基于Hadoop的海量交通数据处理方法与流程
本发明涉及一种海量交通数据处理方法。
背景技术:
在当今的大数据时代,由于GPS采集装置的多种和获取方法的多样化使得交通数据日渐庞大,传统方法已经满足不了数据的分析,为了获取数据中蕴含的价值,各种数据分析与挖掘方法应运而生。
从海量数据中很难直接的提取有价值的信息,能够准确并及时的对交通现状进行分析并为出行者提供优质的交通诱导服务,一直是城市智能交通规划所追求的目标,将交通数据的处理集中在并行分布式计算平台上,利用Hadoop的MapReduce分布式计算框架对交通数据进行流式处理,用分布式平台保证了其时效性和高容错性。Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。Map-Reduce是Hadoop的核心算法,也称为映射-规约算法,算法思想简单,举个例子来说,就是一个任务来了,一台计算机做不了,MapReduce算法可以将它映射成很多子任务,分给不同的计算机去完成,每台机器做完了,最后规约到一个结果交给用户,这就是MapReduce算法的核心思想。
技术实现要素:
本发明要克服现有海量交通数据处理方法的数据冗杂及处理缓慢的缺点,提出一种利用Hadoop平台处理数据的方式,设计出一种基于Hadoop的海量交通数据处理分析方法,更好地解决交通数据冗杂处理缓慢,快速实现数据处理及计算,以达到有效的道路匹配及相关道路流量及各种复杂运算,例如路段流量、车辆速度以及路口分流的具体数据计算。
本发明设计了一种MapReduce交通数据处理方法,以方便数据的清理及快速的路网匹配,与传统的多线程数据处理方式不同,MapReduce是将任务分配给多台计算机并行运算,这与一台电脑多线程的工作效率完全不同,并且在对于路网的复杂状况下更是具有得天独厚的优势,可以将任务在碎片化执行的情况下几乎不会影响到路网的具体情况。为了能具体快速的对交通数据进行处理以及计算,本发明所涉及的一种基于Hadoop的海量交通数据处理方法,包括以下几个步骤:
1)分布式道路匹配:将数据传输到Hadoop平台的HDFS数据存储系统,方便进行分布式处理数据,道路匹配的目的是将有效的GPS点匹配到所在道路,进行准确的流量统计。其中步骤1)具体包括:
(1.1)多节点数据处理及计算:将包含出租车信息的数据文件传输到HDFS的数据存储系统,命令多台电脑作为独立的节点同时对数据进行处理,包括出租车数据的清理、矢量地图的修正等,主要目的是全方位剔除逻辑错误的GPS点数据,具体包括时间错乱以及速度不符合常理的数据;在道路修正上主要解决道路单双向以及道路行驶方向的纠正。由于多台主机同时作为节点处理数据大大提高工作效率,进行快速的流量统计及速度计算;
(1.2)搭建MapReduce道路匹配的框架:通过Hadoop平台的MapReduce框架读取数据与实际路网的杭州市道路路网信息进行路网匹配,进一步提高该系统的高效性。使用dom4j文件处理方式处理数据文件中的路网信息,将文件中路网的边界、节点以及路段信息通过MapReduce框架进行读取和解析,进行多服务器同时处理数据的路网匹配工作;
(1.3)车辆轨迹解析:对已经读取的车辆轨迹进行解析。本计算方法首先将轨迹解析成有联系的一系列的GPS点数据,解析后的数据符合MapReduce框架的处理格式。将文件对应的数据行所代表的GPS点整理为包含经纬度信息、时间信息、和车辆ID的文本文件,为了便于MapReduce任务的进行,每一个数据行的偏移量作为Map任务的Key值便于数据索引,行内的内容作为当前Key值对应的Value,利用MapReduce进行快速的Key-Value读取与处理,完成路网中每一条轨迹的解析;
(1.4)创建扩展路网:利用每一个GPS点的位置对路网进行扩建,以候选GPS为矩形中心,建立边长为M的的最小矩形,M为可修改的矩形边长,所建立的最小矩形称为最小限定矩形MBR(minimum bounding rectangle),使用prtree算法中的find方法查找当前点的MBR与所有路段的MBR(以一条道路的连线作为对角线所形成的矩形)进行比较,凡是有共同面积的每一个MBR作为候选匹配路段。计算GPS候选点和每一条候选匹配路段的距离,得到的最短距离所对应路段的ID信息取出来,则该路段作为候选GPS点的最佳匹配路段。由此利用Hadoop平台完成所有GPS点与路网信息的快速匹配,作为后续道路流量计算和分流数据来源;
2)道路流量及车辆速度的计算:通过匹配成功的路网索引路段ID得到对应车辆的行驶轨迹,将路段流量看做车辆当前时间经过当前路段的次数,根据路段当前所匹配到的轨迹数量确定当前车流量,一条道路所对应的路段流量总和作为该道路流量。另外利用路段序列中当前路段与下一路段在空间中的相对位置,计算两个路段向量的夹角和外积的模,若夹角小于30度则视为直行,若大于150度则为掉头,根据外积的模可以判断转向为左转还是右转,模为正数为左转,负数为右转;对于道路车辆行驶速度v,首先计算三种平均速度,三种平均速度分别为上个路段尾点到当前点的平均速度v1、当前点到下个路段起始点的平均速度v2和当前道路的瞬时速度v3:
v=ω1v1+ω2v2+ω3v3
其中ωi(i=1,2,3)为每种速度的加权值,且∑ωi(i=1,2,3)=1;
然后把出租车轨迹的每一个GPS点匹配到的路段信息(包括速度,流量,下一条路的ID等信息)导出,作为下一个分流工程的输入文件;
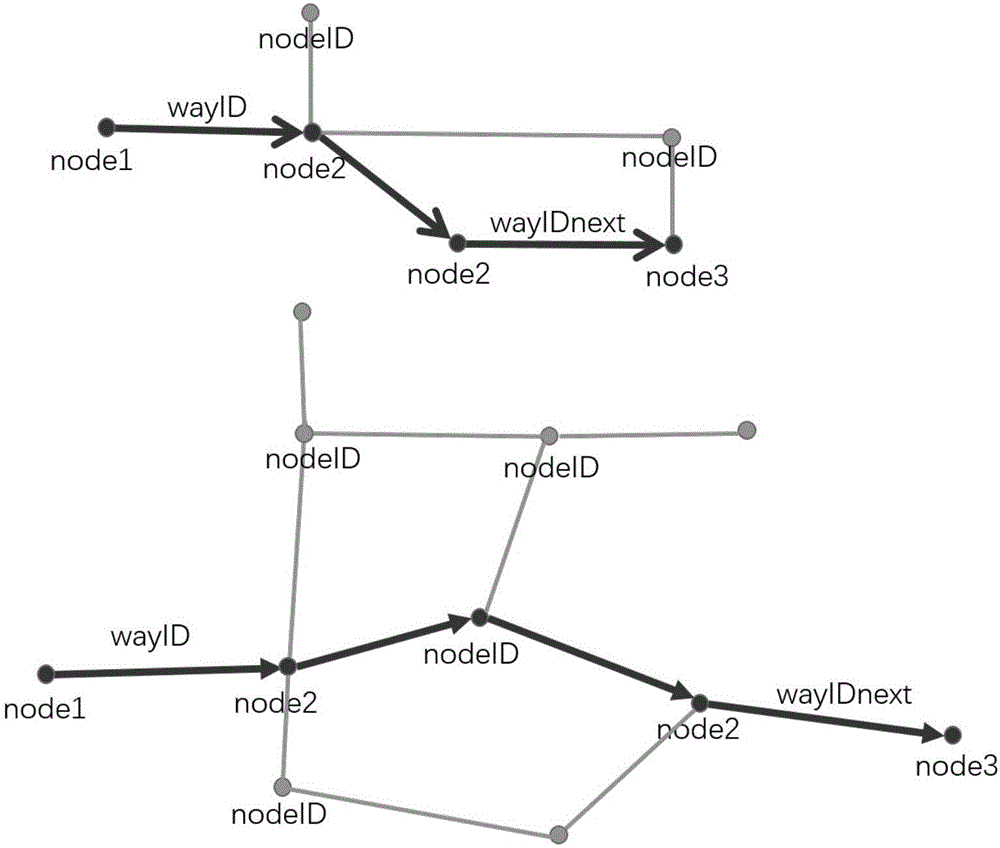
3)道路分流统计:首先判断道路方向,利用每条路的两个节点nodeID判断道路的流向,假设当前路段Way1的两个节点nodeID1和nodeID2,下一条路段Way2的两个节点nodeID3和nodeID4。分流统计则包含以下步骤:
(3.1)若nodeID2和nodeID3相同,则规定这两条路的方向为nodeID1指向nodeID2,nodeID2指向nodeID4;
(3.2)然后通过两条路的空间位置来计算分流的方向,这里定义两条路的夹角大150度的情况为掉头,把夹角介于150度到30度之间以及路段矢量差积来确定左转或者右转,夹角小于30度视为直行;
(3.3)若nodeID1-nodeID4均无任何一个相同ID,则定义两个连续GPS点匹配到的路段之间还包含其他的路段,首先找到当前路Way1所有相邻的路段,然后查找到所有相邻路段对应的相邻路段集合,判断集合中所有路段中是否存在和Way2相同的路段ID,若存在则表示Way1和Way2之间存在一条连接路段,若不存在则继续按照上述方法多次迭代,即可找到当前路段和下一条路段之间的所有连接路段;
(3.4)对每两条相邻路段重复步骤(3.2)判断分流的具体情况。
本发明的技术构思是:搭建MapReduce框架处理交通数据,实现了多台计算机并行执行任务,大大提高了工作效率,且对于克服交通数据的冗杂性有很大的帮助;对于路网匹配中的MBR算法则很大程度上改善了GPS点与路段的匹配速度,并且提高了准确性;道路分流的计算将可能存在的情况均考虑在内,保证了分流计算的准确度与有效性。
本发明可具体应用到手机导航系统,可以帮助用户来显示当前区域的实时路况,包括当前某条路段的流量以及速度情况和路口的分流信息,用户可以通过这些信息来分析道路拥堵情况,并选择合适的路线来避免经过拥堵的路段,提高导航系统的准确性和有效性。
本发明的优点是:部署简易,维护方便,数据处理迅速。
附图说明
图1为实施本发明方法的道路实时处理系统框图。
图2为本发明的不相邻的两条路段的空间方向计算示意图。
图3为本发明的路网匹配过程示意图。
图4为本发明的道路速度计算示意图
具体实施方式
本发明所涉及的基于Hadoop的海量交通数据处理方法,包括以下几个步骤:
1)分布式道路匹配:将数据传输到Hadoop平台的HDFS数据存储系统,方便进行分布式处理数据,道路匹配的目的是将有效的GPS点匹配到所在道路,进行准确的流量统计。其中步骤1)具体包括:
(1.1)多节点数据处理及计算:将包含出租车信息的数据文件传输到HDFS的数据存储系统,命令多台电脑作为独立的节点同时对数据进行处理,包括出租车数据的清理、矢量地图的修正等,主要目的是全方位剔除逻辑错误的GPS点数据,具体包括时间错乱以及速度不符合常理的数据;在道路修正上主要解决道路单双向以及道路行驶方向的纠正。由于多台主机同时作为节点处理数据大大提高工作效率,进行快速的流量统计及速度计算;
(1.2)搭建MapReduce道路匹配的框架:通过Hadoop平台的MapReduce框架读取数据与实际路网的杭州市道路路网信息进行路网匹配,进一步提高该系统的高效性。使用dom4j文件处理方式处理数据文件中的路网信息,将文件中路网的边界、节点以及路段信息通过MapReduce框架进行读取和解析,进行多服务器同时处理数据的路网匹配工作;
(1.3)车辆轨迹解析:对已经读取的车辆轨迹进行解析。本计算方法首先将轨迹解析成有联系的一系列的GPS点数据,解析后的数据符合MapReduce框架的处理格式。将文件对应的数据行所代表的GPS点整理为包含经纬度信息、时间信息、和车辆ID的文本文件,为了便于MapReduce任务的进行,每一个数据行的偏移量作为Map任务的Key值便于数据索引,行内的内容作为当前Key值对应的Value,利用MapReduce进行快速的Key-Value读取与处理,完成路网中每一条轨迹的解析;
(1.4)创建扩展路网:利用每一个GPS点的位置对路网进行扩建,以候选GPS为矩形中心,建立边长为M的的最小矩形,M为可修改的矩形边长,所建立的最小矩形称为最小限定矩形MBR(minimum bounding rectangle),使用prtree算法中的find方法查找当前点的MBR与所有路段的MBR(以一条道路的连线作为对角线所形成的矩形)进行比较,凡是有共同面积的每一个MBR作为候选匹配路段。计算GPS候选点和每一条候选匹配路段的距离,得到的最短距离所对应路段的ID信息取出来,则该路段作为候选GPS点的最佳匹配路段。由此利用Hadoop平台完成所有GPS点与路网信息的快速匹配,作为后续道路流量计算和分流数据来源;
2)道路流量及车辆速度的计算:通过匹配成功的路网索引路段ID得到对应车辆的行驶轨迹,将路段流量看做车辆当前时间经过当前路段的次数,根据路段当前所匹配到的轨迹数量确定当前车流量,一条道路所对应的路段流量总和作为该道路流量。另外利用路段序列中当前路段与下一路段在空间中的相对位置,计算两个路段向量的夹角和外积的模,若夹角小于30度则视为直行,若大于150度则为掉头,根据外积的模可以判断转向为左转还是右转,模为正数为左转,负数为右转;对于道路车辆行驶速度v,首先计算三种平均速度,三种平均速度分别为上个路段尾点到当前点的平均速度v1、当前点到下个路段起始点的平均速度v2和当前道路的瞬时速度v3:
v=ω1v1+ω2v2+ω3v3
其中ωi(i=1,2,3)为每种速度的加权值,且∑ωi(i=1,2,3)=1;
然后把出租车轨迹的每一个GPS点匹配到的路段信息(包括速度,流量,下一条路的ID等信息)导出,作为下一个分流工程的输入文件;
3)道路分流统计:首先判断道路方向,利用每条路的两个节点nodeID判断道路的流向,假设当前路段Way1的两个节点nodeID1和nodeID2,下一条路段Way2的两个节点nodeID3和nodeID4。分流统计则包含以下步骤:
(3.1)若nodeID2和nodeID3相同,则规定这两条路的方向为nodeID1指向nodeID2,nodeID2指向nodeID4;
(3.2)然后通过两条路的空间位置来计算分流的方向,这里定义两条路的夹角大150度的情况为掉头,把夹角介于150度到30度之间以及路段矢量差积来确定左转或者右转,夹角小于30度视为直行;
(3.3)若nodeID1-nodeID4均无任何一个相同ID,则定义两个连续GPS点匹配到的路段之间还包含其他的路段,首先找到当前路Way1所有相邻的路段,然后查找到所有相邻路段对应的相邻路段集合,判断集合中所有路段中是否存在和Way2相同的路段ID,若存在则表示Way1和Way2之间存在一条连接路段,若不存在则继续按照上述方法多次迭代,即可找到当前路段和下一条路段之间的所有连接路段;
(3.4)对每两条相邻路段重复步骤(3.2)判断分流的具体情况。
以上阐述的是本发明给出的一个实施案例展示了交通数据处理的形式列举,显然本发明不只是限于上述实施案例,在不偏离本发明基本精神及不超出本发明实质内容所涉及范围的前提下对其可作种种变形加以实施。所提出的数据处理方法对于解决数据的冗杂及处理缓慢是非常有效的。
- 还没有人留言评论。精彩留言会获得点赞!