一种N抽头的FIR滤波器的制作方法
本发明涉及数据处理
技术领域:
,尤其涉及一种N抽头的FIR滤波器。
背景技术:
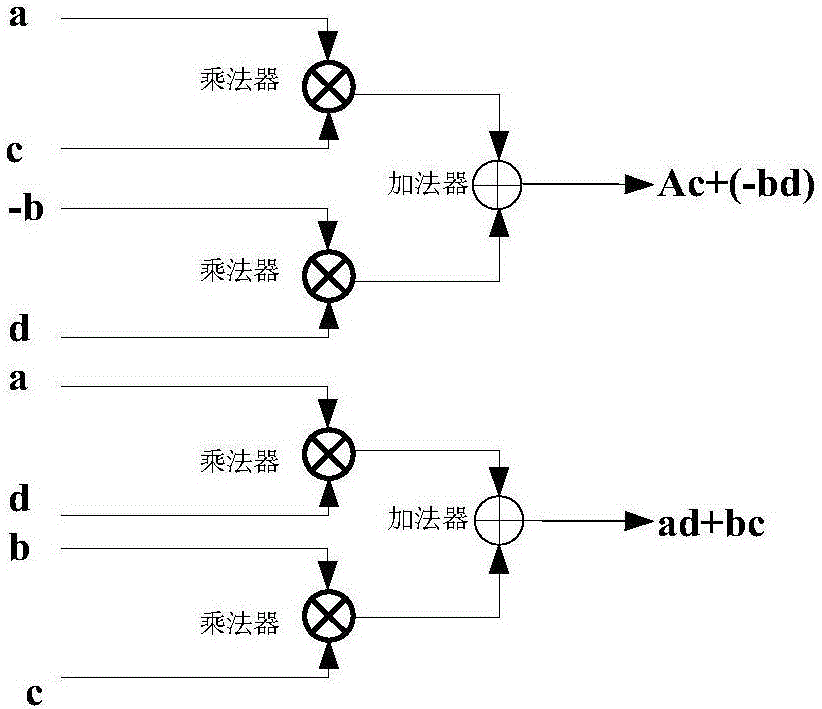
:复数有限脉冲响应(FiniteImpulseResponse,FIR)滤波器在图像处理、信道均衡、频域补偿等多领域得到广泛运用。对于一个N抽头的FIR滤波器,其可以表示为:其中,式(1)中的h[0],h[1]…h[N-1]为FIR滤波器的N个抽头系数,x[n]为输入数据,y[n]为输出数据。图1为现有的N抽头的复数FIR滤波器的结构示意图,在该结构中,一个复数乘法器中包括4个乘法器和2个加法器(图1中未画出),所以复数FIR滤波器总共需要4N个乘法器和4N-2个加法器(包括复数乘法器中的加法器以及图1中画出的加法器),由此可见,复数FIR滤波器所需的乘法器和加法器的数量较大,这导致复数FIR滤波器的硬件开销较大。考虑到复数FIR滤波器的主要开销集中在复数乘法器上,为了降低复数FIR滤波器的硬件开销,现有技术从减少复数乘法器中乘法器的数量的角度出发对复数乘法器进行优化,然而,优化后的复数乘法器虽然减少了乘法器的数量但增加了加法器的数量,复数FIR滤波器的总体硬件开销仍较大。综上可以看出,无论是图1示出的复数FIR滤波器还是优化后的复数FIR滤波器,都存在硬件开销较大的问题。技术实现要素:本申请提供了一种N抽头的FIR滤波器,用于解决现有的复数FIR滤波器硬件开销较大的问题。为了实现上述目的,本申请提出以下技术方案:本申请的第一方面提供了一种N抽头的FIR滤波器,包括预处理单元和N组运算单元,N为大于0的整数。所述预处理单元用于将直角坐标系下的输入数据转换为极坐标系下的输入数据X[n]。所述N组运算单元与X[n]、X[n-1]…X[n-N+1]一一对应,其中,所述N组运算单元中的第i组运算单元包括复数乘单元和后处理单元,所述复数乘单元用于将所述极坐标系下的X[n-i]与所述极坐标系下的抽头系数h[i]进行所述极坐标下的复数乘运算;所述后处理单元用于将所述极坐标系下的X[n-i]与所述极坐标系下的h[i]的复数乘运算结果从所述极坐标系转换到所述直角坐标系,i为整数,且0≤i≤N-1。将输入数据转换到极坐标系后,在极坐标系下与抽头系数进行复数乘运算,与直角坐标系下的复数乘运算相比,需要使用的乘法器和加法器的数目明显减少,在复数乘运算后,再将运算结果转换到极坐标,能够实现与现有的信号处理系统的兼容。所以,本申请提供的滤波器,在与现有系统兼容的情况下,能够明显减少加法器和乘法器的数目,从而降低硬件开销。在一个实现方式中,所述预处理单元包括:采用CORDIC算法的向量模式的计算器。所述采用CORDIC算法的向量模式的计算器的输入端1用于输入所述直角坐标系下的输入数据的实部。所述采用CORDIC算法的向量模式的计算器的输入端2用于输入所述直角坐标系下的输入数据的虚部。所述采用CORDIC算法的向量模式的计算器的输入端3用于输入0。在一个实现方式中,所述采用CORDIC算法的向量模式的计算器的输出端1用于输出所述直角坐标系下的输入数据在所述极坐标系下的幅度。所述采用CORDIC算法的向量模式的计算器的输出端2用于输出0。所述采用CORDIC算法的向量模式的计算器的输出端3用于输出所述直角坐标系下的输入数据在所述极坐标系下的相位。在一个实现方式中,所述复数乘单元包括:一个乘法器和一个加法器。所述乘法器用于将所述X[n-i]与所述抽头系数h[i]在所述极坐标系下的幅度相乘。所述加法器用于将所述X[n-i]与所述抽头系数h[i]在所述极坐标系下的相位相加。在一个实现方式中,所述后处理单元包括:采用所述CORDIC算法的旋转模式的计算器。所述采用所述CORDIC算法的旋转模式的计算器的输入端1用于输入所述复数乘单元输出的幅度之积。所述采用所述CORDIC算法的旋转模式的计算器的输入端2用于输入0。所述采用所述CORDIC算法的旋转模式的计算器的输入端3用于输入所述第i个复数乘单元输出的相位之和。在一个实现方式中,所述采用所述CORDIC算法的旋转模式的计算器的输出端1用于输出所述极坐标系下的X[n-i]与所述极坐标系下的h[i]的复数乘运算结果的实部。所述采用所述CORDIC算法的旋转模式的计算器的输出端2用于输出0。所述采用所述CORDIC算法的旋转模式的计算器的输出端3用于输出所述极坐标系下的X[n-i]与所述极坐标系下的h[i]的复数乘运算结果的虚部。在一个实现方式中,上述滤波器还包括寄存器,用于存储所述极坐标系下的抽头系数h[0]/K2,h[1]/K2,…,h[N-1]/K2。与现有的抽头系数h[0],h[1],…,h[N-1]相比,抽头系数均除以K2的目的在于,抵消上述预处理单元和上述后处理单元引入的K2。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。图1为现有的复数FIR滤波器的结构示意图;图2为图1示出的复数FIR滤波器中复数乘法器的结构示意图;图3为对图2示出的复数乘法器进行优化后的复数乘法器的结构示意图;图4为本申请实施例提供的极坐标系下的复数乘法器的结构示意图;图5为本发明实施例提供的FIR滤波器的结构示意图;图6为采用CORDIC算法的向量模式的计算器的输入和输出的对应关系示意图;图7为图5中的FIR滤波器中的预处理单元的结构示意图;图8为图5中的FIR滤波器中的复数乘法器的结构示意图;图9为采用CORDIC算法的旋转模式的计算器的输入和输出的对应关系示意图;图10为图5所示的FIR滤波器中的后处理单元的结构示意图;图11为图5所示的FIR滤波器N=4的结构示意图。具体实施方式申请人在研究的过程中发现,相比于直角坐标系,在极坐标系下实现复数乘法器能降低硬件资源开销。下面分别以对输入数据x[n]与抽头系数h[0]进行复数乘为例给出直角坐标系下复数乘法器的资源开销情况以及极坐标系下复数乘法器的资源开销情况。假设输入数据为x[n]=a+j*b,其中,a为输入数据x[n]的实部,b为输入数据x[n]的虚部,抽头系数h[0]=c+j*d,其中,c为抽头系数h[0]的实部,d为抽头系数h[0]的虚部。(1)直角坐标系下复数乘法器的资源开销情况(a)对于图1所示的FIR滤波器中的复数乘法器,以x[n]与h[0]进行复数乘为例,在直角坐标系下将x[n]与h[0]进行复数乘的表达式为:x[n]*h[0]=(a+j*b)(c+j*d)=ac-bd+j*(ad+bc)(2)对应上式(2)的复数乘法器的实现结构如图2所示,可以看出,该复数乘法器需要4个乘法器和2个加法器。(b)对式(2)进行优化以后的表达式为:对应上式(3)的复数乘法器的实现结构如图3所示,可以发现,该复数乘法器需要3个乘法器和5个加法器。(2)极坐标系下复数乘法器的资源开销情况仍以x[n]与h[0]进行复数乘为例,在将输入数据x[n]与抽头系数h[0]进行复数乘之前,首先分别将输入数据x[n]与抽头系数h[0]转换到极坐标系下,具体的,其中,A0为x[n]在极坐标系下的幅度,ω0为x[n]在极坐标系下的相位,相应的,其中,A1为h[0]在极坐标系下的幅度,ω1为h[0]在极坐标系下的相位,则复数乘法器在极坐标系下将x[n]与h[0]进行复数乘的表达式为:对应上式(4)的复数乘法器的实现结构如图4所示,可以发现,该复数乘法器需要1个乘法器和1个加法器。对比图2、图3和图4可以看出,极坐标系下复数乘法器需要的乘法器和加法器的数量明显较少,即极坐标系下复数乘法器的实现结构比较简单,硬件开销小。基于申请人的上述发现,本申请提供了一种硬件开销较小的FIR滤波器,并实现此FIR滤波器与现有的数字处理系统的兼容。下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。图5为本申请实施例公开的一种FIR滤波器的结构,该滤波器为N抽头的滤波器,包括预处理单元501和N组运算单元502(图5中以虚线框表示)。其中:预处理单元501用于将直角坐标系下的输入数据转换为极坐标系下的输入数据X[n]。N组运算单元502与X[n]、X[n-1]…X[n-N+1]一一对应。N组运算单元中的任意一个运算单元均包括一个乘法器和一个加法器。具体的,第i组运算单元包括一个复数乘单元5021以及一个后处理单元5022。复数乘单元5021用于将X(n-i)与h(i)进行极坐标下的复数乘运算。后处理单元5022用于将X(n-i)与h(i)的复数乘运算结果从极坐标系转换到直角坐标系,i为整数,且0≤i≤N-1。例如,以图5中左起第一组运算单元502为例,其中包括一个复数乘单元5021和一个后处理单元5022。复数乘单元5021用于将X(n)(i=0)与h(0)进行极坐标下的复数乘运算。后处理单元5022用于将X(n)与h(0)的复数乘运算结果从极坐标系转换到直角坐标系。i=1、2、……N-1的情况下类似,这里不再赘述。需要说明的是,在图5中,还包括N个延时器和N个加法器。其功能及结构与现有的FIR滤波器中的延时器和加法器相同,例如,延时器用于将X[n]进行逐级延迟,得到X[n-1]…X[n-N+1]。这里不再一一赘述。下面对预处理单元501、复数乘单元5021和后处理单元5022进行详细说明。预处理单元501可基于坐标旋转数字计算(CoordinateRotationDigitalComputer,CORDIC)方法将直角坐标系下的输入数据转换至极坐标系下。具体地,CORDIC算法采用一系列与运算基数相关的角度不断偏摆,从而逼近所需旋转的角度,是一种迭代算法。CORDIC算法根据不同的旋转轨迹分成圆周系统、线性系统、双曲系统,每一系统又分别有向量模式和旋转模式两种。其中,圆周系统中CORDIC方程为:其中,di=±1。对于旋转模式,di=sign(z(i)),n次迭代后可得:对于向量模式,di=-sign(x(i)y(i)),n次迭代后可得:其中,K为补偿系数,为一常数。如图6所示,为采用CORDIC算法的向量模式的计算器(简称计算器1)的输入端和输出端的对应关系,如果令x(输入端1)=输入数据的实部,y(输入端2)=输入数据的虚部,z(输入端3)=0,则经计算器1的运算后的输出项为:0,tan-1(y/x)。基于图6,预处理单元501的结构如图7所示,具体地,预处理单元501的输入为直角坐标系下的输入数据X[n],将直角坐标系下的X[n]的实部x输入计算器1的输入端1,将直角坐标系下的X[n]的虚部y输入计算器1的输入端2,输入端3输入为0,则可得到极坐标系下的X[n]的幅度的K倍,即(计算器1的输出端1输出)和相位tan-1(y/x)(计算器1的输出端3输出)。因为CORDIC可以占用较少的硬件实现,所以,采用CORDIC算法进行坐标系的转换能够进一步降低硬件的开销。依据式(4),任意一个复数乘单元5021包括1个乘法器和1个加法器,如图8所示。以对输入数据x[n]和抽头系数h[0]进行复数乘为例,假设输入数据x[n]经预处理单元501转换后获得输入数据x[n]在极坐标系下的幅度为A1,相位为w1,抽头系数h[0]在极坐标系下的幅度为A0,相位为w0,则图8所示的复数乘法器通过乘法器将幅度A1与幅度A0相乘,通过加法器将相位w0和相位w1相加,最终输出A1A0和w0+w1。与预处理单元501相对应的,后处理单元5022采用CORDIC算法的旋转模式将复数乘单元5021的输出结果从极坐标系转换到直角坐标系。如图9所示,为采用CORDIC算法的旋转模式的计算器(简称计算器2)的输入端和输出端的对应关系。如果令x(输入端1)=输入数据的幅度,y(输入端2)=0,z(输入端3)=输入数据的相位,则输出的数据的实部(由计算器2的输出端1输出)=Kx*cosz,输出数据的虚部(由计算器2的输出端3输出)=Kx*sinz,计算器2的输出端2输出为0,可以不连接其它部分。基于图9,后处理单元5022的结构如图10所示,其中输入为复数乘单元5021的输出,以输入数据x[n]和抽头系数h[0]的相乘结果为例,后处理单元5022的输入为A1A0和w0+w1,将A1A0输入计算器2的输入端1,将w0+w1输入计算器2的输入端3,输入端2的输入为0,则后处理单元输出极坐标系下的x[n]和极坐标系下的抽头系数h[0]在直角坐标系下的相乘结果。需要说明的是,从上式(6)、式(7)以及图6和图9可以发现,在使用计算器1和计算器2进行数据的坐标系转换时,运算结果中均会引入常数因子K2,为了消除该常数因子K2,可以采用以下方式:在图5所示的滤波器中还包括寄存器(图5中未画出),寄存器中预先存储抽头系数h[0]/K2,h[1]/K2,…,h[N-1]/K2的极坐标形式,也就是极坐标系下的抽头系数h[0]/K2,h[1]/K2,…,h[N-1]/K2。即通过抽头系数将引入的K2抵消。图11所示为N=4即4抽头滤波器的具体结构示意图,假设该4抽头滤波器的抽头系数分别为h[0]、h[1]、h[2]、h[3],4抽头滤波器的输入数据为x[n],输出数据为y[n],输入数据x[n]=xi+j*xq,其中,xi和xq分别为x[n]的实部和虚部,输出数据y[n]=yi+j*yq,yi和yq分别为输出数据y[n]的实部和虚部,CORDIC的补偿系数为K:A0和ω0分别为h[0]/K2在极坐标系下的幅度和相位;A1和ω1分别为h[1]/K2在极坐标系下的幅度和相位;A2和ω2分别为h[2]/K2在极坐标系下的幅度和相位;A3和ω3分别为h[3]/K2在极坐标系下的幅度和相位。则,图11中示出的4抽头滤波器对输入数据x[n]进行处理,输出数据y[n]的具体过程为:预处理单元1000接收输入数据x[n],将其转换后输出幅度Ax0和相位ωx0,相位ωx0和ω0输入复数乘单元的加法器1011进行相加运算,幅度Ax0和A0输入复数乘单元的乘法器1021进行相乘运算,加法器1011的运算结果ωx0+ω0以及乘法器1021的运算结果Ax0*A0输入后处理单元1031进行转换,获得实部yi0和虚部yq0。经预处理单元1000转换后输出的相位ωx0经延迟模块1041延迟后得到ωx1,经预处理单元1000转换后输出的幅度Ax0经延迟模块1051延迟后得到幅度Ax1,ωx1和ω1输入加法器1012进行相加运算,Ax1和A1输入乘法器1022进行相乘运算,加法器1012的运算结果ωx1+ω1以及乘法器1021的运算结果Ax1*A0输入后处理单元1032进行转换,获得实部yi1和虚部yq1。后处理单元1031输出的yi0和后处理单元1032输出的yi1经加法器1061进行相加运算后得到yi0+yi1并输入至加法器1062,后处理单元1031输出的yq0和后处理单元1032输出的yq1经加法器1071进行相加运算后得到yq0+yq1并输入至加法器1072。经第一级延迟得到的相位ωx0经延迟模块1042延迟后得到相位ωx2,经第一级延迟得到的幅度Ax0经延迟模块1052延迟后得到幅度Ax2,ωx2和ω2输入加法器1013进行相加运算,Ax2和A2输入乘法器1023进行相乘运算,加法器1013的运算结果ωx2+ω2以及乘法器1023的运算结果Ax2*A2输入后处理单元1033进行转换,获得实部yi2和虚部yq2。后处理单元1033输出的yi2输入加法器1062,与yi0+yi1进行相加运算后得到yi0+yi1+yi2并输入加法器1063,同样的,后处理单元1033输出的yq2输入加法器1072,与yq0+yq1进行相加运算后得到yq0+yq1+yq2并输入加法器1073。经第二级延迟后得到的相位ωx2经延迟模块1043延迟后得到相位ωx3,经第二级延迟后得到的Ax2经延迟模块1053延迟后得到幅度Ax3,ωx3和ω3输入加法器1014进行相加运算,Ax3和A3输入乘法器1024进行相乘运算,加法器1013的运算结果ωx3+ω3以及乘法器1023的运算结果Ax3*A3输入后处理单元1034进行转换,获得实部yi3和虚部yq3。后处理单元1034输出的yi3输入加法器1063,与yi0+yi1+yi2进行相加运算后得到yi0+yi1+yi2+yi3=yi,同样的,后处理单元1034输出的yq3输入加法器1073,与yq0+yq1+yq2进行相加运算后得到yq0+yq1+yq2+yq3=yq。通过上述处理过程便得到了输出数据y[n]。本申请实施例提供的滤波器与现有技术中的滤波器相比,大大降低了硬件开销,下表1示出了现有技术中的两种滤波器以及本发明提供的滤波器的硬件开销情况,其中,表中的现有技术一指的是图1示出的滤波器,现有技术二指的是基于图1示出的滤波器进行优化的滤波器(优化后的复数乘法器如图3所示)。表2示出了乘法器和CORDCI模块(包括计算器1和计算器2)的硬件开销对比情况。表1现有技术中的滤波器与本发明提供的滤波器的硬件开销对比滤波器乘法器个数加法器个数CORDIC个数寄存器个数现有技术一4N4N-202N-2现有技术二3N7N-202N-2本发明N3N-2N+12N-2表2乘法器和CORDCI模块硬件开销对比(输入位宽为9bit)工艺:TSMC40nm面积:um2乘法器(9x9bit)640CORDIC(迭代级数9)1206从表1中可以看出,本发明提供的滤波器与现有技术一相比,通过增加N+1个CORDIC模块,节省了3N个乘法器和N个加法器,可以理解的是,滤波器的抽头数量越多,则本发明与现有技术一相比节省的乘法器和加法器越多。本发明提供的滤波器与现有技术二相比,通过增加N+1个CORDIC模块,节省了2N个乘法器和4N个加法器,同样的,滤波器的抽头数量越多,则本发明与现有技术二相比节省的乘法器和加法器越多。而从表2中可以看出,一个CORDIC模块的硬件资源小于等于两个乘法器的资源,将一个CORDIC模块折算成两个乘法器后,本发明应用的乘法器为3N+2个,加法器为3N-2个,将本发明的整体硬件资源与现有技术对比发现,本发明提供的滤波器大大降低了硬件资源,相应大大降低了滤波器的硬件开销,尤其适用于硬件乘法资源紧张的系统中。鉴于极坐标系下的复数乘运算较简单,本发明实施例提供的滤波器,通过将直角坐标系下的数据转换到极坐标系下,使得滤波器中占据主要硬件开销的复数乘法器的结构相比于现有技术得到简化,即极坐标系下的复数乘法器所需的乘法器和加法器的数量减少,这使得复数乘法器的硬件资源减少,相应的滤波器的整体硬件资源减少,滤波器的整体硬件开销降低,进而使得芯片面积减小,硬件成本降低。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1