具有分类精度保持和带宽保护的边云协同深度学习模型训练方法与流程
本发明属于人工智能领域,具体涉及一种具有分类精度保持和带宽保护的边云协同深度学习模型训练方法。
背景技术:
不断增长的边缘计算范式已经成为将深度学习应用于更广泛的实践领域的最有前景的方法之一,并且在在网络带宽节省、延迟减少和隐私保护方面显示出巨大的优势。传统集中式云计算常用于训练高精度深学习模型,例如深层神经网络,然而,数据上云造成的带宽压力造成云上难以汇聚到全局的数据。使用分布式边缘计算范式,边缘服务器从附近的终端节点获取图像、视频等原始数据,在没有大规模原始数据上传的情况下进行本地学习,以减少边缘和云端之间的带宽消耗,然而,在真实场景中边缘节点有着资源的限制,训练高精度的模型是难以实现的。基于边缘服务器上的本地学习和云上的协作是必要的,同时我们需要实现在带宽消耗和模型精度之间进行权衡的方案。对于边缘云协作式深度学习,在保证模型准确性的同时降低带宽消耗,一种直观的方法是在将原始数据上传到云之前压缩边缘服务器上的数据。通常,数据压缩可以是无损的,也可以是有损的。无损压缩方法完全地保留了数据信息,但在减小数据大小方面能力有限,无法缓解协同学习带来的带宽压力。有损压缩方法以丢失数据细节为代价,可以显著的地减小数据大小,但会对此类压缩数据训练的模型的准确性产生影响。开发一种数据压缩方法是至关重要的,数据压缩后上传云端可以有效减少边云带宽压力,同时有选择地保留有价值的细节,以便进行准确的模型训练。
技术实现要素:
本发明的目的在于克服上述现有技术的缺点,提供了一种具有分类精度保持和带宽保护的边云协同深度学习模型训练方法,该方法实现了一种对分类目标具有高可用性的压缩方法,和边云协同训练的方案,并且提供了控制压缩率的方法,可以在同一个深度学习压缩自编码器中实现不同的压缩率,切换压缩率是只有极小的fine-tune成本。
为达到上述目的,本发明采用如下技术方案来实现的:
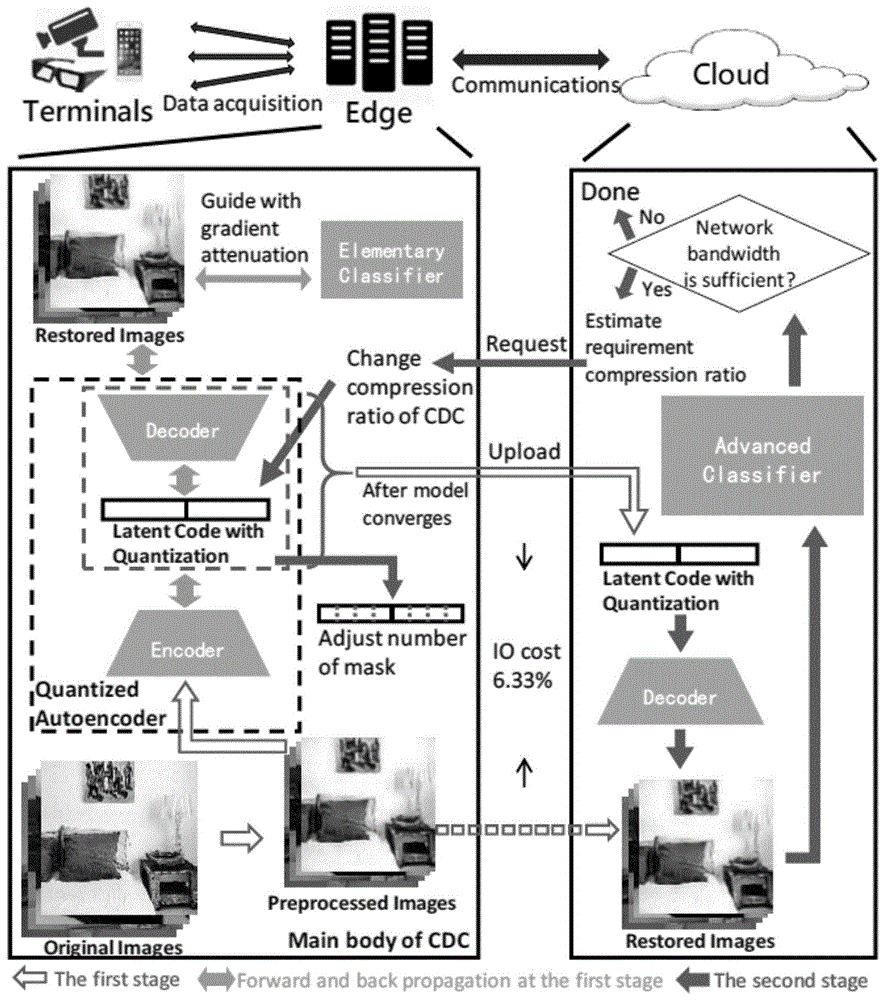
具有分类精度保持和带宽保护的边云协同深度学习模型训练方法,包括两个阶段。阶段一在边缘端训练简单的模型处理数据,并将数据上传云端。阶段二,在云端上训练具有高分类精度的模型,权衡网络情况与模型精度,对边缘的压缩率进行调整。具体包括以下步骤:
阶段一:
1)利用边缘节点上汇聚的终端数据,使用一个量化压缩自编码器和一个分类器,将分类器接在自编码器之后使分类器的梯度可以反向传播到自编码器,来指导自编码器的训练,使分类器与自编码器在同一学习率下进行训练,并设定模型常规超参数;
2)压缩自编码器加入量化操作,设定一个控制压缩率的掩码m;训练过程中利用分类器对自编码器进行指导,设定一个控制分类器指导能力的衰减率α,在边缘端上进行模型训练,得到一个针对分类目标的压缩自编码器;
3)在边缘上的压缩自编码器模型训练完成后,使用得到的压缩自编码器,将当前边缘上有的全部数据,经由训练出的编码器部分压缩成量化后的比特向量;
4)将自编码器的解码器模型结构、参数与量化压缩后的边缘数据及标签,经过边云间的通信网络,由边缘端上传到云端,在云端进行存储,为第二阶段进行准备;
阶段二:
5)云端汇聚边缘端的数据并将其保存后,统一进行读取,并用各自边缘上传数据所携带的解码器进行解码,尽可能的还原数据原貌,同时也还原了数据原本的结构;
6)以解码后的数据作为输入数据,同时使用边缘上传的相应数据标签,选用一个大规模、高精度、资源需求大的主流深度学习分类器,给这一复杂分类器模型设定相应超参数后,利用云上强大的计算资源训练具有更高精度的分类器,训练至模型收敛,测试精度;
7)评估边缘和云之间的带宽情况和分类模型精度需求,参照上一步得到的测试精度,对精度和带宽进行权衡,来调整边缘压缩自编码器的压缩率。
本发明的进一步改进在于,提出分类驱动压缩(cdc)的方法,使用分类目标去指导压缩过程,将自编码器(a)和分类器(c)联合训练,输入t条数据
lf=la(ha(x),x)+lc(hc(ha(x)),y)
本发明的进一步改进在于,为了控制分类器给自编码器影响的程度,加入衰减率来控制训练中的指导过程,衰减率α的条件下,得到的联合训练的损失函数lf为
本发明的进一步改进在于,在梯度反向传播过程中,联合损失函数只对自编码器产生作用,而分类器只受到自身梯度带来的损失函数作用,自编码器(ae)和分类器(ec)的实际用于优化自身参数权重的梯度不同:
本发明的进一步改进在于,带宽调整通过控制量化压缩过程中的掩码值实现,量化过程加在编码器之后,云上的解码器解码前也会经过反量化处理。掩码值为m,且有m∈{0,1,2,3,4},针对编码器最后tanh激活函数的m维输出,量化过程使用随机量化方法,使用随机变量ε∈(-0.5,0.5),对数据的每一维x,量化q与反量化q′的过程,及量化操作q(x)和反量化操作q′(x)计算过程分别为:
q:(-1,1)m→[-24-m+1,...,-1,0,1,...,24-m]m
q′:[-24-m+1,...,-1,0,1,...,24-m]m→(-1,1)m
q′(x)=(x-0.5)/24-m.
边缘节点根据云端的反馈选择适用于当前环境的掩码值m,伴随着m越大,对数据的压缩量越大,带宽节省越多,云端模型的精度越低。
本发明具有如下有益的技术效果:
本发明提供的一种具有分类精度保持和带宽保护的边云协同深度学习模型训练方法,给了边云协同模型训练问题提供了一种高可用性的解决方案。在边缘节点上,使用少量的计算资源完成数据针对分类任务的高可用性压缩,压缩算法提供压缩率的调整方法,并且做到在同一深度学习模型中调整压缩率只需极小的计算资源代价。在云端,利用边缘压缩的数据训练高精度的分类模型,同时通过评估网络情况来进行精度和带宽消耗的折中,选择合适的压缩率。该方法在利用分类指导实现针对分类目标的数据压缩前提下,同时实现模型精度和带宽消耗的折中,给解决边云协同深度学习模型训练问题提供了可靠的方案。
附图说明
图1为边云协同训练过程整体框架及流程示意图;
图2为边缘端深度学习模型结构图;
图3为自编码器分类器连接关系图
图4为压缩图像视觉结果对照图
图5为衰减率作用效果图(左:lsun数据集下;右:imagenet子集下)
图6为调整压缩率模型微调过程(左:压缩率逐步下降;右:衰减率逐步提高)
具体实施方式
下面结合附图对本发明作进一步详细描述。
参考图1,考虑数据直接上云带来的带宽负荷难以被网络消化,且在边缘设备上,无法汇聚全局的数据,且无法提供大量的计算资源来支撑高精度模型的训练。提出具有分类精度保持和带宽保护的边云协同深度学习模型训练方法。包括两个阶段,阶段一,在边缘端训练简单的模型处理数据,并将数据上传云端。阶段二,在云端上训练具有高分类精度的模型,权衡网络情况与模型精度,对边缘的压缩率进行调整。具体包括以下步骤:
阶段一:
1)利用边缘节点上汇聚的终端数据,在这里使用大规模场景理解(large-scalesceneunderstanding,lsun)数据集和imagenet数据集的数据,进行大规模场景感知分类任务和物体分类任务的测试,使用一个量化压缩自编码器和一个分类器,将分类器接在自编码器之后使分类器的梯度可以反向传播到自编码器,来指导自编码器的训练,使分类器与自编码器在同一学习率下进行训练,并设定模型常规超参数,如学习率等;
2)压缩自编码器加入量化操作,设定一个控制压缩率的掩码m;训练过程中利用分类器对自编码器进行指导,设定一个控制分类器指导能力的衰减率α,在边缘端上进行模型训练,得到一个针对分类目标的压缩自编码器,在实现过程中,衰减率作用于分类器的输入层上,这一层同时也是自编码器中解码器的输出层;
3)在边缘上的压缩自编码器模型训练完成后,将当前边缘上有的全部数据,即用于训练模型的lsun和imagenet数据集数据,经由训练出的编码器部分压缩成量化后的比特向量;
4)将自编码器的解码器模型结构、参数与量化压缩后的边缘数据及标签,由边缘端上传到云端;
阶段二:
5)云端汇聚边缘端的数据,用边缘上传数据携带的解码器解码,解码边缘上传的数据,还原出lsun数据集和imagenet数据集的数据,同时还原数据原本的结构;
6)以解码后的数据作为输入数据,同时使用边缘上传的相应数据标签,给主流复杂分类器模型设定相应超参数后,利用云上强大的计算资源训练具有更高精度的分类器;
7)评估边缘和云之间的带宽情况和分类模型精度需求,对精度和带宽进行权衡,通过控制掩码值m,来调整边缘压缩自编码器的压缩率。
参考图2,本发明设计了边缘上的深度学习模型结构,重点在于编码器和解码器之间有量化器的插入,量化过程加在编码器之后,云上的解码器解码前也会经过反量化处理。量化器实现时,设置掩码值为m,且有m∈{0,1,2,3,4},边缘节点根据云端的反馈选择适用于当前环境的掩码值m,伴随着m越大,对数据的压缩量越大,带宽节省越多,云端模型的精度越低。针对编码器最后tanh激活函数的m维输出,量化过程使用随机量化方法,使用随机变量ε∈(-0.5,0.5),对数据的每一维x,量化q与反量化q′的计算分别为:
q:(-1,1)m→[-24-m+1,...,-1,0,1,...,24-m]m
q′:[-24-m+1,...,-1,0,1,...,24-m]m→(-1,1)m
q′(x)=(x-0.5)/24-m.
参考图3,利用由分类器指导的压缩自编码器(利用分类结果对压缩自编码器进行微调,使其压缩时更多舍弃与分类无关的信息特征,保留分类关键特征),进行与分类任务强耦合的图像压缩。训练过程如下图所示,将数据输入压缩自编码器进行压缩和还原,还原出的图像同时输入到图像优化器和简单分类器中,将两者反向传播的梯度结合进行自编码器的优化。输入t条数据
参考图4,我们使用大规模场景理解(large-scalesceneunderstanding,lsun)数据集进行完整的边缘端压缩。对比相同压缩率下,原始图片、分类驱动的压缩(cdc)图片、jpeg压缩图片、相同网络结构但无分类指导的压缩自编码器(autoencoder)得到的图片结果,可以看到cdc的压缩结果在视觉上,能明显区提升图自编码器模糊掉的图像细节质量,针对分类目标有效的提升了图像压缩后的质量,且没有传统jpeg的噪点。
参考图5,我们使用大规模场景理解(lsun)数据集,和imagenet数据集中选出的10类子集进行完整的边云协同过程,得到不同衰减率下云端模型的精确度。相同压缩率下,加入指导的压缩自编码器在不同衰减率α下的得到的云端模型精度表现出了随着α先升,后降至不加入指导的水平的趋势,从结果的角度验证了分类器的指导对于后续云端模型在分类工作精度上的作用。
参考图6,我们使用大规模场景理解(lsun)数据集,在模型收敛后进行压缩率的切换,模型不会出现崩溃的情况,而是会在当前基础上快速收敛,此类压缩率的改变方案,相较传统的改变压缩率需要改变整个网络模型方法,在边缘设备这种计算资源不丰富的场景中有着很高的实用价值。
- 还没有人留言评论。精彩留言会获得点赞!