用于通信或广播系统中的信道编码/解码的装置和方法与流程
本公开涉及一种用于通信或广播系统中的信道编码/解码的装置和方法。更具体地,本公开涉及一种用于能够支持各种输入长度和编码速率的低密度奇偶校验(lowdensityparitycheck,ldpc)编码/解码的装置和方法。
背景技术:
为了满足对自第四代(fourthgeneration,4g)通信系统部署以来已经增长的无线数据业务的需求,已经做出努力以开发改进的第五代(fifthgeneration,5g)通信系统或预5g通信系统。因此,5g或预5g通信系统也被称为“超4g网络”或“后长期演进(longtermevolution,lte)系统”。
5g通信系统被考虑在更高频率的毫米波(mmwave)频带(例如,60ghz频带)中实施,以便实现更高的数据速率。为了降低无线电波的传播损耗并且增加传输距离,在5g通信系统中,波束成形、大规模多输入多输出(multiple-inputandmultiple-output,mimo)、全维mimo(fulldimensionalmimo,fd-mimo)、阵列天线、模拟波束成形和大规模天线技术被讨论。
此外,在5g通信系统中,正在基于高级小型小区、云无线电接入网(radioaccessnetwork,ran)、超密集网络、设备对设备(device-to-device,d2d)通信、无线回程、移动网络、协作通信、协调多点(coordinatedmulti-points,comp)、接收端干扰对消等进行系统网络改进的开发。
在5g系统中,作为高级编码调制(advancedcodingmodulation,acm)的混合fsk和qam调制(hybridfskandqammodulation,fqam)和滑动窗口叠加编码(slidingwindowsuperpositioncoding,swsc)以及作为高级接入技术的滤波器组多载波(filterbankmulticarrier,fbmc)、非正交多址(non-orthogonalmultipleaccess,noma)和稀疏码多址(sparsecodemultipleaccess,scma)已经被开发。在通信或广播系统中,由于各种种类的信道噪声、衰落现象和符号间干扰(inter-symbolinterference,isi),链路性能可能会显著恶化。因此,为了实施需要高数据吞吐量和可靠性的高速数字通信或广播系统(诸如下一代移动通信、数字广播和便携式因特网),需要开发能够克服噪声、衰落和符号间干扰的技术。最近,作为克服噪声等的研究的一部分,针对纠错码的研究已经作为用于通过有效恢复信息失真来加强通信可靠性的方法而积极地进行。
上述信息仅作为背景信息呈现,以帮助理解本公开。对于任何上述内容是否可应用为关于本公开的现有技术应用,没有做出确定,也没有做出断言。
技术实现要素:
技术问题
本公开的方面用以解决至少上述问题和/或缺点,并且提供至少下面描述的优点。因此,本公开的一方面用以提供一种用于能够支持各种输入长度和编码速率的低密度奇偶校验(ldpc)编码/解码的装置和方法。
本公开的另一方面用以提供一种用于设计支持非常高的解码器吞吐量的ldpc码的奇偶校验矩阵的初等矩阵(elementarymatrix)的方法。
本公开的另一方面用以提供一种用于根据设计的奇偶校验矩阵的初等矩阵来设计奇偶校验矩阵的方法。
本公开的另一方面用以提供一种用于支持来自设计的奇偶校验矩阵的各种码字长度的ldpc编码/解码的装置和方法。
问题解决方案
根据本公开的一方面,提供了一种用于通信或广播系统中的信道编码的方法。该方法包括:确定块大小z;以及基于块大小和与块大小相对应的奇偶校验矩阵来执行编码,其中奇偶校验矩阵基于基矩阵(basematrix)和多个循环置换矩阵而确定,并且其中指示基矩阵的每一行中的非零元素的位置的列索引的一部分包括根据下面的数学表达式22的索引。
根据本公开的另一方面,提供了一种用于通信或广播系统中的信道解码的方法。该方法包括:确定块大小z;以及基于块大小和与块大小相对应的奇偶校验矩阵来执行解码,其中奇偶校验矩阵基于基矩阵和多个循环置换矩阵而确定,并且其中指示基矩阵的每一行中的非零元素的位置的列索引的一部分包括根据下面的数学表达式22的索引。
根据本公开的另一方面,提供了一种用于通信或广播系统中的信道编码的装置。该装置包括:收发器;以及至少一个处理器,其中该至少一个处理器被配置为确定块大小z并基于块大小和与块大小相对应的奇偶校验矩阵来执行编码,其中奇偶校验矩阵基于基矩阵和多个循环置换矩阵而确定,并且其中指示基矩阵的每一行中的非零元素的位置的列索引的一部分包括根据下面的数学表达式22的索引。
根据本公开的另一方面,提供了一种用于通信或广播系统中的信道解码的装置。该装置包括:收发器;以及至少一个处理器,其中该至少一个处理器被配置为确定块大小z并基于块大小和与块大小相对应的奇偶校验矩阵来执行解码,其中奇偶校验矩阵基于基矩阵和多个循环置换矩阵而确定,并且指示基矩阵的每一行中的非零元素的位置的列索引的一部分包括根据下面的数学表达式38的索引。
根据本公开的另一方面,提供了一种用于在通信或广播系统中生成ldpc码的方法。该方法包括满足平衡条件的初等矩阵的权重分布。
根据本公开的另一方面,提供了一种用于在通信或广播系统中生成ldpc码的方法。该方法包括满足部分窗口正交条件的初等矩阵的权重分布。
根据本公开的另一方面,提供了一种用于通信或广播系统中的信道解码的方法。该方法包括:确定奇偶校验矩阵的块大小;以及读出用于生成其中权重分布被强平衡的奇偶校验矩阵的序列。该方法进一步包括通过对序列应用操作来转换序列。
发明的有益效果
根据本公开的一方面,可以针对可变长度和可变速率支持ldpc码。
从以下结合附图公开了本公开的各种实施例的详细描述中,本公开的其他方面、优点和显著特征对于本领域技术人员将变得显而易见。
附图说明
从以下结合附图的描述中,本公开的某些实施例的上述和其他方面、特征和优点将变得更加显而易见,其中:
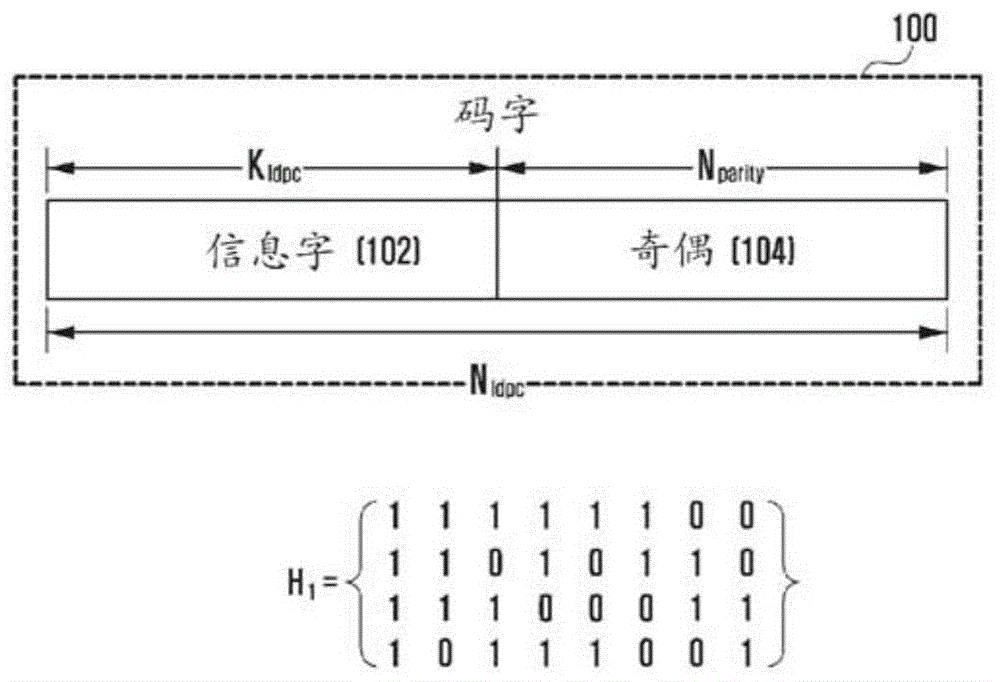
图1是示出根据本公开的实施例的系统性低密度奇偶校验(ldpc)码字的结构的示图;
图2是示出根据本公开的实施例的ldpc码的图形表达方法的示图;
图3是根据本公开的实施例的ldpc码的奇偶校验矩阵的结构的示图;
图4a、图4b和图4c是根据本公开的各种实施例的指数矩阵的示图;
图5是根据本公开的实施例的初等矩阵的示图;
图6是根据本公开的实施例的针对具有图5的初等矩阵的奇偶校验矩阵使用两个块并行处理器(blockparallelprocessor)执行ldpc解码的调度的示图;
图7是根据本公开的实施例的初等矩阵的示图;
图8是根据本公开的实施例的针对具有图7的初等矩阵的奇偶校验矩阵使用两个块并行处理器执行ldpc解码的调度的示图;
图9a、图9b和图9c是根据本公开的各种实施例的指数矩阵的示图;
图10是示出根据本公开的实施例的发送/接收设备的配置的框图;
图11a是示出根据本公开的实施例的解码设备的结构的示图;
图11b是示出根据本公开的实施例的编码设备的结构的示图;
图12是示出根据本公开的实施例的传输块的结构的示图;
图13a、图13b、图13c、图13d、图13e、图13f、图13g、图13h和图13i是根据本公开的各种实施例的其他初等矩阵的示图;
图14a、图14b、图14c、图14d、图14e、图14f、图14g、图14h和图14i是根据本公开的各种实施例的其他指数矩阵的示图;
图15a、图15b和图15c是根据本公开的各种实施例的其他初等矩阵的示图;
图16a、图16b、图16c、图16d和图16e是根据本公开的各种实施例的其他初等矩阵的示图;
图17a、图17b、图17c、图17d和图17e是根据本公开的各种实施例的其他初等矩阵的示图;
图18a、图18b、图18c、图18d和图18e是根据本公开的各种实施例的其他初等矩阵的示图;
图19a、图19b、图19c、图19d和图19e是根据本公开的各种实施例的其他指数矩阵的示图;
图20a、图20b、图20c、图20d和图20e是根据本公开的各种实施例的其他指数矩阵的示图;
图21a、图21b、图21c、图21d、图21e、图21f、图21g、图21h、图21i和图21j是根据本公开的各种实施例的其他初等矩阵的示图;
图22a、图22b、图22c和图22d是根据本公开的各种实施例的其他指数矩阵的示图;
图23a、图23b、图23c和图23d是根据本公开的各种实施例的其他指数矩阵的示图;并且
图24a、图24b、图24c和图24d是根据本公开的各种实施例的其他初等矩阵的示图。
在整个附图中,相似的附图标记将被理解为指代相似的部分、组件和结构。
具体实施方式
提供了参考附图的以下描述,以帮助全面理解由权利要求及其等同物限定的本公开的各种实施例。它包括各种具体细节以帮助理解,但这些将仅仅被视为示例性的。因此,本领域的普通技术人员将认识到,在不脱离本公开的范围和精神的情况下,可以对本文描述的各种实施例进行各种改变和修改。另外,为了清楚和简洁,可能省略对熟知的功能和结构的描述。
在以下描述和权利要求中使用的术语和词语不限于书面含义,而是仅由发明人使用以使得能够清楚和一致地理解本公开。因此,对于本领域技术人员来说显而易见的是,提供本公开的各种实施例的以下描述仅仅是为了说明的目的,而不是为了限制由所附权利要求及其等同物限定的本公开的目的。
应该理解的是,单数形式“一”和“该”包括复数指示物,除非上下文另外清楚地指定。因此,例如,对“组件表面”的引用包括对这样的表面中的一个或多个的引用。
术语“基本上”意味着所述特性、参数或值不需要精确地实现,而是偏差或变化(包括例如,公差、测量误差、测量精度限制和本领域技术人员已知的其他因素)可以以不排除特性意图提供的效果的量出现。
gallager在20世纪60年代首次引入的低密度奇偶校验(ldpc)码被遗忘了很长时间,因为其使得从当时的技术水平来看难以实施的复杂性。然而,在1993年,由于由berrou、glavieux和thitimajshima提出的turbo码展示出接近shannon信道容量的性能,所以利用对turbo码的性能和特性进行的大量分析,对基于图形和迭代解码的信道编码进行了许多研究。借此机会,ldpc码在20世纪90年代后半期被重新研究,并且很明显,通过对与ldpc码相对应的tanner图应用基于和积算法(sum-productalgorithm)的迭代解码来执行解码,ldpc码也具有接近shannon信道容量的性能。
通常,ldpc码被定义为奇偶校验矩阵,并且可以使用通常称为tanner图的二分图来表达。
图1是说明根据本公开的实施例的系统性ldpc码字的结构的示图。
在下文中,参考图1,将描述系统性ldpc码字。
参考图1,ldpc码接收由kldpc比特或kldpc个符号组成的信息字102的输入,并生成由nldpc比特或nldpc个符号组成的码字100。在下文中,为了便于解释,假设输入包括kldpc比特的信息字102,并且生成由nldpc比特组成的码字100。例如,如果由kldpc输入比特组成的信息字
ldpc码是一种线性块码,并且包括确定满足如下面的数学表达式1中表达的条件的码字的过程。
[数学表达式1]
这里,c是
在数学表达式1中,h表示奇偶校验矩阵,c表示码字,ci表示第i个比特,并且nldpc表示ldpc码字的长度。这里,hi表示奇偶校验矩阵h的第i列。
奇偶校验矩阵h由nldpc列组成,其中列的数量等于ldpc码字的比特数。由于数学表达式1意味着奇偶校验矩阵的第i列hi与第i个码字比特ci的乘积之和为0,因此第i列hi与第i个码字比特ci相关。
图2是示出根据本公开的实施例的ldpc码的图形表达方法的示图。
参考图2,将描述ldpc码的图形表达方法。
图2示出了由4行和8列组成的ldpc码的奇偶校验矩阵h1的示例以及示出h1的tanner图。参考图2,由于奇偶校验矩阵h1具有8列,因此它生成长度为8的码字。通过h1生成的码意味着ldpc码,并且每一列对应于编码的8比特。
参考图2,基于奇偶校验矩阵h1执行编码和解码的ldpc码的tanner图由8个变量节点(variablenode)x1(202)、x2(204)、x3(206)、x4(208)、x5(210)、x6(212)、x7(214)和x8(216)以及4个校验节点218、220、222和224组成。这里,ldpc码的奇偶校验矩阵h1的第i列和第j行分别对应于变量节点xi和第j个校验节点。此外,ldpc码的奇偶校验矩阵h1的第j列和第j行彼此交叉的点处的值1,即非零值,意味着在tanner图上存在将变量节点xi和第j个校验节点彼此连接的边,如图2所示。
在ldpc码的tanner图中,变量节点和校验节点的度数(degree)意味着连接到各个节点的边数,并且该数量等于与ldpc码的奇偶校验矩阵中的对应节点相对应的列或行中的非零元(entry)的数量。例如,图2中的变量节点x1(202)、x2(204)、x3(206)、x4(208)、x5(210)、x6(212)、x7(214)和x8(216)的度数依次分别变为4、3、3、3、2、2、2和2,并且校验节点218、220、222和224的度数依次变为6、5、5和5。此外,在与图2的变量节点相对应的图2的奇偶校验矩阵h1的各个列中,非零元的数量依次与上述度数4、3、3、3、2、2、2和2一致,并且在与图2的校验节点相对应的图2的奇偶校验矩阵h1的各个行中,非零元的数量依次与上述度数6、5、5和5一致。
可以使用基于图2中枚举的二分图上的和积算法的迭代解码算法来解码ldpc码。这里,和积算法是一种消息传递算法,并且这样的消息传递算法是其中通过二分图上的边交换消息并且从输入到变量节点或校验节点的消息计算和更新输出消息的算法。
这里,可以基于第i个变量节点的消息确定第i个编码比特值。对于第i个编码比特值,硬判决和软判决都是可能的。因此,作为ldpc码字的第i个比特的ci的性能对应于tanner图的第i个变量节点的性能,并且这可以根据奇偶校验矩阵的第i列中的1的位置和数量而确定。换句话说,码字的nldpc个码字比特的性能可以由奇偶校验矩阵的1的位置和数量主导,这意味着ldpc码的性能受到奇偶校验矩阵的很大影响。因此,为了设计具有优越性能的ldpc码,需要用于设计良好奇偶校验矩阵的方法。
为了实施在通信或广播系统中使用的奇偶校验矩阵,广泛使用通常使用准循环型奇偶校验矩阵的准循环ldpc(quasi-cyclicldpc,qc-ldpc)码。
qc-ldpc码的特征在于具有由方阵形式的零矩阵、或循环置换矩阵组成的奇偶校验矩阵。在这种情况下,置换矩阵指示其中方阵的所有元都是0或1并且每一行或每一列仅包括一个1的矩阵。此外,循环置换矩阵意味着其中单位矩阵的各个元向右循环移位的矩阵。
在下文中,将在下面描述qc-ldpc码。
如数学表达式2中那样定义具有l×l大小的p=(pi,j)。这里,pi,j意味着矩阵p的第i行和第j列中的元(这里,0≤i,并且j<l)。
[数学表达式2]
针对如上定义的置换矩阵p,pi(0≤i<l)是循环置换矩阵,其形式为具有l×l大小的单位矩阵的各个元在右方向上循环移位多达i次。
最简单的qc-ldpc码的奇偶校验矩阵h可以以下面的数学表达式3的形式而表达。
[数学表达式3]
如果将p-1定义为具有l×l大小的零矩阵,则数学表达式3中的循环置换矩阵或零矩阵的每个指数ai,j具有{-1,0,1,2,...,l-1}值中的一个。此外,由于数学表达式3中的奇偶校验矩阵h具有n个列块和m个行块,因此它具有ml×nl大小。
如果数学表达式3中的奇偶校验矩阵具有满秩,很明显与奇偶校验矩阵相对应的qc-ldpc码的信息字比特的大小变为(n-m)l。为了方便起见,与信息字比特相对应的(n-m)个列块被称为列块,并且与剩余奇偶比特相对应的m个列块被称为奇偶列块。
通常,通过在数学表达式3的奇偶校验矩阵中分别以1和0替换每个循环置换矩阵和零矩阵而获得的具有m×n大小的二进制矩阵被称为母矩阵或基矩阵m(h),并且通过选择每个循环置换矩阵和零矩阵的指数而获得的如数学表达式4中的具有m×n大小的整数矩阵被称为奇偶校验矩阵的指数矩阵e(h)。
[数学表达式4]
结果,被包括在指数矩阵中的一个整数对应于奇偶校验矩阵中的循环置换矩阵,并且因此为了方便起见,指数矩阵可以被表达为由整数组成的序列(上述序列也可以被称为ldpc序列或ldpc码的序列,以便区别于其他序列)。通常,奇偶校验矩阵不仅可以被表达为指数矩阵,还可以被表达为在代数上(algebraically)具有相同特性的序列。在本公开的实施例中,为了方便起见,奇偶校验矩阵被表达为指示存在于奇偶校验矩阵中的1的位置的指数矩阵或序列。然而,存在能够区分被包括在奇偶校验矩阵中的1或0的位置的各种序列记号方法,并且因此奇偶校验矩阵不限于在描述中表达的方法,而是可以以在代数上代表相同效果的各种序列形式而表达。
此外,根据实施方式的特征,设备上的收发器可以通过直接生成奇偶校验矩阵来执行ldpc编码和解码,或者可以使用在代数上具有与奇偶校验矩阵相同的效果的指数矩阵或序列来执行ldpc编码和解码。因此,尽管在本公开的实施例中,为了方便起见,已经描述了使用奇偶校验矩阵的编码/解码,但是应该考虑到可以使用能够获得与奇偶校验矩阵相同的效果的各种方法来实施编码/解码。
作为参考,在代数上相同的效果意味着可以解释两个或更多个不同的表达在逻辑或数学上彼此完全相等或可相互转换。
在本公开的实施例中,为了方便起见,描述了一个循环置换矩阵对应于一个块,但是本公开甚至可以应用于几个循环置换矩阵被包括在一个块中的情况。例如,如果两个循环置换矩阵
[数学表达式5]
[数学表达式6]
如在如上所述的实施例中,通常qc-ldpc码的特征在于多个循环置换矩阵可以对应于奇偶校验矩阵中的一个行块和一个列块。在本公开中,为了方便起见,将仅描述一个循环置换矩阵对应于一个块的情况,但是本公开的主题不限于此。作为参考,其中多个循环置换矩阵在一个行块和一个列块中是重复的、具有l×l大小的矩阵被称为循环矩阵或循环。
另一方面,数学表达式5和6中的奇偶校验矩阵的母矩阵或基矩阵和指数矩阵意味着通过以类似于在数学表达式3中使用的定义的方式分别以1和0替换每个循环置换矩阵和零矩阵而获得的二进制矩阵,并且被包括在一个块中的多个循环置换矩阵(即,循环矩阵)之和简单地以1替换。
由于根据奇偶校验矩阵确定ldpc码的性能,因此有必要为具有优越性能的ldpc码设计奇偶校验矩阵。此外,为了系统中的各种服务,能够支持灵活输入长度和编码速率的ldpc编码或解码方法是必要的。在设计ldpc码时,不仅编码性能和灵活性,而且解码效率也成为重要因素。通常,众所周知,qc-ldpc码具有对并行解码有利的结构,并且并行解码适合于通过增加解码吞吐量来减少由于解码引起的延迟。qc-ldpc码的并行解码可以根据奇偶校验矩阵的基矩阵进一步最大化解码效率。在本公开的实施例中,提出了能够最大化解码效率的基矩阵结构,并且此外,提出了一种用于设计基矩阵的方法。
图3是根据本公开的实施例的ldpc码的奇偶校验矩阵的结构的示图。
参考图3,将描述如图3所示的奇偶校验矩阵的结构。在图3中,部分矩阵a和d的部分对应于k个信息字比特,并且部分矩阵b和d的剩余部分对应于g个第一奇偶比特。部分矩阵c和e对应于(n-k-g)个第二奇偶比特。通常,在基于具有图3的结构的奇偶校验矩阵的ldpc编码/解码系统中,c可以被配置为零矩阵,并且e可以被限制为单位矩阵或下三角矩阵。在本公开的实施例中,为了支持各种多速率或需要高灵活性的技术,诸如增量冗余(incrementalredundancy,ir)harq。在本公开的实施例中,为了便于解释,下面仅描述e是单位矩阵的情况,但是本公开的主题不限于e是单位矩阵的情况。
图4a至图4c是根据本公开的各种实施例的指数矩阵的示图。
参考图4a至图4c,下面将描述图4a的指数矩阵。作为参考,图4b和图4c是示出图4a的指数矩阵的各个部分的放大图。图4a的每个部分对应于其中与在各个部分上描述的附图标记相对应的矩阵被组合的矩阵。因此,可以通过图4b和图4c的部分的组合来配置如图4a所示的一个指数矩阵。
图4a的指数矩阵的基矩阵如图5所示。在图4a的指数矩阵中,空子块意味着大小为zxz的零矩阵,并且元0意味着单位矩阵。此外,在图5的基矩阵中,空块意味着元为0。
图5是根据本公开的实施例的初等矩阵的示图。
参考图5,图4a的每个行块中的循环矩阵的位置,即图5的每一行中的1的位置,可以基于列块而概括,以示例性地表达如下(第一行作为第零行开始)。
...
行-6(row-6):{0,1,13,16,23,38}
行-7:{1,2,4,10,11,13,17,21,27,32,39}
行-8:{0,8,15,19,24,30,35,40}
行-9:{0,1,5,9,14,20,22,25,41}
行-10:{0,1,3,29,33,37,42}
行-11:{1,6,12,14,20,23,26,43}
...
通常,在ldpc解码器使用一个块并行处理器执行ldpc码的解码的情况下,该解码以与各个行块中的上述位置相对应的块为单位而连续执行。在使用两个或更多个块并行处理器的情况下,每个处理器以与从各个行块适当划分的块为单位执行连续解码。在这种情况下,从各个行块划分的块应该根据硬件实施特性以针对所有行块确定的规则而划分。例如,可以考虑ldpc解码器通过将被包括在各个行块中的循环置换矩阵划分为与偶数列块相对应的循环置换矩阵和与奇数列块相对应的循环置换矩阵,处理如图6所示的通过两个块并行处理器的调度。
图6是根据本公开的实施例的针对具有图5的初等矩阵的奇偶校验矩阵使用两个块并行处理器执行ldpc解码的调度的示图。
图6示出了与由各个处理器以流程顺序处理的一个循环置换矩阵相对应的块的调度枚举位置的示例。例如,处理器0以第0块、第16块和第38块的顺序处理行-6,然后以第2块、第4块、第10块、第32块和第39块的顺序处理行-7。
参考图6,根据确定的规则,第一处理器仅处理位于偶数列块中的循环置换矩阵,并且第二处理器仅处理位于奇数列块中的循环置换矩阵。这里,假设度数为1的列块不遵循上述规则,并且为了最小化各个处理器的空闲时间,适当的处理器可以选择性地处理对应列块。
即使以使用两个块并行处理器的上述规则而设计的ldpc解码器能够适当地布置与度数为1的列块相对应的块,但特定处理器的空闲时间也可能变长,如图6中的行-10的情况。由于这样的处理的低效率最终增加了整个处理时间,因此每小时的解码吞吐量降低,因此这可能导致解码延迟作为结果。换句话说,在正常使用两个或更多个块并行处理器执行解码的情况下,需要各个处理器通过适当的规则将被包括在各个行块中的块(即循环置换矩阵)划分为与处理器的数量一样多的集合,以便很好地分配要由各个处理器处理的块。
然而,在不考虑两个或更多个块并行处理器的使用的情况下设计ldpc码的奇偶校验矩阵的基矩阵之后,通常难以通过如上所述的适当规则来划分与处理器的数量一样多的块。具体地,在不知道ldpc解码器是使用两个、三个还是四个块并行处理器的情况下,这样做要困难得多。
本公开提出了一种用于设计基矩阵的方法,其中该基矩阵能够基于两个或更多个块并行处理器的使用,通过限制循环置换矩阵在指数矩阵中的位置(即,基于多个块并行处理器的使用,通过限制元1在基矩阵中的位置)来最大化解码效率。
首先,如果假设要设计的基矩阵作为图3的矩阵给出,则可以考虑a的大小是gxk,b的大小是gxg,d的大小是(n-k-g)x(k+g),并且e的大小是(n-k-g)x(n-k-g)。为了便于解释,在本公开的以下实施例中,将描述c为零矩阵且e为单位矩阵的情况,但基本上,在本公开的实施例中提出的方法不必限制于此。
本公开的主要目的是提出用于设计基矩阵使得基矩阵中的每一行的每个元1的位置索引根据基于多个块并行处理器的使用的预定规则而划分为多个集合的方法,其中在该多个集合中元的数量彼此类似。为了方便起见,基矩阵中的每一行的每个元1的位置索引根据预定规则而这样划分为其中元的数量彼此类似的集合被称为平衡。换句话说,平衡意味着在根据预定规则将每一行的每个元1分配给两个或更多个集合时的最大限度统一分配。
在这种情况下,如果分配给两个或更多个集合的行的元1的数量之间的差异等于或小于1,则称为完美平衡,而如果分配给两个或更多个集合的行的元1的数量之间的差异等于或小于2,则称为弱平衡。
换句话说,平衡意味着根据预定规则将各个行的元1最大限度统一分类为两个或更多个组。在这种情况下,如果被包括在两个或更多个组中的元1的数量之间的差异等于或小于1,则称为实现的完美平衡,而如果分配给两个或更多个集合的行的元1的数量之间的差异等于或小于2,则称为实现的弱平衡。
此外,换句话说,在表达该平衡时,基矩阵平衡可以意味着各个行的元1可以根据预定规则而分类为两个或更多个组或集合,并且其中被包括在各个组或集合中的元1的数量之间的差异或者它们的索引的数量之间的差异等于或小于1的情况可以被表达为基矩阵满足完美平衡,而其中差异等于或小于2的情况可以被表达为基矩阵满足弱平衡。
另一方面,在本公开的实施例中,可以使用术语第一平衡、第二平衡和第三平衡来表达具有不同特性的平衡,诸如完美平衡、弱平衡和强平衡。如上设计的基矩阵用于减少当使用块并行处理器基于与各个集合相对应的位置索引来执行ldpc解码时的空闲时间,其中该块并行处理器的数量对应于集合的数量。这里,明显的是,位置索引可以具有数字0到(n-1)。
在设计基矩阵之前,假设当使用具有对应的基矩阵的ldpc码的奇偶校验矩阵来执行ldpc解码时要使用的块并行处理器的可能数量对应于q1、q2、...、qp。换句话说,假设基于其中使用q1、q2、...、qp个块并行处理器的所有情况来设计基矩阵。如果假设使用qi(i=1,2,…,p)个块处理器执行ldpc解码,为了最小化空闲时间,针对基矩阵中度数为d的行的每个1的位置索引j1、j2、...、jd应该被划分为最大限度具有相同的元数量的qi部分矩阵。针对所有行,这应该以相同的方式建立。
满足这样的特性的实施例如下。
首先,如数学表达式7中所述,针对l=1,2,...,p定义q1个集合。
[数学表达式7]
si={x|x≡i(modql),x=0,1,...n-1},
i=0,1,2,...,ql-1
为了帮助理解,数学表达式7的简单示例在下面的数学表达式8中表达。
[数学表达式8]
i)当定义为q1=2
s0={x|x≡0(mod2),x=0,1,...45}={0,2,4,8,...,42,44}
s1={x|x≡1(mod2),x=0,1,...45}={1,3,5,7,...,43,45}
ii)当定义为q2=3
s0={x|x≡0(mod3),x=0,1,...45}={0,3,6,...,42,45}
s1={x|x≡1(mod3),x=0,1,...45}={1,4,7,...,40,43}
s2={x|x≡2(mod3),x=0,1,...45}={2,5,8,...,41,44}
iii)当定义为q3=4
s0={x|x≡0(mod4),x=0,1,...45}={0,4,8,...,40,44}
s1={x|x≡1(mod4),x=0,1,...45}={1,5,9,...,41,45}
s2={x|x≡2(mod4),x=0,1,...45}={2,6,10,...,38,42}
s3={x|x≡3(mod4),x=0,1,...45}={3,7,11,...,39,43}
(q1=定义为2个集合的情况,q2=定义为3个集合的情况,q3=定义为4个集合的情况)
在数学表达式7和8中,可以存在用于定义q1个集合的各种方法。在本公开的实施例中,为了便于解释,将描述在数学表达式7和8中表达的示例。然而,本公开的范围不限于此,并且在通常定义q1个集合的情况下,各个集合不必具有相同数量的元,而是可以根据需要而适当地定义。然而,各个集合si应始终具有不同的元。
在基矩阵中,关于每一行中的1的位置的信息可以被表达为如数学表达式9中表达的索引集。
[数学表达式9]
ind(i)={w(i,j)|j=0,1,...,di-1},i=0,1,...,n-k-1
这里,w(i,j)意味着第i行的第j个1存在于其中的列的位置,并且di意味着第i行的度数。
为了帮助理解,参考图5在下面的数学表达式10中表达数学表达式9的简单示例。
[数学表达式10]
ind(6)={w(6,0)=0,w(6,1)=1,w(6,2)=13,w(6,3)=16,w(6,4)=23,w(6,5)=38}
ind(10)={w(10,0)=0,w(10,1)=1,w(10,2)=3,w(10,3)=29,w(10,4)=33,w(10,5)=37,,w(10,6)=42}
数学表达式9中表达的索引集可以被划分为满足下面的数学表达式11的q1个部分集合,而不具有公共元(l=1,2,...,p)。
[数学表达式11]
r(i,j)={x|x∈ind(i)∩sj},
i=0,1,...,n-k-1,j=0,1,...,ql-1
这里,sj和ind(i)是分别在数学表达式7和9中定义的集合。
应注意,在数学表达式7中,为了便于解释,各个集合sj具有几乎相同数量的元,并且基于取模操作(modulooperation)而简单地划分。然而,一般而言,元数量是否彼此有很大差异以及元是否在更复杂的条件下被划分并不重要。然而,不同的集合sj应该是不相交的而不具有公共的元。
在本公开的实施例中,如果在数学表达式11中定义的集合r(i,j)满足下面的数学表达式12的条件,则称数学表达式9中表达的基矩阵的权重分布是完美平衡的。
[数学表达式12]
在数学表达式9中定义的索引集始终满足以下
对于j1≠j2,(0≤j1,j2<ql).||r(i,j1)|-|r(i,j2)||≤1,
i=0,1,...,n-k-1
在满足数学表达式12中表达的条件的基矩阵中,可以知道在q1个块并行处理器当中的第j个处理器针对被包括在r(i,j)中的位置中的循环置换矩阵连续执行ldpc解码的情况下,空闲时间被最小化。
然而,难以设计满足数学表达式12中表达的条件的基矩阵。这是因为在设计良好的基矩阵时,基矩阵或奇偶校验矩阵的每一行和每一列中的1的数量的分布和tanner图上的循环特性作为重要因素发挥影响。例如,很难设计同时满足良好的权重分布、良好的循环特性和数学表达式12中表达的条件的基矩阵。
由于上述原因,针对在数学表达式12中定义的关于索引集的条件,称满足下面的数学表达式13中表达的稍微宽松的条件的基矩阵的权重分布是弱平衡的。
[数学表达式13]
在数学表达式9中定义的索引集始终满足以下
对于j1≠j2,(0≤j1,j2<ql).
||r(i,j1)|-|r(i,j2)||≤2,i=0,1,...,n-k-1,
即使在满足数学表达式13中的条件的基矩阵的权重分布是弱平衡的情况下,当使用多个处理器执行ldpc解码时,空闲时间也被大大减少。然而,明显的是,与完美平衡的情况相比,这种情况是低效的。然而,在这种情况下,由于宽松的条件,基于ldpc码的编码性能来设计良好的奇偶校验矩阵的基矩阵变得容易。
提出了一种方法,其中同时到考虑完美平衡情况和弱平衡情况而设计良好的基矩阵稍微简单,并且在使用多个处理器的ldpc解码期间,空闲时间可以被大大减少。
首先,将在下面的数学表达式13中新定义在数学表达式9中定义的索引集。
[数学表达式14]
ind(i)={w(i,j)|j=0,1,...,di-1},i=0,1,...,n-k-1.
这里,w(i,j)意味着列的位置,其中第i行的第j个1存在,排除度数为1的列,并且di意味着第i行的度数,排除度数为1的列中的元。
在本公开的实施例中,如果根据在数学表达式14中定义的索引集的在数学表达式11中定义的集合r(i,j)满足下面的数学表达式15的条件,则称数学表达式9中表达的基矩阵的权重分布是强平衡的。
[数学表达式15]
在数学表达式14中定义的索引集始终满足以下
对于j1≠j2,(0≤j1,j2<ql).
||r(i,j1)|-|r(i,j2)||≤2,i=0,1,...,n-k-1
在数学表达式15中,考虑度数为1的列被排除在数学表达式14之外。这是因为与其他列相比,容易将度数为1的列自由地分配给块并行处理器。现在将在下面描述在数学表达式15中表达的强平衡的特征。
基本上,在数学表达式15中表达的强平衡具有与可以如在数学表达式13中表达的弱平衡类似的特性。然而,在将基矩阵的各个行的元1分类为两个或更多个集合或组时排除与度数为1的列相对应的元1这点上,强平衡大大不同于弱平衡。换句话说,强平衡意味着根据预定规则将来自每一行除了与度数为1的列相对应的元1之外的剩余元1最大限度统一分配给两个或更多个集合。在这种情况下,如果要分配给两个或更多个集合的元1的数量之间的差异等于或小于2,则称为实现的强平衡。此外,换句话说,在表达强平衡时,它意味着根据预定规则将来自每一行除了与度数为1的列相对应的元1之外的剩余元1最大限度统一分类为两个或更多个组。在这种情况下,如果要被包括在两个或更多个组中的元1的数量之间的差异等于或小于2,则称为实现的强平衡。换句话说,基矩阵的强平衡意味着可以根据预定规则将来自每一行除了与度数为1的列相对应的元1的剩余元1分类为两个或更多个组或集合。在这种情况下,如果要被包括在各个组或集合中的元1的数量之间的差异或者它们的索引的数量之间的差异等于或小于2,则称基矩阵满足如在数学表达式15中表达的强平衡条件。因此,在满足数学表达式15中表达的强平衡条件的情况下,通过将与度数为1的列相对应的循环置换矩阵适当地分配给处理器,强平衡具有非常接近于在数学表达式12中定义的完美平衡的特性的特性,并且因此可以大大减少处理器的空闲时间。
图7是根据本公开的实施例的初等矩阵的示图。
参考图7,为了帮助理解,作为本公开的详细实施例,将描述图7中所示的基矩阵。在图7的基矩阵中,应注意,空块意味着元为0。
图7的每一行中存在1的位置(即其中循环置换矩阵位于实际奇偶校验矩阵中的列块的位置)可以基于列块而概括为被示例性地表达如下(第一行作为第零行开始)。
...
行-6:{0,1,2,11,25,38}
行-7:{1,5,10,14,15,19,20,21,32,39}
行-8:{0,1,3,4,9,11,13,28,34,40}
行-9:{0,1,6,7,12,26,37,41}
行-10:{0,1,3,9,11,14,28,42}
行-11:{0,1,2,4,5,8,27,31,43}
…
基于使用两个块并行处理器针对具有图7的基矩阵的奇偶校验矩阵执行ldpc解码的情况,可以将在数学表达式7、11和14中定义的集合概括为在如下数学表达式16中表达。
[数学表达式16]
s0={x|x≡0(mod2),x=0,1,...45},
s1={x|x≡1(mod2),x=0,1,...,45},
…
ind(6)={0,1,2,11,25},
ind(7)={1,5,10,14,15,19,20,21,32},
ind(8)={0,1,3,4,9,11,13,28,34},
ind(9)={0,1,6,7,12,26,37},
ind(10)={0,1,3,9,11,14,28},
ind(11)={0,1,2,4,5,8,27,31,},
…
r(6,0)={0,2,38},r(6,1)={1,11,25}
r(7,0)={10,14,20,32},r(7,1)={1,5,15,19,21}
r(8,0)={0,4,28,34},r(8,1)={1,3,9,11,13}
r(9,0)={0,6,12,26},r(9,1)={1,7,37}
…
参考图7和数学表达式16,可以识别出图7的基矩阵满足数学表达式15,并且因此它是强平衡的基矩阵。因此,可以考虑,ldpc解码器通过将被包括在各个行块中的循环置换矩阵划分为与偶数列块相对应的循环置换矩阵和与奇数列块相对应的循环置换矩阵,处理如图8所示的通过两个块并行处理器的调度。
图8是根据本公开的实施例的针对具有图7的初等矩阵的奇偶校验矩阵使用两个块并行处理器执行ldpc解码的调度的示图。
图8示出了与由各个处理器以流程顺序处理的一个循环置换矩阵相对应的块的调度枚举位置的示例。例如,处理器0以第0块、第2块和第38块的顺序处理行-6,然后以第10块、第14块、第20块和第32块的顺序处理行-7。在这种情况下,可以识别出与度数为1的的列块相对应的循环置换矩阵被适当地布置在各个处理器中。例如,它对应于当处理器-0处理行-7时,处理第39列块的循环置换矩阵的情况。
参考图8,可以知道每个处理器的空闲时间已经被最小化。在实际设计基矩阵以满足数学表达式15的强平衡条件的情况下,设计几乎接近数学表达式12的完美平衡条件的基矩阵变得容易。
在图8的情况下,在设计基矩阵时,同时考虑ldpc解码器的块并行处理器的数量是2的情况和处理器的数量是4的情况。例如,针对图8的基矩阵假设4个处理器,则在数学表达式7和11中定义的集合被再次概括如下。
s0={x|x≡0(mod4),x=0,1,...45},
s1={x|x≡1(mod4),x=0,1,...,45},
s2={x|x≡2(mod4),x=0,1,...45},
s3={x|x≡3(mod4),x=0,1,...,45}
…
r(6,0)={0},r(6,1)={1,25},r(6,2)={2},r(6,3)={11}
r(7,0)={20,32},r(7,1)={1,5,21},r(7,2)={10,14},r(7,3)={15,19}
r(8,0)={0,4,28},r(8,1)={1,9,13},r(8,2)={34},r(8,3)={3,11}
r(9,0)={0,12},r(9,1)={1,37},r(9,2)={6,26},r(9,3)={7}
…
如上所述,在设计具有完美平衡、弱平衡或强平衡权重分布的基矩阵时,可以知道基矩阵的设计基础根据所考虑的块并行处理器的数量而改变。在图8的实施例中,对于使用两个块处理器的情况和使用四个块处理器的情况,同时满足强平衡条件。
如果在数学表达式7中定义了q1个集合,为了方便起见,满足数学表达式12、13和15中呈现的平衡条件的基矩阵分别表达满足完美q1-平衡、弱q1-平衡和强q1-平衡。例如,图8的基矩阵可以同时满足弱2-平衡和弱4-平衡,或者可以同时满足2-平衡和4-平衡。
如果要在ldpc解码器中使用的块并行处理器的数量不清楚,并且在同时考虑使用(q1,q2,...,qp)个处理器的情况,为了方便起见,它们被表达为完美(q1,q2,...,qp)-平衡、弱(q1,q2,...,qp)-平衡和强(q1,q2,...,qp)-平衡。
在如上所述的本公开的实施例中,为了方便起见,使用取模(modulo),基于特定规则来划分集合si,但不限于此。可以根据系统的要求适当地不规则地定义对si的划分,并且每个集合的元的数量可以不同。然而,各个集合si应该具有不同的元以保持不相交的特性。
在本公开的实施例中,作为用于设计另一ldpc码的基矩阵以在使用两个或更多个块并行处理器的情况下最小化空闲时间的方法,将描述部分窗口正交条件(partialwindowing-orthogonalcondition)。
首先,将基于图9a至图9c简要描述适合于现有公知的分层解码的基矩阵或指数矩阵的结构。作为参考,图9b和图9c是从图9a的指数矩阵划分的各个部分的放大图。图9a的各个部分对应于矩阵,其中在该矩阵中组合了与针对各个部分描述的附图标记相对应的矩阵。因此,如图9a所示的一个指数矩阵可以通过如图9b和图9c所示的部分的组合而配置。
图9a至图9c是根据本公开的各种实施例的指数矩阵的示图。
参考图9a至图9c,可以知道第6行、第7行和第8行彼此正交。这里,正交性意味着循环置换矩阵不存在于每一行中的相同列块位置中。例如,最大限度1个循环置换矩阵存在于所选择的第6行、第7行和第8行的每个列块中。以相同的方式,第9行、第10行、第11行和第12行彼此正交,并且第13行、第14行、第15行、第16行和第17行也彼此正交。然而,第12行和第13行彼此不正交(参考第3行块)。
如上所述的正交结构是适合于分层解码的结构,即,基于行并行处理器的解码。行并行处理器通常对应于用于针对整个行块执行解码的方法,并且通常具有比块并行处理器更大的大小和更高的复杂性,但是与块并行处理器相比可以执行快速解码。在基于行并行处理器的解码中,可以考虑具有正交结构的行作为一行来执行解码,并且因此非常快速的解码变得可能。例如,行并行处理器可以执行对具有正交结构的第6行块、第7行块和第8行块作为一个行块的解码。具有正交结构的行块可以被考虑为称为有效行块的一个行块。分层解码的特征在于,被包括在这样的有效行块中的多个行块彼此正交,但是有效行块之间的行块彼此不正交。例如,第12行块和第13行块被包括在不同的有效行块中,并且因此彼此不正交。
当基于块并行处理器的ldpc解码器使用两个或更多个处理器执行解码时,与上述正交结构稍微不同的结构适合于提高解码效率。
在本公开的实施例中,提出了部分窗口正交结构。首先,将简要描述窗口正交结构。
如果存在满足p个窗口正交结构的基矩阵,这意味着如果连续选择p个行块,则它们始终满足正交结构。换句话说,当选择第i个、第(i+1)个、......、(i+p-1)个行块时,p个行块始终彼此正交。具有如上所述的p个窗口正交结构的基矩阵不仅基于块并行处理器而且基于行并行处理器在ldpc解码期间提供非常高的解码效率。然而,这是针对基矩阵的非常强的限制条件,并且因此可能容易导致ldpc码的编码性能的恶化。因此,在使用如图3所示的奇偶校验矩阵结构的ldpc编码/解码系统中,针对部分矩阵[ab]部分,通常不考虑多个行块的正交结构,而是仅针对与图3的奇偶校验矩阵中的部分矩阵[de]或[de]的一部分相对应的基矩阵的部分矩阵考虑正交结构。可以容易地知道,适合于图9中呈现的分层解码的指数矩阵仅针对与图3的部分矩阵[de]相对应的部分具有正交结构。
然而,与部分矩阵[de]或其部分相对应的正交结构也可以大大约束ldpc码的度数分布,从而使ldpc编码性能恶化。为了解决该问题,针对特定的预定行块,正交结构不受限制。例如,参考图7的基矩阵,针对两个前列块,不为部分矩阵[de]考虑正交性。这可能会稍微降低解码效率,但会大大改善编码性能。如上所述,针对除了整个奇偶校验矩阵或其基矩阵中的特定行块(或行)和列块(或列)之外的剩余部分考虑正交性,并且如果当针对剩余部分选择第i、(i+1)、…、(i+p-1)个行块时,p个行块始终彼此正交,则它被称为满足p个部分窗口正交结构的奇偶校验矩阵或基矩阵。
参考图7,对于除了图7的基矩阵中的6个上行(upperrow)和两个前列之外的剩余部分矩阵,两个相邻行始终具有正交性。因此,图7意味着满足2个部分窗口正交结构的基矩阵。
总之,如果针对给定基矩阵,除了特定行和列之外的剩余部分矩阵满足p个窗口正交结构,则称基矩阵满足p个部分窗口正交结构。
在设计满足p个部分窗口正交结构的基矩阵时,在许多情况下,如图7所示,不针对与图3中的[ab]相对应的结构考虑正交性,并且仅针对与[de]相对应且排除特定列块的情况考虑部分窗口正交性,但不限于此。
结果,用于使用具有在本公开的实施例中提出的满足平衡特性和部分窗口正交结构的基矩阵的奇偶校验矩阵的ldpc编码和解码的装置和方法的特征在于,使用两个或更多个块并行处理器改善编码性能并且最大化基于ldpc解码的解码效率。
图10是示出根据本公开的实施例的发送/接收设备的配置的框图。
参考图7,kldpc比特可以为解码设备1000的ldpc编码器1010配置kldpc个ldpc信息字比特
如上面在数学表达式1中所述,用于ldpc编码的方法包括确定码字,使得ldpc码字和奇偶校验矩阵的乘积变为零向量。
参考图10,编码设备包括ldpc编码器1010,并且ldpc编码器1010可以通过基于奇偶校验矩阵或对应指数矩阵或序列针对输入比特执行ldpc编码来生成ldpc码字。在这种情况下,ldpc编码器1010可以使用根据码率(即,ldpc码的码率)而不同地定义的奇偶校验矩阵来执行ldpc编码。
常规qcldpc码包括识别要编码的输入比特的大小,确定适合于对应的输入比特的块大小z,以及基于ldpc矩阵和所确定的块大小来执行ldpc编码。解码过程包括与如上所述的过程相对应的类似过程。
另一方面,编码设备可以进一步包括用于在其中存储关于ldpc码的编码速率、码字长度和奇偶校验矩阵的信息的存储器(未示出),并且ldpc编码器1010可以使用这样的信息来执行ldpc编码。在使用本公开的实施例中提出的奇偶矩阵的情况下,关于奇偶校验矩阵的信息可以被存储为关于循环矩阵的指数值的信息。
解码设备1000可以包括ldpc解码器1020。ldpc解码器1020基于奇偶校验矩阵或对应指数矩阵或序列针对ldpc码字执行ldpc解码。
例如,ldpc解码器1020可以通过迭代解码算法传递与ldpc码字比特相对应的对数似然比(loglikelihoodratio,llr)值执行ldpc解码来生成信息字比特。
这里,llr值是与ldpc码字比特相对应的信道值,并且可以以各种方式表达。
例如,llr值可以代表通过对从发送侧通过信道发送的比特为0和1的概率比取对数而获得的值。此外,llr值可以是通过硬判决确定的比特值本身,或者可以是根据从发送侧发送的比特为0或1的概率的区段(section)而确定的代表值。
在这种情况下,发送侧可以使用ldpc编码器1010生成ldpc码字。
在这种情况下,ldpc解码器1020可以使用根据编码速率(即,ldpc码的编码速率)而不同地定义的奇偶校验矩阵来执行ldpc解码。
图11a是示出根据本公开的实施例的解码设备的结构的示图。
另一方面,如上所述,ldpc解码器1020可以使用迭代解码算法来执行ldpc解码,并且在这种情况下,ldpc解码器1020可以被配置为图11a的结构。然而,由于迭代解码算法已经是已知的,所以图11a中所示的配置也是如此。
参考图11a,解码设备1100包括输入处理器1101、存储器1102、变量节点操作器1104、控制器1106、校验节点操作器1108和输出处理器1110。
输入处理器1101在其中存储输入值。具体地,输入处理器1101可以存储通过无线电信道接收的所接收的信号的llr值。
控制器1104基于通过无线电信道接收的所接收的信号的块大小(即,码字长度)和与编码速率相对应的奇偶校验矩阵,确定输入到变量节点操作器1104的值的数量、存储器1102的地址值、输入到校验节点操作器1108的值的数量以及存储器1102的地址值。
存储器1102存储变量节点操作器1104和校验节点操作器1108的输入数据和输出数据。
变量节点操作器1104从存储器接收数据的输入,并且根据从控制器1106输入的输入数据的地址信息和关于输入数据的条数的信息执行变量节点操作。此后,变量节点操作器1104基于从控制器1106输入的输出数据的地址信息和关于输出数据的条数的信息将变量节点操作结果存储在存储器1102中。此外,变量节点操作器1104基于从输入处理器1101和存储器1102输入的数据将变量节点操作结果输入到输出处理器1110。
校验节点操作器1108从存储器1102接收数据的输入,并且基于从控制器1106输入的输入数据的地址信息和关于输入数据的条数的信息来执行校验节点操作。此后,校验节点操作器1108基于从控制器1106输入的输出数据的地址信息和关于输出数据的条数的信息将变量节点操作结果存储在存储器1102中。
输出处理器1110基于从变量节点操作器1104输入的数据,对发送侧上的码字的信息字比特是0还是1执行硬判决,然后输出硬判决结果,使得输出处理器1110的输出值变成最终解码值。
另一方面,解码设备1100可以进一步包括用于预存储关于ldpc码的编码速率、码字长度和奇偶校验矩阵的信息的存储器(未示出),并且ldpc解码器1020可以使用这样的信息来执行ldpc解码。然而,这仅仅是多样的,并且可以从发送侧提供对应信息。
另一方面,可以省略被包括在解码设备1100中的配置的部分,或者可以向其添加部分配置。此外,被包括在解码设备1100中的输入处理器、存储器、变量节点操作器、校验节点操作器和输出处理器的配置可以由控制器1106控制。
图11b是示出根据本公开的实施例的编码设备的结构的示图。
ldpc编码器1010可以被配置为具有如图11b所示的结构。
参考图11b,编码设备可以由收发器1121、控制器1122和存储器1123组成。在本公开的实施例中,控制器可以被定义为电路或专用集成电路或至少一个处理器。
收发器1121可以发送和接收信号。控制器1122可以控制根据本公开的实施例的解码设备的操作。存储器1122可以存储通过收发器1121发送/接收的信息和通过控制器1122而生成的信息中的至少一个。
图12是示出根据本公开的实施例的传输块的结构的示图。
参考图12,可以添加<null>比特以匹配ldpc码的信息长度。
根据前述内容,在支持具有各种长度的ldpc码的通信和广播系统中,已经描述了用于应用基于qc-ldpc码的各种块大小的方法。
图13a至图13i是根据本公开的各种实施例提出的满足平衡和部分窗口正交特性的基矩阵的示图。具体地,图13a的基矩阵满足强2-平衡,并且还满足2个部分窗口正交特性。
参考图13a至图13i,图13a的基矩阵的大小为90x112,并且在与5个上行和27个前列相对应的部分矩阵中,不存在度数为1的列。这意味着即使基于该部分矩阵定义了任何指数矩阵,在与指数矩阵相对应的奇偶校验矩阵中也不存在度数为1的列或列块。此外,图13b至图13i是示出图13a的基矩阵的各个部分的放大图。图13a对应于其中与在各个部分上描述的附图标记相对应的矩阵被组合的矩阵。因此,可以通过组合图13b至图13i的部分来配置一个奇偶校验矩阵(在图中,假设基矩阵被划分为2*4个分区(partition),13b、13c、…、13i)。
图13a中所示的基矩阵的特征还在于第28列至第112列的度数为1。例如,大小为85x112并且由图13a的基矩阵的第6行至第90行组成的基矩阵对应于单个奇偶校验码。
在图13a的基矩阵中,前22列对应于用于执行编码的信息比特。根据情况,信息比特也称为码块。
关于每一行中元1的位置,从图13a的基矩阵排除度数为1的列,其中奇数定位的1的数量与偶数定位的1的数量之间的差对于所有行满足等于或者小于2的值。例如,如果如数学表达式7中那样对于s1和s2定义奇数和偶数集合,并且每一行的元1被分类以匹配这些集合,则可以知道满足在数学表达式15中定义的强平衡特性。此外,可以知道,针对由5个上行和27个前列组成的部分矩阵满足在数学表达式12中定义的完美平衡特性,该部分矩阵不包括图13a的基矩阵中度数为1的列。如上所述,可以通过针对基矩阵的各个部分矩阵的不同平衡特性的组合来设计基矩阵。
发送器通过奇偶校验矩阵生成并发送码字,其中该奇偶校验矩阵具有如图13a所示的具有平衡和部分窗口正交特性的基矩阵。在这种情况下,根据需要,可以通过应用对信息比特的一部分进行打孔来发送码字。接收器基于所接收的信号对所发送的码字执行解码。在使用一个块并行处理器执行解码的情况下,针对一个循环置换矩阵或循环矩阵按顺序执行解码。在使用两个块并行处理器执行解码的情况下,针对对应于该组的循环置换矩阵或循环矩阵,可以使用两个块并行处理器同时执行解码。
图14a是根据本公开的实施例提出的具有图13a的满足平衡和部分窗口正交特性的基矩阵的指数矩阵的示图。因此,与图14a的指数矩阵相对应的奇偶校验矩阵也针对各个列块满足强2-平衡,并且还针对各个行块满足2个部分窗口正交特性。
图14a的指数矩阵的大小为90x112,并且在与5个上行和27个前列相对应的部分矩阵中,没有度数为1的列。此外,在图14的指数矩阵中,空块对应于大小为lxl的零矩阵。
此外,图14b至图14i是示出根据本公开的各种实施例的图14a的指数矩阵的各个部分的放大图。图14a对应于其中与在各个部分上描述的附图标记相对应的矩阵被组合的矩阵。因此,可以通过图14b至图14i的部分的组合来配置一个指数矩阵。在图14a中,假设基矩阵被划分为2*4个分区:14b、14c、...、14i。
图14a中所示的指数矩阵的特征还在于第28列至第112列的度数均为1。例如,大小为85x112且由图14a的指数矩阵的第6行至第90行组成的指数矩阵对应于大量单个奇偶校验码。
由于图14a的指数矩阵的每个元对应于循环置换矩阵的索引,因此块并行处理器的操作根据循环置换矩阵的大小lxl而执行。如果使用两个块并行处理器,则可以针对与定义的集合s1和s2相对应的各个循环置换矩阵执行解码。
通过针对各种l值改变元的值,图14a的指数矩阵可以用于ldpc编码和解码。
例如,如果假设图14a的指数矩阵是e=(ei,j),并且根据l值而转换的指数矩阵是
[数学表达式17]
或者
在数学表达式17中,f(x,l)可以以各种形式而定义,并且例如,可以使用如下面的数学表达式18中的定义。
[数学表达式18]
或者
或者
在数学表达式18中,mod(a,b)意味着对a的a取模b操作,并且d意味着作为预定义正整数的常数。
根据系统,可以原样使用图13a和图14a中所示的基矩阵和指数矩阵,或者可以仅使用其部分。例如,由图13a和图14a的基矩阵和指数矩阵的46个上行和68个前列组成的矩阵可以作为新基矩阵和指数矩阵用于系统中的ldpc编码和解码。在这种情况下,如果与x个信息字块相对应的信息字比特被打孔,则最高可以支持编码速率22/(68-x),而无需码字比特的迭代传输。
此外,可以使用新基矩阵来应用ldpc编码和解码,其中该新基矩阵可以通过将由图13a的基矩阵的6个上行组成的部分矩阵和与大小为40x68的单个奇偶校验码相对应的另一基矩阵彼此连接而获得。以相同的方式,可以使用新基矩阵来应用ldpc编码和解码,其中该新基矩阵通过将由图13a的基矩阵的6个上行组成的不同部分矩阵和图13a的基矩阵的相同的第7行至第46行彼此连接而获得。
通常,ldpc码可以通过根据编码速率应用码字比特的打孔来调整编码速率。在对与度数为1的列相对应的奇偶比特进行打孔的情况下,基于如图13a和14a所示的基矩阵或指数矩阵的ldpc码可以在不使用奇偶校验矩阵中的对应部分的情况下执行解码,并且因此可以降低解码复杂性。然而,在考虑编码性能的情况下,可以通过调整奇偶比特的打孔顺序(或所生成的ldpc码字的传输顺序)来改善ldpc码的性能。
例如,如果与对应于图13a和图14a的指数矩阵的两个前列相对应的信息字比特被打孔,并且度数为1的奇偶比特都被打孔,则在编码速率为22/25的情况下,可以发送ldpc码字。然而,如果与对应于图13a和图14a的指数矩阵和基矩阵的两个前列相对应的信息字比特被打孔,并且与度数为2的第26列相对应的奇偶比特被打孔,而不打孔与指数矩阵的度数为1的第28列相对应的奇偶,则可以以相同的方式以22/25的编码速率发送ldpc码字。然而,后者具有更好的性能,并且可以通过在使用与图13a和图14a相对应的基矩阵和指数矩阵生成ldpc码字之后应用适当的速率匹配来进一步改善性能。基于速率匹配,指数矩阵中列的顺序可以被适当地重新排列以应用于ldpc编码。
作为本公开的详细实施例,如果基于与图13a和图14a相对应的基矩阵和指数矩阵来应用ldpc编码和解码,则可以定义以下传输顺序。基于一基于图13a和图14a中由46个上行和68个前列组成的部分矩阵应用ldpc编码和解码的情况来导出以下图案。此外,为了方便起见,考虑第一列是第0列,并且最后一列是第67列。
图案1:
2,3,4,…,20,21,22,23-a,26,24,27,23-b,25,28,29,…,67,0,1
图案2:
2,3,4,…,20,21,22,23-a,26,27,24,23-b,25,28,29,…,67,0,1
图案1和图案2意味着以与对应于图案顺序的列相对应的码字比特的顺序进行传输。换句话说,图案1和图案2意味着以相反的顺序对码字比特应用打孔。在图案1的情况下,例如,在对用于速率匹配的码字应用打孔的情况下,从与第一列相对应的大小为z的码字比特开始,打孔按顺序被应用必要的长度(然而,在图案1和图案2中,0和1的顺序可以被改变)。
在图案1和图案2中,23-a和23-b意味着与第23列块相对应的码字比特已经被划分为两组。例如,23-a可以意味着与第23列组相对应的码字比特的前
关于传输顺序,没有必要以与列块相对应的码字比特单元的顺序来执行传输,并且为了性能改善,传输顺序可以通过将与列块相对应的码字比特划分为两个或更多个组而不同。换句话说,为了获得更优越的编码性能,可以不同地配置与至少一个列块相对应的码字比特的传输顺序。
作为参考,以与列块相对应的码字比特为单位的传输可以意味着在连续发送一个列块的码字比特的同时不发送与另一列块相对应的码字比特。
可以使用上述图案来应用这样的速率匹配方法,并且可以在针对码字比特执行适当的交织之后应用由系统用于从预定位置执行打孔的方法。例如,在lte系统中,可以使用冗余版本(redundancyversion,rv)技术。rv技术的示例将简要描述如下。
首先,图案1和图案2被分别改变为图案3和图案4。
图案3:
0,1,2,3,4,…,20,21,22,23-a,26,24,27,23-b,25,28,29,…,67
图案4:
0,1,2,3,4,…,20,21,22,23-a,26,27,24,23-b,25,28,29,…,67
如果指示传输开始位置的rv-0的值针对码字被配置为2,则可以根据编码速率配置要从第0和第1列块的码字比特采取的打孔。这里,可以根据rv-0值确定各种初始传输顺序,并且通过适当地配置rv-i值,可以将其应用于ldpc编码和解码的应用技术,诸如harq。例如,当在发送第2列至第67列块的所有码字比特之后发送附加奇偶比特时,可以循环地从第0和第1列块开始迭代发送附加码字比特,或者可以根据rv-1值以各种方法发送附加码字比特。
此外,可以根据调制顺序不同地应用图案或交织方法以改善性能。例如,如果编码速率低于特定编码速率r_th,则应用与第一图案相对应的速率匹配方法,以及如果编码速率变得高于r_th,则可以使用不同于第一图案的第二图案(如果编码速率等于r_th,则可以根据预定方法选择图案)。
如图13a和图14a所示的基矩阵和指数矩阵可以以各种形式表达,并且作为示例,它们可以使用如下面的数学表达式19和20中表达的序列而表达(为了方便起见,它们是基于一基于由图13a和图14a中的46个上行和68个前列组成的部分矩阵来应用ldpc编码和解码的情况而导出的)。
[数学表达式19]
02345679121519202223
01461011131617181920212324
01478101112131415161921222425
12356891012131415171820212526
0123578911141617182226
012227
01411212228
17131416181929
0123591030
0141112152231
017816202132
0125171933
0469112234
1714162135
0123192436
04591137
0171416222338
12181939
045112540
01892141
017142642
13161943
01251544
049111345
17101446
012192247
01162048
06111749
027950
0114192451
01101352
142553
05161754
0172355
0181856
0111192657
0191558
05162359
171260
0162561
03141962
0112463
01202164
09162665
1101366
05867
[数学表达式20]
19425921609824492481781074024510
019211822914215716429235831112924000
39140178227633124230731795712616145000
1851861181712402032511482051622331872551014610400
1492221691771611722214724721411513410
10629130
1952191011261221810
61185146248148402350
233133220174151261730
8220857148211149820
4219216757947410
57445476640
422035328103200
8313735780
2352511201211191120
861994891830
50254126250188591770
232123741720
701872491451300
18520200172280
601252362551090
1549529150
1351982281561990
1416217176130
9654441120
8498164190
2480249740
57245163900
68772092030
5543205141130
1531272302500
23682740
140129251680
87291231390
67170771610
2282331232172260
951552331580
802331211380
1982402270
17510423320
28191132180
751241340
6972531250
1861921450
1832182310
9591960
数学表达式19指示图13a的基矩阵中大小为46x68的部分矩阵中的每一行的元1的位置。例如,在数学表达式19中,第三个序列的第三个值5意味着元1存在于基矩阵的第三行和第五列中(在上述示例中,考虑序列和元的开始顺序从0开始)。
数学表达式20指示图14a的基矩阵中大小为46x68的部分矩阵中的每一行的各个元值。例如,在数学表达式20中,第三个序列的第三个值171意味着指数矩阵中的第三行中的第三个元值是171,并且基于图13a和数学表达式19,第三个值意味着与奇偶校验矩阵中的第三行块和第五列块相对应的循环置换矩阵的索引是171。
如果基矩阵和指数矩阵的部分具有特定规则,则可以更简单地表达基矩阵和指数矩阵。例如,如果第27列块至最后列块具有对角线结构,诸如图13a和图14a的基矩阵和指数矩阵,则假设省略了元位置和索引值,但是对应规则是已知的。
作为示例,下面的数学表达式21示出了在第27列块至最后列块中省略元1的位置的示例。
[数学表达式21]
02345679121519202223
01461011131617181920212324
01478101112131415161921222425
12356891012131415171820212526
0123578911141617182226
0122
014112122
171314161819
01235910
01411121522
0178162021
01251719
04691122
17141621
01231924
045911
01714162223
121819
0451125
018921
0171426
131619
012515
0491113
171014
0121922
011620
061117
0279
01141924
011013
1425
051617
01723
01818
01111926
01915
051623
1712
01625
031419
01124
012021
091626
11013
058
如上所述,可以以各种方法表达图13a和图14a的基矩阵和指数矩阵。
在图15a至图15c中示出了在本公开的实施例中提出的满足平衡和部分窗口正交特性的基矩阵的另一实施例。
图15a至图15c是示出大小为20x47的基矩阵的示图。
参考图15a至图15c,在图15a至图15c的基矩阵中,空块通常意味着0,并且指示与根据本公开的各种实施例的奇偶校验矩阵中大小为zxz的零矩阵相对应的部分。
此外,图15b至图15c是示出图15a的基矩阵的各个部分的放大图。图15a对应于其中与在各个部分上描述的附图标记相对应的矩阵被组合矩阵。因此,可以通过图15b和图15c的部分的组合来配置一个基矩阵。
可以容易地识别出图15a的基矩阵具有强2-平衡特性和2个部分窗口正交结构。此外,第28列至第47列的度数均为1。换句话说,与图15的第28列至第47列相对应的所有列在可以从图15a的基矩阵通过应用提升(lift)而生成的奇偶校验矩阵中的度数为1。
在图16a至图16e中示出了用于ldpc编码和解码的基矩阵的另一实施例,其中该ldpc编码和解码支持基于在本公开的实施例中提出的满足平衡和部分窗口正交特性的基矩阵的各种编码速率和编码长度。图16a至图16e是示出大小为25x47的基矩阵的示图。在图16a至图16e的基矩阵中,空块通常意味着0,并且指示与奇偶校验矩阵中大小为zxz的零矩阵相对应的部分。
图16a至图16e是根据本公开的各种实施例的其他初等矩阵的示图。
参考图16a至图16e,图16b至图16e是示出图16a的基矩阵的各个部分的放大图。图16a对应于其中与在各个部分上描述的附图标记相对应的矩阵被组合的矩阵。因此,可以通过图16b至图16e的部分的组合来配置一个基矩阵。作为参考,图15b等于图16d,并且图15c等于图16e。
图16a中所示的基矩阵可以以各种形式而表达,并且作为示例,它可以使用如下面的数学表达式22中的序列而表达。数学表达式22指示图16a的基矩阵中的每一行的元1的位置。例如,在数学表达式22中,第二个序列的第二个值4意味着元1存在于基矩阵的第二行和第四列中(在上述示例中,考虑序列和矩阵中的元的开始顺序从0开始)。
[数学表达式22]
0123569101112131516181920212223
023457891112141516171921222324
01245678910131415171819202425
0134678101112131416171820212225
0126
0131216212227
0610111317182028
014781429
01312161921222430
0110111317182031
124781432
01121621222333
011011131834
037202335
0121516172136
011013182537
1311202238
01416172139
11213181940
01781041
039112242
1516202143
012131744
12101845
034112246
如果可以针对基矩阵的部分找到特定规则,则可以更简单地表达基矩阵。例如,如果第27列到最后列具有对角线结构,诸如图16a的基矩阵,则假设收发器知道对应规则,并且可以省略元位置或元值。作为示例,下面的数学表达式23示出了其中在数学表达式22中的第27列块至最后列块中省略元1的位置的示例。
[数学表达式23]
0123569101112131516181920212223
023457891112141516171921222324
01245678910131415171819202425
0134678101112131416171820212225
01
01312162122
06101113171820
0147814
013121619212224
01101113171820
1247814
011216212223
0110111318
0372023
01215161721
0110131825
13112022
014161721
112131819
017810
0391122
15162021
0121317
121018
0341122
数学表达式24指示图16a的基矩阵中的每一列的元1的位置。例如,在数学表达式24中,第三个序列的第三个值5意味着元1存在于基矩阵的第三行和第五列中(在上述示例中,考虑序列和矩阵中的元的开始顺序从0开始)。
[数学表达式24]
012345678911121314151719202224
02345789101112151618192123
0121023
0135813162024
12371024
01221
0236
1237101319
12371019
01220
0236912151923
0136912162024
0135811141822
0236912151822
12371017
01214
0135811141721
12369141722
0236912151823
012818
02369131621
0135811141721
0135811162024
011113
128
2315
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
如果可以针对基矩阵的部分找到特定规则,则可以更简单地表达基矩阵。例如,如果第27列到最后列具有对角线结构,诸如图16a的基矩阵,则假设收发器知道对应规则,并且可以省略元位置或元值。作为示例,下面的数学表达式25示出了其中在数学表达式24中的第27列块至最后列块中省略元1的位置的示例。
[数学表达式25]
012345678911121314151719202224
02345789101112151618192123
0121023
0135813162024
12371024
01221
0236
1237101319
12371019
01220
0236912151923
0136912162024
0135811141822
0236912151822
12371017
01214
0135811141721
12369141722
0236912151823
012818
02369131621
0135811141721
0135811162024
011113
128
2315
如上所述,基矩阵和指数矩阵可以以各种方法而表达。如果针对基矩阵应用列或行的置换,通过适当改变数学表达式19至25中的序列或序列中数字的位置,可以相等地表达基矩阵和指数矩阵。
在图16a的基矩阵中,由图16b和图16c中的部分组成的部分矩阵可能不满足在本公开的实施例中提出的平衡特性或部分窗口正交特性。然而,通过将由图16b和图16c中的部分组成的部分矩阵和由图16d和图16e中的部分组成的部分矩阵彼此连接,变得可以以更优越的性能支持用于支持各种编码速率和编码长度的ldpc编码和解码的装置和方法。
作为参考,通过针对可以基于图16a的基矩阵而生成的ldpc码适当地缩短和打孔信息字比特的部分,变得可以支持具有各种编码速率和各种长度的ldpc编码和解码。例如,如果假设与图16a的基矩阵的两个初始列相对应的信息字比特始终被打孔且仅不包括与图16b相对应的奇偶比特的比特被打孔,则显然从编码速率22/25到22/45的各种编码速率可以从图16a的基矩阵得到支持。
ldpc码可以通过根据编码速率应用码字比特的打孔来调整编码速率。在对与度数为1的列相对应的奇偶比特进行打孔的情况下,基于本公开的实施例提出的基矩阵或指数矩阵的ldpc码可以在不使用奇偶校验矩阵中的对应部分的情况下执行解码,并且因此可以减少解码复杂性。然而,在考虑编码性能的情况下,可以通过调整奇偶比特的打孔顺序或所生成的ldpc码字的传输顺序来改善ldpc码的性能。
通常,可以通过在使用本公开的实施例中提出的基矩阵或指数矩阵生成ldpc码字之后应用适当的速率匹配来进一步改善性能。基于速率匹配,基矩阵或指数矩阵中的列的顺序可以被适当地重新排列以应用于ldpc编码和解码。
ldpc编码过程可以包括确定用于应用ldpc编码的输入比特(或编码块)的大小,根据该大小确定用于应用ldpc编码的块大小z,根据块大小确定适当的ldpc指数矩阵或序列,以及基于块大小z、所确定的指数矩阵或ldpc序列执行ldpc编码。在这种情况下,ldpc指数矩阵或序列可以在没有任何转换的情况下应用于ldpc编码,并且根据情况,可以通过根据块大小z适当地转换ldpc指数矩阵或序列来执行ldpc编码。
以相同的方式,ldpc解码过程可以包括确定用于所发送的ldpc码字的输入比特(或码块)的大小,根据该大小确定用于应用ldpc解码的块大小z,根据块大小确定适当的ldpc指数矩阵或序列,以及基于块大小z、所确定的指数矩阵或ldpc序列执行ldpc解码。在这种情况下,ldpc指数矩阵或序列可以在没有任何转换的情况下应用于ldpc解码,并且根据情况,可以通过根据块大小z适当地转换ldpc指数矩阵或序列来执行ldpc解码。
这里,ldpc指数矩阵或序列的基矩阵的特征可以在于是图15a、图16a或下文将描述的图17a的基矩阵。
在图17a至图17j中示出了用于ldpc编码和解码的基矩阵的另一实施例,其中该ldpc编码和解码支持基于在本公开的实施例中提出的满足平衡和部分窗口正交特性的基矩阵的各种编码速率和编码长度。
图17a至图17j是根据本公开的各种实施例的其他初等矩阵的示图。
参考图17a至图17j,图17a是示出大小为46x68的基矩阵的示图。在图17a至图17j的基矩阵中,空块通常意味着0,并且指示与奇偶校验矩阵中大小为zxz的零矩阵相对应的部分。
此外,图17b至图17j是示出图17a的基矩阵的各个部分的放大图。图17a对应于其中与在各个部分上描述的附图标记相对应的矩阵被组合的矩阵。因此,可以通过图17b至图17j的部分的组合来配置一个基矩阵。作为参考,图16b和图17b彼此相等,图16c和图17d彼此相等,图15b、图16d和图17d彼此相等,并且图15c、图16e和图17e彼此相等。
通常,如果图17f、图17g和图17i中的部分被配置为零矩阵,并且图17j中的部分被配置为单位矩阵或具有对角结构的矩阵,则整个基矩阵结构具有扩展形式,而没有大大不同于图16a至图16e的基矩阵,并且因此便于码连接。
此外,如果图17h的每一行具有正交特性,则易于实施支持高解码吞吐量的解码器。
结果,使用图17h的基矩阵,图17a至图17j的基矩阵可以支持与图16a的基矩阵相比更多不同的编码速率,其中图17h的基矩阵中每一行具有正交特性,同时相对于图16a至图16e的基矩阵保持扩展形式。
尽管图16a和图17a仅示出了原样使用图15a的基矩阵的情况,但通常重新排列图15a的基矩阵的列的顺序,重新排列行的顺序,或者重新排列列和行的顺序。此外,通过将重新排列的基矩阵连接到图16b和图16c的基矩阵,可以将以如图16a所示形式的新基矩阵用于ldpc编码和解码方法以及装置。例如,通过将重新排列的基矩阵应用于图16d和图16e的基矩阵,可以生成与图16a的形式类似的新基矩阵。
以相同的方式,通过将重新排列的基矩阵连接到图17b和图17c的基矩阵,可以将以如图17a所示形式的新基矩阵用于ldpc编码和解码方法以及装置。例如,通过将重新排列的基矩阵应用于图17d和图17e的基矩阵,可以生成与图17a的形式类似的新基矩阵。
尽管图17a仅示出了原样使用图16a的基矩阵的情况,但通常重新排列图16a的基矩阵的列的顺序,重新排列行的顺序,或者重新排列列和行的顺序。此外,通过将重新排列的基矩阵应用于图17b、图17c、图17d和图17e的基矩阵,可以将与图17a的形式类似的新基矩阵应用于ldpc编码和解码方法以及装置。如上所述,通过将图16a的基矩阵应用于图17a的基矩阵,通过数学表达式26中表达的ldpc序列呈现基矩阵的示例。
数学表达式26指示基矩阵中的每一行的元1的位置,并且如图17a所示,它可以以ldpc基矩阵的形式而表达。作为与数学表达式26相对应的基矩阵,图17f、图17g和图17i中的部分被配置为零矩阵,并且图17j中的部分被配置为单位矩阵。图17h示出了其中每一行具有正交特性的基矩阵的示例。此外,数学表达式26中表达的基矩阵可以通过与数学表达式23至25中表达的方法类似的方法以各种形式而表达。
[数学表达式26]
0123569101112131516181920212223
023457891112141516171921222324
01245678910131415171819202425
0134678101112131416171820212225
0126
0131216212227
0610111317182028
014781429
01312161921222430
0110111317182031
124781432
01121621222333
011011131834
037202335
0121516172136
011013182537
1311202238
01416172139
11213181940
01781041
039112242
1516202143
012131744
12101845
034112246
1671447
0241548
16849
04192150
114182551
010132452
17222553
012142454
12112155
07151756
16122257
014151858
1132359
09101260
1371961
081762
1391863
042464
116182565
0792266
161067
通常,在使用ldpc码的缩短或零填充(shorteningorzeropadding)来支持可变信息字长或可变码率的情况下,可以根据缩短的顺序来改善ldpc码的性能。如果缩短的顺序是预定的,则可以通过适当地重新排列给定基矩阵的一部分或全部的顺序来改善编码性能。
如上所述的重新排列的基矩阵的示例在图18a至图18e中示出。在图18a至图18e的基矩阵中,空块通常意味着0,并且指示与奇偶校验矩阵中大小为zxz的零矩阵相对应的部分。
图18a、图18b、图18c、图18d和图18e是根据本公开的各种实施例的其他初等矩阵的示图。
参考图18a,可以容易地知道,图18a的基矩阵具有这样的结构,其中图15a的第7列和第21列的顺序(如果考虑初始列是第0列、第6列和第20列)被改变并且重新排列,然后连接到图16b和图16c的部分。
图18a的基矩阵仅仅是可以通过重新排列图15a的列而获得的基矩阵的示例,并且可以根据性能改善效果或各种目的来定义新基矩阵。此外,通过分别用图18b代替图17b,用图18c代替图17c,用图18d代替图17d,用图18e代替图17e,可以生成具有与图17a的形式类似的形式的新基矩阵。
图18a中所示的基矩阵可以以各种形式而表达,并且作为示例,它们可以使用如数学表达式27中表达的序列而表达。数学表达式27指示图18a的基矩阵中的每一行的元1的位置。
[数学表达式27]
0123569101112131516181920212223
023457891112141516171921222324
01245678910131415171819202425
0134678101112131416171820212225
0126
0131216212227
0610111317182028
014781429
01312161921222430
016101113171831
124781432
01121621222333
011011131834
03672335
0121516172136
011013182537
136112238
01416172139
11213181940
01781041
039112242
156162143
012131744
12101845
034112246
如果可以针对基矩阵的部分找到特定规则,则可以更简单地表达基矩阵。例如,如果第27列到最后列具有对角线结构,诸如图18a的基矩阵,则假设收发器知道对应规则,并且可以省略元位置或元值。作为示例,下面的数学表达式28示出了其中在数学表达式27中的第27列块至最后列块中省略元1的位置的示例。
[数学表达式28]
0123569101112131516181920212223
023457891112141516171921222324
01245678910131415171819202425
0134678101112131416171820212225
01
01312162122
06101113171820
0147814
013121619212224
0161011131718
1247814
011216212223
0110111318
036723
01215161721
0110131825
1361122
014161721
112131819
017810
0391122
1561621
0121317
121018
0341122
如上所述,基矩阵和指数矩阵可以以各种方法而表达。如果部分矩阵的列或行的置换被应用于基矩阵或基矩阵的一部分,则可以通过适当地改变在数学表达式19至28中表达的序列或序列中数字的位置来定义新基矩阵。
作为本公开的另一实施例,提出了一种用于基于图18a的基矩阵应用多个指数矩阵或ldpc序列的方法。换句话说,基矩阵如图18a所示,在基矩阵上获得指数矩阵或ldpc码的序列,并且通过应用提升来执行可变长度ldpc编码和解码,以匹配被包括在来自指数矩阵或序列的每个块大小组中的块大小。换句话说,与多个不同ldpc码的指数矩阵或序列相对应的奇偶校验矩阵的基矩阵彼此相等。根据该方法,构成ldpc码或ldpc序列的指数矩阵的元或数字可以具有不同的值,但是对应元或数字的位置准确地彼此一致。如上所述,指数矩阵或ldpc码的序列意味着循环置换矩阵的索引,即比特的一种循环置换值,并且通过将元或数字的位置配置为彼此相等,可以容易地抓取与对应循环置换矩阵相对应的比特的位置。
首先,将要支持的块大小z划分为多个块大小组(或集合),如下面的数学表达式20所表达的。应注意,块大小z是与ldpc码的奇偶校验矩阵中的循环置换矩阵或循环矩阵的大小zxz相对应的值。
[数学表达式29]
z1={3,6,12,24,48,96,192,384}
z2={11,22,44,88,176,352}
z3={5,10,20,40,80,160,320}
z4={9,18,36,72,144,288}
z5={2,4,8,16,32,64,128,256}
z6={15,30,60,120,240}
z7={7,14,28,56,112,224}
z8={13,26,52,104,208}
数学表达式29仅是各种各样的,并且可以使用被包括在数学表达式29的块大小组中的所有块大小z值,或者被包括在如下面的数学表达式30中表达的适当的部分矩阵中的块大小值。此外,可以将适当的值添加到要使用的数学表达式29或30中表达的块大小组(集合)。
[数学表达式30]
z1’={12,24,48,96,192,384}
z2’={11,22,44,88,176,352}
z3’={10,20,40,80,160,320}
z4’={9,18,36,72,144,288}
z5’={8,16,32,64,128,256}
z6’={15,30,60,120,240}
z7’={14,28,56,112,224}
z8’={13,26,52,104,208}
在数学表达式29或30中表达的块大小组的特征在于它们具有不同的粒度(particlesize)并且相邻块大小的比率都是相等的整数。换句话说,被包括在一个组中的块的大小彼此之间是除数或倍数关系。如果假设与第p(p=1,2,…,8)组相对应的指数矩阵是
[数学表达式31]
或者
在数学表达式31中表达的转换可以简单地如在下面的数学表达式32中表达。
[数学表达式32]
ep(z)=ep(modz)),z∈zp
基于数学表达式29至32设计的ldpc码的基矩阵以及指数矩阵(或ldpc序列)如图19至图26所示。作为参考,尽管已经在数学表达式17、31或32中表达的指数矩阵的提升或转换被应用于与奇偶校验矩阵相对应的整个指数矩阵的假设下进行了解释,但是它也可以被应用于指数矩阵的一部分。例如,通常与奇偶校验矩阵的奇偶比特相对应的部分矩阵具有用于有效编码的特殊结构。在这种情况下,可能由于提升而改变编码方法或复杂性。因此,为了保持相同的编码方法或复杂性,针对与奇偶校验矩阵中的奇偶相对应的部分矩阵的指数矩阵的一部分,可以不应用提升,或者可以应用对与信息字比特相对应的部分矩阵的、不同于应用于指数矩阵的提升方法的提升。换句话说,应用于指数矩阵中与信息字比特相对应的序列的提升方法和应用于与奇偶比特相对应的序列的提升方法可以被不同地配置,并且根据情况,提升不应用于与奇偶比特相对应的序列的部分或全部,并且因此可以在没有序列转换的情况下使用固定值。
在图19a和图20a中连续示出了与基于数学表达式29至32设计的qcldpc码的奇偶校验矩阵相对应的指数矩阵的实施例(应注意,在图19a和图20a的指数矩阵中,空块是与大小为zxz的零矩阵相对应的部分。根据情况,在图19a和图20a的指数矩阵中,空块可以被表达为指定值,诸如-1等。图19a和图20a所示的ldpc码的指数矩阵的特征在于具有与图18a基矩阵相同的基矩阵。
图19a和图20a示出了大小为25x47的ldpc指数矩阵,并且分别对应于数学表达式29和30中表达的第一块大小组和第二块大小组。此外,在由每个指数矩阵中的4个上行和26个前列组成的部分矩阵中,不存在度数为1的列。换句话说,在可以从部分矩阵通过应用提升而生成的奇偶校验矩阵中,不存在度数为1的列或列块。
图19a至图19e是根据本公开的各种实施例的其他指数矩阵的示图。
参考图19a至图19e,图19b至图19e是示出图19a的指数矩阵的各个部分的放大图。图19a对应于附图中与在各个部分上描述的附图标记相对应的矩阵。因此,可以通过图19b至图19e的部分的组合来配置一个基矩阵。
图20a至图20e是根据本公开的各种实施例的其他指数矩阵的示图。
参考图20a至图20e,图20a是示出在划分各个指数矩阵之后的各个部分的放大图。
图19a和图20a中所示的指数矩阵的特征还在于第28列至第47列的度数均为1。例如,大小为21x47并且由指数矩阵的第5行至第25行组成的基矩阵或指数矩阵对应于大量单个奇偶校验码。
图19a和图20a中所示的指数矩阵对应于基于在数学表达式29或30中定义的块大小组而设计的ldpc码。然而,根据系统要求,没有必要支持被包括在块大小组中的所有块大小,并且根据情况,除了图19和图20所示的块大小之外,还可以添加其他值。例如,图19和图20中所示的指数矩阵不仅可以支持与在数学表达式29或30中定义的块大小组(集合)相对应的块大小,还可以支持与各个组(集合)的子集相对应的块大小,并且根据情况,可以支持其他值。
此外,根据系统,可以原样使用图10a和图20a中所示的指数矩阵,或者可以仅使用其一部分。例如,排除了由图19a和图20a的各个指数矩阵的5个上行和27个前列组成的大小为5x27的部分矩阵,并且不同于部分矩阵的大小为5x27的ldpc指数矩阵和由图19a和20a的各个指数矩阵的第6行到最后行组成的大小为20x47的部分矩阵被相互连接,以用于基于新基矩阵的ldpc编码和解码装置以及方法。
由于图19a和图20a的ldpc指数矩阵具有与图18a相同的基矩阵,因此它们可以应用于并用于与图17a的形式类似的新基矩阵,该新基矩阵可以通过分别用图18b代替图17b、用图18c代替图17c、用图18d代替图17d和用图18e代替图17e而获得。例如,通过使图19a和图20a的指数矩阵对应于与图17b、图17c、图17d和图17e相对应的部分矩阵,并使适当的指数矩阵对应于图17f、图17g、图17h、图17i和图17j,新ldpc指数矩阵被定义用于ldpc编码和解码装置以及方法。在这种情况下,所有ldpc索引矩阵都具有图17a的基矩阵,并且基矩阵中与图17b、图17c、图17d和图17e相对应的部分矩阵变得等于图18a的那些矩阵。
通常,可以通过应用通过从图15a、图16a、图17a和图18a的基矩阵适当选择行和列而配置的部分矩阵作为新基矩阵来执行ldpc编码和解码。以相同的方式,通过从图19a和图20a的指数矩阵适当选择行和列而配置的部分矩阵可以作为基矩阵应用于ldpc编码和解码装置以及方法。
图21a至图21j是根据本公开的各种实施例的其他初等矩阵的示图。
参考图21a至图21j,基于数学表达式29至32设计的ldpc码的基矩阵和指数矩阵(或ldpc序列)的另一实施例在图21a、图22a和图23a中示出。该实施例提出了一种基于图21a的基矩阵应用多个指数矩阵或ldpc序列的方法。换句话说,基矩阵如图21a所示,在基矩阵上获得指数矩阵或ldpc码的序列,并且通过应用提升来执行可变长度ldpc编码和解码,以匹配被包括在来自指数矩阵或序列的每个块大小组中的块大小。换句话说,与多个不同ldpc码的指数矩阵或序列相对应的奇偶校验矩阵的基矩阵彼此相等。根据该方法,构成ldpc码或ldpc序列的指数矩阵的元或数字可以具有不同的值,但是对应元或数字的位置准确地彼此一致。如上所述,指数矩阵或ldpc码的序列意味着循环置换矩阵的索引,即比特的一种循环置换值,并且通过将元或数字的位置配置为彼此相等,可以容易地抓取与对应循环置换矩阵相对应的比特的位置。
图22a至图22j是根据本公开的各种实施例的其他指数矩阵的示图。
参考图22a至图22j,在图22a和图23a中连续示出了与基于数学表达式29至32设计的qcldpc码的奇偶校验矩阵相对应的指数矩阵的实施例(应注意,在图22a和图23a的指数矩阵中,空块是与大小为zxz的零矩阵相对应的部分。根据情况,在图22a和图23a的指数矩阵中,空块可以被表达为指定值,诸如-1等。图22a和图23a所示的ldpc码的指数矩阵的特征在于具有与图21a基矩阵相同的基矩阵。
图22a和图23a示出了大小为46x68的ldpc指数矩阵,并且分别对应于在数学表达式29和30中表达的第五块大小组和第六块大小组。此外,图22b至图22j是示出图22a的指数矩阵的各个部分的放大图。图22a对应于附图中与在各个部件上描述的附图标记相对应的矩阵。因此,可以通过图22b至图22j中的部分的组合来配置一个基矩阵。
图23a至图23j是根据本公开的各种实施例的其他指数矩阵的示图。
参考图23a至图23j,图23a是示出在划分各个指数矩阵之后的各个部分的放大图。作为参考,图23e等于图22e,图23h等于图22h,图23f等于图22f。此外,图23i等于图22i,图23g等于图22,图23j等于图22j。
图22a和图23a中所示的指数矩阵对应于基于在数学表达式29或30中定义的块大小组而设计的ldpc码。然而,根据系统要求,没有必要支持被包括在块大小组中的所有块大小,并且根据情况,除了数学表达式29或30中表达的块大小之外,还可以添加其他值。
例如,图22a和图23a中所示的指数矩阵不仅可以支持与在数学表达式29或30中定义的块大小组(集合)相对应的块大小,还可以支持与各个组(集合)的子集相对应的块大小,并且根据情况,可以支持其他值。
此外,根据系统,可以原样使用图22a和图23a中所示的指数矩阵,或者可以仅使用其一部分。例如,通过使图22a和图23a的基矩阵或除21个下行和21个后列之外的剩余部分矩阵对应于图17b、17c、17d和17e,并使另一个矩阵或ldpc序列对应于图17f、17g、17h、17i和17j,ldpc编码和解码装置以及方法可以通过与图17的形式类似的基矩阵或者指数矩阵而使用。
通常,可以通过应用通过从图21a的基矩阵适当地选择行和列而配置的部分矩阵作为新基矩阵或指数矩阵来执行ldpc编码和解码。以相同的方式,通过从图22a和图23a的指数矩阵适当地选择行块和列块而配置的部分矩阵可以作为新的指数矩阵应用于ldpc编码和解码装置以及方法。
作为参考,被表达为数学表达式26中的序列的用于ldpc编码和解码的基矩阵可以如在数学表达式33或34中被表达。
数学表达式33意味着,如果假设省略了元的位置或它们的索引值,但是在第27列块至最后列块(诸如基矩阵)具有对角结构的情况下对应规则是已知的,则可以使用ldpc序列。作为示例,数学表达式33示出了其中在第27列块至最后列块中省略元1的位置的示例。
[数学表达式33]
0123569101112131516181920212223
023457891112141516171921222324
01245678910131415171819202425
0134678101112131416171820212225
01
01312162122
06101113171820
0147814
013121619212224
01101113171820
1247814
011216212223
0110111318
0372023
01215161721
0110131825
13112022
014161721
112131819
017810
0391122
15162021
0121317
121018
0341122
16714
02415
168
041921
1141825
0101324
172225
0121424
121121
071517
161222
0141518
11323
091012
13719
0817
13918
0424
1161825
07922
1610
数学表达式34指示在数学表达式26中表达的基矩阵的元1的位置。为了方便起见,数学表达式34是这样的示例,其中在第27列块至最后列块中省略元1的位置,并且从第28列开始,可以以4,5,6,...的顺序添加并表达一个序列。
[数学表达式34]
01234567891112131415171920222426283032343638404244
023457891011121516181921232527293133353739414345
01210232633
01358131620243941
12371024262842
01221
023625273545
12371013192531343944
123710192740
01220384144
0236912151923303845
013691216202433
0135811141822323538
02369121518223037
1237101725293236
01214263436
013581114172143
123691417223440
023691215182329364143
0128182839
02369131621
01358111417212833
0135811162024313544
01111337
128303242
2315293143
图24a至图24j是根据本公开的各种实施例的其他初等矩阵的示图。
参考图24a至图24j,被表达为数学表达式26中的序列的用于ldpc编码和解码的基矩阵可以如图24a所示。图24的矩阵示出了大小为46x68的基矩阵。此外,图24b至图24j是示出图24的指数矩阵的各个部分的放大图。图24a对应于附图中与在各个部分上描述的附图标记相对应的矩阵被组合。因此,可以通过图24b至图24j中的部分的组合来配置一个基矩阵。作为参考,图24e、图24h、图24f、图24i、图24g和图24j等于图21e、图21h、图21f、图21i、图21g和图21j,因此它们在图24a中被省略。
虽然已经参考本公开的各种实施例示出和描述了本公开,但是本领域技术人员将理解,在不脱离由所附权利要求及其等同物限定的本公开的精神和范围的情况下,可以在其中进行形式和细节上的各种改变。
- 还没有人留言评论。精彩留言会获得点赞!
- 一种广播网络复用协议的转换方法及系统与制造工艺
- 一种基于EM算法的LDPC码译码噪声方差的估计方法与制造工艺
- 一种校验码穿孔和解穿孔方法及装置与制造工艺
- 一种针对Turbo乘积码的修正的软入软出译码方法与制造工艺
- 一种低复杂度的(47,24,11)平方剩余码译码方法与制造工艺
- 一种基于串行抵消列表极化码译码的动态分布排序算法的制造方法与工艺
- 基于k段分解的低复杂度极化码折叠硬件构架的实现方法与制造工艺
- 基于极化码的自适应连续消除译码方法及架构与制造工艺
- 一种基于Hoey序列的非规则Type‑II QC‑LDPC码构造方法与制造工艺
- 一种基于完备循环差集的可快速编码的Type‑II QC‑LDPC码构造方法与制造工艺