一种基于GoogLeNet-SVM的污水曝气池泡沫识别方法与流程
本发明涉及污水处理领域,尤其是涉及一种基于googlenet-svm的污水曝气池泡沫识别方法。
背景技术:
污水处理企业目前对于曝气池泡沫识别还采用人工检测,人工检测依赖工作人员的经验和行业知识,人才难得,会增加企业的人力成本;同时人工检测中个人的主观决策,在复杂,相近的情况容易带有偏向性,会带来较大偏差。另外长期待在现场会影响工人的身体健康。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供无需人工参与、准确度更高的一种基于googlenet-svm的污水曝气池泡沫识别方法。
本发明的目的可以通过以下技术方案来实现:
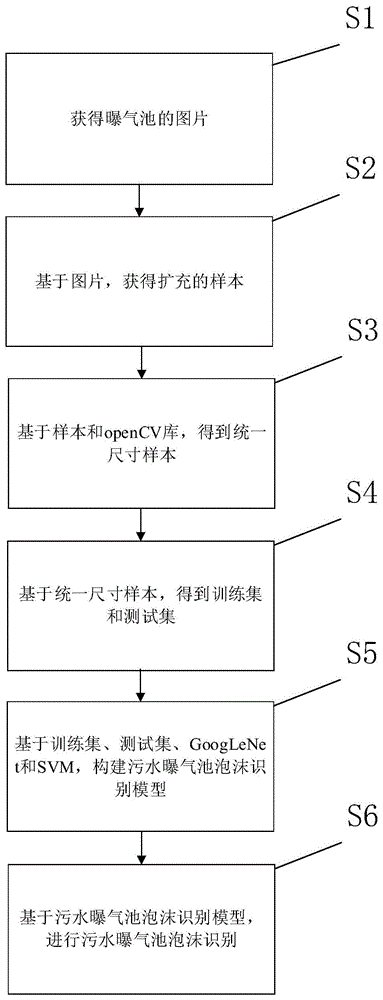
一种基于googlenet-svm的污水曝气池泡沫识别方法,该方法包括以下步骤:
步骤s1:获得曝气池的图片;
步骤s2:基于图片,获得扩充的样本;
步骤s3:基于样本和opencv库,得到统一尺寸样本;
步骤s4:基于统一尺寸样本,得到训练集和测试集;
步骤s5:基于训练集、测试集、googlenet和svm,构建污水曝气池泡沫识别模型;
步骤s6:基于污水曝气池泡沫识别模型,进行污水曝气池泡沫识别。
所述的步骤s2中的扩充过程包括将图片进行翻转、向图片加入椒盐噪声、将图片进行分割和向图片添加光照。
所述的步骤s4对统一尺寸样本进行零均值化,得到训练集和测试集。
所述的步骤s5污水曝气池泡沫识别模型的构建过程包括:
步骤s51:基于googlenet框架和svm框架,得到初始模型;
步骤s52:基于初始模型和训练集,利用优化算法训练得到初始污水曝气池泡沫识别模型;
步骤s53:利用测试集对初始污水曝气池泡沫识别模型进行测试,若测试结果符合设定,则得到污水曝气池泡沫识别模型;若测试结果不符合设定,则改变googlenet框架和svm框架的参数,执行步骤s51。
所述的优化算法为反向传播算法。
所述的googlenet包括六层结构,第一层结构、第二层结构和第六层结构为单层结构,第三层结构和低五层结构各包括两个子层结构,所述的第四层结构包括五个子层结构,将所述的第四层结构的第二子层结构的输出特征、第四层结构的第五子层结构的输出特征以及第六层结构的输出特征进行分类。
所述的第四层结构的第二子层结构的输出特征、第四层结构的第五子层结构的输出特征以及第六层结构的输出特征的权重依次为0.3、0.5和1.0。
所述的第四层结构的第二子层结构的输出特征和第四层结构的第五子层结构的输出特征通过softmaxactivation进行分类,所述的第六层结构的输出特征通过svm进行分类。
与现有技术相比,本发明具有以下优点:
(1)使用googlenet和svm构建污水曝气池泡沫识别模型,只需输入待测曝气池的图片,即可得到泡沫识别结果,无需人工参与,减少了增加企业的人力成本,避免了对工人身体健康的影响,同时准确度更高。
(2)googlenet具有较深的深度和较少的参数,具有较好的性能和较小的计算量。
附图说明
图1为本发明的流程图;
图2为本发明的结构框图;
图3为本发明的参与特征分类的第四层结构的第二子层结构和第五子层结构示意图;
图4为本发明的未参与特征分类的子层结构。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例
本实施例提供一种基于googlenet-svm的污水曝气池泡沫识别方法,步骤包括:
1)采集曝气池的图片。
2)鉴于图片数量少,采用扩充方法对图片进行扩充,得到扩充的样本;扩充方法主要有:
a.图片翻转,将正图片左右翻转,数据增加1倍;
b.加入椒盐噪声,在原始正图片中加入椒盐噪声,将数据增加1倍;
c.分割图片,将目标区域分割出,其他区域置为0,将数据增加1倍;
d.添加光照,图片旋转90°、180°、270°,将数据增加3倍。
3)利用opencv库(提供python、ruby、matlab等语言的接口,实现图像处理和计算机视觉方面的通用算法)对图片统一修改尺寸为224*224,得到统一尺寸样本。
4)对统一尺寸样本进行零均值化,划分得到训练集与测试集。
5)基于训练集、测试集、googlenet和svm,构建污水曝气池泡沫识别模型,该步骤包括:
设计卷积神经网络,建立初始模型:采用googlenet提出inception,使用1x1的卷积来进行升降维,并在多个尺寸上同时进行卷积再聚合。
网络结构包括:
a.第一层,使用7x7的卷积核(滑动步长2,padding为3,64通道,输出为[112x112x64],卷积后进行relu操作,经过3x3的maxpooling(步长为2),输出为((112-3+1)/2)+1=56,即[56x56x64],再进行relu操作;
b.第二层,先做lrn处理(lrn一般是在激活、池化后进行的一中处理方法,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力),使用1x1的卷积核(滑动步长1),192通道,输出为[56x56x192],卷积后进行relu操作,经过3x3的卷积(滑动步长1,padding为1),输出为[56x56x192],即56x56x192,再进行relu操作,接着做lrn处理,经过3x3的maxpooling(步长为2),输出为((56-3+1)/2)+1=28,即[28x28x192],再进行relu操作;
c.第三层i(inception3a层)
分为四个分支,采用不同尺度的卷积核来进行处理:
(1)64个1x1的卷积核,然后rulu,输出[28x28x64];
(2)96个1x1的卷积核,作为3x3卷积核之前的降维,变成[28x28x96],然后进行relu计算,再进行128个3x3的卷积(padding为1),输出[28x28x128];
(3)16个1x1的卷积核,作为5x5卷积核之前的降维,变成[28x28x16],进行relu计算后,再进行32个5x5的卷积(padding为2),输出[28x28x32];
(4)maxpool层,使用3x3的核(padding为1),输出[28x28x192],然后进行32个1x1的卷积,输出[28x28x32];
将四个结果进行连接,对这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出[28x28x256];
第三层ii(inception3b层)
(1)128个1x1的卷积核,然后rulu,输出[28x28x128];
(2)128个1x1的卷积核,作为3x3卷积核之前的降维,变成[28x28x128],进行relu,再进行192个3x3的卷积(padding为1),输出[28x28x192];
(3)32个1x1的卷积核,作为5x5卷积核之前的降维,变成[28x28x32],进行relu计算后,再进行96个5x5的卷积(padding为2),输出[28x28x96];
(4)maxpool层,使用3x3的核(padding为1),输出[28x28x256],然后进行64个1x1的卷积,输出[28x28x64];
将四个结果进行连接,对这四部分输出结果的第三维并联,即128+192+96+64=480,最终输出输出为[28x28x480],接着做maxpool层,使用3x3的核(step为2),输出为:((28-3+1)/2)+1=14,即:[14x14x480]。
d.第四层i(inception4a层)
分为四个分支,采用不同尺度的卷积核来进行处理:
(1)192个1x1的卷积核,然后rulu,输出[14x14x192];
(2)96个1x1的卷积核,作为3x3卷积核之前的降维,变成[14x14x96],然后进行relu计算,再进行208个3x3的卷积(padding为1),输出[14x14x208];
(3)16个1x1的卷积核,作为5x5卷积核之前的降维,变成[14x14x16],进行relu计算后,再进行48个5x5的卷积(padding为2),输出[14x14x48];
(4)maxpool层,使用3x3的核(padding为1),输出[14x14x192],然后进行64个1x1的卷积,输出[14x14x64];
将四个结果进行连接,对这四部分输出结果的第三维并联,即192+208+48+64=512,最终输出[14x14x512];
第四层ii(inception4b层)
分为五个分支,采用不同尺度的卷积核来进行处理:
(1)160个1x1的卷积核,然后rulu,输出[14x14x160];
(2)112个1x1的卷积核,作为3x3卷积核之前的降维,变成[14x14x112],然后进行relu计算,再进行224个3x3的卷积(padding为1),输出[14x14x224];
(3)24个1x1的卷积核,作为5x5卷积核之前的降维,变成[14x14x24],进行relu计算后,再进行,64个5x5的卷积(padding为2),输出[14x14x64];
(4)maxpool层,使用3x3的核(padding为1),输出[14x14x512],然后进行64个1x1的卷积,输出[14x14x64];
将四个结果进行连接,对这四部分输出结果的第三维并联,即160+224+64+64=512,最终输出[14x14x512];
(5)averagepool层,使用5x5的核(setp为3),输出[4x4x512],然后进行160个1x1的卷积核,然后rulu,输出[1x1x1024],再进行dropout操作,系数设置40%,接着进行俩个liner全连接,神经元个数分别为512、256,激活函数relu,之后使用softmaxactivation作为辅助分类器0,分类别为5;
第四层iii(inception4c层)
分为四个分支,采用不同尺度的卷积核来进行处理:
(1)128个1x1的卷积核,然后rulu,输出[14x14x128];
(2)128个1x1的卷积核,作为3x3卷积核之前的降维,变成[14x14x128],然后进行relu计算,再进行256个3x3的卷积(padding为1),输出[14x14x256];
(3)24个1x1的卷积核,作为5x5卷积核之前的降维,变成[14x14x24],进行relu计算后,再进行,64个5x5的卷积(padding为2),输出[14x14x64];
(4)maxpool层,使用3x3的核(padding为1),输出[14x14x512],然后进行64个1x1的卷积,输出[14x14x64];
将四个结果进行连接,对这四部分输出结果的第三维并联,即128+256+64+64=512,最终输出[28x28x512];
第四层iv(inception4d层)
分为五个分支,采用不同尺度的卷积核来进行处理:
(1)112个1x1的卷积核,然后rulu,输出[14x14x112];
(2)144个1x1的卷积核,作为3x3卷积核之前的降维,变成[14x14x144],然后进行relu计算,再进行288个3x3的卷积(padding为1),输出[14x14x288];
(3)32个1x1的卷积核,作为5x5卷积核之前的降维,变成[14x14x32],进行relu计算后,再进行,64个5x5的卷积(padding为2),输出[14x14x64];
(4)maxpool层,使用3x3的核(padding为1),输出[14x14x512],然后进行64个1x1的卷积,输出[14x14x64];
将四个结果进行连接,对这四部分输出结果的第三维并联,即112+288+64+64=528,最终输出[14x14x512];
第四层v(inception4e层)
分为五个分支,采用不同尺度的卷积核来进行处理:
(1)256个1x1的卷积核,然后rulu,输出[14x14x256];
(2)160个1x1的卷积核,作为3x3卷积核之前的降维,变成[14x14x160],然后进行relu计算,再进行320个3x3的卷积(padding为1),输出[14x14x320];
(3)32个1x1的卷积核,作为5x5卷积核之前的降维,变成[14x14x32],进行relu计算后,再进行,128个5x5的卷积(padding为2),输出[14x14x128];
(4)maxpool层,使用3x3的核(padding为1),输出[14x14x512],然后进行128个1x1的卷积,输出[14x14x128];
将四个结果进行连接,对这四部分输出结果的第三维并联,即256+320+128+128=832,最终输出[14x14x832],接着做卷积后进行relu操作,经过3x3的maxpooling(步长为2),输出为((14-3+1)/2)+1=7,即[7x7x832],再进行relu操作;
(5)averagepool层,使用5x5的核(步长为3),输出[4x4x512],然后进行160个1x1的卷积核,然后rulu,输出[1x1x1024],再进行dropout操作,系数设置40%,接着进行俩个liner全连接,接着进行俩个liner全连接,神经元个数分别为512、256,激活函数relu,之后使用softmaxactivation作为辅助分类器1,分类别为5。
e.第五层i(inception5a层)
(1)256个1x1的卷积核,然后rulu,输出[7x7x256];
(2)160个1x1的卷积核,作为3x3卷积核之前的降维,变成[7x7x160],然后进行relu计算,再进行320个3x3的卷积(padding为1),输出[7x7x320];
(3)32个1x1的卷积核,作为5x5卷积核之前的降维,变成[7x7x32],进行relu计算后,再进行,128个5x5的卷积(padding为2),输出[7x7x128];
(4)maxpool层,使用3x3的核(padding为1),输出[7x7x512],然后进行128个1x1的卷积,输出[7x7x128];
将四个结果进行连接,对这四部分输出结果的第三维并联,即256+320+128+128=832,最终输出[7x7x832];
第五层ii(inception5b层)
(1)384个1x1的卷积核,然后rulu,输出[7x7x384];
(2)192个1x1的卷积核,作为3x3卷积核之前的降维,变成[7x7x192],然后进行relu计算,再进行384个3x3的卷积(padding为1),输出[7x7x384];
(3)48个1x1的卷积核,作为5x5卷积核之前的降维,变成[7x7x48],进行relu计算后,再进行,128个5x5的卷积(padding为2),输出[7x7x128];
(4)maxpool层,使用3x3的核(padding为1),输出[7x7x512],然后进行128个1x1的卷积,输出[7x7x128];
将四个结果进行连接,对这四部分输出结果的第三维并联,即384+384+128+128=1024,最终输出[7x7x1024]。
f.第六层
首先进行averagepool层处理,使用7x7的核(步长=1),输出[1x1x1024],再进行dropout操作,系数设置40%,将提取的特征结合污水泡沫类别采用支持向量机进行分类。
综合考虑第四层ii的输出特征、第四层v的输出特征和第六层的最终特征,分别给予权重0.3、0.5和1.0。
训练方法采用反向传播算法和随机梯度下降方法,根据前向传播的loss值的大小,来进行反向传播迭代更新每一层的权重,直到模型的loss值趋于收敛。得到初始污水曝气池泡沫识别模型。
使用测试集来验证初始污水曝气池泡沫识别模型,测试内容包括准确率,召回率,精度以及f-messure,测试合格则得到污水曝气池泡沫识别模型;若测试结果不符合设定,则改变googlenet框架和svm框架的参数,重复执行步骤5)。。
6)基于污水曝气池泡沫识别模型和待测曝气池的图片,进行污水曝气池泡沫识别。
- 还没有人留言评论。精彩留言会获得点赞!