经网络对第一特征向量和第二特征向量进行比例更新:
gate(fi)=σ(wg·fi)
其中,relu()表示激活函数,σ()表示sigmoid激活函数,wg和wtr为可训练权重参数矩阵。步骤“采用高速路神经网络将变换后第一特征向量与更新后第一特征向量进行融合,得到处理后第一特征向量;将变换后第二特征向量与更新后第二特征向量进行融合,得到处理后第二特征向量”,具体可以采用如下公式将变换后第一特征向量与更新后第一特征向量进行融合、变换后第二特征向量与更新后第二特征向量进行融合,从而得到处理后第一特征向量和处理后第二特征向量,记为hi:
104、分别对处理后第一特征向量、处理后第二特征向量进行特征提取,得到第一字单元的第一目标特征向量、第二字单元的第二目标特征向量。
其中,对处理后第一特征向量、处理后第二特征向量进行特征提取的方式可以有多种,例如,可以采用循环神经网络对处理后第一特征向量、处理后第二特征向量进行特征提取。为了使得特征提取的准确度更高,同时减少计算的复杂度,具体可以使用门控循环单元网络(gru,gatedrecurrentunit)对处理后第一特征向量、处理后第二特征向量进行特征提取。参见图1c,具体可以使用门控循环单元网络分别对处理后第一特征向量和处理后第二特征向量进行正向传递操作,从而得到第一字单元的第一正向传递结果向量和第二字单元的第二正向传递结果向量,记为
使用gru网络对处理后第一特征向量和处理后第二特征向量进行反向传递操作,得到第一字单元的第一反向传递结果向量和第二字单元的第二反向传递结果向量,记为
其中,hi处理后第一特征向量和处理后第二特征向量的汇总。使用gru网络将第一字单元的第一正向传递结果向量与第一字单元的第一反向传递结果向量进行连接,将第二字单元的第二正向传递结果向量与第二字单元的第二反向传递结果向量进行连接,得到第一字单元的第一目标特征向量和第二字单元的第二目标特征向量,第一目标向量和第二目标向量记为gi,进行连接的公式如下:
105、根据第一字单元的第一目标特征向量和第二字单元的第二目标特征向量,预测第一字单元的第一概率、第二字单元的第二概率,其中,第一概率为第一字单元为候选答案起止字单元的概率,第二概率为第二字单元为候选答案起止字单元的概率。例如,参见图1c,具体可以如下:
使用全连接网络对第一字单元的第一目标特征向量和第二字单元的第二目标特征向量进行线性变换,得到变换后第一目标特征向量、变换后第二目标特征向量;
基于变换后第一目标特征向量和变换后第二目标特征向量,使用全连接网络对第一字单元和第二字单元进行分类,得到第一字单元的第一概率、第二字单元的第二概率,其中,第一概率为第一字单元为候选答案起止字单元的概率,第二概率为第二字单元为候选答案起止字单元的概率。
比如,可以使用全连接网络对第一字单元的第一目标特征向量和第二字单元的第二目标特征向量采用如下公式进行线性变换,得到变换后第一目标特征向量和变换后第二目标特征向量,记为p:
p=wp·gi,p∈r2×t
其中,wp为可训练权重参数矩阵,gi为第一目标特征向量和第二目标特征向量的汇总。使用全连接网络对变换后第一目标特征向量和变换后第二目标特征向量进行分类,从而得到第一字单元中每个字为候选答案的起止字的概率,和第二字单元中每个字为候选答案的起止字的概率,即第一字单元和第二字单元中的每个字都有两个概率,这两个概率分别是作为候选答案起始字的概率和终止字的概率。以问题文本“张三因何借款”为例,问题文本中的每一个字(“张”、“三”、“因”、“何”、“借”、“款”)都有两个位置概率,即作为答案起始字的位置概率和答案终止字的位置概率。
106、基于第一字单元的第一概率和第二字单元的第二概率,确定并输出问题文本对应的答案文本。例如,具体可以包括:
根据第一概率和第二概率,从第一字单元和第二字单元中,确定答案起始字单元和答案终止字单元;
根据答案起始字单元和答案终止字单元,构建问题文本对应的答案文本,并输出所述答案文本。
比如,参见图1c,在得到第一字单元和第二字单元中每个字作为答案文本起止字的概率分布情况后,选取起始位置概率最高的字作为候选答案的起始字、选取终止位置概率最高的字作为候选答案的终止字,抽取并输出起始字和终止字之间(包括起始字和终止字)连续的内容作为问题文本所对应的候选答案文本。
在一些实施例中,为应对检测文本超过预设阈值的情况,可以将检测文本划分为多个检测子文本,因此,问题文本和多个检测子文本最终会产生多个候选答案,每个候选答案都包含起始字的位置概率和终止字的位置概率,在多个候选答案中,选择起始位置概率最高的字为答案文本的起始字、选取终止位置概率最高的字为答案文本的终止字,通过起始字和终止字,抽取并输出起始字和终止字之间(包括起始字和终止字)连续的文本内容作为问题文本所对应的答案文本。需要说明的是,在此过程中,排除起始位置的字在终止位置的字之后的情况。
由上可知,本申请实施例可以获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。由于该方案在原有输入的文本信息的基础上,通过引入一系列匹配特征与原有输入进行融合作为对输入文本信息的增强,并对引入匹配特征后的输入文本信息进行非线性处理以及特征提取,从而可以更好地提取问题文本与检测文本间的语义特征信息,使得文本输出的精准度大大提高。
根据上述实施例所描述的方法,以下将举例作进一步详细说明。
在本实施例中,将以该文本输出装置具体集成在计算机设备中为例进行说明。
如图2a所示,一种文本输出方法,具体流程可以如下:
201、计算机设备获取问题文本和检测文本。
其中,计算机设备获取问题文本和检测文本的方式可以有多种,例如,具体可以是通过用户在计算机设备如终端的搜索操作得到,譬如网页搜索、应用程序(app)内搜索等,也可以是通过在自动问答场景下对用户的语音提问进行语音识别得到,譬如智能语音助手,等等。
其中,通过用户的搜索操作获取到问题文本和检测文本,可以是通过直接搜索(即直接在搜索控件中输入问题和检测文本名)获取到问题文本和检测文本,或者是通过搜索结果增强(即在已给定检测文本的情况下,在搜索控件中输入问题)获取到检测文本和问题文本。例如,以基于法律裁判文书的搜索为例,如图2b所示,当用户在搜索控件中输入问题和法律裁判文书名称并触发“搜索”控件,计算机设备便可以通过用户的触发操作获取问题文本(如“张三因何借款”)和检测文本,检测文本为用户指定的法律裁判文书(如:(2019)京01民终0000号案件)。可选的,计算机设备还可以在已指定法律裁判文书下,通过用户在搜索控件中输入问题,并触发控件,便可获取到问题文本。例如,当前案件为(2019)京01民终0000号案件,用户可以在搜索控件中输入问题,所输入的问题即为问题文本,当前案件即为检测文本。
可选的,通过对用户的语音提问进行语音识别获取到问题文本和检测文本,可以是在已给定检测文本的情况下,通过对用户的语音提问进行语音识别从而得到问题文本,例如,如图2c所示,在某个终端应用如智能助手中,在已指定当前案件的情况下,通过将用户发送的语音转化为文本从而得到问题文本,检测文本为已指定的当前案件。比如,语音内容为:“张三因何借款?”即为问题文本,(2019)京01民终0000号案件即为检测文本;或者,还可以通过对用户手动输入问题如“借了几次?多少钱?”获取到问题文本。
202、计算机设备将该检测文本划分为多个检测子文本。
在一实施例中,为了应对检测文本超过预设阈值的情况,计算机设备可以将检测文本划分为多个检测子文本,例如,具体可以通过在检测文本上构建文本窗口(文本窗口长度小于预设阈值),按照预设步长(预设步长小于文本窗口长度)对文本窗口进行滑动(滑动方向为预设方向),每滑动一个步长,便可得到一个检测子文本,从而将检测文本划分为多个检测子文本。如图2d所示,具体可以通过在检测文本上构建文本窗口(文本窗口的长度为w),按照预设步长(步长为s)对文本窗口按照预设方向如向右进行滑动,每滑动一个步长,便可得到一个检测子文本,从而将检测文本划分为多个检测子文本。其中,文本窗口长度w应小于预设阈值,步长s小于文本窗口长度w。比如,文本窗口长度为5,步长为2时,表示,先处理第1-5个字,再处理第3-7个字,然后处理第5-9个字,依此类推。
由于在使用bert模型对问题文本和检测文本进行编码的过程中,该模型每次所能处理的文本长度不超过512个字,难以应对长文本的处理。因此,在本申请实施例中,通过构建滑动文本窗口,将检测文本划分为多个检测子文本,使输入的文本长度在bert模型所能处理的长度范围内,从而改进原始模型的不足,使得可以具有处理长文本的能力。
203、计算机设备对问题文本的第一字单元和检测子文本的第二字单元进行编码,得到第一字单元的第一字单元向量、第二字单元的第二字单元向量。
其中,对问题文本的第一字单元和检测子文本的第二字单元进行编码之前,计算机设备分别对问题文本和检测子文本进行字单元切分,得到问题文本的第一字单元、检测子文本的第二字单元。计算机设备通过bert模型对问题文本的第一字单元和检测子文本的第二字单元进行编码,得到第一字单元向量和第二字单元向量。参见图1c,第一字单元中的每一个字为tokq1、tokq2……tokqn,第二字单元中的每一个字为tokd1、tokd2……tokdn,将第一字单元中的每一个字采用向量表示为eq1、eq2……eqn,将第二字单元中的每一个字采用向量表示为ed1、ed2……edn。使用bert模型对采用向量表示后的第一字单元和第二字单元分别进行编码,得到第一字单元中每个字的输出向量tq1、tq2……tqn,作为第一字单元向量,得到第二字单元中每个字的输出向量td1、td2……tdn,作为第二字单元向量。
其中,为对第一字单元和第二字单元进行分类标志,可以在二者的首尾和中间位置加入特殊符号(如[cls]和[sep])进行拼接,共同作为bert模型的输入,如图1c所示,bert模型的输入为[cls]、第一字单元(tokq1、tokq2……tokqn)、[sep]、第二字单元(tokd1、tokd2……tokdn)、[sep]。
204、计算机设备将第一字单元向量和第二字单元向量分别与预设匹配特征进行融合,得到问题文本中第一字单元的第一特征向量、检测子文本中第二字单元的第二特征向量。
在本申请实施例中,为了提高文本输出的精准度,计算机设备通过引入预设匹配特征,将预设匹配特征与输入的文本信息进行融合,使得对原有的输入信息进行增强,以便后续更好的提取所输入文本的语义特征信息,具体可以如下:
计算机设备获取预设匹配特征,该预设匹配特征包括子领域特征、词性特征和词汇重叠特征;
将预设匹配特征使用向量进行表示,得到子领域特征向量、词性特征向量和词汇重叠特征向量;
将第一字单元向量和第二字单元向量分别与子领域特征向量、词性特征向量和词汇重叠特征向量进行融合,得到问题文本中第一字单元的第一特征向量、检测子文本中第二字单元的第二特征向量,参见图1c。
其中,子领域特征用来标志问题文本和检测子文本所属领域的子领域特征,比如,以法律裁判文书为例,所属领域为司法领域,司法领域中又可以分为民法、刑法和行政法等子领域,例如,可以使用固定的10维向量进行表示,记为vfdom。词性特征用来标志问题文本和检测子文本中字单元的词性,包括名词、动词和形容词等20个类别,例如,可以使用固定的10维向量进行表示,记为vfpos。词汇重叠特征用来标志第一字单元中的字是否出现在第二字单元中,或第二字单元中的字是否出现在第一字单元中,例如,可以使用1维向量进行表示,记为vfmat,如果问题文本中的第i个字的字单元向量tqi也出现在检测子文本中,我们就将设置vfmat,qi=[1],否则设置vfmat,qi=[0]。同理如果检测子文本中的第i个字的字单元向量tdi也出现在问题文本中,我们就将设置vfmat,di=[1],否则设置vfmat,di=[0]。将第一字单元向量和第二字单元向量分别与子领域特征向量、词性特征向量和词汇重叠特征向量进行融合,可以是将第一字单元向量和第二字单元向量分别与子领域特征向量vfdom、词性特征向量vfpos和词汇重叠特征向量vfmat进行首尾拼接,从而得到第一特征向量和第二特征向量。
205、计算机设备分别对第一特征向量和第二特征向量进行非线性处理,得到处理后第一特征向量和处理后第二特征向量。
例如,参见图1c,计算机设备具体可以采用高速路神经网络(highwaynetworks)对第一特征向量和第二特征向量进行非线性处理,具体的非线性处理过程可以参考图1d以及上述的相关描述。
206、计算机设备分别对处理后第一特征向量和处理后第二特征向量进行特征提取,得到第一字单元的第一目标特征向量和第二字单元的第二目标特征向量。
其中,对处理后第一特征向量、处理后第二特征向量进行特征提取的方式可以有多种,例如,可以采用循环神经网络对处理后第一特征向量、处理后第二特征向量进行特征提取。为了使得特征提取的准确度更高,同时也能减少计算的复杂度,具体可以使用门控循环单元网络(gru,gatedrecurrentunit)对处理后第一特征向量、处理后第二特征向量进行特征提取。参见图1c,具体的特征提取过程可以参考上述的相关描述。
207、计算机设备根据第一字单元的第一目标特征向量和第二字单元的第二目标特征向量,预测第一字单元的第一概率、第二字单元的第二概率,其中,第一概率为第一字单元为候选答案起止字单元的概率,第二概率为第二字单元为候选答案起止字单元的概率。例如,参见图1c,具体的答案预测过程可以参考上述的相关描述。
208、计算机设备基于第一字单元的第一概率和第二字单元的第二概率,确定并输出问题文本对应的答案文本。例如,具体可以如下:
在一实施例中,计算机设备根据第一概率和第二概率,从第一字单元和第二字单元中,确定答案起始字单元和答案终止字单元;
在一实施例中,计算机设备根据答案起始字单元和答案终止字单元,构建问题文本对应的答案文本,并输出所述答案文本。
其中,在得到第一字单元和第二字单元中每个字作为答案文本起止字的概率分布情况后,选取起始位置概率最高的字作为候选答案的起始字、选取终止位置概率最高的字作为候选答案的终止字,抽取并输出起始字和终止字之间(包括起始字和终止字)连续的内容作为问题文本所对应的候选答案文本。
例如,参见图2b,问题文本“张三因何借款”对应的答案为“由于资金周转困难”。其中,“由”和“难”为答案的起始字和终止字,抽取起始字“由”和终止字“难”之间连续的文本内容为候选答案文本。参见图2c,当用户所提问题为“借了几次?多少钱?”,终端则给出所对应的答案为“分别于2012年3月15日向原告李四借款20000元;于2012年5月15日向原告李四借款15000元”。
在一实施例中,为应对检测文本超过预设阈值的情况,可以将检测文本划分为多个检测子文本,因此,问题文本和多个检测子文本最终会产生多个候选答案,每个候选答案都包含起始字的位置概率和终止字的位置概率,在多个候选答案中,选择起始位置概率最高的字为答案文本的起始字、选取终止位置概率最高的字为答案文本的终止字,通过起始字和终止字,抽取并输出起始字和终止字之间(包括起始字和终止字)连续的内容作为问题文本所对应的答案文本。需要说明的是,在此过程中,排除起始位置的字在终止位置的字之后的情况。
在一实施例中,本申请实施例还可以将本申请实施例提供的文本输出方案以云服务的形式实现,具体地,可以在云服务器上实现。在实际应用中,云服务可以提供应用程序接口(api,applicationprogramminginterface)供用户终端使用,以调用云服务侧的文本输出方法来实现问题的答案文本输出等。在一些实施例中,为了便于使用,可以将api集成至某个软件开发工具包(sdk,softwaredevelopmentkit)中。
其中,api的输入参数和输出参数可以根据实际需求来设定,比如,参考表1,为一实施例中提供的api输入参数的描述。例如,作为api时的输入参数可以为:
表1
参考表2,为一实施例中提供的api输出参数的描述,例如,作为api时的输出参数可以为:
输出参数
表2
计算机设备如终端可以将问题文本和检测文本作为api的输入,从而通过api实现问题文本所对应的答案文本的输出。
由上可知,本申请实施例可以获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。由于该方案在原有输入的文本信息的基础上,通过引入一系列匹配特征与原有输入进行融合作为对输入文本信息的增强,并对引入匹配特征后的输入文本信息进行非线性处理以及特征提取,从而可以更好地提取问题文本与检测文本间的语义特征信息,使得文本输出的精准度大大提高。
为便于更好地实施以上方法,本申请实施例还提供了一种文本输出装置,该文本输出装置可以集成在计算机设备,比如服务器或终端等设备中。
例如,如图3a所示,该文本输出装置可以包括获取单元301、特征构建单元302、处理单元303、特征提取单元304、预测单元305和确定单元306等,如下:
获取单元301,用于获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;
特征构建单元302,用于构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;
处理单元303,用于分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;
特征提取单元304,用于分别对所述处理后第一特征向量、处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;
预测单元305,用于根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;
确定单元306,用于基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。
在一些实施例中,参考图3b,所述特征构建单元302,包括:
切分子单元3021,用于分别对所述问题文本和所述检测子文本进行字单元切分,得到所述问题文本的第一字单元、所述检测子文本的第二字单元;
编码子单元3022,用于分别对所述问题文本的第一字单元和所述检测子文本的第二字单元进行编码,得到第一字单元的第一字单元向量、第二字单元的第二字单元向量;
融合子单元3023,用于将所述第一字单元向量和第二字单元向量分别与预设匹配特征进行融合,得到所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量。
在一些实施例中,所述融合子单元3023,用于:
获取预设匹配特征,所述预设匹配特征包括子领域特征、词性特征和词汇重叠特征;
将所述预设匹配特征使用向量进行表示,得到子领域特征向量、词性特征向量和词汇重叠特征向量;
将所述第一字单元向量和第二字单元向量分别与子领域特征向量、词性特征向量和词汇重叠特征向量进行融合,得到所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量。
在一些实施例中,所述处理单元303,用于:
采用高速路神经网络对所述第一特征向量和所述第二特征向量进行非线性变换,得到变换后第一特征向量、变换后第二特征向量;
采用高速路神经网络对所述第一特征向量和所述第二特征向量进行比例更新,得到更新后第一特征向量、更新后第二特征向量;
采用高速路神经网络将变换后第一特征向量与更新后第一特征向量进行融合,得到处理后第一特征向量;将变换后第二特征向量与更新后第二特征向量进行融合,得到处理后第二特征向量。
在一些实施例中,所述特征提取单元304,用于:
采用循环神经网络分别对所述处理后第一特征向量和所述处理后第二特征向量进行正向传递操作,得到所述第一字单元的第一正向传递结果向量、所述第二字单元的第二正向传递结果向量;
采用循环神经网络分别对所述处理后第一特征向量和所述处理后第二特征向量进行反向传递操作,得到所述第一字单元的第一反向传递结果向量、所述第二字单元的第二反向传递结果向量;
采用循环神经网络将所述第一字单元的第一正向传递结果向量与所述第一字单元的第一反向传递结果向量进行连接,得到所述第一字单元的第一目标特征向量;将所述第二字单元的第二正向传递结果向量与所述第二字单元的第二反向传递结果向量进行连接,得到所述第二字单元的第二目标特征向量。
在一些实施例中,所述预测单元305,用于:
使用全连接网络对所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量进行线性变换,得到变换后第一目标特征向量、变换后第二目标特征向量;
基于变换后第一目标特征向量和变换后第二目标特征向量,使用全连接网络对所述第一字单元和所述第二字单元进行分类,得到所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率。
在一些实施例中,参考图3c,所述确定单元306,包括:
确定子单元3061,用于根据所述第一概率和所述第二概率,从所述第一字单元和所述第二字单元中,确定答案起始字单元和答案终止字单元;
本文构建子单元3062,用于根据答案起始字单元和答案终止字单元,构建所述问题文本对应的答案文本,并输出所述答案文本。
在一些实施例中,参考图3d,所述获取单元301,包括:
文本获取子单元3011,用于获取问题文本和检测文本;
文本划分子单元3012,用于将所述检测文本划分为多个检测子文本。
在一些实施例中,所述文本划分子单元3012,用于:
在所述检测文本上构建文本窗口;
按照预设步长对文本窗口进行滑动,以将所述检测文本划分为多个检测子文本。
具体实施时,以上各个单元可以作为独立的实体来实现,也可以进行任意组合,作为同一或若干个实体来实现,以上各个单元的具体实施可参见前面的方法实施例,在此不再赘述。
由上可知,本发明实施例的文本输出装置可以通过获取单元301获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;由特征构建单元302构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;由处理单元303分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;由特征提取单元304分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;由预测单元305根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;由确定单元306基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。由于该方案在原有输入的文本信息的基础上,引入一系列匹配特征与原有输入进行融合作为对输入文本信息的增强,并对引入匹配特征后的输入文本信息进行非线性处理以及特征提取,从而可以更好地提取问题文本与检测文本间的语义特征信息,使得文本输出的精准度大大提高。
本申请实施例还提供一种计算机设备,如图4所示,其示出了本申请实施例所涉及的计算机设备的结构示意图,具体来讲:
该计算机设备可以包括一个或者一个以上处理核心的处理器401、一个或一个以上计算机可读存储介质的存储器402、电源403和输入单元404等部件。本领域技术人员可以理解,图4中示出的计算机设备结构并不构成对计算机设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。其中:
处理器401是该计算机设备的控制中心,利用各种接口和线路连接整个计算机设备的各个部分,通过运行或执行存储在存储器402内的软件程序和/或模块,以及调用存储在存储器402内的数据,执行计算机设备的各种功能和处理数据,从而对计算机设备进行整体监控。可选的,处理器401可包括一个或多个处理核心;优选的,处理器401可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器401中。
存储器402可用于存储软件程序以及模块,处理器401通过运行存储在存储器402的软件程序以及模块,从而执行各种功能应用以及数据处理。存储器402可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、影像播放功能等)等;存储数据区可存储根据计算机设备的使用所创建的数据等。此外,存储器402可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。相应地,存储器402还可以包括存储器控制器,以提供处理器401对存储器402的访问。
计算机设备还包括给各个部件供电的电源403,优选的,电源403可以通过电源管理系统与处理器401逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。电源403还可以包括一个或一个以上的直流或交流电源、再充电系统、电源故障检测电路、电源转换器或者逆变器、电源状态指示器等任意组件。
该计算机设备还可包括输入单元404,该输入单元404可用于接收输入的数字或字符信息,以及产生与用户设置以及功能控制有关的键盘、鼠标、操作杆、光学或者轨迹球信号输入。
尽管未示出,计算机设备还可以包括显示单元等,在此不再赘述。具体在本实施例中,计算机设备中的处理器401会按照如下的指令,将一个或一个以上的应用程序的进程对应的可执行文件加载到存储器402中,并由处理器401来运行存储在存储器402中的应用程序,从而实现各种功能,如下:
获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。
以上各个操作具体可参见前面的实施例,在此不作赘述。
由上可知,本申请实施例可以获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。由于该方案在原有输入的文本信息的基础上,引入一系列匹配特征与原有输入进行融合作为对输入文本信息的增强,并对引入匹配特征后的输入文本信息进行非线性处理以及特征提取,从而可以更好地提取问题文本与检测文本间的语义特征信息,使得文本输出的精准度大大提高。
本领域普通技术人员可以理解,上述实施例的各种方法中的全部或部分步骤可以通过指令来完成,或通过指令控制相关的硬件来完成,该指令可以存储于一计算机可读存储介质中,并由处理器进行加载和执行。
为此,本申请实施例提供一种计算机可读存储介质,其中存储有计算机程序,该计算机程序能够被处理器进行加载,以执行本申请实施例所提供的任一种文本输出方法中的步骤。例如,该计算机程序可以执行如下步骤:
获取问题文本和检测文本,将所述检测文本划分为多个检测子文本;构建所述问题文本中第一字单元的第一特征向量、所述检测子文本中第二字单元的第二特征向量;分别对所述第一特征向量、所述第二特征向量进行非线性处理,得到处理后第一特征向量、处理后第二特征向量;分别对所述处理后第一特征向量、所述处理后第二特征向量进行特征提取,得到所述第一字单元的第一目标特征向量、所述第二字单元的第二目标特征向量;根据所述第一字单元的第一目标特征向量和所述第二字单元的第二目标特征向量,预测所述第一字单元的第一概率、所述第二字单元的第二概率,其中,所述第一概率为所述第一字单元为候选答案起止字单元的概率,所述第二概率为所述第二字单元为候选答案起止字单元的概率;基于所述第一字单元的第一概率和所述第二字单元的第二概率,确定并输出所述问题文本对应的答案文本。
以上各个操作的具体实施可参见前面的实施例,在此不再赘述。
其中,该计算机可读存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取记忆体(ram,randomaccessmemory)、磁盘或光盘等。
由于该计算机可读存储介质中所存储的指令,可以执行本申请实施例所提供的任一种文本输出方法中的步骤,因此,可以实现本申请实施例所提供的任一种文本输出方法所能实现的有益效果,详见前面的实施例,在此不再赘述。
以上对本申请实施例所提供的一种文本输出方法、装置、计算机设备和计算机可读存储介质进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!