基于数据重用的非负自适应滤波方法与流程
本发明涉及一种非负自适应滤波方法,具体地涉及一种基于数据重用的非负自适应滤波方法,属于数字滤波器设计领域。
背景技术:
自适应滤波方法在信道均衡、自适应噪声消除、自适应回声抵消、主动噪声控制等领域获得了广泛应用。自适应滤波方法在大部分应用中都可以归结为系统辨识问题,即采用自适应滤波的方法来逼近未知系统的权值向量。在一些应用中,由于受到系统内在的物理特性的限制,需要对待估计的系统的权值向量施加非负性约束。这种非负性约束条件下的系统辨识问题是非负性约束条件下的最优化问题的一种具体表现形式。非负性约束条件下的最优化问题在理论和工程实践中经常涉及,是目前的研究热点之一,例如非负最小二乘、非负矩阵分解等理论及其在天体物理图像去模糊、计量化学光谱发散反卷积、高光谱图像分析等问题中的应用。然而,传统的非负最小二乘法需要进行批处理,因此不适合用来在线处理非负性约束条件下的系统辨识问题。
为了克服非负最小二乘方法存在的问题,Jie Chen等人提出了非负最小均方自适应滤波(NNLMS)方法(Nonnegative least-mean-square algorithm,IEEE Transactions on Signal Processing,2011,59(11):5225-5235)。NNLMS方法流程简单,且易于实现,因而得到了广泛关注,但其缺点是收敛较慢。收敛速度是自适应滤波器的重要性能指标,收敛速度的快慢决定了自适应滤波器逼近未知系统需要花费的时间。在许多实时系统中,需要自适应滤波器尽可能快的逼近未知系统,从而达到更好的滤波效果,因而需要采用收敛更快的非负自适应滤波方法。
技术实现要素:
针对上述存在的技术问题,本发明目的:提供一种基于数据重用的非负自适应滤波方法,具有更快的收敛速度,可以获得更好的性能。
为实现上述方案,本发明采用如下技术方案:
一种基于数据重用的非负自适应滤波方法,其特征在于,所述方法将过去时刻的输入信号向量和期望信号进行重用,并采用定点迭代的方式对自适应滤波器的权值向量进行非负性约束更新。
进一步的,所述方法更新自适应滤波器的权值向量包含以下步骤:
1)由输入信号的最近M个样值{u(n),u(n-1),…,u(n-M+1)}构成输入向量u(n)=[u(n),u(n-1),…,u(n-M+1)]T,其中,M表示自适应滤波器权值向量的长度,上标T表示向量或矩阵的转置运算符,n表示样值所在的时刻;
2)由最近K个时刻的输入向量{u(n),u(n-1),…,u(n-K+1)}构成输入信号矩阵U(n)=[u(n),u(n-1),…,u(n-K+1)],其中,K为数据重用的阶数;
3)由最近K个时刻的期望信号样值{d(n),d(n-1),…,d(n-K+1)}构成期望向量d(n)=[d(n),d(n-1),…,d(n-K+1)]T;
4)采用表达式e(n)=d(n)-UT(n)w(n)计算自适应滤波器的误差向量e(n),其中w(n)表示自适应滤波器在n时刻的权值向量;
5)采用表达式g(n)=U(n)[δI+UT(n)U(n)]-1e(n)计算数据重用向量g(n),其中,符号[·]-1表示对矩阵[·]进行求逆,I为单位矩阵,δ为很小的正则化因子,用来防止矩阵求逆时引起数值计算困难;
6)以数据重用向量g(n)的元素为对角元素,构建对角矩阵diag[g(n)],其中diag[…]表示将向量[…]形成对角矩阵的运算符;
7)采用数据重用矩阵和定点迭代方式,建立自适应滤波器的权值向量更新公式,即在n+1时刻的权值向量w(n+1)通过表达式w(n+1)=w(n)+μ×diag[g(n)]w(n)更新得到,其中,μ为自适应滤波器的步长参数。
相对于现有技术中的方案,本发明的优点是:
相对于现有技术中的方案(即NNLMS方法),本发明公开的基于数据重用的非负自适应滤波方法(简记为NAP方法)具有更快的收敛速度,从而使得自适应滤波器的权值向量能够在更短的时间内逼近最优的非负系统权值向量,从而获得更好的性能。该非负自适应滤波方法可用于仪器、仪表、通信等需要对系统进行非负性约束的领域。
附图说明
下面结合附图及实施例对本发明作进一步描述:
图1为非负自适应滤波器结构原理图;
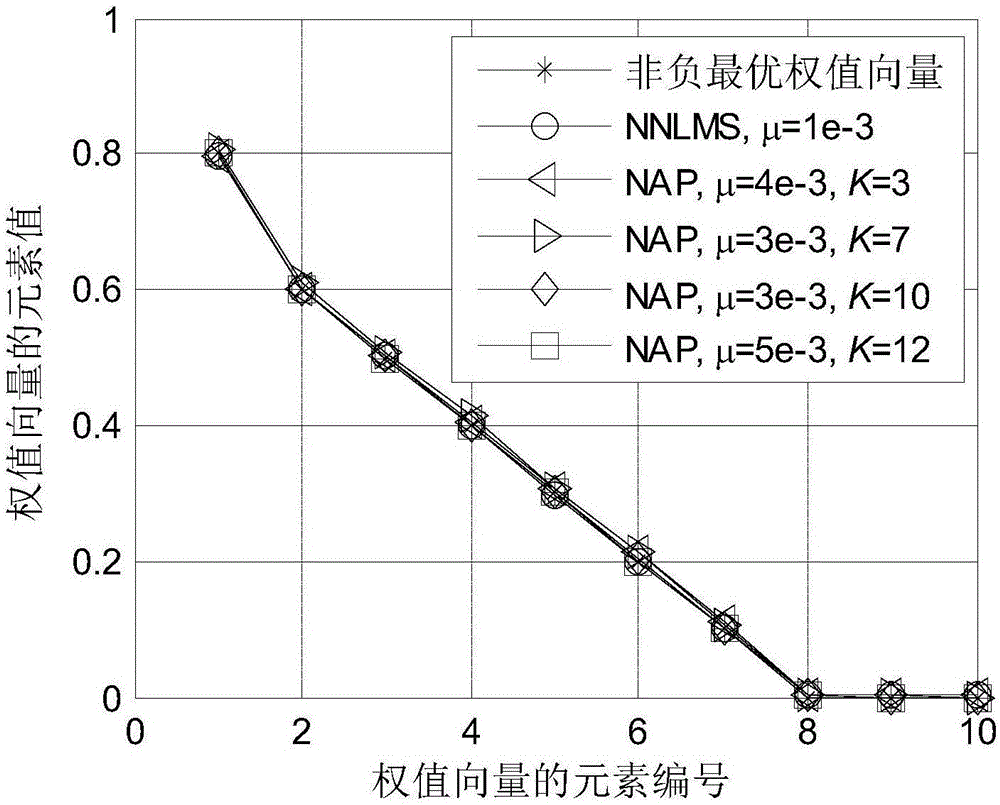
图2为采用NNLMS方法和NAP方法对自适应滤波器的权值向量进行更新后的收敛值;
图3为采用NNLMS方法和NAP方法获得的归一化均方偏差曲线。
具体实施方式
实施例
本实施例采用计算机实验的方法来验证非负自适应滤波方法的性能。实验中使用本发明公开的NAP方法对未知稀疏系统进行辨识,并将其性能与NNLMS方法的性能进行对比。
非负自适应滤波的原理图如附图1所示。
实验中,未知系统的权值向量取为w*=[0.8,0.6,0.5,0.4,0.3,0.2,0.1,-0.1,-0.3,-0.6]T,其长度M=10。自适应滤波器的初始权值向量取自均匀分布的随机过程。输入信号u(n)为零均值的高斯白噪声,其方差为1。测量噪声也为零均值的高斯白噪声,其方差为10-2。在上述条件下,未知系统的非负最优权值向量为wo=[0.8,0.6,0.5,0.4,0.3,0.2,0.1,0,0,0]T。NAP方法的正则化因子取δ=0.01,数据重用阶数分别取K=3、K=7、K=10和K=12。采用归一化失调M(n)来表示两种方法的性能,其定义为M(n)=20log10||wo-w(n)||/||wo||。所有曲线为100次独立实验取平均的结果。
在上述条件下,采用基于数据重用的非负自适应滤波方法对未知系统进行非负自适应滤波,具体步骤为:
1)由输入信号的最近M个样值{u(n),u(n-1),…,u(n-M+1)}构成输入向量;
2)由最近K个时刻的输入向量{u(n),u(n-1),…,u(n-K+1)}构成输入信号矩阵U(n)=[u(n),u(n-1),…,u(n-K+1)];
3)由最近K个时刻的期望信号样值{d(n),d(n-1),…,d(n-K+1)}构成期望向量d(n)=[d(n),d(n-1),…,d(n-K+1)]T;
4)采用表达式e(n)=d(n)-UT(n)w(n)计算自适应滤波器的误差向量e(n);
5)采用表达式g(n)=U(n)[δI+UT(n)U(n)]-1e(n)计算数据重用向量g(n);
6)以数据重用向量g(n)的元素为对角元素,形成对角矩阵diag[g(n)];
7)通过表达式w(n+1)=w(n)+μ×diag[g(n)]w(n)计算w(n+1);
8)通过M(n)=20log10||wo-w(n)||/||wo||计算归一化失调。
实验结果如附图2和附图3所示。
附图2给出了分别采用NNLMS方法和NAP方法后,自适应滤波器达到稳态时的权值向量各个元素的平均值。由附图2可见,NNLMS方法和NAP方法都能收敛到未知系统的非负最优权值向量,因而NAP方法是有效的。附图3给出了分别采用NNLMS方法和NAP方法得到的归一化失调曲线。由附图3可见,当K=3时,NAP方法与NNLMS方法收敛速度相近,而当K=7、K=10或K=12时,NAP方法比NNLMS方法收敛更快。此外,当K=3或K=7时,NAP方法和NNLMS方法的稳态失调相近,而当K=10或K=12时,NAP方法比NNLMS方法的稳态失调更低。
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明主要技术方案的精神实质所做的修饰,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!