用于DCGAN网络生成图像的质量评估方法与流程
本发明涉及图像处理领域,特别涉及用于dcgan网络生成图像的质量评估方法。
背景技术:
gan的全称为generativeadversarialnetworks,意为生成式对抗网络。原始的gan是一种无监督学习方法,它巧妙地利用“对抗”的思想来学习生成式模型,一旦训练完成后可以生成全新的数据样本。dcgan将gan的概念扩展到卷积神经网络中,可以生成质量较高的图片样本。
生成式对抗网络是当前最流行的图像生成方法,各种不同的gan网络也是层出不穷,生成的图片的质量也是越来越高,但是当前对于对抗网络生成的图片的质量的评判方法却不是很多,以前人们平时去判定一个生成对抗网络的好坏也是根据最终生成的图片的质量判定,但大多数都是通过目视观察法来定性的、主观的判别生成图片与真实图片之间的差距,鉴于定性评估的内在缺陷,还有就是当前的最好的gan网络生成的图片质量人眼定性评估已经判别不出来了了,恰当的定量评估指标对于gan的发展和更好模型的设计至关重要。当前最流行的定量评估方法是is和fid判别法,is仅仅能判别的是生成图像的多样性,没有把生成样本和真实样本进行比较,有着一定的缺陷,而fid的值也是依赖于用imagenet与训练的inceptionnet,比较的是真实图像和生成图像间的inception激活值,这样的比较把真实图像和生成图像的激活值近似为高斯分布,对于细节变化的提升做出不了明确的解释。
技术实现要素:
本发明要解决的技术问题是:提供一种用于dcgan网络生成图像的质量评估方法,用以提高dcgan网络生成图像的质量评估的准确度。
为解决上述问题,本发明采用的技术方案是:用于dcgan网络生成图像的质量评估方法,包括以下步骤:
步骤1:将dcgan网络生成的图片作为dcgan网络的输入进行反复迭代,直到迭代次数达到阈值m次,其中,m>1,dcgan网络的初始输入为用户准备的原始图片;迭代过程中,每迭代n次后输出并保存一次图片,其中m为n的整数倍;迭代完成之后,从每次保存的图片中,挑选出一部分质量较优的图片,作为后续图片混合之用,其中,挑选时可将每次保存的图片按照质量从高到低排序,取排序靠前的一部分,例如前1/4、1/3;
步骤2:将步骤1每一次挑选的图片分别打上不同标签,同时也从原始图片中取出一部分图片并打上标签,之后将打了标签的各类图片等比例的混合在一起,得到混合图片集;
步骤3:将混合图片集的一部分作为训练集输入到分类器当中训练分类器,再用混合图片集剩下的部分测试分类器的分类精度,当分类精度满足要求之后进入步骤4;
步骤4:将混合图片集输入到dcgan网络中,让它生成一定数量的图片我们称为x,再把x放入步骤3得到的分类器让其分类,从而得到多维的向量y以及向量y的概率p(y),向量y的每个维度的值对应x属于各类图片的概率p(y|x),基于概率p(y|x)和概率p(y)得出dcgan网络生成图像的质量评估结果。
进一步的,步骤4中得到概率p(y)和p(y|x)之后,可通过计算p(y)和p(y|x)的散度得出dcgan网络生成图像的质量评估结果,其中散度越小说明dcgan网络生成图像的质量评估结果越好。
进一步的,步骤3的一种较佳的分配方式为:将混合图片集的90%作为训练集输入到分类器当中训练分类器,再用混合图片集剩下的10%测试分类器的分类精度。
进一步的,所述dcgan网络的生成器的激活函数最后一层最好使用tanh函数。使用tanh函数的原因在于最后一层要输出图像,而图像的像素值是有一个取值范围的,如0~255。relu函数的输出可能会很大,而tanh函数的输出是在-1~1之间的,只要将tanh函数的输出加1再乘以127.5可以得到0~255的像素值。
本发明的有益效果是:本发明采用迭代的思想加上is方法中的思想,在另一个层面可以很好的反映出一个gan网络在一代一代的迭代下,到底损失特征情况是怎样,从另外一个方面入手间接的评判了dcgan的质量。此外,本实例能通过迭代很好的识别过拟合的问题。
附图说明
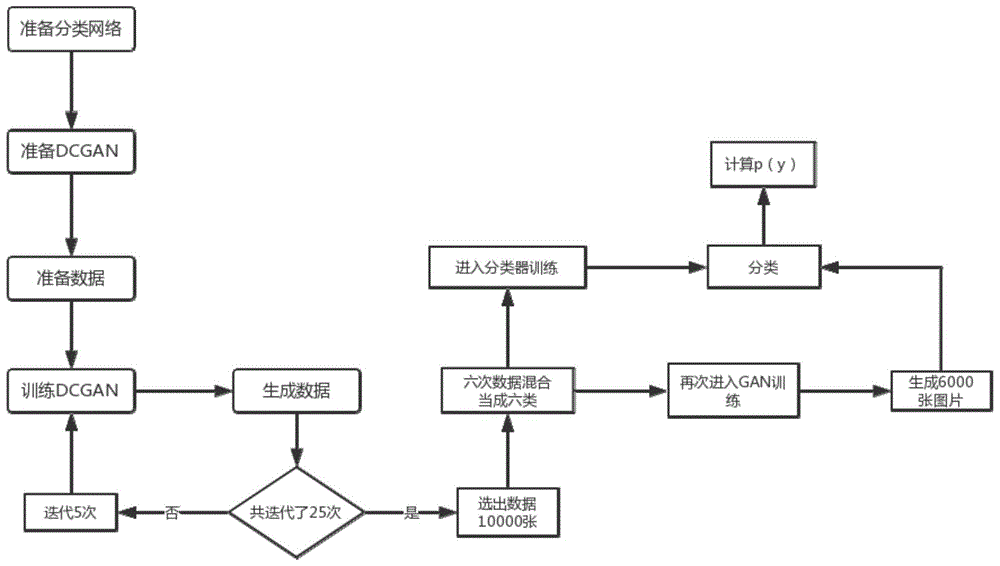
图1是本发明具体实施的流程图。
具体实施方式
现有的评测手段过于严苛的去分析网络模型,弱势的去分析结果,但我们使用生成式对抗网络,就是为了能得到较好的结果,评判对抗网络的好坏,更加可以从结果入手,所以本发明在做dcgan的测评时,根据dcgan网络是基于卷积特征提取生成的,其原理类似与遗传,可以分析原始数据与生成数据的关系系数恰好可以成为一个评判标准。is和fid值都是基于inception的方法不能区分图像质量和图像多样性的关系,换句话说,这两个方法只知道最后图片质量好还是坏,并不知道影响最后图片质量的原因是否与原始数据有关。在我们在分析影响dcgan网络的因素时,或许分析了很久参数的因素依旧没能找到原因,最后发现是原始的训练数据差的因素。我们的方法就可以很好的避免这种问题。我们的方法基于准确率的图像分类新方法解决了这个问题,改进了is方法,并展示了真实图像和生成图像间的显著差异。而且针对dcgan训练的过拟合问题,能较好的判别出过拟合问题。本发明的灵感来自于根据夫妻的相貌找儿子,也可以根据儿子的相貌去判别父母,因为图片所具有的的像素特征更能从这方面体现出来。
下结合附图对本发明的方案做详细阐述,本发明的具体方案如下:
(1)、本发明主要包括dcgan选取合适的生成器、辨别器、数据集,以及优化后的损失函数和训练方法,以及分类器调参寻优方式找到最好的分类效果。并且实现方式是在pytorch上实现dcgan。
(2)、本发明中dcgan中的生成模型结构为:生成器先生成一个100维的噪声,这个噪声可以看成是100*1*1的图片,因为训练的数据集是3*96*96的图片,所以说生成器最终生成图片的分辨率也应该为3*96*96。经过五个卷积层,分别输出1024*4*4—>256*8*8—>64*16*16—>64*32*32—>3*96**96分辨率的图片,并且前四层的全连接层都采用batchnorm2d(ndf),批规范化在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。gamma与beta是可学习的大小为c的参数向量(c为输入大小)。在训练时,该层计算每次输入的均值与方差,并进行移动平均。使之进行输入规范化固化学习过程,这个操作可以提高训练效率,减小初始化不佳带来的影响。移动平均默认的动量值为0.1。是前四层的激活函数采用relu激活,输出层采用tanh函数激活。使用tanh函数的原因在于最后一层要输出图像,而图像的像素值是有一个取值范围的,如0~255。relu函数的输出可能会很大,而tanh函数的输出是在-1~1之间的,只要将tanh函数的输出加1再乘以127.5可以得到0~255的像素值。
(3)、本发明判别器的网络结构和生成器的网络很相似,基本上是一个对称的过程,都是有五层网络,前四层通过conv2d二维卷积层函数卷积缩小尺寸,判别器的尺度都是生成器的逆向过程,经过五个卷积层,分别输出3*96**96—>64*32*32—>64*16*16—>256*8*8—>1024*4*4分辨率的图片。之后都有规范化操作,前四层都有激活函数leakyrelu激活,最后一层输出层没有激活函数,在最后通过sigmoid()函数归一为0-1之间的数,也是图片为真的概率。
(4)、本发明可采用动漫头像数据集作为实验数据,并运用深度学习算法卷积神经网络(cnn)对动漫头像进行特征提取,通过机器学习算法对cnn提取的特征样本进行预测和分类。在机器学习分类算法中主要完成svm分类器的调参寻优实验,分别对kernel、c和gamma三个参数的共20种组合进行对比寻优。并用其他的机器学习分类方法作为对比实验,其中包括:k最近邻分类法(knn)、高斯朴素贝叶斯分类法(gnb)、极端随机树分类法(et)、随机森林分类法(rf)、多层感知器分类法(mlp)、线性判别分析分类法(lda)以及自训练inceptionnet等多种算法。实验利用t-sne特征图、混淆矩阵、精确度、准确率、召回率及f1值等评估标准对各分类器的分类效率和精度进行全面的对比评估。最终的分类精度取平均值得到一个值p(w)。
(5)、如图1所示,调试训练好的dcgan网络,用3万张(这里的数量根据可根据用户需要调整)原始的动漫人物头像进行训练,也生成3万张图片,之后用生成的3万张图片再作为训练数据,进入到dcgan网络,再生成3万张图片,就这样不断迭代。每5个迭代次数(这里的迭代次数根据可根据用户需要调整)后保存输出一次图片,迭代25次,共输出5次图片,每次输出3万张,人工挑取出质量好的1万张,挑选图片时可将每次保存的图片按照质量从高到低排序,取排序靠前的1万张。
(6)、之后把每次输出的图片打上标签,再从原始数据中取出一万张图片也打上标签,共当做六类。然后把混合的六类六万张图片按比例取出90%作为训练集输入到分类器当中训练分类器,用剩下的10%作为测试数据,测试分类器的分类精度p(z),当分类精度满足要求之后进入步骤(7)。
(7)、之后把混合的六万张图片继续输入到dcgan网络中,让它生成6000张图片我们称为x,把6000张图片放入分类器让其分类,会得到一个6维的向量y以及向量y的概率,向量y的每个维度的值对应图片属于原始图片以及第5、10、15、20、25次迭代产生图片的概率p(y|x),然后就像is那样去计算p(y)和p(y|x)之间的散度,当然他们之间的散度是越小越好,不是is那样越大好。但是最终的结果不一定要用kl散度去做,仅仅p(y)和p(y|x)两个值就已经很能说明问题,他们甚至有点互斥,就是说一个好的时候另一个一定很差。
(8)本例子也可以更好的找出过拟合的状态,因为一旦过拟合,迭代次数无论多少,最后在p(y)的关于原数据的值一定非常接近于1,所以能很好的反映出过拟合的问题。
- 还没有人留言评论。精彩留言会获得点赞!