基于混合MASK的POI地址纠错方法、装置、存储介质和设备与流程
基于混合mask的poi地址纠错方法、装置、存储介质和设备
技术领域
1.本发明涉及数据检索技术领域,具体而言,本发明涉及一种基于混合mask的poi地址纠错方法、装置、计算机可读存储介质和计算机设备。
背景技术:
2.检索召回是指对用户输入的查询信息进行全方面的意图理解,从多个角度挖掘查询信息中包含的关键数据信息,进而通过多路召回返回符合需求的结果,满足用户检索需求。当用户输入查询信息时,可能会由于手误打出了错别字,如果根据这个查询信息内容进行检索召回,那返回的内容可能就不满足用户的预期,当用户需求得不到满足时,会直接影响用户发单情况,因此需要进行中文纠错。在现有技术中,中文纠错主要采用以下几种方案:1、基于规则的中文字符纠错方法优点:可以直接根据中文语法的主谓关系、动宾关系、修饰关系、补充关系等,设计符合目的规则,根据中文分词结果匹配出错位位置短语;或者在某种特定场景下,设计一定的汉字组合规则即可覆盖大部分用户的搜索内容。
3.缺点:规则匹配方式较为粗暴,设计人员需要从历史数据中尽可能多的挖掘出用户输入的错误汉字,以此来设计出相应的规则来覆盖这些例子;与此同时,这种方式无法对未出现的状况进行解析,必须在出现问题后才能解决,不具有较好的泛化能力。
4.2、基于统计语言模型的中文纠错方法优点:统计语言模型的纠错方法是基于n-gram语言模型实现的,模型通过统计字词之间例如2-gram、3-gram前后共同出现的频次来建立词表中的各个汉字之间的关系,这个分布真实,正确的词语ppl困惑度值较低,反之,错误的词(即存在错别字的词)ppl困惑度值较高,能够直接的根据历史数据核查用户输入的汉字中是否存在错别字。
5.缺点:基于统计语言模型的方式同样存在泛化能力较弱的问题,同时因为统计语言模型是基于n-gram建模,当用户输入请求较长,即其是由多个词语构成的句子时,统计语言模型的打分的真实度就会降低,ppl困惑度分数就会存在异常。
6.3、基于seq2seq的中文纠错方法优点:seq2seq可采用rnn、lstm等多种方式实现encoder-decoder的模型架构,模型根据大量的用户历史行为数据建模,神经网络中各层参数的非线性映射会激活在更多维空间内的潜在特征,从而更充分的理解用户意图,修正用户输入中存在的错误汉字,其具有较优的泛化能力。
7.缺点:模型将汉字转为对应向量时依赖于向量表示的准确性,向量所蕴含的语义影响后期向量之间的交互能力,较多依赖大量的人工标注好的数据;模型训练过程相对于其他方法代价较大,寻找一组相对完善的参数需要消耗更多的时间,不能鲁棒的预测未知的错误汉字。
8.因此,在地址信息检索召回应用场景中,亟需一种能够避免上述缺点的poi地址纠
错方法。
技术实现要素:
9.为至少能解决上述的技术缺陷之一,本发明提供了以下技术方案的基于混合mask的poi地址纠错方法及对应的装置、计算机可读存储介质和计算机设备。
10.本发明的实施例根据一个方面,提供了一种基于混合mask的poi地址纠错方法,包括如下步骤:获取用户输入的poi地址信息;将所述poi地址信息通过映射转换为id序列;判断是否对所述id序列进行掩码;若是,以p1概率将所述id序列中的一个字符替换为mask,或以1-p1概率将所述id序列中的至少两个字符替换为mask,其中所述至少两个字符为一个实体词语的概率为p2;若否,保持所述id序列不变;根据保持不变的id序列或掩码后的id序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息。
11.优选地,所述以1-p1概率将所述id序列中的至少两个字符替换为mask,其中所述至少两个字符为实体词语的概率为p2,包括:对于要将至少两个字符替换为mask的id序列,以1-p2概率将其中的任意两个字符替换为mask,或以p2概率将其中的一个实体词语替换为mask。
12.优选地,所述以p2概率将其中的一个实体词语替换为mask,包括:对于要将其中的一个实体词语替换为mask的id序列,先确认该id序列中要被替换为mask的一个字符,判断该字符与其前后两位字符中是否存在与预设poi地址词表匹配的实体词语,若是,将包括该字符的实体词语替换为mask,若否,将该字符与其前一位字符或该字符与其后一位字符所构成的词语作为实体词语替换为mask。
13.优选地,所述预设poi地址词表通过以下步骤预先生成:获取历史用户检索poi地址信息时的历史使用数据;从所述历史使用数据中提取poi拼接字段;对所述poi拼接字段进行分词和词频统计,得到多个实体词语及对应的词频;根据所述词频大小排在前预设占比的实体词语,生成预设poi地址词表。
14.优选地,所述根据保持不变的id序列或掩码后的id序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息,包括:获取城市信息编码;将所述城市信息编码与保持不变的id序列或掩码后的id序列进行拼接,得到拼接后的序列;根据拼接后的序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息。
15.优选地,所述根据拼接后的序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息,包括:在拼接后的序列中,将掩码后的id序列中被替换为mask的字符替换为对应的预设字集,通过映射转换得到最终拼接序列;
将所述最终拼接序列输入预先训练生成的纠错模型,得到纠错后的poi地址信息。
16.优选地,所述纠错模型为基于多头注意力机制的bp神经网络模型。
17.此外,本发明的实施例根据另一个方面,提供了一种基于混合mask的poi地址纠错装置,包括:地址信息获取模块,用于获取用户输入的poi地址信息;序列化模块,用于将所述poi地址信息通过映射转换为id序列;混合mask模块,用于判断是否对所述id序列进行掩码;若是,以p1概率将所述id序列中的一个字符替换为mask,或以1-p1概率将所述id序列中的至少两个字符替换为mask,其中所述至少两个字符为一个实体词语的概率为p2;若否,保持所述id序列不变;模型纠错模块,用于根据保持不变的id序列或掩码后的id序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息。
18.本发明的实施例根据又一个方面,提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述的基于混合mask的poi地址纠错方法。
19.本发明的实施例根据再一个方面,提供了一种计算机设备,所述计算机包括一个或多个处理器;存储器;一个或多个计算机程序,其中所述一个或多个计算机程序被存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个计算机程序配置用于:执行上述的基于混合mask的poi地址纠错方法。
20.本发明与现有技术相比,具有以下有益效果:本发明提供的基于混合mask的poi地址纠错方法、装置、计算机可读存储介质和计算机设备,通过对用户输入的poi地址信息进行预处理、序列化、基于混合mask机制的掩码操作,并输入至基于深度学习算法预先训练生成的纠错模型,最终得到纠错后的poi地址信息,本方案所采用的混合mask机制掩码方式扩大了纠错面,提升容错率,有效保证纠错模型的纠错准确率,进而可以提升货运应用场景相关的poi地址信息召回能力,满足用户检索需求,从而进一步提升用户发单情况。
21.本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
22.本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:图1为本发明实施例提供的一种基于混合mask的poi地址纠错方法的方法流程图;图2为本发明实施例提供的另一种基于混合mask的poi地址纠错方法的方法流程图;图3为本发明实施例提供的基于混合mask的poi地址纠错装置的结构示意图。
具体实施方式
23.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附
图描述的实施例是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
24.本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。
25.本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语),具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语,应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样被特定定义,否则不会用理想化或过于正式的含义来解释。
26.本发明实施例提供了一种基于混合mask的poi地址纠错方法,该方法主要应用于地址信息检索召回相关的应用场景,例如货运应用场景下的poi地址信息检索召回。地址信息检索召回是指对用户输入的query,即检索查询内容进行全方面的意图理解,从多个角度挖掘query中包含的关键数据信息,进而通过多路召回返回符合需求的结果,满足用户检索需求。当用户输入query时,可能会由于手误打出了错别字,如果根据这个包含错别字的query内容进行检索召回,那返回的内容可能就不满足用户的预期。在货运应用场景中,当用户需求得不到满足时,可能会直接影响用户发单情况。
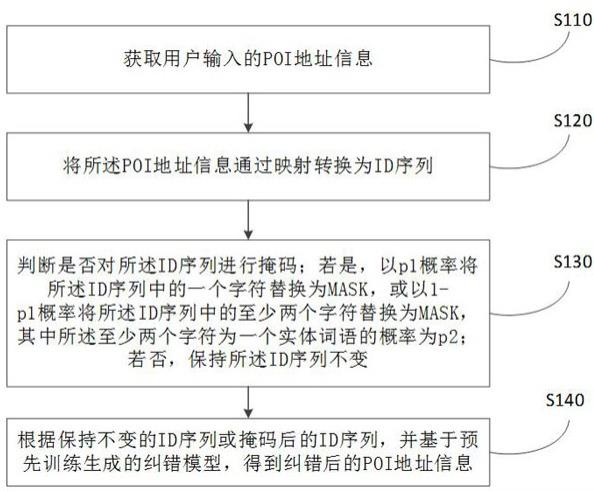
27.如图1所示,所述基于混合mask的poi地址纠错方法包括:步骤s110:获取用户输入的poi地址信息。
28.对于本实施例,用户输入的检索查询内容具体为poi地址信息。
29.poi是“point of interest”的缩写,中文可以翻译为“兴趣点”。在地址信息检索相关的应用场景中,一个poi可以是一栋房子、一个商铺、一个邮筒、一个公交站等。在货运应用场景中,poi地址信息检索查询主要是为了获取货运服务的起点和终点的地理位置信息,进而实现对货运服务的起终点进行定位。
30.步骤s120:将所述poi地址信息通过映射转换为id序列。
31.在获得用户输入的poi地址信息之后,对所述poi地址信息进行预处理,所述预处理具体为包含空值处理、特殊符号过滤、繁体简体转换等数据清洗操作。
32.对于本实施例,预先设置有向量id映射表,在向量id映射表中,每个字符对应一个id,id对应相应的向量表示,形如《字符,id,embedding》。在poi地址信息经过预处理后,进一步进行序列化,基于预先设置的向量id映射表将所述poi地址信息通过映射转换为id序列。
33.步骤s130:判断是否对所述id序列进行掩码;若是,以p1概率将所述id序列中的一个字符替换为mask,或以1-p1概率将所述id序列中的至少两个字符替换为mask,其中所述至少两个字符为一个实体词语的概率为p2;若否,保持所述id序列不变。
34.对于本实施例,所获取的poi地址信息可以由省、市、区、实体名称、具体街道号或门牌号等多个字符构成,每个输入字符都有一定的概率是错别字。在实际应用中,对应不同的应用场景,预先统计分析有需要纠错的检索查询内容占比,该占比即为对检索查询内容进行掩码的概率。
35.具体地,根据基于rand()函数生成的第一随机数和所述对所述id序列进行掩码的概率,判断是否对所述id序列进行掩码,设定若生成的第一随机数小于该概率,则需要对所述id序列进行掩码,否则则不需要对所述id序列进行掩码,保持所述id序列不变,在后续步骤中直接采用原来的id序列。
36.例如,对应货运应用场景下的poi地址信息检索召回应用场景,经预先统计分析得知,用户输入检索查询内容的信息长度大多分布在12~22个字符,其中有需要纠错的检索查询内容占比约为10%,则将所述id序列进行掩码的概率为10%,即0.1,具体地若基于rand()函数生成的第一随机数小于0.1,则需要对所述id序列进行掩码,否则则不需要对所述id序列进行掩码,保持所述id序列不变,在后续步骤中直接采用原来的id序列。对所述id序列进行掩码的概率也可以根据实际统计分析结果调整为0.15、0.2等值,本发明实施例对该概率的具体取值不作限定。
37.对于本实施例,对于需要进行掩码进行的id序列,以p1概率将所述id序列中的一个字符替换为mask,或以1-p1概率将所述id序列中的至少两个字符替换为mask,其中所述至少两个字符为一个实体词语的概率为p2。
38.对应不同的应用场景,预先统计分析有单字错误、二字错误和多字错误的占比,基于上述占比设定对不同数量字符进行掩码的概率。具体地,基于rand()函数生成的第二随机数,判断第二随机数是否小于所述概率p1对应的数值,若是,则将所述id序列中的一个字符替换为mask,若否,则将所述id序列中的至少两个字符替换为mask,可知将所述id序列中的至少两个字符替换为mask的概率为1-p1。
39.例如,对应货运应用场景下的poi地址信息检索召回应用场景,经预先统计分析得知,在需要纠错的检索查询内容中,单字错误占比约为90%,二字错误占比6%,其余为多字错误,因为多字错别分布较散,则所以对于需要进行掩码进行的id序列,将id序列中的一个字符替换为mask的概率p1为90%,将所述id序列中的至少两个字符替换为mask的概率1-p1为10%。相应地,基于rand()函数生成的第二随机数,判断第二随机数是否小于所述概率p1对应的数值,即0.9,若是,则将所述id序列中的一个字符替换为mask,若否,则将所述id序列中的至少两个字符替换为mask,可知将所述id序列中的至少两个字符替换为mask的概率1-p1对应的数值为0.1。将id序列中的一个字符替换为mask的概率p1也可以根据实际统计分析结果调整为0.95、0.8等值,本发明实施例对p1的具体取值不作限定。
40.对于本实施例,对于需要将至少两个字符进行掩码的检索查询内容,这其中包含分散的单字符错误、连续实体词语错误。对应不同的应用场景,预先统计分析有分散的单字错误、连续实体词语错误的占比,基于上述占比设定对实体词语进行掩码的概率p2。例如,对应货运应用场景下的poi地址信息检索召回应用场景,经预先统计分析得知,对于需要将至少两个字符进行掩码的检索查询内容,实体词语错误占比约为10%,则对于需要将至少两个字符替换为mask的id序列,其中将一个实体词语替换为mask的概率为10%。
41.步骤s140:根据保持不变的id序列或掩码后的id序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息。
42.对于本实施例,根据保持不变的id序列或掩码后的id序列得到输入数据特征向量,将输入数据特征向量输入至预先训练生成的纠错模型中进行预测,对于掩码后的id序列会选择概率最大的候选字符替换原来的poi地址信息,对于保持不变的id序列则直接采
用原来的poi地址信息,最终得到纠错后的poi地址信息。
43.对于本实施例,所述纠错模型基于深度学习算法预先训练生成,其模型训练数据的处理过程与上述用户输入的poi地址信息的处理过程一致,均通过预处理、序列化、基于混合mask机制的掩码操作的过程,最终作为训练输入数据的格式与上述输入数据特征向量一致。对应货运应用场景下的poi地址信息检索召回应用场景,上述纠错模型学习可从多个空间维度分析历史货运地址名称等信息分布和文本语义,挖掘特征之间的关联,可以增强对未知数据的泛化能力和低频数据的正确处理能力。通过组合方式选择需要mask的poi地址信息的字符位置,这样既可以学习实体词语之间的组合关系,也可以合理完成单个错误位置的纠错。添加词语级别的mask,将某个词语直接屏蔽掉,促使模型根据上下文语义去推断当前位置的内容,有效提升纠错模型的实体词语识别和连贯性学习能力,混合mask扩大了纠错面,提升容错率,使得纠错模型可以提升货运场景相关poi召回能力。
44.本发明提供的基于混合mask的poi地址纠错方法,通过对用户输入的poi地址信息进行预处理、序列化、基于混合mask机制的掩码操作,并输入至基于深度学习算法预先训练生成的纠错模型,最终得到纠错后的poi地址信息,本方案所采用的混合mask机制掩码方式扩大了纠错面,提升容错率,有效保证纠错模型的纠错准确率,进而可以提升货运应用场景相关的poi地址信息召回能力,满足用户检索需求,从而进一步提升用户发单情况。
45.在一些实施例中,所述步骤s130中的以1-p1概率将所述id序列中的至少两个字符替换为mask,其中所述至少两个字符为实体词语的概率为p2,包括:对于要将至少两个字符替换为mask的id序列,以1-p2概率将其中的任意两个字符替换为mask,或以p2概率将其中的一个实体词语替换为mask。
46.对于本实施例,对于需要将至少两个字符进行掩码的检索查询内容,这其中包含分散的单字符错误、连续实体词语错误。对应不同的应用场景,预先统计分析有其中分散的单字错误、连续实体词语错误的占比,基于上述占比设定对实体词语或任意两个单字符进行掩码的概率。具体地,基于rand()函数生成的第三随机数,判断第三随机数是否小于所述概率1-p2对应的数值,若是,则将其中的任意两个单字符替换为mask,若否,则将其中的一个实体词语替换为mask,可知对于需要将至少两个字符进行掩码的id序列中,将其中一个实体词语替换为mask的概率为p2。
47.例如,对应货运应用场景下的poi地址信息检索召回应用场景,经预先统计分析得知,对于需要将至少两个字符进行掩码的检索查询内容,实体词语错误占比约为10%,则对于需要将至少两个字符替换为mask的id序列,其中将一个实体词语替换为mask的概率为10%,其中将任意两个单字符替换为mask的概率为90%。相应地,基于rand()函数生成的第三随机数,判断第三随机数是否小于所述概率1-p2对应的数值,即0.9,若是,则其中的任意两个单字符替换为mask,若否,则将其中一个实体词语替换为mask,可知p2对应的数值为0.1。将其中一个实体词语替换为mask的概率p1也可以根据实际统计分析结果调整为0.15、0.2等值,本发明实施例对p2的具体取值不作限定。
48.在一些实施例中,进一步的,所述以p2概率将其中的一个实体词语替换为mask,包括:对于要将其中的一个实体词语替换为mask的id序列,先确认该id序列中要被替换为mask的一个字符,判断该字符与其前后两位字符中是否存在与预设poi地址词表匹配的实体词语,若是,将包括该字符的实体词语替换为mask,若否,将该字符与其前一位字符或该
字符与其后一位字符所构成的词语作为实体词语替换为mask。
49.对于本实施例,假设要将其中的一个实体词语替换为mask的id序列为{w1,w2,...wn},先确认该id序列中要被替换为mask的一个字符wi,然后查看该字符wi与其前后两位字符中,即[wi-2,wi+2]范围内是否有和wi构成连续词语实体并且在poi地址词表中,如果有包括该字符wi的实体词语替换为mask,如果没有,则将该字符与其前一位字符或该字符与其后一位字符所构成的词语,即选择[wi-1,wi]或者[wi,wi+1]作为实体词语替换为mask。这样既可以覆盖大部分用户输入的poi地址信息中的潜在错误,不会由于过多mask而使纠错模型无法正确理解用户意图,也可以涉及到用户输入的poi地址信息中存在多个实体词语输入错误这种较少的情况。融合这两种策略的基于混合mask机制掩码可以有效提高模型的泛化性和容错率。
[0050]
在一些实施例中,所述预设poi地址词表通过以下步骤预先生成:i、获取历史用户检索poi地址信息时的历史使用数据。获取所有历史用户或抽样历史用户检索poi地址信息时的历史使用数据,具体为从用户点击session(会话)日志中抽取用户历史点击数据,能够获得海量的数据用于poi地址词表生成及纠错模型训练。
[0051]
ii、从所述历史使用数据中提取poi拼接字段。在获取历史使用数据之后,对所述历史使用数据中name(实体名称)、address(地址)和city(城市)字段进行预处理,所述预处理具体为包含空值处理、特殊符号过滤、繁体简体转换等数据清洗操作。然后将经过预处理后的字段进行拼接,提取到poi拼接字段。该方法可以丰富检索查询内容中包含的poi信息,使得模型学习到更精准的poi地址信息并提高纠错的准确率。
[0052]
iii、对所述poi拼接字段进行分词和词频统计,得到多个实体词语及对应的词频。采用jieba将上一步骤中获取的海量poi拼接字段进行分词,并统计词频。
[0053]
iv、根据所述词频大小排在前预设占比的实体词语,生成预设poi地址词表。例如,筛选出词频位于整体频率分布前70%频率的实体词语,同时限定实体词语中不能包含停用词和长度不得小于1,实体词语长度不得长于5,将以上实体词语作为当前应用场景的poi地址词表。所述预设占比还可以是60%、80%、90%等比例,本发明实施例所述预设占比的具体取值不作限定。
[0054]
在一些实施例中,所述步骤s140根据保持不变的id序列或掩码后的id序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息,包括:获取城市信息编码;将所述城市信息编码与保持不变的id序列或掩码后的id序列进行拼接,得到拼接后的序列;根据拼接后的序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息。
[0055]
对于本实施例,在poi地址信息经过预处理、序列化、基于混合mask机制的掩码操作的过程,得到保持不变或掩码后的id序列之后,进一步将城市信息编码与id序列进行拼接。其中,城市信息编码方式采用word2vec训练上述历史使用数据中出现的城市字段信息,得到城市信息的embedding(嵌入)矩阵,通过id映射得到对应嵌入式表示。在一个可能实现的方式中,将所述城市信息编码拼接于保持不变的id序列或掩码后的id序列前面,得到拼接后的序列。通过将城市信息编码入embedding,能够缩小纠错范围,减少范围外歧义地址信息的干扰,进而提升纠错的准确率。
[0056]
在一些实施例中,进一步的,所述根据拼接后的序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息,包括:在拼接后的序列中,将掩码后的id序列中被替换为
mask的字符替换为对应的预设字集,通过映射转换得到最终拼接序列;将所述最终拼接序列输入预先训练生成的纠错模型,得到纠错后的poi地址信息。
[0057]
对于本实施例,将掩码后的id序列中被替换为mask的字符替换为对应的预设字集,所述预设字集可以是由被掩码的字符及其形近字或同音字等共同组成的字集,并进一步基于预先设置的向量id映射表将所替换的预设字集也通过映射转换为向量化表示,得到包括城市信息编码和最终id序列的最终拼接序列。
[0058]
如图2所示,是一种基于混合mask的poi地址纠错方法流程图,其体现了结合以上各个实施例所述的poi地址纠错过程,具体请参见上述方法实施例中的说明,在此不再赘述。
[0059]
在一些实施例中,所述纠错模型为基于多头注意力机制的bp神经网络模型。
[0060]
对于本实施例,将所述最终拼接序列输入预先训练生成的纠错模型,得到纠错后的poi地址信息,具体为,将最终拼接序列输入到多头注意力网络,学习向量之间的交互关系得到hidden(隐藏层),继而输入至bp神经网络进行映射学习,最后进入激活层,输出被掩码的字符对应预设字集的各个候选词的概率,选择概率最大的进行替换,从而得到纠错后的poi地址信息。
[0061]
以下,示出一个实例对所述poi地址纠错方法做进一步阐明:(1)用户输入的 poi地址信息:上海市黄埔区制造局路584号;(2)经预处理后得到:上海市黄埔区制造局路584号;(3)经序列化后得到:[67, 68, 69, 101, 88, 91, 23, 25, 541, 345, 366, 2, 10, 169];(4)先确认字符级mask:随机只遮掩一个位置[67, 68, 69, [mask], 88, 91, 23, 25, 541, 345, 366, 2, 10, 169];(5)进行词语级mask:前后扫描得“黄埔区”在poi地址词表中,则mask该实体词语,得到[67, 68, 69, [mask], [mask], [mask], 23, 25, 541, 345, 366, 2, 10, 169];(6)输入至纠错模型中预测打分,预设字集[黄, 青, 静], [浦, 陂, 埔, 埔], [区, 去, 安],最后选择最大概率的组合结果为黄浦区,得到纠错后的poi地址信息:上海市黄浦区制造局路584号。
[0062]
对于本实施例,所述纠错模型基于深度学习算法预先训练生成,具体的,为基于bp(back propagation)神经网络预先训练生成,bp神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络。所述纠错模型还采用了多头注意力机制,能够关注输入的不同部分。
[0063]
对于本实施例,所述纠错模型的训练数据的处理过程与上述用户输入的poi地址信息的处理过程一致,具体实现过程此处不再赘述。首先获取历史用户检索poi地址信息时的历史使用数据,将所述历史使用数据通过预处理、序列化、基于混合mask机制的掩码操作的过程,得到保持不变或掩码后的id序列,可用作纠错模型的训练输入数据,此外,还可进一步将城市信息编码与保持不变或掩码后的id序列进行拼接。其中,城市信息编码方式采用word2vec训练上述历史使用数据中出现的城市字段信息,得到城市信息的embedding(嵌入)矩阵,通过id映射得到对应嵌入式表示。在一个可能实现的方式中,将所述城市信息编码拼接于保持不变的id序列或掩码后的id序列前面,得到拼接后的序列,将最终拼接序列
作为纠错模型的训练输入数据。通过将城市信息编码入embedding,能够缩小纠错范围,减少范围外歧义地址信息的干扰,进而提升纠错的准确率。最终作为训练输入数据的格式与上述输入数据特征向量一致。
[0064]
此外,本发明实施例提供了一种基于混合mask的poi地址纠错装置,如图3所示,所述装置包括:地址信息获取模块31,用于获取用户输入的poi地址信息;序列化模块32,用于将所述poi地址信息通过映射转换为id序列;混合mask模块33,用于判断是否对所述id序列进行掩码;若是,以p1概率将所述id序列中的一个字符替换为mask,或以1-p1概率将所述id序列中的至少两个字符替换为mask,其中所述至少两个字符为一个实体词语的概率为p2;若否,保持所述id序列不变;模型纠错模块34,用于根据保持不变的id序列或掩码后的id序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息。
[0065]
在一些实施例中,所述混合mask模块33用于以1-p1概率将所述id序列中的至少两个字符替换为mask,其中所述至少两个字符为实体词语的概率为p2时,具体用于:对于要将至少两个字符替换为mask的id序列,以1-p2概率将其中的任意两个字符替换为mask,或以p2概率将其中的一个实体词语替换为mask。
[0066]
在一些实施例中,所述以p2概率将其中的一个实体词语替换为mask,包括:对于要将其中的一个实体词语替换为mask的id序列,先确认该id序列中要被替换为mask的一个字符,判断该字符与其前后两位字符中是否存在与预设poi地址词表匹配的实体词语,若是,将包括该字符的实体词语替换为mask,若否,将该字符与其前一位字符或该字符与其后一位字符所构成的词语作为实体词语替换为mask。
[0067]
在一些实施例中,所述预设poi地址词表通过以下步骤预先生成:获取历史用户检索poi地址信息时的历史使用数据;从所述历史使用数据中提取poi拼接字段;对所述poi拼接字段进行分词和词频统计,得到多个实体词语及对应的词频;根据所述词频大小排在前预设占比的实体词语,生成预设poi地址词表。
[0068]
在一些实施例中,所述模型纠错模块34,具体用于:获取城市信息编码;将所述城市信息编码与保持不变的id序列或掩码后的id序列进行拼接,得到拼接后的序列;根据拼接后的序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息。
[0069]
在一些实施例中,所述根据拼接后的序列,并基于预先训练生成的纠错模型,得到纠错后的poi地址信息,包括:在拼接后的序列中,将掩码后的id序列中被替换为mask的字符替换为对应的预设字集,通过映射转换得到最终拼接序列;将所述最终拼接序列输入预先训练生成的纠错模型,得到纠错后的poi地址信息。
[0070]
在一些实施例中,所述纠错模型为基于多头注意力机制的bp神经网络模型。
[0071]
本发明方法实施例的内容均适用于本装置实施例,本装置实施例所具体实现的功
能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同,具体请参见方法实施例中的说明,在此不再赘述。
[0072]
此外,本发明实施例提供了一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现以上任一实施例所述的基于混合mask的poi地址纠错方法。其中,所述计算机可读存储介质包括但不限于任何类型的盘(包括软盘、硬盘、光盘、cd-rom、和磁光盘)、rom(read-only memory,只读存储器)、ram(random access memory,随即存储器)、eprom(erasable programmable read-only memory,可擦写可编程只读存储器)、eeprom(electrically erasable programmable read-only memory,电可擦可编程只读存储器)、闪存、磁性卡片或光线卡片。也就是,存储设备包括由设备(例如,计算机、手机)以能够读的形式存储或传输信息的任何介质,可以是只读存储器,磁盘或光盘等。
[0073]
本发明方法实施例的内容均适用于本存储介质实施例,本存储介质实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同,具体请参见方法实施例中的说明,在此不再赘述。
[0074]
此外,本发明实施例还提供了一种计算机设备,本实施例所述的计算机设备可以是服务器、个人计算机以及网络设备等设备。所述计算机设备包括:一个或多个处理器,存储器,一个或多个计算机程序,其中所述一个或多个计算机程序被存储在存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个计算机程序配置用于执行以上任一实施例所述的基于混合mask的poi地址纠错方法。
[0075]
本发明方法实施例的内容均适用于本计算机设备实施例,本计算机设备实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同,具体请参见方法实施例中的说明,在此不再赘述。
[0076]
此外,在本发明各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
[0077]
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1