一种基于改进YOLOV5网络模型的马铃薯病害识别方法
一种基于改进yolo v5网络模型的马铃薯病害识别方法
技术领域
1.本发明涉及神经网络技术领域,尤其涉及一种基于改进yolo v5网络模型的马铃薯病害识别方法。
背景技术:
2.深度学习模型已被广泛应用于作物病害测量的各种应用中,作为最具代表性的深度学习算法之一,卷积神经网络(cnn)是解决当前图像分类问题的最佳方案。cnn结构通过残次结构深入学习层次特征,non-maximum suppression(nms)使用边界框衰减检测到对象,网络被解释为具有隐藏层、过滤器和超参数的普遍逼近定理,cnn在准确性和稳定性方面构成了一种经验证的高性能技术。
3.目前,在现有的研究中,已经提出了许多有效的深度卷积神经网络结构来对植物叶片病害进行分类。主要使用的数据集是基于plant village的某一类或者某一部分,例如:通过alex net网络识别健康和患病的植物,并用支持向量机和深度学习分类器对结果进行验证;针对植物叶片病害检测和分类的难点,基于ssd提出植物叶片深度块注意力ssd(dba_ssd)实现了植物叶片的病害识别和病害程度分类;使用深层自动编码器和残差神经网络(resnet50)分类器结合注意力机制senet模块识别番茄叶病害的十类特征,并在四类葡萄叶病害的对比实验取得了较高的准确率,轻量级网络模型在体积与速度方面具有较高的优势,一种基于mobilenet模型作为特征提取技术,利用emperor penguin optimizer(epo)算法优化超参数,基于extreme learning machine(elm)分类器为应用的植物叶片图像分配合适的类别标签进行分类。在最新的研究中,越来越多的大型深度学习模型被提出。vision transformer(vit)受到了相当多的关注,并削弱了cnn的主导地位,在主流分类基准上实现了类似甚至更高的性能。图像分类任务visual transformer方法的提出,指出了计算机视觉前途的未来方向。
4.通过对上述研究过程的分析,作物病害的识别主要分为,图像处理、作物的纹理特征提取,输入机器学习进行分类,或者使用卷积神经网络对深层次的作物特征进行识别提取。虽然上述研究在农作物图像分类方面取得了良好的进展。但相关研究关注较多的事考虑单个场景数据集的准确性,忽视了模型在实际生产中需要考虑的存储规模、推理时间、部署成本和应用环境。具体来说分为以下几个方面的不足:
5.(1)计算成本高:随着神经网络的不断发展,图像分类任务需要一个参数量庞大而复杂的网络来实现更高的精度。通常,训练庞大参数量网络模型将会需要强大的计算机能力和数据存储能力,然而,极其昂贵的计算成本和内存极大地阻碍了cnn在资源范围广泛的有限平台上的部署,特别是对于频繁执行的任务或实时应用程序。面向农业应用场景,应注重受限于野外自然环境以及低成本部署、简单易用等要求。
6.(2)方法通用性低:现有研究通常提取plant village数据集中相关的数据,这些数据具有不平衡的类别,另一方面,在plant village数据集添加部分当地采集或者网络收集数据集太少,容易过度拟合来训练模型,另一个问题是,大多数方法没有评估它们在看不
见的图像上的性能,因为数据集已经很小。当对看不见的数据进行测试时,任何模型的版本都可以标记为良好。
7.(3)训练周期长:当深度学习模型投入生产环境时,使用经典神经网络模型或者使用two-stage类模型在对数据集训练时,由于其模型参数量大,或由于需要先计算region proposal,而导致反向传播计算缓慢,且开发成本太高,维护和扩展困难,难以在移动设备上部署。
8.为解决上述实际问题,避免单纯的理论研究。因此,本文提出了一种高性能、低成本、适用性强、非常可行的方案来解决目前农业工业化图像分类的诸多问题。
技术实现要素:
9.本发明的目的在于提供一种基于改进yolo v5网络模型的马铃薯病害识别方法,从而解决现有技术中存在的前述问题。
10.为了实现上述目的,本发明采用的技术方案如下:
11.本发明提供了一种基于改进yolo v5网络模型的马铃薯病害识别方法,包括以下步骤:
12.s1,通过神经网络剪枝、知识蒸馏、actnn、低精度量化和激活权重压
13.缩过程构建基于改进yolo v5的深度神经网络模型;
14.s2,获取马铃薯病害图片数据,经过对病害图片的筛选、扩充后获得数据集;
15.s3,对数据集中的马铃薯病害图像进行预处理,并将预处理之后的数据集分为训练集、测试集和验证集;
16.s4,采用训练集对构建的基于改进yolo v5的深度神经网络模型进行训练,获取基于改进yolo v5的深度神经网络模型的各个参数指标,得到训练后的基于改进yolo v5的深度神经网络模型;
17.s5,采用验证集对训练后的基于改进yolo v5的深度神经网络模型进行验证,对测试结果的精度进行评价。
18.优选的,步骤s1中采用的神经网络剪枝通过识别网络中存在的几何中位数相接近filters,通过消除冗余的filters及其相关的输入输出关系,达到精简权重加速推理的目的;其中,几何中位数的计算公式如公式1所示:
[0019][0020]
其中x
*
是d维空间中参数最小值,表示几何中位数;f(x)是计算n点a1至ai的欧式距离之和最小值,每个公式(2)利用公式(1)几何中位数来获得i层内所有filters的欧式距离之和:
[0021][0022][0023]
[0024][0025]
表示i层的filters,x是i层的张量,式(3)表示i层的几何中位数,g(x)中所有filters欧式距离之和代入式(3),得到i层内最小的几何中位数,表示该层的数据中心;若考虑存在i层中与几何中位数相接近的filters是冗余的,则可以认为此filters是可以被替代的,式(4)计算得到的表示临近可替代的filters,被替代网络临近区域对整个网络来说影响很小,所以,对网络模型所有层确定可替代的filters;式(2)与式(4)可以进一步表示为式(5),由式(4)可知可被替代,即为则g
′
(x)=g(x)。
[0026]
优选的,步骤s1中的知识蒸馏过程包括以下内容:
[0027]
以原始模型作为教师模型,剪枝后的原始模型为学生模型,教师模型按照既定原则,使用一系列超参数使所述教师模型收敛到最优状态;然后,使用与所述教师模型的相同的超参数对所述学生模型进行知识蒸馏训练;蒸馏训练总损失包括蒸馏损失以及学生损失,其中所述蒸馏损失使用教师模型soft labels与soft predictions共同作用,学生损失通过系数β修正教师模型与学生模型蒸馏损失的错误率,由此得到总损失计算公式如下所示:
[0028]
l
total
=αl
soft
+βl
hard
[0029][0030][0031]
其中,l
total
表示总损失,l
hard
是学生损失;l
soft
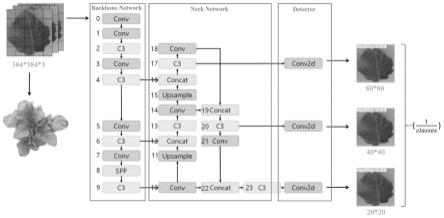
中,n为标签数量,为教师模型在系数t的softmax输出在i类的值;为学生模型在系数t的softmax输出在i类的值;l
hard
中,为学生模型在t=1下softmax输出在i类的值,cj为i类上的ground truth值,正标签取1,负标签取0。
[0032]
优选的,步骤s1中的采用actnn对yolo v5进行动态式随机量化过程具体包括:通过关注激活量化上下文来降低数值精度,从而实现在训练时对权重、激活和优化器的量化压缩。
[0033]
优选的,步骤s2中获取马铃薯病害图片数据,经过筛选、扩充后获得数据集具体包括:
[0034]
构建plant fruit disease数据集,将所述plant fruit disease数据集中的图片分别进行如下的数据增强处理,以扩充数据集:
[0035]
1),对数据集中的图片进行随机旋转0
°
、90
°
、180
°
或270
°
;
[0036]
2),以0.2随机概率改变数据集中图像的亮度、对比度、饱和度,以此来模拟图像在不同天气拍摄照片差异;
[0037]
3),在图像中随机添加运动模糊或者中值滤波,以模拟在田野环境中拍摄的不同定义的图像,随机概率值为0.2;
[0038]
4)将数据集中的图像随机添加gauss noise或者multiplicative noise噪声;
[0039]
对经过以上增强处理步骤的图像通过填充0像素将图像的分辨率扩展或缩放为512
×
512像素,由此获得扩充后的数据集。
[0040]
优选的,所述plant fruit disease数据集基于ai challenger数据集、pld开源数据集以及plant village。
[0041]
优选的,步骤s3中对扩充后的数据集进行预处理具体包括:从图像的色相、饱和度、明度与结构四个方面度量图像相似性,使用structural similarity index算法,设置相似度阈值为0.95,过滤掉相似度高于0.95的图像,获得预处理后的数据集;
[0042]
将预处理后的数据集划分为训练集、验证集和测试集的比例具体为:按照9:1划分训练验证集、测试集,训练与验证集则继续按照8:2划分。
[0043]
优选的,步骤s5中的精度评价指标采用精度dp、召回率drr、f1分数和平均精度map,具体计算过程如下:
[0044][0045][0046][0047][0048]
本发明的有益效果是:
[0049]
本发明提供了一种基于改进的yolo v5网络结构的马铃薯病害识别方法,该方法使用ra、focalloss、smoothbce策略改进神经网络架构,同时还提出了模型参数压缩剪枝与知识蒸馏;模型内存激活参数压缩actnn两条技术路线,用于不同硬件条件下的模型训练与识别,最后利用简化算子与int8量化进一步优化,并在面向移动端深度学习推理平台ncnn进行部署,形成工业级解决方案。在51,772张马铃薯作物病害图像中达到了94%的map,每个样本的推理时间平均为1.5毫秒。因此,本研究可以为解决当前农业图像分类中常见的问题提供坚实的理论与实践基础,同时在精度和计算成本方面优势能满足农业工业化的需求。
附图说明
[0050]
图1是实施例1中提供的基于改进的yolo v5网络模型的马铃薯病害识别方法技术路线图;
[0051]
图2是实施例1中采用的yolo v5网络模型结构图;
[0052]
图3是实施例1中采用fpgm剪枝过程流程图;
[0053]
图4是实施例1中采用的知识蒸馏流程示意图;
[0054]
图5是实施例1中采用的actnn压缩与解压缩过程示意图;
[0055]
图6是实施例1中采用的层融合和数据重用流程示意图;
[0056]
图7是置信度精确率曲线与召回率精确率曲线,(a)是反应置信度与精确率连续变量的综合指标,(b)是反应召回率与精确率连续变化的综合指标;
[0057]
图8是ai challenger精确率、参数下降、稀疏率曲线与pfd精确率、参数下降、稀疏率曲线;
[0058]
图9是稀疏训练时模型权重变化直方图;
[0059]
图10是温度参数对知识蒸馏的影响示意图。
具体实施方式
[0060]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
[0061]
实施例1
[0062]
本实施例提供了一种基于改进yolo v5网络模型的马铃薯病害识别方法,如图1所示,包括以下步骤:
[0063]
s1,通过神经网络剪枝、知识蒸馏、actnn、低精度量化和激活权重压缩过程构建基于改进yolo v5的深度神经网络模型;
[0064]
s2,获取马铃薯病害图片数据,经过对病害图片的筛选、扩充后获得数据集;
[0065]
s3,对数据集中的马铃薯病害图像进行预处理,并将预处理之后的数据集分为训练集、测试集和验证集;
[0066]
s4,采用训练集对构建的基于改进yolo v5的深度神经网络模型进行训练,获取基于改进yolo v5的深度神经网络模型的各个参数指标,得到训练后的基于改进yolo v5的深度神经网络模型;
[0067]
s5,采用验证集对训练后的基于改进yolo v5的深度神经网络模型进行验证,对测试结果的精度进行评价。
[0068]
本实施例中的深度神经网络模型包括yolo v5s、yolo v5m、yolo v5n模型,均采yolo v5框架,主要结构如图2所示,包括neck network、backbone network和detect network。neck network是一种卷积神经网络(cnn),它结合了各种细粒度图像并形成图像特征。确切地说,neck network旨在减少模型的计算并加快训练速度。conv模块为yolo v5的基本卷积单元,对输入依次进行二维卷积、二维正则化、加权线性单元(silu)激活操作。c3模块由3个conv与若干个bottleneck组成,组成的结构依次添加到计算图。bottleneck在不减少特征的同时完成残差特征传递。并将输出结果进concat拼接,输出深度与输入深度
相同,c3模块转换输入数据,在bottleneck层进行计算,将初始输入的conv值和concat中bottleneck计算值相加,然后收敛并输出。bottleneck继续处理输入值上的conv(1,1),并输出conv(3,1)的计算值。conv操作后,spp使用5*5、9*9、13*13进行max pooling操作,将concat中的三个max pooling值与现有输入值中的conv值组合,并在conv后发送。上采样upsample是pytorch的基础库函数,该函数将结构值中每个特征贴图数组的数量增加一倍。concat扮演合并输入层的角色。
[0069]
neck network的第十一层与十五层使用upsample模块对特征进行扩大,backbone network中的四层与六层提取的特征传递给neck network融合。neck中将第四层与上采样后的十五层使用concat进一步融合,后将融合后的第十四层与二次融合后的第十八层再次融合,小目标检测采用较深第九层网络特征融合二十一层conv,融合形成更大定的特征图输出到detector进行预测。由于detector当前有三个conv2d值作为结果,因此将三个值合并输出。yolo v5拥有三个特征检测尺度,适用于不同大小的特征检测,同时yolo v5具有增强训练数据的特性。数据加载器可以执行多种类型的数据增强,但具有一定的局限性。
[0070]
深度学习性能的突破离不开模型规模的疯狂增长,参数量较大模型通常有更好的性能已经成为业界的共识;但是,由此而来的内存墙问题限制了ai模型参数的指数增长,因此需要对模型进行压缩,主要包括神经网络剪枝、低精度量化、知识蒸馏和激活权重压缩。
[0071]
本实施例中所采用的神经网络剪枝过程如图3所示,具体包括:通过识别网络中存在的几何中位数相接近filters,通过消除冗余的filters及其相关的输入输出关系,达到精简权重加速推理的目的;其中,几何中位数的计算公式如公式1所示:
[0072][0073]
其中x
*
是d维空间中参数最小值,表示几何中位数;f(x)是计算n点a1至ai的欧式距离之和最小值,每个
[0074]
公式(2)利用公式(1)几何中位数来获得i层内所有filters的欧式距离之和:
[0075][0076][0077][0078][0079]
表示i层的filters,x是i层的张量,式(3)表示i层的几何中位数,g(x)中所有filters欧式距离之和代入式(3),得到i层内最小的几何中位数,表示该层的数据中心;若考虑存在i层中与几何中位数相接近的filters是冗余的,则可以认为此filters是可以被替代的,式(4)计算得到的表示临近可替代的filters,被替代网络临近区域对整个网络来说影响很小,所以,对网络模型所有层确定可替代的
filters;式(2)与式(4)可以进一步表示为式(5),由式(4)可知可被替代,即为则g
′
(x)=g(x)。
[0080]
模型剪枝后,模型的准确性普遍会降低,即使重新对剪枝后的模型微调,该模型的准确性仍可能与剪枝前模型存在较大的差距。因此,本实施例中可以通过知识蒸馏(konwledge distillation,kd)来解决这个问题,从而最大限度地减少精度损失,本实施例中的知识蒸馏过程如图4所示,主要包括以下内容:
[0081]
以原始模型作为教师模型,剪枝后的原始模型为学生模型,教师模型按照既定原则,使用一系列超参数使所述教师模型收敛到最优状态;然后,使用与所述教师模型的相同的超参数对所述学生模型进行知识蒸馏训练;蒸馏训练总损失包括蒸馏损失以及学生损失,其中所述蒸馏损失使用教师模型soft labels与soft predictions共同作用,学生损失通过系数β修正教师模型与学生模型蒸馏损失的错误率,由此得到总损失计算公式如公式(6)所示:
[0082]
其中hard label(ground truth)可以有效降低错误被传播给学生模型的可能性。衡量学生与教师模型相似性,可用式(6)表示,是一个能够衡量相似性的函数,
[0083][0084][0085]
具体用softmax表示,一般情况下,当softmax输出的概率分布熵值相对较小时,负标签的值很接近0,对损失函数的贡献非常小,这导致蒸馏过程中学生模型对于负标签的关注度降低,式(7)中温度系数t解决了这个问题。其中i是输入到softmax层的logits。t越高,softmax输出类别值概率越趋于平缓。总损失l
total
由式(8)、式(9)、式(10)表示,α与β是平衡系数,l
soft
是蒸馏损失,l
hard
是学生损失;l
soft
中,n为标签数量,为教师模型在系数t的softmax输出在i类的值;为学生模型在系数t的softmax输出在i类的值;l
hard
中,为学生模型在t=1下softmax输出在i类的值,cj为i类上的ground truth值,正标签取1,负标签取0。以上kd理论,本文同样在yolo v5上进行了实现。
[0086]
l
total
=αl
soft
+βl
hard
ꢀꢀꢀ
(8)
[0087]
[0088][0089]
本实施例中的低精度量化存储的实现方式具体是:
[0090]
量化存储可概括为式(11),其中q为fp32类型实数r的量化值,而缩放系数scale与zp共同确定量化q;其中和分别是模型权重张量中的最大值和最小值(fp32)。[int8
min
,int8
max
]是int8的值范围,float与round函数分别表示转换为单精度浮点数、四舍五入使用以下方法将fp32映射到int8,其中x
float32
表示fp32权重,x
int8
表示int8权重。
[0091]
r=scale(q-zp)
ꢀꢀꢀ
(11)
[0092][0093][0094][0095]
由于存储onnx的int8模型时,量化存储的scale与zp值可以保存下来,因此,无论载入到那个框架,在推理阶段,可以使用以下公式将网络参数还原为fp32类型,模型的推理时间和模型精度保持不变:
[0096]
x
float32
=(x
int8-zp)
ꢀꢀꢀ
(15)
[0097]
×
scale
[0098]
本实施例中采用的随机量化激活actnn实现了一种动态式随机量化激活神经网络的方法,该算法通过关注激活量化上下文来降低数值精度,从而实现在训练时对权重、激活和优化器的量化压缩。本实施例中的随机量化激活actnn压缩和解压缩的过程如图5所示,actnn定义了l1至l5压缩程度依次提高的可选压缩参数,其中l1与l2使用4bit per-group quantization进行压缩,但l1允许使用32bit量化,且只处理卷积层;l3至l5分别在2bit下使用fine-grained-mixed-precision、swapping、defragmentation压缩,它们作用于所有
层的激活结果,具体处理效果取决于你使用actnn模块处理原始模型的比例,处理过程只在训练中进行,检测过程不在涉及。此外,如式所示,l1至l5使用的压缩算法是前一个压缩级别的叠加,在训练过程中,相同的硬件条件下,压缩级别越高,反向传播时对激活结果解压缩的时间就越长,则训练速度越慢,从调节参数与数据角度讲,增大batch size与使用高分辨率图像都会增加ca与dca的时间,减缓模型收敛效率。
[0099]
目前,训练后产生模型的卷积层上下文各层是可被优化的。推理框架在推理阶段的大多数操作可以简化为线性操作,简化模型结构一般需要使用融合技术进行线性优化,单个卷积层中涉及的步骤序列是卷积操作,偏置加法、批量归一化算子(batch-normalization-operators)和激活函数(silu、hardswish、mish),融合机制将这些步骤组合在一起形成单个步骤,即同时执行,如图6所示。
[0100]
为有效匹配实际农业场景的部署应用,进一步实现模型加速,减少硬件负担,本文将简化后的模型转换为ncnn模型,然后通过ncnn c++api加载它。选择使用ncnn(tencent’s neural network inference framework)是因为为它是针对arm移动平台优化的高性能神经网络推理计算框架,该框架完全用c++语言实现,不依赖任何第三方库。可方便的在多种设备终端高效部署。
[0101]
本实施例中构建数据集是基于ai challenger与pld开源数据集,还有部分plant village作物病害数据。plant village数据集包含54306张健康和患病叶片图像,该数据集由256
×
256大小jpg彩色图像组成,按物种和疾病分为38类(26种疾病,14种作物物种)。而pld数据集,从巴基斯坦旁遮普省中部地区收集的4072幅马铃薯病害图像,病害包括early blight、late blight、healthy三类。ai challenger数据集以物种、病害、程度划分共计61个类别,10个物种,27种病害,但其中存在较多的不平衡类别,个别类别的数量极少。
[0102]
本实施例中的pfd数据集包含51722张作物病害图像数据,图像尺寸width为256,height为256-512之间,主要由ai challenger数据集以及部分plant village、pld构成,其中在ai challenger数据集中存在类别不平衡或者错误的4类作物病害。tomato bacterial spot bacteria、tomato target spot bacteria两类病害,存在严重的标注错误,因此本文抽取plant village数据集进行替换;获得的数据集如表1所示。
[0103]
表1
[0104][0105]
本文使用python的albumentations库的图像数据生成器方法,对数据集中存在的2类不平衡病害应用不同的数据增强技术,以克服过度拟合,增强数据集的多样性,如表1所示。
[0106]
1.spin:将图片随机旋转0
°
、90
°
、180
°
、270
°
,模拟自然条件下拍摄角度的随机性,不会改变作物患病与健康特征的相对位置。
[0107]
2.color jitter:识别农作物病害场景多在田间,受天气影响较大,以0.2随机概率改变图像的亮度、对比度、饱和度来模拟图像在不同天气拍摄照片差异。
[0108]
3.blur:在图像中随机添加运动模糊或者中值滤波,以模拟在田野环境中拍摄的不同定义的图像,随机概率值为0.2。
[0109]
4.noise:将图像添加gauss noise或者multiplicative noise噪声,以泛化多个图像,屏蔽图像采集设备、自然环境因素等诸多因素的差异。
[0110]
5.resize:对经过以上步骤的图像,通过填充0像素将图像的分辨率扩展或缩放为512
×
512像素。
[0111]
后经过数据分析,发现数据集中马铃薯叶片病害相关品种的数据较少,由于马铃薯种业发展迅速,本文从pld数据集中选择4072张图像数据补足这部分差异。最终,经过统计,pfd数据集标签类别由作物物种、病害名称与病害程度构成,包括59个病害类别,10个作物物种,27种病害分类(其中22个病害有分一般和严重两种程度),10个健康作物分类。
[0112]
本实施例中步骤s3中对数据集进行预处理的过程,具体如下:
[0113]
pfd数据集样本中存在较多的人为标注数据,这部分数据可能存在重复的样本,从而导致模型求解的最终结果会偏向于降低这部分样本的训练误差,而牺牲其他样本的训练误差,即oversampling。本实施例从图像的色相、饱和度、明度与结构四个方面度量图像相似性,使用structural similarity index(ssim)算法,相似度阈值为0.95(最大值为1),过滤掉相似的图像,考虑到相似性图像样本会影响模型的泛化性,对低于相似度阈值每一类图像本文进行保留。最终,去重后的数据集总计为51772。使用hold-out方式,按照9:1划分训练验证集、测试集,训练与验证集则继续按照8:2划分,如表2所示。
[0114][0115]
本实施例中所采用的操作平台为nettrix x640 g30 ai服务器,操作系统环境为ubuntu 20.04,cpu为2块intel(r)xeon(r)gold 6226r cpu@2.90ghz,gpu为两台n-vidia geforce rtx 3090、256g内存、7.5t固态驱动器。训练环境由anaconda3创建,环境配置为python 3.9.5、pytorch 1.10.1与tor-ch vision 0.10.1人工神经网络库。同时,采用cuda 11.1深度神经网络加速库。
[0116]
采用图2所示yolov5网络对pfd数据集训练,全局损失函数使用bc eloss[38],优化器使用sgd,batch size为128,输入图像尺寸为384,学习率初始化为0.0032,最终为0.12,动量参数为0.843,重量衰减设置为0.00036,并使用预热参数5.0保证模型对数据具有一定的先验知识。其他参数保持默认,进行1000个epochs预训练。取得初始训练模型之后,发现模型的性能与本文的预测有一定的距离,因此,本文对模型再一次进行微调。虽然本文使用了表3参数对图像增广,但是样本中很可能还存在正负样本比例失衡的问题,所以在原损失函数中加入focalloss与smoothbce,并设置flgamma为1.5,s moothbce作用是降低模型过拟合可能性,并改用batch size为64,输入图像尺寸为512。其他超参数设置与预训练相同,使用early stopping机制参数设置为100次。此外,本文对模型进行五次微调训练,每次执行300个epochs,并以最高精度记录结果,然后使用最佳结果作为下一步的输入。
[0117]
本实施例中的精度评价采用精度(dp)、召回率(drr)、f1分数(f1)、平均精度(map):
[0118]
[0119][0120][0121][0122]
除此之外,为了进一步比较本文提出的提升精度的方法,本文使用消融实验的方式来处理分类任务,这三种方法都基于yolo v5s,包括:
[0123]
(1)method1:使用基于ra抽样策略的data augmentation方法。
[0124]
(2)method2:修改原始损失函数、在原损失函数中加入focalloss与smoothbce损失函数。
[0125]
(3)method3:同时使用基于ra抽样策略的data augmentation与使用focalloss与smoothbce损失函数。
[0126]
本文在ai challenger与pfd数据集进行了实验,这两个数据集的分类结果如表4所示。表4显示了使用本文的三类方法以及yolo v5三类模型相比较时的准确性分类性能指标,这些结果都是产生于最新的研究方法。
[0127]
在这六个模型中,pfd数据集的结果要优于所有同层次模型ai challenger数据集的结果。在精度方面,不考虑本文提出的方法,三个基于yolo v5原始模型的方法,在dp、f1、map分别至少有1.6%、2.3%、1.7%的优势。此外,在训练过程中,ai challenger的四类不平衡作物病害类别对yolo v5原始模型的整体性能都有不同程度的影响,这个现象可归结于其样本数量的严重不足,特别是其中存在标注错误的样本使得准确率反而更差;在pfd数据集中,本文去掉了标注错误的两类作物病害类别、并对另两类样本较少的类别使用数据增强重新生成数据图像,从实验结果上看,性能指标都要优于原始数据集;后补充的马铃薯叶片病害数据也没有对模型整体性能造成影响,个别性能指标高于未加入pld的pfd数据集。因此,本技术中采用的构建pfd数据集方法被证明是成功的。
[0128]
在本文提出的三个方法中,method3的综合性能要优于其他两种方法,且在ai challenger与pfd数据集的表现要优于原始yolo v5s模型。从三种方法中选择最低的性能指标与原始yolo v5s模型对比,在ai challenger中map高出0.4%,而在pfd数据集中则高出1.5%。此外,一个有趣的现象是,method1在ai challenger的map要优于原始yolov5s模型,而在pfd数据集中,则低于原始yolo v5s模型0.6%的map,经过分析,造成这种现象的主要原因是本文使用ra抽样策略取得的预训练超参数是建立在ai challenger之上,将其应用在pfd出现了性能的负增益;而在method2使用了新的策略,使得其性能恢复并提高1.5%,由此可知,method1与method2具有一定的相互补充的作用。此外,method3对于drr的提升要显著一些,两个数据集分别提高了1.2%、2.1%。综上所述,本文提出两种策略得到
的method3对于原始yolo v5s模型的改进是成功的。
[0129]
为了清楚的说明该效果,采用图7进行直观描述。
[0130]
剪枝过程中的稀疏率对于剪枝效果有很大的影响,对此,本发明在0.001至0.1稀疏率下对原始模型进行稀疏训练实验,以method3作为原始模型,实验结果如图8所示,说明yolo v5s模型空间的冗余参数阈值在0.009稀疏率左右,这对其它应用稀疏化具有一定的指导作用。
[0131]
然后对剪枝方法进行对照,以slim-filter-pruner、l1-norm-pruner和l2-norm-pruner剪枝算法作为参照组,最终的精度和参数影响结果如表5所示,很明显本实施例中采用的剪枝方法更有效。
[0132]
表5
[0133][0134]
虽然选择使用最优剪枝率可以尽可能的保持模型的精度,但与原模型相比,检测的精度仍下降不少,而通过使用知识蒸馏方法可以恢复模型的精度,甚至进一步提高修剪模型的性能。对知识蒸馏的温度影响进行了对比实验,本文将知识蒸馏的整个训练过程分为两个阶段,首先,选择原始模型作为教师模型,剪枝率0.4下的四个修剪模型作为学生模型进行实验,依据hinton实验提出的温度t对于模型性能的影响,本文通过kd用不同的t(1,5,10,15)训练学生模型。训练设置使用前面实验相同超参数,但是优化器使用adam,并降低起始学习率为0.0001,α与β平衡系数分别为1.0和0.8。
[0135]
通过使用不同的温度t,在教师模型结构相同的情况下,得到如图9所示结果。结果显示在蒸馏温度t为10或者15时,模型通常能够取得较好的性能,接近全精度。
[0136]
最后,将模型蒸馏训练后的修剪模型相对于未修剪模型与原始模型的性能变化进行对比,如表6所示,显示了四类剪枝算法中method3模型的平均测试精度、模型参数与计算所需浮点运算量。本文还计算了知识蒸馏相对于剪枝模型的性能改变百分比。结果表明,剪枝后的四个模型,通过本文的方法使模型性能都得到较大的提升,与原始模型相比,参数量降低了56%,由此可见本实施例中的模型蒸馏技术最有效。
[0137]
表6
challenger与pld数据集使用多种数据增强方法平衡病害类别,构建了pfd数据集,然后使用两种策略改进原始yolo v5s模型提出了method3,实现了多种作物叶片图像的病害分类。同时考虑了模型的存储大小、推理时间、部署成本和应用环境对模型在农业应用场景的影响,本文提出的fpgm-yolov5模型剪枝方法在method3上取得了显著的效果,其中所提出的方法优于其他剪枝方法,后使用知识蒸馏技术对剪枝后模型进行性能恢复,相同试验环境下在不同温度t均取得了较好的效果,性能接近原始模型。此外,提出的actnn对训练模型进行激活参数压缩,解决了硬件性能不足或训练大参数模型的问题。最后,在简化算子与int8量化对模型的帮助下,模型性能进一步提高,并在ncnn部署模型取得了最佳效果,节省了大量的计算成本和时间。结果表明,目前最先进的actnn、yolo v5模型与模型剪枝、知识蒸馏技术的相互协作,均取得了较好的效果,有效地解决了当前农业图像分类中常见的问题,对精准农业具有广阔的应用前景,提升农业工业效率。未来,这方面的研究将扩展到更复杂的农业场景中。
[0144]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1