一种基于多源数据的危险驾驶行为预测方法
1.本发明涉及驾驶风险领域,特别涉及一种基于多源数据的危险驾驶行为预测方法。
背景技术:
2.随着人口及机动车保有量的飞速增加,道路交通安全问题愈发凸显,道路交通伤害成为伤亡的重要原因。驾驶过程中出现的异常驾驶行为与交通事故密切相关,因此为提高道路交通安全性,减少道路交通事故发生,针对驾驶人驾驶行为的研究是非常必要的。对驾驶人行为的识别和预测是驾驶人安全系统中迫切需要的模块,通过适当的警告反馈,可以预防驾驶人潜在的不安全驾驶行为,减少交通事故出现。
3.现阶段对于驾驶行为的研究已经取得了丰富的成果,但仍然存在以下不足:现有研究大多集中在针对驾驶行为识别和分类上,对于驾驶行为的预测研究较少;在针对数据集的选取上,采用的数据集仅限于客观的车辆运动数据,数据比较单一,导致预测的准确率较低。
技术实现要素:
4.发明目的:针对以上问题,本发明目的是提供一种基于多源数据的危险驾驶行为预测方法,综合考虑现实因素,给出道路环境中使用的危险驾驶行为预测方案。
5.技术方案:本发明的一种基于多源数据的危险驾驶行为预测方法,该预测方法包括以下步骤:
6.s10,采集在自然驾驶环境下的车辆运动数据和车辆视频数据,对数据进行预处理,保留有效数据;
7.s20,根据获得的车辆速度和横向加速度变化关系,选取急加速、急减速以及急转弯为标定对象,将加速度和速度数据结合,使用横向加速度阈值标定急转弯,使用纵向加速度阈值标定急加速和急减速,区分出正常驾驶样本和异常驾驶样本;
8.s30,将异常驾驶样本分成三类,分别为车辆运动数据、情绪数据以及微表情数据,通过对三类数据不同的搭配组合将异常驾驶样本划分为不同的特征集,利用不同的模型在每个特征集上进行建模,选取综合预测能力最好的模型作为最佳预测模型;
9.s40,通过改变最佳预测模型的输入特征集和时间窗,分析各特征集的预测能力随时间窗变化规律,找出预测危险驾驶行为的最佳特征集和最佳时间窗。
10.进一步,步骤s10中,对数据进行预处理包括:
11.s101,按照时间戳将面部表情数据和车辆运动数据进行拼接,面部表情数据来源车辆视频数据;
12.s102,通过临近值填补及直接删除的方法清除拼接后数据集中的无效数据;
13.s103,采用sg滤波方法对有效数据进行平滑处理,利用z-score法对平滑处理后的数据进行数据标准化处理。
14.进一步,步骤s30中,所述特征集包括:情绪数据集、微表情数据集、车辆运动数据集、情绪数据集+微表情数据集、车辆运动数据集+情绪数据集、车辆运动数据集+微表情数据集、车辆运动数据集+情绪数据集+微表情数据集。
15.进一步,步骤s30中,所述模型包括决策树模型、随机森林模型、梯度提升树模型、支持向量机模型以及朴素贝叶斯模型;
16.最佳预测模型的评价标准用参数f1表示,表达式为:
17.f1=(2*precision*recall)/(precision+recall)
18.其中precision表示准确率,recall表示召回率。
19.进一步,步骤s30中,利用不同的模型在每个特征集上进行建模包括:
20.s301,利用smote算法均衡训练集的正负样本数量,生成新的异常驾驶样本,使训练集正负样本比例为1:1;
21.s302,每个模型在训练之前,使用贝叶斯优化算法调节模型超参数,在搜索过程中,使用5折交叉验证对模型的表现进行评估;
22.s303,通过超参数的调整和交叉验证,结合不同的特征集进行建模,利用f1值比较不同模型预测性能。
23.进一步,步骤s40中,改变时间窗包括:
24.将时间窗进行更细致的切分,将时间窗起点从驾驶行为发生时刻向前滑动,滑动步长为δt,每个起点使用多种时间窗长度利用最优预测模型进行建模,使用网格搜索策略,根据危险驾驶行为模型的f1值确定最佳预测效果的时间窗和特征集组合。
25.有益效果:本发明与现有技术相比,其显著优点是:
26.1、本发明首次将车辆视频数据用于驾驶行为的预测,在融合车辆运动数据和面部表情数据后,模型预测的准确率得到较大的提升;
27.2、本发明充分考虑不同预测模型的在不同特征集上的性能,对异常驾驶行为最优预测模型进行了筛选;
28.3、现有的驾驶行为预测研究尚没有统一观测时间窗,本发明提供了一种比较和优化预测特征集和预测时间窗的方法。
附图说明
29.图1为本发明流程框图;
30.图2为车辆受力示意图;
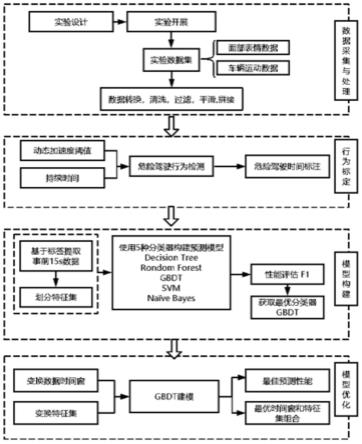
31.图3为smote算法示意图;
32.图4为时间窗划分示意图。
具体实施方式
33.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。
34.如图1,本实施例所述的一种基于多源数据的危险驾驶行为预测方法,流程图如图1所示,该预测方法包括以下步骤:
35.s10,采集在自然驾驶环境下的车辆运动数据和车辆视频数据,对数据进行预处
理,保留有效数据。
36.本实施例数据来自于自然驾驶实验数据,车辆的运动数据由高精度gps设备vbox采集得到,vbox以10hz的频率记录gps和其他数据信息,采集的运动数据直接存储在内置的存储卡中以便导出。车辆视频数据由双摄像头行车记录仪拍摄,画面清晰度为1080p。行车记录仪内置128g存储卡,保证一天的视频存储。该行车记录仪安装在前挡风玻璃上方,由驾驶员本人确认不干扰视线。使用前置和后置双摄像头记录司机面部表情视频和车外情况,非侵入的采集方式最大程度上减少设备对驾驶人产生的干扰。在调节行车记录仪拍摄角度过程中,保证前置摄像头可以拍摄到驾驶人全脸,同时不会拍到乘客。视频画面后续会输入到专业软件进行处理,以获得数值型的面部数据。所有需要采集的数据已事前告知驾驶人,在驾驶人知情且同意的情况下开展试验。
37.由于数据是在自然环境中采集,gps接收器可能因受到高大建筑物或者数目遮挡导致信号中断,造成数据噪声以及无效值。面部视频需要通过算法提取出表情数据,并与vbox数据实现时间同步。因此在建模前,需要对数据进行清洗、填补缺失值、数据同步等预处理工作,包括:
38.s101,按照时间戳将面部表情数据和车辆运动数据进行拼接,面部表情数据来源车辆视频数据;
39.车辆视频数据无法直接用于建模,需要通过处理转化为数值型数据。由于计算机视觉知识过于复杂,因此借用专业软件facereader 8.0进行面部表情分析。它可以检测人脸的情绪表情,识别出七种基本情绪以及情绪的效价和唤醒度,测量最常见的20个面部微表情动作单位au。本实施例使用的输出的数据包含7种表情、效价,唤醒度以及20个动作单元的数值,频率为10hz。效价的数值在-1到1之间,其余所有数据均在0-1范围内,数值越高,程度越大。
40.网约车驾驶人在工作过程中,会由于等客或者休息等原因停车熄火,vbox会随着每次车辆熄火保存一个记录文件,行车记录仪每一分钟存储一个视频文件一名驾驶人的试验数据存储在多个文件中。为获得连续的数据,需要对每名驾驶人的文件进行纵向拼接。视频数据和车辆运动数据由两台设备采集,vbox设备默认记录标准utc时间,而行车记录仪显示的是北京时间。本实施例中将vbox的数据加8个小时转换为北京时间,实现时区统一。同时通过视频确定数据时间差,调整时间戳实现车辆运动数据和面部表情数据的同步,并进行横向拼接。拼接后的数据集总特征数为34个。
41.s102,通过临近值填补及直接删除的方法清除拼接后数据集中的无效数据。
42.在该数据集中,无效数据包括错误数据以及缺失值。错误数据主要存在车辆运动数据中,由于vbox启动后,需要一段时间锁定最少5颗卫星,才能够记录准确的数据。因此每个vbox文件前段卫星数小于5颗的数据,均为无效数据。车辆运动过程,由于树木或者高大建筑物的遮挡,gps接收器无法获得卫星信号,出现数据缺失。
43.在车辆视频数据中,当驾驶人的头部转动角度过大,如回头与乘客交谈,或者眼部被遮挡时,会因为无法对面部建模而产生缺失值。对于缺失值,则需要根据缺失值的类型、成因、数量和分布以及数据特点,采用合适的处理方式。由于vbox重新启动导致的无效值存在于每个数据文件的开头,特点明显,成段存在,填补的意义不大,且本实施例仅需要特定时段的运动数据,因此可以直接删除。因为gps信号遮挡产生的无效数据,若持续时间较短,
由于车辆数据之间有一定的时序性,且短时间内不会有较大的变化,因此使用临近值填补的方法处理。若长时间未收到卫星信号导致长时间的数据无效,则该段数据将被舍弃。面部表情数据会因为未捕捉到人脸,或眼眉被遮挡而产生缺失值,少量数据缺失,采用临近值填补,大量数据缺失则直接删除该片段。
44.s103,采用sg滤波方法对有效数据进行平滑处理,利用z-score法对平滑处理后的数据进行数据标准化处理。
45.在数据采集的过程中,由于设备故障或者数据传输问题,原始数据存在抖动的情况,出现轨迹锯齿,需要对数据做平滑处理,提高数据的光滑性,降低噪声对于建模的干扰。本实施例中采用sg滤波方法进行数据处理使得数据更加平滑,更贴近真实值。
46.数据的量纲会影响梯度下降的速度,当特征间的量级相差过大时,参数下降的速度过于缓慢,来回震荡,下降路径复杂,甚至无法找到全局最优解。由于本实例使用的数据存在量级差别,例如情绪和微表情数据在0-1之间,而车辆运动数据在在0-200之间变化,所以在使用关注特征量级的模型之前(支持向量机),采用z-score对特征进行缩放,表达式为:
[0047][0048]
其中x为原始特征值,μ为特征均值,δ为特征标准化,x
*
为转化后的特征值。
[0049]
s20,根据获得的车辆速度和横向加速度变化关系,选取急加速、急减速以及急转弯为标定对象,将加速度和速度数据结合,使用横向加速度阈值标定急转弯,使用纵向加速度阈值标定急加速和急减速,区分出正常驾驶样本和异常驾驶样本。
[0050]
(1)横向加速度阈值
[0051]
道路设计中曲线半径对弯道安全性的影响最为显著,车辆在圆形曲线上行驶时会受到径向力,通常称为离心力,由于向心加速度,还有一个作用于曲率中心的向外的径向力,道路设置倾斜度以平衡向心加速度,道路的这种倾斜度称为超高,向心加速度的大小取决于轮胎和路面之间的侧摩擦力,以及倾斜路面上车辆的重量,离心力fc表达式为:
[0052][0053]
其中:m为车辆质量,ac为车辆做曲线运动时的加速度;v为速度;r为曲线半径;w为车辆重量。
[0054]
如图2所示,当车辆相对于斜坡处于平衡状态时(车辆向前移动,但既不向上也不向下滑动时),fc表示离心力,fn表示支持力,水平方向的分力表达式为:
[0055]fc cosα=wsinα+wf
s cosα
[0056]
其中fs为径向摩擦系数,则曲线半径r表达式为:
[0057][0058]
则车辆做曲线运动时的加速度为:
[0059][0060]
将道路坡度设为0,则径向摩擦系数为:
[0061][0062]
其中g为重力,径向摩擦系数为:
[0063]fs
=0.21-0.001v
[0064]
其中v是车辆的速度,单位是km/h,则横向加速度阈值为:
[0065]ac
=(0.21-0.001v)g
[0066]
(2)纵向加速度阈值
[0067]
大多数驾驶人在遇到道路意外物体需要停车时,减速速率高于4.5m/s2,因此本实施例中选取4.5m/s2(对应0.45g)作为纵向加速度阈值。
[0068]
为了避免传感器数据波动对检测结果的影响,以及获得危险程度相对较高的驾驶行为,本实施例将横向加速度连续超过阈值持续时间超过1s设定为急转弯行为,纵向加速度的绝对值超过0.45g持续时间超过0.5s为急加速和急减速行为。将加速度第一次超过阈值的时间点设为危险驾驶行为开始时间点。
[0069]
本实施例中使用与道路线性设计以及速度相关的横向加速度阈值标定急转弯,使用纵向加速度阈值确定急加速和急减速发生的时间点,提取事件前15秒的数据。并根据时间戳对危险驾驶事前样本进行了挑选,保证样本内不包含上一次危险驾驶的数据,最终获得539个样本。同时按照相同的时间长度挑选了3937个正常驾驶片段,组成完整数据集。
[0070]
s30,将异常驾驶样本分成三类,分别为车辆运动数据、情绪数据以及微表情数据,通过对三类数据不同的搭配组合将异常驾驶样本划分为不同的特征集,利用不同的模型在每个特征集上进行建模,选取综合预测能力最好的模型作为最佳预测模型;
[0071]
特征集包括:情绪数据集emotion、微表情数据集au、车辆运动数据集car_motion、情绪数据集+微表情数据集emotion+au、车辆运动数据集+情绪数据集car_motion+emotion、车辆运动数据集+微表情数据集car_motion+au、车辆运动数据集+情绪数据集+微表情数据集all。其中情绪数据集包含七种基本情绪、效价和唤醒度,微表情数据集包含20个动作单元,车辆运动数据集包含速度、纵向速度、横向加速度、纵向加速度、航向角。
[0072]
本实施例中使用各种类别具有代表性的算法进行测试,模型包括决策树模型decisiontree、随机森林模型randomforest、梯度提升树模型gradientboosting、支持向量机模型svm以及朴素贝叶斯模型naive bayes model。比较不同预测模型在各个特征集上的表现,最佳预测模型的评价标准用参数f1表示,表达式为:
[0073]
f1=(2*precision*recall)/(precision+recall)
[0074]
其中precision表示准确率,recall表示召回率。
[0075]
利用不同的模型在每个特征集上进行建模包括:
[0076]
s301,为避免数据样本不均衡导致预测不准确,利用smote算法均衡训练集的正负样本数量,生成新的异常驾驶样本,使训练集正负样本比例为1:1;
[0077]
s302,每个模型在训练之前,使用贝叶斯优化算法调节模型超参数,在搜索过程中,使用5折交叉验证对模型的表现进行评估;
[0078]
s303,通过超参数的调整和交叉验证,结合不同的特征集进行建模,利用f1值比较不同模型预测性能。
[0079]
smote算法的主要概念是利用现有异常驾驶样本,通过最近邻算法人工生成少数
群体的新样本,原理如图3所示,首先任选一个少数类样本,然后在k近邻中任选若干个样本,最后在连线上生成新样本。
[0080]
通过比较不同预测模型在各个特征集上的表现,梯度提升树在所有特征集上均取得最优的预测能力,如表1所示,在使用车辆运动数据+情绪数据时,取得整体最好的预测效果,f1值为92.66%。因此选取梯度提升树作为最佳预测模型。
[0081]
表1模型预测性能表
[0082]
[0083][0084]
s40,通过改变最佳预测模型的输入特征集和时间窗,分析各特征集的预测能力随时间窗变化规律,找出预测危险驾驶行为的最佳特征集和最佳时间窗。
[0085]
改变时间窗包括:
[0086]
将时间窗进行更细致的切分,将时间窗起点从驾驶行为发生时刻向前滑动,滑动步长为δt,每个起点使用多种时间窗长度利用最优预测模型进行建模,使用网格搜索策略,根据危险驾驶行为模型的f1值确定最佳预测效果的时间窗和特征集组合。
[0087]
本实施例中用于驾驶行为预测的是事前15s数据,但并不确定这是最适合预测的输入数据。为了获得更好的预测效果,将15s数据进行更细致的切分,以确定最优的输入数据。时间窗从驾驶行为发生的时刻(拟定为0时刻)向前滑动,滑动部长为1s,每个起点尝试
使用多种时间窗长度进行建模。随着时间窗起点前移,可取最大的时间窗长度不断减小,当起点移动到行为前14s时,时间窗长度仅取1s。共建立120个预测模型,使用网格搜索策略,根据危险驾驶行为预测模型的性能,确定具有最佳预测效果的时间窗,具体的时间窗划分如图4所示。截取各个特征集预测能力排名前20的时间窗,如表2所示。可以看出,在微表情特征集上,模型使用0-15s的数据预测效果最佳,f1为60.45%。使用情绪数据时,使用行为前2-9s的数据可以获得最好的结果,f1为71.82%。使用车辆运动数据,前10个时间窗均是以事前0s为起点,最优的结果是使用事前0-3s的数据,f1可达93.10%。
[0088]
根据已有研究,40岁以下的驾驶人反应时间平均值小于1.1s,40岁以上的驾驶人反应时间平均值小于1.15s。本发明充分考虑现实驾驶员反应时间的需要,在预留1s驾驶人反应时间的情况下,使用全部特征可以获得的最佳预测效果,f1值为85.88%。
[0089]
表2特征集f1排序
[0090]
[0091]
[0092]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1