一种风力发电机组风功率曲线优化计算及异常值检测方法与流程
本发明涉及风力发电数据分析领域,尤其涉及一种风力发电机组风功率曲线计算及异常值检测方法。
背景技术:
风力发电机组的风功率曲线是衡量机组出力性能的重要指标之一。风功率曲线是以风速为横坐标,功率为纵坐标所拟合出来一条近似曲线。采用合适的拟合方法对准确评估机组出力性能有着至关重要作用。
目前,风力发电机组的风功率曲线拟合方法主要基于机组scada数据完成。拟合方法主要是将scada数据按照风速进行区间分割,然后求出每个区间内的功率均值,最后结合风速与功率均值拟合出机组实际运行风功率曲线。虽然scada数据包括时间、风速和功率数据,但实际采集到的数据分布较为离散,且存在非正常发电数据,直接利用区间分割并求均值的方法会带来计算误差。针对该类方法的不足,改进的方法主要是利用四分位或者基于标准风功率曲线设置置信区间来消除异常数据,然后再拟合出风功率曲线。
但是,改进的方法依赖风机数据中正常数据占比高,或者假设机组大部分时间处于设计范围内,当机组异常数据占比高,或者投入运行时就处于异常状态时,这类方法拟合出来的风功率曲线会偏离真实的机组风功率曲线,且缺少对机组异常值分布情况的分析。
技术实现要素:
针对上述现有技术存在的问题,本发明提供一种风力发电机组风功率曲线优化计算及异常值检测方法,与其他方法相比,本方法不需要知道机组设计功率曲线且对正常数据的占比没有要求,方法适用性强,计算效率高。
本发明采用的技术方案:一种风力发电机组风功率曲线优化计算及异常值检测方法,包括以下步骤:
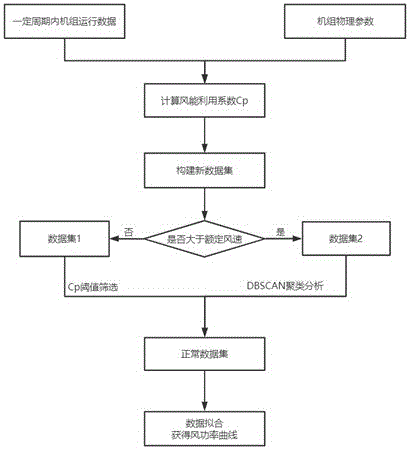
s1:采集风力发电机组一个周期内的运行数据,得到原始采集数据;
s2:根据风轮直径和空气密度计算风能利用系数cp;
s3:将cp值拼接到原始数据中,构建新的数据集a;
s4:设定额定风速,将数据集a中风速小于额定风速的数据归为数据集b,其余数据归为数据集c;
s5:设置cp阈值,对数据集b中的数据进行cp阈值筛选,将在阈值范围内的数据标记为正常数据,在阈值范围之外的数据标记为异常数据;
s6:对数据集c中的数据利用dbscan算法进行聚类分析,得到数据集所属的类别;将数据集c中数量最多的一类数据标记为正常数据,其他的标记为异常数据;
s7:将数据集b和数据集c中的正常数据进行拼接,得到清洗后的数据集d;将数据集b和数据集c中的异常数据桶方法拼接,得到异常数据集e;
s8:对正常数据集d和异常数据集e进行排序,以切入风速为起点,区间长度为0.5m/s,进行风速区间划分;
s9:计算每个区间内正常数据的风功率均值;计算每个区间内异常数据占对应区间的百分比,若某个区间内数据集为空,则该区间的风功率值取前、后区间风功率的均值,百分比则计算为0;
s10:以划分区间内的风速为横坐标,风功率均值为纵坐标,采用三次样条插值拟合,得到机组实际风功率曲线。
优选的,所述的步骤s1中,一个周期不小于3个月,数据采样间隔为10分钟,采集的数据包括时间、风速和对应的风功率。
优选的,步骤s2中计算风能利用系数cp的方法为:
其中p为风机实际运行功率,ρ为空气密度,s为风轮扫风面积,v为风速,对应时间需与运行数据时间相同,空气密度为风场实测空气密度或者标准空气密度。
优选的,步骤s5中,cp阈值设置为[0.2,0.5].
优选的,所述步骤s6中,对数据集c中的数据先进行标准化处理,再利用dbscan算法进行聚类分析。
优选的,所述的步骤s3中将cp值拼接到原始数据的方法为:循环比较cp值所在的时刻是否与某条原始数据时刻相同,如果相同,则在该条原始数据右边直接增加cp列;如果不同,则继续遍历搜寻匹配,直至循环结束。
优选的,步骤s7中将数据集b和数据集c中的正常数据进行拼接的方法为:将b和c按照列名称是否相同进行上下拼接,然后按照风速由小到大进行排序。
本发明的有益效果:
1、不依赖机组标准功率曲线,可适用于任何机型;
2、对采集到的数据集中正常样本占比没有要求,能展现任何工况下的机组风功率曲线;
3、对机组运行数据进行分段处理,更加有效剔除了异常数据,拟合出的功率曲线更接近机组实际风功率曲线;
4、增加了对运行数据异常分布分析,能弥补只根据风功率曲线来评估机组性能的不足;
5、cp值特征计算简单,方法可重复使用,有效提高了方法泛化能力。
附图说明
图1是本方法实施流程图;
图2是本方法拟合出的风功率曲线及异常数据示例;
图3是本方法对异常数据集分布结果示例。
具体实施方式
如图1、图2和图3所示,本实例提供一种风力发电机组风功率曲线优化计算及异常值检测方法,包括以下步骤:
s1:采集风力发电机组一个周期内的运行数据,得到原始采集数据,本示例数据来源于某风场真实运行数据;
s2:根据风轮直径和空气密度计算风能利用系数cp;
s3:将cp值拼接到原始数据中,构建新的数据集a;
s4:设定额定风速,将数据集a中风速小于额定风速的数据归为数据集b,其余数据归为数据集c;
s5:设置cp阈值,对数据集b中的数据进行cp阈值筛选,将在阈值范围内的数据标记为正常数据,在阈值范围之外的数据标记为异常数据;
s6:对数据集c中的数据利用dbscan算法进行聚类分析,得到数据集所属的类别;将数据集c中数量最多的一类数据标记为正常数据,其他的标记为异常数据;
s7:将数据集b和数据集c中的正常数据进行拼接,得到清洗后的数据集d;将数据集b和数据集c中的异常数据桶方法拼接,得到异常数据集e;
s8:对正常数据集d和异常数据集e进行排序,以切入风速为起点,区间长度为0.5m/s,进行风速区间划分;
s9:计算每个区间内正常数据的风功率均值;计算每个区间内异常数据占对应区间的百分比,若某个区间内数据集为空,则该区间的风功率值取前、后区间风功率的均值,百分比则计算为0;
s10:以划分区间内的风速为横坐标,风功率均值为纵坐标,采用三次样条插值拟合,得到机组实际风功率曲线。
本实施例中,步骤s1中,一个周期不小于3个月,数据采样间隔为10分钟,采集的数据包括时间、风速和对应的风功率。
步骤s2中计算风能利用系数cp的方法为:
其中p为风机实际运行功率,ρ为空气密度,s为风轮扫风面积,v为风速,对应时间需与运行数据时间相同,空气密度为风场实测空气密度或者标准空气密度。
步骤s5中,cp阈值设置为[0.2,0.5],当cp值大于0.5或者小于0.2时,将该条机组标记为异常1,其余的标价为正常0;
所述步骤s6中,对数据集c中的数据先进行标准化处理,得到归一化后的数据样本,然后设置dbscan模型的算法参数,最优利用dbscan算法对数据样本进行聚类分析,得到样本二分类结果,将数量较多的类标记为正常0,数量较少的类标记为异常1。
所述的步骤s3中将cp值拼接到原始数据的方法为:循环比较cp值所在的时刻是否与某条原始数据时刻相同,如果相同,则在该条原始数据右边直接增加cp列;如果不同,则继续遍历搜寻匹配,直至循环结束。
步骤s7中将数据集b和数据集c中的正常数据进行拼接的方法为:将b和c按照列名称是否相同进行上下拼接,然后按照风速由小到大进行排序。
- 还没有人留言评论。精彩留言会获得点赞!