解码装置、解码方法、及程序与流程
本发明涉及编码技术,特别是涉及有效地进行解码处理的技术。
背景技术:
现有的纠错码技术有里德-所罗门码(reed-solomoncodes)。里德-所罗门码例如记载于非专利文献1中。
纠错码的编码处理作为明文的输入向量a乘以线形变换(即矩阵)a而得到输出向量b的处理能够通过式(1)表现。即,矩阵a的第i号的行表示为了生成输出向量b的第i号的元素bi而与输入向量a的各元素相乘的系数。
b=aa…(1)
纠错码的解码处理也能够看作是线形变换。能够将a',b'作为a,b中的提取了仅与用于解码的k个元素对应的行的矩阵或向量,通过式(2)来表现。
b'=a'a…(2)
因此,如果矩阵a存在逆矩阵,则能够通过(3)进行解码。
a=a'-1b'…(3)
在纠错码的编码中,输入向量a为式(4)表示的k次的向量。其中,k是2以上的整数。
输出向量b为式(5)表示的n次的向量。其中,n是2以上的整数,且n≧2k-1。
矩阵a是将式(6)表示的k行k列的单位矩阵和m行k列的范特蒙德矩阵(vandermondematrix)纵向连结的矩阵。其中,m=n-k。范特蒙德矩阵是在行或列的矩阵元素中按顺序排列等比数列的各项的特别结构的矩阵。
其中,
i∈{0,...,n-1},j∈{0,...,k-1}
即,矩阵a是式(7)那种n行k列的矩阵。
矩阵a中至第k行为单位矩阵,因此,输出向量b的至第k号的元素b0,…,bk-1与输入向量a的元素a0,…,ak-1一致。在输出向量b中,将与输入向量a的元素一致的元素称作数据共享,将其以外的元素称作奇偶共享。
现有技术文献
专利文献
非特許文献1:バァナード·スカラー著、“ディジタル通信基本和応用”、ピアソン·エデュケーション、2006年
发明所要解决的课题
在现有的纠错码技术中,存在处理量大的课题。特别是,在解码处理中进行的域相乘的处理量大。
技术实现要素:
本发明的目的在于,鉴于这样的方面,提供一种能够降低编码技术中的域相乘的处理量的解码技术。
用于解决课题的技术方案
为了解决所述课题,本发明提供一种解码装置,x是生成扩展域gf(xq)的不可约多项式f[x]的根x,n,k是2以上的整数,n≧2k-1,m是1以上的整数,m=n-k,a是以a0,…,ak-1∈gf(xq)为元素的k次向量,a是以下式定义的n行k列的矩阵,
其中
i∈{0,...,n-1},j∈{0,...,k-1}
b是以b0,…,bn-1∈gf(xq)为元素且将所述向量a和所述矩阵a相乘所得的n次向量,
所述解码装置包含:
使用所述向量b的
通过下式生成
通过将所述向量b'和所述逆矩阵a'-1相乘而计算所述向量a的元素
发明效果
根据本发明,能够降低编码技术中的域相乘的处理量。
附图说明
图1是示例解码装置的功能结构的图;
图2是示例解码方法的处理流程的图。
具体实施方式
在说明实施方式之前,说明本发明的原理。
作为前提,在以下的说明中,x是将不可约多项式设为f[x]=x64+x4+x3+x2+x+1的扩展域gf(264)的根x。在将x以整数表现时为2。
gf(264)是多项式除以以mod2整数为系数的64次多项式f[x]所得的(作为多项式的除法运算)余数的集合。作为域能够进行四则运算。也可以考虑具有特殊的运算的位的64次向量。gf(264)能够以64位整数表现,以2i表现项xi。例如,1+x+x3能够表现为20+21+23=11。
a,b∈gf(264)的乘法运算是将两个63次多项式a,b(式(8))相乘后除以64次多项式f的操作(式(9))。此时,λ次的项的系数为式(10)。
式(9)中,将对126次多项式进行modf而设为63次多项式的处理称为化简(reduction)。化简是使用式(11)的同值关系进行处理。
f=x64+x4+x3+x+1=0modf…(11)
如果将式(11)变形,则如式(12)所示,成为将64次项降为4次式的关系。
x64=x4+x3+x+1modf…(12)
如式(13)所示,64次以上的项也全部降低60次次数。
x64+n=xn(x4+x3+x+1)modf…(13)
能够使用63次多项式g和62次多项式h将126次多项式如式(14)那样表现。
g+x64h=g+(x4+x3+x+1)hmodf…(14)
某任意的元素a和x+1的乘法运算(x+1)a能够由式(15)表现。
另外,xna由于a的各项为高n次的项,因此,与整数表现中的2n倍、或n位左移等效。因此,能够如式(16)那样表现。
h是62次多项式,因此,式(16)的
成为64次以上的多项式,需要再次降低次数。64次以上的部分如式(17)。
在64位整数内,如果考虑舍去超过64位的位,则只要计算式(18)即可。
在进行乘法运算时,在一方为61位以内时(更准确而言将两方的位数相加成为125以下时),式(19)成立,因此,能够将化简高效化。
因此,如果包含化简在内加以考虑,则在61位数中仅1位成立的数、即与0≦i≦60的范围内的2i的乘法运算是高速的。
如上述,在纠错码的解码处理中,通过将提取了用于解码的向量b的元素的向量b'、和用于编码处理的矩阵a中的提取了与向量b'的元素对应的行的矩阵a'的逆矩阵相乘,对明文的向量a进行解码。在数据共享b0,…,bk-1全部可利用的情况下,数据共享是输入向量的各元素本身,因此,只要将输入直接输出即可。另一方面,在即使只有一个不能利用的数据共享的情况下,也需要根据可利用的数据共享和奇偶共享将明文复原。
明文的复原如下进行。设存在
代替将逆矩阵直接相乘,利用数据共享仅具有一个输入向量的元素的情况,首先,从奇偶共享中除去与数据共享对应的输入向量的元素。例如,能够如式(21)那样使用数据共享b0,从奇偶共享bp(其中,p为与任意的奇偶共享对应的编号)除去了第0号的明文的元素。
根据b0=(100…0)a,
bp=(1xp-kx(p-k)2…x(p-k)(k-1))a,
bp-b0=(0xp-kx(p-k)2…x(p-k)(k-1))a…(21)
如果使用这样的变形,则能够使用比k次低次的
其中,
将式(22)的左边设为向量b',如式(23),只要乘以
其中
用于生成向量b'所需的处理量为式(24)。此外,bmul是一方为单项式的相乘的次数,bred是最高次项的次数的合计为2q-d-1以下的相乘中的化简的次数。
向量b'和
因此,整体的处理量为将式(24)和式(25)合并成的式(26)。
在不能利用的数据共享为1个的情况下,即
在不能利用的数据共享为2个以上4个以下的情况下,即
剩余的ae0使用式(28)中求出的
该情况下的处理量为式(30)。
对通过式(30)减少处理量的情况进行说明。首先,bmul和mul的合计数在式(20)(26)(30)中均相等,为
在不能利用的数据共享为2个的情况下,
在不能利用的数据共享为3个以上的情况下,乘以逆矩阵时的处理量成为式(32)。
在此,尝试仅将
于是,通过与除去数据共享成分时相同的方法,通过式(34)的处理量能够消减1次次数。
在重复该次数消减的情况下,处理量成为式(35)。
与式(26)相比,mul和bmul的总数相等,mul的比率减轻约一半。仅bred增加,但由于增量与mul的减少量相等,所以如果bul+bred<mul,则作为整体,处理量降低。
就绝对的计算量而言,式(35)为最小,但在一个一个地将数据共享复原,反复从其它奇偶共享除去该成分的方法中,存在mul和red的并行性降低的问题。与和并列性高的逆矩阵的乘法运算相比,仅能依次执行的处理会增加,因此,性能会因cpu的mul,red的可并行执行的数而降低。因此,最终反复进行通过cpu的mul,red的每次可并行执行的数的逆矩阵进行复原,从奇偶共享除去该复原了的成分的方法最快。此外,mul的可并行执行的数在intel公司的ivy-bridge中为1,在haswell中为2,red的可并行执行的数在ivy-bridge,haswell均为2。
下式表示实现了上述的纠错码的解码处理的算法的例子。此外,f是不能利用的个数,d0,…,dk-f-1是k-f个可利用的数据共享编号,p0,…,pf-1是f个能利用的奇偶共享编号,e0,…,ef-1是应复原的明文编号,以k-f个数据共享bd0,…,bdk-f-1、f个奇偶共享bp0,…,bpf-1作为输入,以系数矩阵的列c0,…,系数c0,c1作为辅助输入,以明文ae0,…,aef-1作为输出。
1:
2:iff∈{3,4}then
3:
4:f′:=f-1
5:else
6:b″:=b′(仅视为。不进行复制等)
7:f′:=f
8:i:=0
9:whilef′>2do
10:
11:
12:f′:=f′-2
13:iff′=2then
14:
15:
16:
作为辅助输入的系数矩阵ci及系数c0,c1根据
在
在
在
在
在
以下,对本发明的实施方式进行详细说明。此外,对于附图中具有相同功能的结构部标注同一编号,省略重复说明。
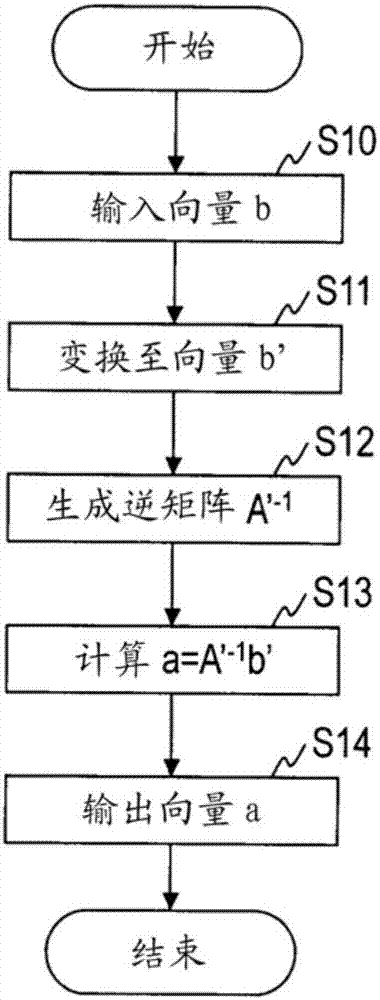
如图1所示,实施方式的解码装置1包含向量输入单元10、向量变换单元11、逆矩阵生成单元12、明文计算单元13、及向量输出单元14。该解码装置1通过进行图2所示例的各步骤的处理,实现实施方式的解码方法。
解码装置1例如是使具有中央运算处理装置(cpu:centralprocessingunit)、主存储装置(ram:randomaccessmemory)等的公知或专用的计算机读入特别的程序而构成的特别的装置。解码装置1例如基于中央运算处理装置的控制来执行各处理。被输入解码装置1的数据或各处理中得到的数据例如存储于主存储装置中,存储于主存储装置的数据根据需要被读出到中央运算处理装置而用于其它处理。解码装置1的各处理单元也可以至少一部分由集成电路等硬件构成。
参照图2说明实施方式的解码方法的处理步骤。
在步骤s10,向向量输入单元10输入n次向量b。n次向量b的奇偶共享中的可利用的
其中
i∈{0,...,n-1},j∈{0,...,k-1}
在步骤s11,向量变换单元11使用
在步骤s12,逆矩阵生成单元12通过式(39)生成
在步骤s13,如式(40)所示,明文计算单元13通过将向量b'和逆矩阵a'-1相乘而计算向量a的元素
在步骤s14,向量输出单元14将从向量输入单元10接收的
通过如上述构成,根据实施方式的解码装置,在将作为k次正方矩阵的矩阵a'消减次数为
本发明的解码技术可以适用于计算量的秘密分散。计算量型秘密分散是基于计算量的安全性从小于一定个数的分散值完全不能将原始数据复原的秘密分散方式。计算量型秘密分散例如记载于下述参考文献1中。
〔参考文献1〕h.krawczyk,“secretsharingmadeshort.”,crypto1993,pp.136-146,1993.
不言而喻,本发明不限于上述的实施方式,在不脱离本发明的宗旨的范围内也可以进行适宜变更。上述实施方式中说明的各种处理不仅按照记载的顺序以时间系列执行,而且还可以根据执行处理的装置的处理能力或需要并列或单独地执行。
[程序、记录介质]
在上述实施方式中说明的各装置中的各种处理功能通过计算机实现的情况下,各装置应具有的功能的处理内容通过程序进行记述。而且,通过由计算机执行该程序,在计算机上实现上述各装置中的各种处理功能。
记述有该处理内容的程序能够事先记录于可由计算机读取的记录介质中。作为可由计算机读取的记录介质,例如也可以为磁记录装置、光盘、光磁记录介质、半导体存储器等。
另外,该程序的流通对记录了该程序的dvd、cd-rom、usb存储器等可移动记录介质进行销售、转让、借出等来进行。进而,也可以将该程序储存至服务器计算机的存储装置,经由网络从服务器计算机向其他计算机转发该程序,从而使该程序流通。
执行这样的程序的计算机例如首先将在可移动记录介质中记录的程序或从服务器计算机转发的程序暂时储存至自己的存储部。并且,在执行处理时,该计算机读取在自己的记录介质中储存的程序,执行按照所读取的程序的处理。另外,作为该程序的另一实施方式,也可以设为计算机从可移动记录介质直接读取程序,执行按照该程序的处理。进而,也可以设为在每次从服务器计算机向该计算机转发程序时,逐次执行按照所接受的程序的处理。另外,也可以设为不进行从服务器计算机向该计算机的程序的转发,而是通过仅通过其执行指示和结果取得来实现处理功能的所谓asp((应用服务提供商(applicationserviceprovider))型的服务来执行上述的处理的结构。此外,在本方式的程序中,包括供电子计算机的处理用的信息且遵照程序的数据(虽然不是对于计算机的直接指令但具有规定计算机的处理的性质的数据等)。
另外,在该方式中,通过在计算机上执行预定的程序而构成了各装置,但这些处理内容的至少一部分也可以通过硬件来实现。
- 还没有人留言评论。精彩留言会获得点赞!