一种引入双向注意力的目标检测方法与流程
本发明属于目标检测领域,涉及一种引入双向注意力的目标检测方法。
背景技术:
目标检测技术是指:给定一幅图像以及检测类别,确定在该图像中是否存在给定类别(比如人、鸟、风筝等)的任何实例,若存在,则返回该实例的空间位置和范围(通常用矩形框框出)。
基于深度神经网络的目标检测算法框架可以分为两类:(1)基于候选区域的两阶段算法;(2)基于边框回归的单阶段算法。具体来说:
(1)基于候选区域的两阶段算法:该算法框架分为两个阶段,首先提取图片中目标可能存在的区域,其次,将所有的区域输入到卷积神经网络中进行特征提取,再对这些区域进行目标分类和边框回归修正。较典型的工作包括rossgirshick等人发表的“fasterr-cnn:towardsrealtimeobjectdetectionwithregionproposalnetworks”,(见,ieeetransactionsonpatternanalysis&machineintelligence,2015.)它创造性地将神经网络应用于候选框的提取,从而实现了整个算法的端到端训练。
(2)基于边框回归的单阶段算法:该算法框架不再提取候选区域,而是将原图像作为输入,直接对边框进行回归,输出预测结果,如redmon等人在“proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2016.”发表的“youonlylookonce:unified,real-timeobjectdetection”。该算法利用卷积神经网络提取特征,将不同大小的特征图都作为输出特征图,其后接分类和回归模块,可以解决不同尺度物体的检测问题,速度远快于fasterrcnn。
通常,二阶段算法具有更高的精度,单阶段算法具有更快的速度。原因如下:第一,单阶段算法从网络结构上看只相当于二阶段网络的第一阶段,而二阶段网络会在此基础上对筛选后的候选框做更精细的计算。第二,二阶段算法在第一个阶段时就已经剔除了大量不包含实例的背景区域,这会让正负样本的数量在训练时更加均衡。第三,二阶段算法在第二阶段开始前会对候选框做resize,小目标将会放大,因此在小物体的检测上二阶段算法比单阶段算法更为准确。同时,正是由于第一阶段的存在,二阶段算法在速度上要慢于单阶段算法。
技术实现要素:
本发明的目的在于提高目标检测算法的性能,本发明提供了一种引入双向注意力的目标检测方法,可以在保持较快的运行速度的情况下,提高目标检测准确率。本发明具有通用性,适用于一阶段和二阶段目标检测算法。
本发明采用的技术方案是:
一种引入双向注意力的目标检测方法,其具体步骤如下:
步骤1,获取用于目标检测的训练样本,并对训练样本进行预处理;
步骤2,建立引入双向注意力的目标检测算法模型,所述引入双向注意力的目标检测算法模型包括共享卷积网络、基础目标检测器和注意力模块;
步骤3,将训练样本送入引入双向注意力的目标检测算法模型中进行训练,并优化模型的多任务损失;
步骤4,将实际应用场景中的测试样本送入训练好的引入双向注意力的目标检测算法模型进行测试,得到目标检测结果。
进一步,所述步骤1中训练样本的预处理具体包括以下子步骤:
步骤11,读取目标检测训练样本,每个样本包括图像和标签;
步骤12,对图像进行预处理,将图像进行随机大小,随机长宽比的裁剪,然后将裁剪后的图像调整为固定大小;
步骤13,依概率p对图像进行水平翻转;
步骤14,将读入的图像数据转换为张量,并将rgb三个通道[0,255]的数值归一化至[0,1];
步骤15,将图像数据按通道进行标准化。
进一步,所述步骤2具体包括以下子步骤:
步骤21,所述共享卷积网络用于提取图像的浅层特征图;
步骤22,基础目标检测器通过深度卷积神经网络组成的主干网络对浅层特征图继续提取特征,得到深层特征图;再对深层特征图进行分类和回归,得到矩形框和分类得分矩阵r;
步骤23,注意力模块根据基础目标检测器的结果给浅层特征图赋予不同的注意力权值,浅层特征图中的每个像素对应的特征向量和注意力权值进行点乘之后再继续输入到卷积网络中进行处理,得到注意力模块分类得分矩阵m;
步骤24,注意力模块的结果以一定的注意力权重和基础目标检测器的结果进行结合得到最后的目标检测结果。
进一步,所述基础目标检测器采用一阶段或者两阶段的目标检测算法。
进一步,所述注意力模块的卷积网络采用mobilenetv3网络。
进一步,所述注意力权值按照如下的方法进行赋予:
(1)如果基础目标检测器预测的矩形框和真实物体框最大的iou大于设定的前景阈值fg_thresh,该矩形框中所有像素点的注意力权值赋为1;
(2)如果基础目标检测器预测的特征图的像素点对应预测得到的分类分数大于设定的attention阈值,该像素点预测得到的矩形框中范围内包含的所有像素点的注意力权值赋为1;
(3)其余像素点的注意力权值赋为0。
进一步,注意力模块的结果以一定的注意力权重和基础目标检测器的结果结合的具体方式是:
首先计算注意力权重矩阵w:
其中m是注意力模块分类得分矩阵,c表示所有物体类别数;r是基础目标检测器分类得分矩阵,rt是r经过转置后的矩阵;
假设基础目标检测器得到某像素点的分数为r,结合注意力模块的结果得到该像素点的分类分数为
score=r·(wtm)
其中wt表示注意力权重矩阵w转置后的矩阵;
该像素点对应的分类分数score(只是该像素点的分类分数,忽略矩形框中包含的其他像素点的分类分数)和基础目标检测器预测得到的矩形框(由矩形框左上角和右下角的坐标组成)一起组成了该像素点的目标检测结果,然后利用非极大抑制算法对矩形框进行筛选,得到最后的目标检测结果。
进一步,所述步骤3具体包括以下子步骤:
步骤31,将训练样本对随机打乱,每次训练迭代选择nb个训练样本进行训练,其中nb<<训练样本总数;
步骤32,将步骤31中预处理后的图像输入到共享卷积网络中,得到浅层特征图,浅层特征图同时输入到基础目标检测器和注意力模块中;基础目标检测器计算分类损失lcls和定位损失lloc,其中分类损失lcls采用交叉熵损失函数,定位损失lloc采用smooth-l1损失函数;
注意力模块分类损失lattention采用交叉熵损失函数;
步骤33,对网络参数进行调整优化多任务损失:l=lcls+lloc+lattention,训练算法模型直到收敛。
进一步,所述的步骤4具体包括以下子步骤:
步骤41,将测试样本进行预处理;
步骤42,将预处理后的测试样本输入训练好的引入双向注意力的目标检测算法模型,得到目标检测结果;
步骤43,重复步骤41至步骤42,直到测试样本集中所有图片均测试完毕,计算目标检测评价指标map;
本发明与现有技术相比,其显著优点包括:
1)人脑在观察一幅图片时,并不是均衡地关注整幅图片,而是有侧重地关注图片的某一部分。本发明公开了一种引入双向注意力的目标检测方法,可以模拟人脑的工作机制,提高目标检测性能。
2)注意力模块通过一定的权值关注特征图中位置,使得注意力模块的重点始终放在目标区域。一方面,对于小物体来说,可以减少多余的背景信息,提高网络对小物体的目标检测能力。另一方面,传统的网络一般在降采样的高层语义图进行预测,较小的误差在原图像上会被放大,导致较大的误差。本发明在attention模块中,特征图和目标可以很好地对齐。
3)传统的目标检测网络对目标的检测性能不够,本发明采用注意力模块和基础目标检测器通过共享浅层网络结合的方式,可以提高目标检测模型的性能,也不会增加过多的计算量。
4)注意力模块的结果以一定的注意力权重和基础目标检测器的结果进行结合得到最后的目标检测结果。这个过程相当于基础目标检测器关注图片中所有位置并在嵌入空间中取加权平均值来表示图片中某位置处的响应,可以得到更多的语义信息。
附图说明
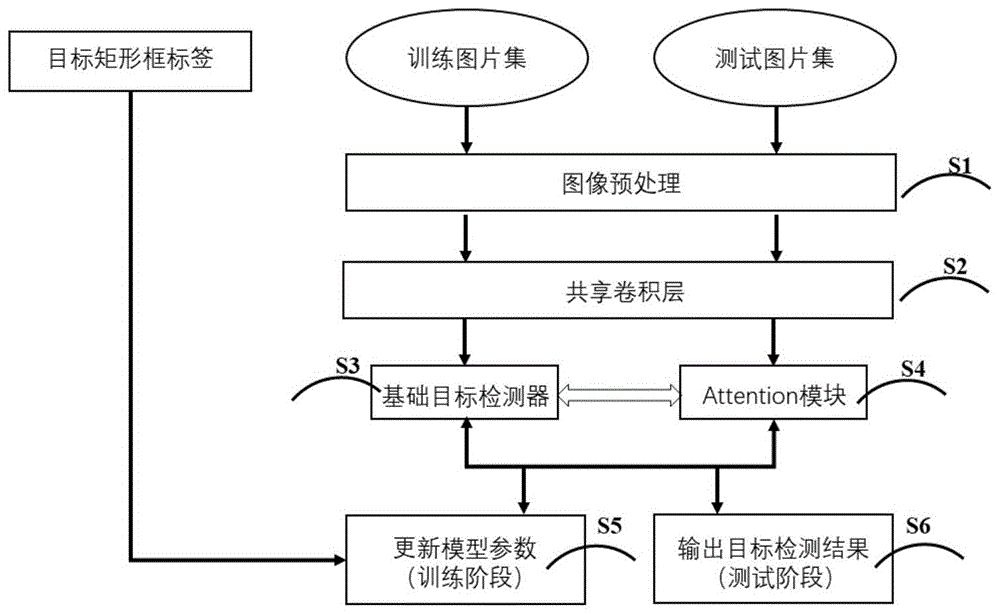
图1为本发明实施例的引入双向注意力的目标检测算法模型的训练和测试流程图。
图2为本发明所述的引入双向注意力的目标检测算法模型的总体结构。
图3为本发明所述的注意力模块所采用的mobilenetv3的网络结构。
图4为本发明所采用的ssd算法的网络结构。
图5为本发明实施例的结果展示对比。
具体实施方式
下面结合具体实施例来对本发明进行进一步说明,但并不将本发明局限于这些具体实施方式。本领域技术人员应该认识到,本发明涵盖了权利要求书范围内所可能包括的所有备选方案、改进方案和等效方案。
参照图1、图2,本实施例提供了一种引入双向注意力的目标检测方法,包括以下步骤:
步骤1,获取用于目标检测的训练样本,并对训练样本进行预处理;
具体的,步骤1中训练样本的预处理具体包括以下子步骤:
步骤11,读取目标检测训练样本,每个样本包括图像和标签;
步骤12,对图像进行预处理,将图像进行随机大小,随机长宽比的裁剪,然后将裁剪后的图像调整为固定大小(通常为224x224,32x32等);
步骤13,依概率p对图像进行水平翻转,p可取0.5;
步骤14,将读入的图像数据转换为张量(tensor),并将rgb三个通道[0,255]的数值归一化至[0,1],以便深度学习框架如pytorch等对图像进行后续的操作;
步骤15,将图像数据按通道进行标准化,即rgb每个通道先减去对应的均值(mean),再除以标准差(std)。均值和标准差由所有训练图片统计得到。
步骤2,建立引入双向注意力的目标检测算法模型,所述引入双向注意力的目标检测算法模型包括共享卷积网络、注意力模块和基础目标检测器;
具体的,步骤2具体包括以下子步骤:
步骤21,所述共享卷积网络用于提取图像的浅层特征图。
步骤22,基础目标检测器通过深度卷积神经网络组成的主干网络(backbone)对浅层特征图继续提取特征,得到深层特征图;再对深层特征图进行分类和回归,得到矩形框和分类分数组成的得分矩阵r。
基础目标检测器可以采用一阶段或者两阶段的目标检测算法框架,比如常用一阶段算法框架ssd、retinanet和两阶段算法框架fasterrcnn等。采用不同的基础目标检测器算法框架均可以和注意力模块进行结合,采用同样的工作流程来提高基础目标检测器的性能。
本实施例以采用一阶段目标检测算法ssd为例,ssd网络结构如图4所示。采用vgg16作为主干网络,得到6个多尺度特征图,大小为m×n,具有p个通道。特征图上每个像素点预先生成k个默认框。使用3×3×p卷积核对每个特征图进行卷积操作,得到每个像素点对应的相对于默认框的偏移量和物体类别的分数。一张特征图上所有像素点对应的物体类别的分数共同组成了基础目标检测器的得分矩阵r。通过偏移量可以计算出矩形框。
步骤23,注意力模块根据基础目标检测器的结果给浅层特征图赋予不同的注意力权值,浅层特征图中的每个像素对应的特征向量和注意力权值进行点乘之后再继续输入到剩下的卷积网络中进行处理。attention模块剩下的卷积网络采用mobilenetv3网络,mobilenetv3网络结构如图3所示。同样,每个像素点都会得到对应的物体类别的分数,一张特征图上所有像素点对应的物体类别的分数共同组成了attention模块的得分矩阵m。
其中注意力权值按照如下的方法进行赋予:
(1)如果基础目标检测器预测的矩形框和真实物体框(groundtruth)最大的iou大于设定的前景阈值fg_thresh,该矩形框中所有像素点的注意力权值赋为1。作为优选,前景阈值fg_thresh设置为0.5;
(2)如果基础目标检测器预测的特征图的像素点对应预测得到的分类分数大于设定的attention阈值,该矩形框中所有像素点的注意力权值赋为1。作为优选,attention阈值设置为0.3;
(3)其余像素点的注意力权值赋为0。
步骤24,注意力模块的结果以一定的注意力权重和基础目标检测器的结果进行结合得到最后的目标检测结果。结合的具体方式是:基础目标检测器得到的得分矩阵是r,注意力模块得到特征图的得分矩阵为m,首先计算注意力权重矩阵w:
其中m是n×c的矩阵,n表示一张特征图上共有n个像素点,c表示所有物体类别数。r也是n×c的矩阵,rt是r经过转置后的矩阵,大小为c×n。mrt得到n×n的矩阵,除以缩放因子
假设x是一组数值,xi是x中的第i个元素。其中softmax的计算公式为:
假设基础目标检测器得到某像素点的分数为r,注意力模块得到特征图的得分矩阵为m,注意力权重矩阵为w,最后得到该像素点的分数为
score=r·(wtm)
其中wtm表示注意力矩阵转置和得分矩阵相乘,得到c×c的矩阵,像素点分数r是1×c维向量,最后相乘得到大小为1×c维的像素点分数score。该像素点对应的分类分数score(只是该像素点的分类分数,忽略矩形框中包含的其他像素点的分类分数)和基础目标检测器预测得到的矩形框(由矩形框左上角和右下角的坐标组成)一起组成了该像素点的目标检测结果。在训练时,该结果可以用来计算目标检测的损失函数;在测试时,对该结果,利用非极大抑制算法(nms)对矩形框进行筛选,得到最后的目标检测结果,即矩形框+物体类别+该类别的分数。
步骤3,将训练样本送入引入双向注意力的目标检测算法模型中进行端到端的深度学习,优化模型的多任务损失;
具体的,所述步骤3具体包括以下子步骤:
步骤31,将训练样本对随机打乱,每次训练迭代选择nb个训练样本进行训练,其中nb<<训练样本总数;
步骤32,将上述初始化处理后的图像输入到步骤21定义的共享卷积网络中,得到浅层特征图。浅层特征图同时输入到基础目标检测器和注意力模块中。基础目标检测器可以采用一阶段或者两阶段的目标检测模型,在这里,以ssd为例,ssd网络结构如图4所示。主干网络提取得到深度特征图后,再得到特征图上每个像素点对应的相对于默认框的偏移量和物体类别的分数。将真实物体框(groundtruth)分配给默认框,分配策略是:首先将gt分配给iou(交并比)最大的默认框,然后将gt分配给iou大于0.5的默认框。再计算损失函数:具有gt的是正样本,计算分类损失和定位损失;其余是负样本,只计算分类损失。分类损失(lcls)采用交叉熵损失函数,定位损失(lloc)采用smooth-l1损失函数。
注意力模块根据基础目标检测器的结果给浅层特征图赋予不同的注意力权值,浅层特征图中的每个像素对应的特征向量和注意力权值进行点乘之后再继续输入到剩下的卷积网络中进行处理,得到分类分数之后,和正确的类别标签计算交叉熵损失函数,计算得到损失函数lattention。
步骤33,对网络参数进行调整优化多任务损失:l=lcls+lloc+lattention,训练算法模型直到收敛。
步骤4,将实际应用场景中的测试样本送入训练好的引入双向注意力的目标检测算法模型进行测试,得到目标检测结果。
具体的,所述步骤4具体包括以下子步骤:
步骤41,将图像调整为300×300像素大小,依照步骤13和步骤14对图像进行后续处理;
步骤42;将图像输入训练好的引入双向注意力的目标检测算法模型中,将注意力模块的结果以一定的注意力权重和基础目标检测器的结果进行结合,利用非极大抑制算法(nms)对矩形框进行筛选,得到最后的目标检测结果;
步骤43,重复步骤41至步骤42,直到测试数据集中所有图片均测试完毕,计算目标检测评价指标map(meanaverageprecision)。
人脑在观察一幅图片时,并不是均衡地关注整幅图片,而是有侧重地关注图片的某一部分。类似地,本发明在进行目标检测时,引入注意力机制来模拟人脑的工作方式。具体来说,本发明的算法分为两个部分:基础目标检测器和注意力(attention)模块,两个模块共享基础的卷积网络来节省计算量。基础目标检测器的结果以一定的注意力权重输入到注意力模块中;注意力模块的结果以一定的注意力权重和基础目标检测器的结果进行结合得到最后的目标检测结果。在训练阶段,将准备好的目标检测的训练样本输入到算法模型中进行训练,尽可能降低基础目标检测器和注意力模块的多任务损失。在运行速度较快的情况下,和单一的目标检测器相比,本发明进一步提高了目标检测算法精度。本发明可作为图像语义分割、实例分割、图像标注和视频理解的基础,也可应用于机器人、自动驾驶、增强现实、视频监控等领域,具有较好的实用价值。
实施例
本实施例将上述方法应用于目标检测数据集pascalvoc2007,并与主流的目标检测算法fasterrcnn、r-fcn、ssd、dssd、dcn相比较。pascalvoc2007数据集由20个类别的9963张图片组成,包括5011张trainval图片和4952张test图片。20个类别分别为飞机、自行车、鸟、船、瓶子、公共汽车、汽车、猫、椅子、奶牛、餐台、狗、马、摩托车、人、盆栽植物、羊、沙发、火车、电视监视器,见表一。
表一算法性能对比
本实施例采用1080ti显卡对数据进行训练,在测试集上得到结果如表一所示。图5是以ssd算法为例,和本发明提出的方法的对比示例,其中图5(a)是ssd算法,图5(b)是本发明使用的算法,可以看出,相比于其他目标检测算法,本发明提出的算法在相同的数据集上性能更优,误检更少。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!