一种基于依赖树的深度学习视觉问答方法及系统与流程
本发明涉及基于深度学习的计算机视觉技术领域,特别是涉及一种基于依赖树的深度学习视觉问答方法及系统。
背景技术:
视觉问答是指根据图像以及问句,准确找到对应区域并回答问题。近年来由于这种技术能在众多不同的视觉技术中得到运用,激发了大量计算机视觉和认知科学的研究工作。
近几年,卷积神经网络的成功运用为视觉问答技术带来了重大突破,研究者提出多种不同的方法以提升视觉问答的准确度。
模块网络方法,如jacobandreas等人在2016年提出神经模块网络“neuralmodulenetworks”(ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2016),预先设计多个小模块网络,利用问句选择使用其中一部分模块运行,这种方法的可解释性较强,但训练难度较大,较容易出现过拟合现象,甚至有时需要强化学习方法的辅助。
多模态融合方法,如hedi等人的工作“block:bilinearsuperdiagonalfusionforvisualquestionansweringandvisualrelationshipdetection”(theassociationfortheadvanceofartificialintelligence(aaai),2019),成功尝试了将两种不同模态的特征融合起来,但该方法弱化了模型的可解释性。
链式推理方法,如chenfeiwu等人的工作“chainofreasoningforvisualquestionanswering”(neuralinformationprocessingsystems(neurips2018)),通过交替获得物体与关系的特征进行链式推理,但该方法的推理链长度一致导致语句适应度较低,且推理的过程被限制在链式结构上。
关注方法,包括自关注,以及协同关注等,如jiasenlu等人的工作“hierarchicalquestion-imageco-attentionforvisualquestionanswering”(ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2016)以及最新的zhouyu等人的工作“deepmodularco-attentionnetworksforvisualquestionanswering”(ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2019),他们的工作表明当前视觉问答最合适的方法是基于关注的方法,关注到不同的区域且更新特征,但这种方法主要是全局特征改变而并没有涉及到局部的特征,视觉问答缺乏推理过程。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种基于依赖树的深度学习视觉问答方法及系统,其有效地结合了全局特征和局部特征的视觉问答方法,同时根据问句长度的不同得到深度不同的依赖树,能够自适应地解决长问题以及短问题。
为达上述目的,本发明提出一种基于依赖树的深度学习视觉问答方法,包括如下步骤:
步骤s1,对问句-图像对的输入进行预处理,提取图像i的目标区域特征,记为图像特征r,以及生成问句q的问句词语特征,记为问句特征e;
步骤s2,使用自关注的方法分别关注到图像以及问句的显著部分,从而更新图像特征以及问句特征;
步骤s3,通过协同关注的方法,将步骤s2得到的图像和问句特征交替作为引导,利用图像特征更新问句特征以及利用问句特征更新图像特征;
步骤s4,将问句解析成依赖树,根据词语的类型进行剪枝,留下的结点词语属于关系与物体两种类型,将步骤s3得到的问句特征按照词语分配到每个树结点上
步骤s5,利用步骤s3中得到的图像特征,从步骤s4得到的依赖树叶子结点开始往根结点流动,根据结点词语类型分为物体关注模块以及关系构建模块,将图像特征以及问句词语特征在模块流动过程中进行更新;
步骤s6,利用步骤s5根据依赖树流动更新过后的图像和问句词语特征进行融合,并通过全连接神经网络分类得到问题的答案,即得到类别概率分布。
优选地,于步骤s1中,利用以残差网络为骨架的fasterr-cnn预训练模型提取图像i的目标区域特征r,对于每个问句q,利用glove预训练模型预处理问句q的独热编码,并利用双向lstm获取问句上下文的特征,得到问句特征e。
优选地,于步骤s2中,通过自关注的方法,分别以全局角度观察图像以及问句,分别利用全连接层得到图像区域重要性概率分布,以及问句词语重要性概率分布,从而更新图像与问句特征。
优选地,步骤s3进一步包括:
步骤s301,借助问句词语特征e对图像特征r进行引导关注,将问句词语特征e的重要信息加入到图像特征r中,以此获得更加丰富的图像特征r;
步骤s302,在步骤s301的前提下,借助更新过后的图像特征r对问句特征e进行引导关注,将图像特征r的重要信息加入到问句特征e中,以此获得更加丰富的问句特征e;
优选地,于步骤s4中,利用斯坦福自然语言解析器将问句解析成依赖树,根据词语的类型进行剪枝,通过剪枝保留属于物体以及关系类型的树结点。
优选地,在步骤s5中,所述依赖树每个结点对应一个词语,在从叶子结点到根结点的流动过程中,每个词语为图像特征提供了局部特征,同时图像特征也引导每个词语进行更新和流动。
优选地,步骤s5进一步包括:
根据依赖树中每个结点词语的类型不同,分为物体关注模块结点以及关系构建模块结点;
在所述物体关注模块结点中,物体类型的词语引导图像关注到对应的局部图像区域,从而更新图像特征;在所述关系构建模块结点中,多个局部图像区域根据关系词语进行融合,得到携带关系的图像特征
优选地,于步骤s6中,将步骤s5中流动到根结点流出的图像特征与问句特征分别通过两层感知器使得两者的维度相同,并通过乘运算进行融合,最后得到的特征通过一个全连接层得到类别的概率分布。
优选地,于步骤s6后,还包括如下步骤:
将得到的类别概率分布将与真实类别的独热编码进行比较,计算交叉熵损失以及预测准确率,通过神经网络的训练,并在训练收敛后选择在对应验证集上预测准确率最高的模型作为最终模型,用于在测试集上进行测试。
为达到上述目的,本发明还提供一种基于依赖树的深度学习视觉问答系统,包括:
预处理单元,用于获取问句-图像对,提取获得图像i的目标区域特征,记为图像特征r;生成问句q的问句词语特征,记为问句特征e;
全局关注单元,用于利用自关注以及协同关注的方法,分别更新图像特征r以及问句特征e;
局部关注单元,借助斯坦福自然语言解析器将问句解析成依赖树,根据词语的类型进行剪枝,留下的结点词语属于关系与物体两种类型,将所述全局关注单元得到的图像特征r以及问句特征e逐层从叶子结点到根结点的流动,得到局部特征融合后的新图像特征r与问句特征s;
融合分类单元,用于将从根结点得到的图像特征r与问句特征s,通过两层感知层调整特征及维度后,进行融合,并通过全连接层得到问题的答案,即得到类别概率分布。
与现有技术相比,本发明一种基于依赖树的深度学习视觉问答方法及系统通过利用自关注与协同关注的方法从全局的角度更新图像区域特征以及问句词语特征,并借助斯坦福自然语言解析器生成的离线依赖树,通过将信息从叶子结点流动到根结点的做法,实现有层次地将局部特征信息进行融合从而更好地更新图像区域特征以及问句词语特征,本发明有效地利用了依赖树对问题和图像特征进行逐层自适应的调整,提取了全局以及局部特征进行融合,能够提升在视觉问答上的可解释性并达到良好的问答效果。
附图说明
图1为本发明一种基于依赖树的深度学习视觉问答方法的步骤流程图;
图2为本发明具体实施例中全局特征关注中自关注方法的过程示意图;
图3为本发明具体实施例中解析问句并经过剪枝后得到的依赖树示例图;
图4为本发明一种基于依赖树的深度学习视觉问答系统的系统架构图;
图5为本发明具体实施例中基于依赖树的深度学习视觉问答系统的网络结构图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
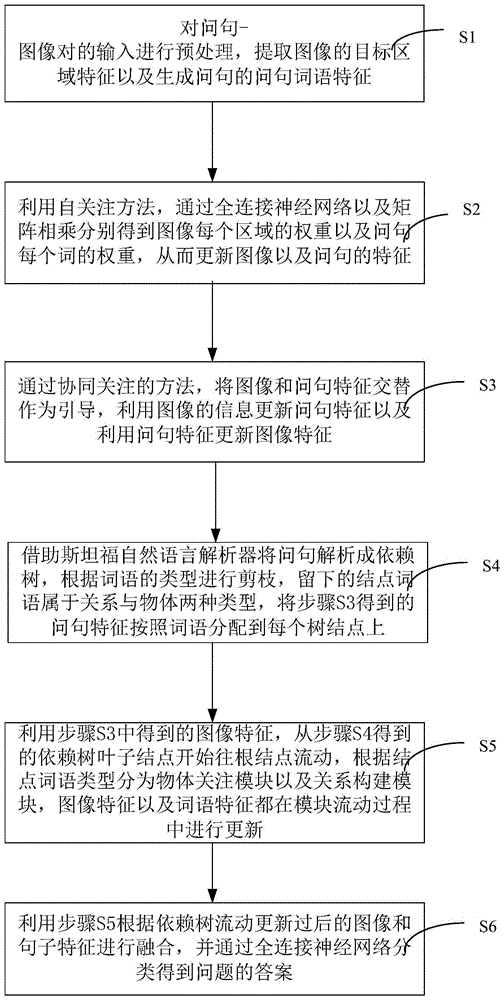
图1为本发明一种基于依赖树的深度学习视觉问答方法的步骤流程图。如图1所示,本发明一种基于依赖树的深度学习视觉问答方法,包括如下步骤:
步骤s1,对问句-图像对的输入进行预处理,提取图像的目标区域特征以及生成问句的问句词语特征。
在本发明具体实施例中,对于每个图像i,利用以残差网络为骨架的fasterr-cnn预训练模型提取图像i的目标区域特征,记为图像特征r,每个图像有100个目标区域特征(目标不足用0补充);对于每个问句q,利用glove预训练模型预处理问句q的独热编码,并利用双向lstm(longshort-termmemory,长短期记忆网络)获取问句上下文的特征,得到问句词语特征,记为问句特征e。公式如下(其中θrcnn和θlstm分别为各自模型的参数):
r=rcnn(i;θrcnn)
e=lstm(q;θlstm)
步骤s2,利用自关注方法,通过全连接神经网络以及矩阵相乘分别得到图像每个区域的权重以及问句每个词的权重,从而更新图像以及问句的特征。也就是说,使用自关注的方法分别关注到图像以及问句的显著部分,图像特征将更多地突出关注到拥有物体的区域,而问句特征也将更多地关注到表达物体或关系的词语
具体地,如图2所示,于步骤s2中,分别使用三个全连接层从问句/图像特征中提取出key,query,value特征:
rk=linear(r;θrk),ek=linear(e;θek)
rq=linear(r;θrq),eq=linear(e;θeq)
rv=linear(r;θrv),ev=linear(e;θev)
其中θrk、θek、θrq、θeq、θrv、θev分别是各全连接层的参数,
通过key与query特征矩阵相乘后通过softmax得到问句词语/图像区域关注的概率分布,与value相乘后更新到原本的问句/图像特征中:
其中dim为query特征的维度;
更新过程中,使用原有的r/e与更新值进行加和并通过一层全连接得到自关注后的特征。
步骤s3,通过协同关注的方法,将图像和问句特征交替作为引导,利用图像的信息更新问句特征以及利用问句特征更新图像特征。本发明采用协同关注使得模型能在全局的层面上通过问句浏览图像以及通过图像阅读问句。
具体地,参考jiasenlu等人的工作“hierarchicalquestion-imageco-attentionforvisualquestionanswering”(ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2016),步骤s3进一步包括:
步骤s301,借助问句词语特征e对图像区域特征r进行引导关注,将问句特征e的重要信息加入到图像特征r中,以此获得更加丰富的图像特征r。
步骤s302,在步骤s301的前提下,借助更新过后的图像特征r对问句特征e进行引导关注,将图像特征r的重要信息加入到问句特征e中,以此获得更加丰富的问句特征e。
更具体地,在进行引导关注时,使用的方法与步骤s2中的方法有相似之处,同样分别利用三个全连接层获取特征r/e对应的key,query,value特征。区别在于在计算更新值时,需要使用到另一个模态的特征作为引导,得到的另一个模态的重要特征将会被补充到当前模态下,公式如下:
得到相应模态的更新值后,将其与原来的特征值进行连接,并随后分别通过一个全连接层对特征进行调整,得到步骤s3的输出。公式如下:
r=linear([r,rupdate]t;θrt)
e=linear([e,eupdate]t;θet)
步骤s4,借助斯坦福自然语言解析器将问句解析成依赖树,根据词语的类型进行剪枝,留下的结点词语属于关系与物体两种类型,将步骤s3得到的问句特征按照词语分配到每个树结点上。
具体地,对于每个问句,斯坦福自然语言解析器将问句解析成离线的依赖树。问句上的每个词语都是依赖树的一个树结点,使得整棵树变得深而复杂且不足够具有语义性,因此需要根据词语的类型对依赖树进行剪枝,此处只保留属于关系和物体两种类型的树结点。其他属性的词语,如修饰词会合并到对应物体结点上,介词会合并到关系结点上,最终离线的依赖树仅包含关系和物体两种类型的结点,复杂度降低,更具有合理的推理过程以及可解释性。依赖树生成并剪枝后,将对应的词特征记为wi分配到每个结点上,对于有多个词的结点,词特征将取均值。定义wi为词语特征e中每个词的特征,是词语特征e中的列特征:
e=[w0,...wi,...wn]
n为问句长度(不包含标点)。
根据统计,在vqa-v2数据集上,问句词语个数最多为23个,生成的依赖树深度最大为11;而在gqa数据集上,问句词语个数最多为28个,生成的依赖树深度最大为9(gqa数据集相对于vqa-v2数据集有对物体更详细的描述修饰,因此在修饰词被合并后,依赖树深度较小)。
由于每个问句生成的依赖树深度不同,该做法更具有自适应能力;考虑到不同依赖树同一深度下可能存在多个结点,因此对同一深度的树结点共享参数;接下来的步骤中,图像区域特征r将从叶子结点开始往根结点处流动,在经过每个结点时将根据结点对应的词特征补充局部特征,从而使得区域特征更加丰富。
步骤s5,利用步骤s3中得到的图像特征,从步骤s4得到的依赖树叶子结点开始往根结点流动,根据结点词语类型分为物体关注模块以及关系构建模块,图像特征以及词语特征都在模块流动过程中进行更新。
具体地,在步骤s5中,信息在结点之间进行流动,对于每个结点,控制其输入输出的维度一致。每个结点接受一个图像区域特征r,一个结点对应词语特征w以及流动句子特征记为s作为输入,输出经过结点局部更新后的图像区域特征r,以及流动句子特征s。对于有多个子结点的结点,先对所有子结点的输出求均值,再作为父结点的输入。
在本发明具体实施例中,根据依赖树中每个结点词语的类型不同,分为物体关注模块结点以及关系构建模块结点,在物体关注模块结点中,物体类型的词语引导图像关注到对应的局部图像区域,从而更新图像特征;在关系构建模块结点中,多个局部图像区域根据关系词语进行融合,得到携带关系的图像特征。
更具体地,对于不同类型的结点,流过结点时将提取不同的特征,步骤s5进一步包括:
步骤s501,对于物体关注模块结点,使用当前结点对应的词语特征w引导图像特征r进行局部物体关注,公式如下:
其中w与r都经过了一层全连接层分别得到query,key,value特征。将更新值补充到输入r中:
r=linear(r+rupdate;θru)
其中linear代表全连接层,θru代表全连接层的参数。
步骤s502,对于关系构建模块结点,由于结点词语描述物体间关系,没有新物体,因此使用结点对应的词语特征w引导对拥有关系的物体进行关注,公式:
为了使关系的信息更好地融入到图像区域特征r中,对更新过后的图像区域特征r再进行自关注,使得关系的信息更加凸显,公式如下:
同样地,更新的信息需要与原有的信息相加,并利用一层全连接层对特征进行调整。
步骤s503,对于句子特征的流动,在图像区域特征r流动更新的过程中,句子特征s也同时进行更新,对于某一个结点,句子特征s的更新在图像特征r的更新之后,将当前更新的图像特征rupdate也融入到句子特征s中。由于句子特征s是一维行向量,而图像特征rupdate是二维特征,因此首先将图像特征在区域维度(100维)上进行加和,记为ru,后与句子特征进行融合,公式如下:
supdate=linear(ru)×linear(s)
同样地,将更新的句子特征与原本的句子特征相加,并利用一层全连接层对特征进行调整。
特别地,根据结点包含的词语属性不同(物体,关系)而采用不同的步骤(s501,s502)得到更新的图像特征,再对句子特征进行更新(步骤s503)。
图3为本发明具体实施例步骤s4对问句进行解析并经过剪枝后得到的依赖树示例。对于不同长度的问句,得到的依赖树深度不同,凸显本发明的自适应性;从树中每个结点包含的词语可以看出,依赖树提供了较准确的推理过程,从而具有较好的可解释性。
步骤s6,利用步骤s5根据依赖树流动更新过后的图像和句子特征进行融合,并通过全连接神经网络分类得到问题的答案。在本发明具体实施里中,将从根结点得到的最终图像特征r与问句特征s,通过两层感知机调整特征及维度后,进行融合,并通过全连接层分类得到问题的答案,即,得到类别概率分布记为pred。
具体地,于步骤s6中,将从根结点得到的图像特征r与句子特征s进行融合,使用的是两层的感知机mlp,公式如下:
ans=mlp(rs)×mlp(s)
其中rs记为图像特征r在区域维度上的加和,最后通过一个全连接层进行分类,得到答案类别的概率分布:
pred=linear(ans)
优选地,于步骤s6之后,本发明之基于依赖树的深度学习视觉问答方法还包括如下步骤:
步骤s7,将得到的预测结果pred与真实结果gt进行对比,计算交叉熵损失以及预测准确率,通过神经网络的训练,并在训练收敛后选择在对应验证集上预测准确率最高的模型作为最终模型,用于在测试集上进行测试。计算交叉熵损失公式:
loss=∑(-log(softmax(pred))×gt)
图4为本发明基于依赖树的深度学习视觉问答系统的系统架构图,图5为本发明具体实施例中基于依赖树的深度学习视觉问答系统的网络结构图。如图4及图5所示,本发明一种基于依赖树的深度学习视觉问答系统,包括:
预处理单元401,用于获取问句-图像对,提取获得图像i的目标区域特征r,生成问句q的问句词语特征e,根据问句生成依赖树tree。具体地,在预处理单元中,对于每个图,借助以残差网络为骨架的fasterr-cnn预训练模型提取100个目标区域特征r(区域不足用0补充);对于每个问句,首先使用glove预处理问句的独热编码,后通过双向lstm获取问句上下文的特征,得到问句词语特征e;对于每个问句,借助斯坦福自然语言解析器将问句解析成依赖树并进行剪枝,得到最终树型结构。
全局关注单元402,用于利用自关注以及协同关注的方法,分别更新图像特征r以及问句特征e。
具体地,全局关注单元402首先使用自关注的方法分别关注到图像以及问句的显著部分,图像特征将更多地突出关注到拥有物体的区域,而问句特征也将更多地关注到表达物体或关系的词语。然后通过协同关注的方法,使用问句/图像特征分别作为引导协助图像/问句特征进行更新,协同关注使得模型能在全局的层面上通过问句浏览图像以及通过图像阅读问句。
局部关注单元403,借助斯坦福自然语言解析器将问句解析成依赖树,根据词语的类型进行剪枝,留下的结点词语属于关系与物体两种类型,将全局关注单元402得到的图像特征r以及问句特征e逐层从叶子结点到根结点的流动,得到局部特征融合后的新图像特征r与问句特征s。具体地,对于每个问句,斯坦福自然语言解析器将问句解析成离线的依赖树,问句上的每个词语都是依赖树的一个树结点,使得整棵树变得深而复杂且不足够具有语义性,因此需要根据词语的类型对依赖树进行剪枝,此处只保留属于关系和物体两种类型的树结点。其他属性的词语,如修饰词会合并到对应物体结点上,介词会合并到关系结点上,最终离线的依赖树仅包含关系和物体两种类型的结点,复杂度降低,更具有合理的推理过程以及可解释性。依赖树生成并剪枝后,将对应的词特征记为wi分配到每个结点上,对于有多个词的结点,词特征将取均值,定义wi为词语特征e中每个词的特征,是词语特征e中的列特征:
e=[w0,...wi,...wn]
n为问句长度(不包含标点)。
信息流动过程中,每个结点接受一个图像特征r,一个问句特征s以及结点对应词语特征wi的输入,利用词语特征对图像特征进行引导关注,从而补充局部信息;将得到的更新图像特征信息rupdate用于更新问句特征s。
特别地,由于结点包含的词语属性不同(物体,关系),将结点分为物体关注结点以及关系构建结点,分别对图像特征作不同的调整,但问句特征都必须进行更新。在本单元中,图像特征r以及问句特征s都在流动的过程中不断补充局部信息,使得全局信息与局部信息相结合得到更合适的特征。
融合分类单元404,用于将从根结点得到的最终图像特征r与问句特征s,通过两层感知机调整特征及维度后,进行融合,并通过全连接层分类得到问题的答案,即得到类别概率分布记为pred。具体地,参考zhouyu等人的工作“deepmodularco-attentionnetworksforvisualquestionanswering”(ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2019),通过感知机调整特征后,将图像特征与问句特征相乘作为融合的方法,最后通过一层全连接层得到与答案字典相同维度的类别概率分布,用于计算单元的损失和准确率计算。
比对计算单元405,用于将预测结果与真实结果进行对比,计算交叉熵损失用作神经网络的反向传播,计算预测准确率用作观察模型的运行效果。具体地,在计算预测准确率时,使用预测的类别概率分布中概率最大的类别作为预测类别,与真实结果进行对比。特别地,当训练在训练集上收敛后,获取在验证集上准确率最高的模型作为最终的模型,用于后续的测试。
综上所述,本发明一种基于依赖树的深度学习视觉问答方法及系统通过利用自关注与协同关注的方法从全局的角度更新图像区域特征以及问句词语特征,并借助斯坦福自然语言解析器生成的离线依赖树,通过将信息从叶子结点流动到根结点的做法,实现有层次地将局部特征信息进行融合从而更好地更新图像区域特征以及问句词语特征,有效结合了全局特征关注以及局部特征融合,同时具备一定的可解释性以及较强的自适应能力;在信息流动过程中,由于结点根据词语划分成物体关注模块以及关系构建模块,使得局部信息融合更加具有语义性,推理过程更加具有可解释性;本发明由于生成的离线依赖树深度不同,使得整个视觉问答系统具备自适应能力,能自动适应长问句与短问句,本发明还利用交叉熵作为损失函数,准确率作为测试指标,通过反向传播机制进行端到端的训练,收敛后得到最终的模型,本发明能应用到多个不同的视觉问答数据集。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 还没有人留言评论。精彩留言会获得点赞!