虚拟声场产生装置和虚拟声场产生方法与流程
本公开一般涉及声场技术领域,具体涉及虚拟声场产生装置及虚拟声场产生方法。
背景技术:
随着娱乐视听技术的发展,在视听娱乐活动中,越来越面对多样化的需求。例如,当在观看电视节目的时候,同一空间中有他人从事其他活动,例如休息睡眠。这时声音太大会影响他人活动,声音小自己体验不佳或听不清楚。虽然佩戴耳机能够避免对他人活动的干扰,但耳机对头部和耳造成压力,体验不佳。
另外,尽管电视能够实现多画面播放,如果多人同时看电视,又希望看不同的频道,现有技术通过画面分割可以实现不同的人看不同的画面,但同时进行声音分割却很困难。这种情况下,虽然理论上通过每人佩戴一个耳机可以实现声音分离,但多个耳机连接的不便及连接线的线长限制,都使得该收听的娱乐体验下降。
再者,在进行体感游戏活动时,游戏创建的虚拟声场充满整个房间,由于声场分散而使得体验效果下降。
技术实现要素:
鉴于现有技术中的上述缺陷或不足,期望提供一种技术方案,克服上述缺陷或不足。
在本发明的第一方面,提供一种一种虚拟声场产生装置,包括:
音源输入装置,用于从外部接收媒体声音;
定位系统,用于定位空间内用户人脸的位置、扬声器阵列的位置,并计算和校准所述空间的声学模型;
声场控制器,用于基于所述空间的声学模型和特定的声场模式控制所述媒体声音;
声场输出装置,用于与所述扬声器阵列连接,将经所述声场控制器控制的媒体声音输出到所述扬声器阵列。
优选地,所述定位系统包括摄像头和麦克风阵列,所述麦克风阵列用于接收所述扬声器阵列发出的校准信号确定所述空间的声学模型,所述摄像头基于所述用户、所述扬声器阵列及所述麦克风阵列的图像以及所述空间的声学模型,确定所述用户的人脸位置和扬声器阵列的位置。
优选地,所述声场模式包括全景模式、独享模式或综合模式;其中,在所述全景模式下,所述扬声器阵列作为多声道音响操作,所述声场控制器控制所述扬声器阵列建立充满整个所述空间的声场,以房间中心为声场中心;在独享模式下,所述声场控制器控制所述扬声器阵列建立以所述空间内的每个用户为中心的声场,为每个用户建立的声场之间彼此互不干扰;在综合模式下,所述声场控制器控制所述扬声器阵列建立以所述空间内的一个用户为中心的多维度声场供用户选择使用。
优选地,所述虚拟声场产生装置还包括声场模式输入端子,用于输入所述用户选择的声场模式或者根据播放的媒体声音内容自动确定的声场模式。
进一步地,所述虚拟声场产生装置的特定的声场模式缺省配置为全景模式。
优选地,所述空间的声学模型随所述用户的位置更新而被更新。
可选地,上述任一虚拟声场产生装置还包括扬声器阵列,用于与所述声场输出装置连接播放所述媒体声音。
在本发明的第二方面,还提供一种虚拟声场产生方法,包括:
从外部接收媒体声音;
定位空间内用户的人脸位置、扬声器阵列位置,并计算和校准所述空间的声学模型;
基于所述空间的声学模型和特定的声场模式控制所述媒体声音;
输出经控制的所述媒体声音。
优选地,所述方法进一步包括:确定所述空间的声学模型,基于所述空间的声学模型以及所述用户、所述扬声器阵列及所述麦克风阵列的图像确定所述用户的人脸位置和扬声器阵列位置。
优选地,所述方法进一步包括:所述声场模式包括全景模式、独享模式或综合模式;其中,在所述全景模式下,所述扬声器阵列作为多声道音响操作,所述声场控制器控制所述扬声器阵列建立充满整个所述空间的声场,以房间中心为声场中心;在独享模式下,所述声场控制器控制所述扬声器阵列建立以所述空间内的每个用户为中心的声场,为每个用户建立的声场之间彼此互不干扰;在综合模式下,所述声场控制器控制所述扬声器阵列建立以所述空间内的一个用户为中心的多维度声场供用户选择使用。
优选地,所述方法进一步包括:其中,其中,所述特定的声场模式由所述用户输入或者根据播放的媒体声音内容自动确定。
优选地,所述方法进一步包括:所述特定的声场模式缺省配置为全景模式。
优选地,所述方法进一步包括:所述空间的声学模型随所述用户的位置更新而被更新。
通过根据本发明实施例的虚拟声场产生装置和虚拟声场产生方法,能够产生自动跟随空间内用户位置的多种虚拟声场,由用户选择使用。并且用户无需佩戴耳机等头戴式设备而被声场自动跟随,实现自由跟听。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显:
图1示出根据本发明一个实施例的虚拟声场产生装置的应用环境的图;
图2示出根据本发明一个实施例的虚拟声场产生装置的组成框图;
图3示出根据本发明上述实施例的虚拟声场产生装置在全景模式下操作的示意图;
图4示出根据本发明上述实施例的虚拟声场产生装置在独享模式下操作的示意图;
图5示出根据本发明上述实施例的虚拟声场产生装置在综合模式下操作的示意图。
图6示出根据本发明上述实施例的虚拟声场产生装置进行校准操作的示意图;
图7示出根据本发明上述实施例的虚拟声场产生方法的流程图。
具体实施方式
下面结合附图和实施例对本申请作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与发明相关的部分。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
请参考图1,图1示出根据本发明一个实施例的虚拟声场产生装置的应用环境的图。空间100中设置有根据本发明实施例的虚拟声场产生装置1,空间可以是房间,客厅或者特定场所。图1中示出其包含的用于定位的两个麦克风组成的麦克风阵列6和一个摄像头5,虚拟声场产生装置的组成未完全示出。组成麦克风阵列的麦克风6和摄像头5的数量可以分别不限于两个或一个。设置在虚拟声场产生装置两侧的是扬声器阵列,包括左侧阵列SPL1、SPL2。。。SPLN和右侧阵列SPL1、SPL2。。。SPLN。N可以为正整数。
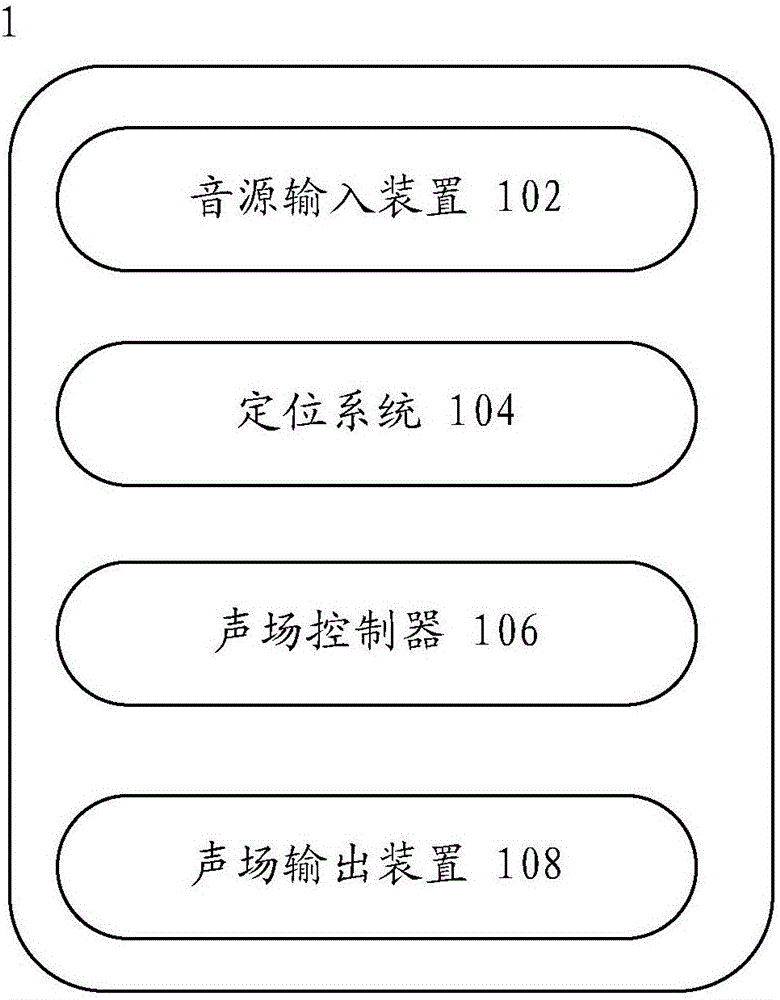
图2示出该虚拟声场产生装置1的组成框图。其包括音源输入装置102、定位系统104、声场控制器106以及声场输出装置108。各个部分组成如下:
---音源输入装置102,其可以采用现有的各种连接方式与外部音源连接,用于输入想要播放的外部媒体声音,包括有线或无线连接方式,例如音频连接线或WiFi。媒体声音例如来自电视机、影碟机或网络音频。
---定位系统104,用于定位空间内用户的人脸和外部扬声器阵列的位置,从而计算和校准该空间的声学模型。这里的声学模型包括在当前空间设置环境下校准声音从扬声器阵列中的每个扬声器传播到达每个麦克风阵列6的空间传递函数组成的空间传递函数矩阵,以及校准声音从扬声器阵列中的每个扬声器传播到达用户脸部的空间传递函数矩阵。空间内有多个用户时,定位系统104确定每个用户的人脸位置以及校准声音从扬声器阵列中的每个扬声器传播到达每个用户头部的空间传递函数矩阵。
---声场控制器106,用于基于空间的上述声学模型和一定的声场模式控制所述音源的输出。
---声场输出装置108,与外部的扬声器阵列连接,用于将经控制的音源输出到外部的扬声器阵列产生虚拟声场,其也可以采用有线或无线连接方式。
通过根据上述实施例的虚拟声场产生装置,能够产生自动跟随空间内用户位置的多种虚拟声场,由用户选择使用。并且用户无需佩戴耳机等头戴式设备而被声场自动跟随,实现了自由跟听。
这里的声场模式包括:全景模式、独享模式或综合模式。图3、图4、图5分别示出根据本方实施例的虚拟声场产生装置在三种声场模式配置下的操作示意图。
如图3所示,全景模式是以下的声场模式:扬声器阵列作为普通的多声道音响设备操作,声场控制器106控制扬声器阵列建立以空间(例如房间)中心或者以空间内的特定位置为声场中心,充满整个所述空间的声场。该特定位置与用户位置不关联。该模式适用于多个用户希望共享同一声音内容的情况。
如图4所示,独享模式是以下的声场模式:声场控制器106控制扬声器阵列建立分别以空间内的多个用户中的每个用户为中心的声场,并且为每个用户建立的声场之间彼此互不干扰。这种模式下,声场控制器106通过对音源输入装置102接收来的媒体声音信号进行相位调制,例如,发送至扬声器阵列的声音信号中,部分扬声器接收的声音信号被移相,从而实现在空间分布上具有特定中心的声场。各个中心彼此分开,互不干扰。这种分开可以用根据现有技术的各种声音调制技术实现。在此模式下,多用户之间各自享有各自的声场,彼此之间互不干扰,且各自的声场中心随各个用户的位置移动,避免传统头戴式耳机对人的位置的约束。
如图5所示,综合模式是以下的声场模式:声场控制器106控制扬声器阵列建立以该空间内的一个用户为中心的多维度声场,供用户选择使用。例如,声场控制器106控制扬声器阵列建立以空间内的一个用户为中心的五种效果的声场,用户可以选择其中任意一种或多种叠加使用。在此模式下,一个用户具有多种声场效果选择,从而为用户创建更为丰富的体验。这为沉浸式的体感游戏提供更灵活的选择。
上述定位系统104包括摄像头和麦克风阵列。麦克风阵列通过接收扬声器阵列发出的校准声音信号确定空间的声学模型。摄像头用于识别用户、扬声器阵列及麦克风阵列6的图像,定位系统104通过计算在当前空间设置环境下声音从扬声器阵列中的每个扬声器传播到达每个麦克风阵列6的空间传递函数,以及校准声音从扬声器阵列中的每个扬声器传播到达每个用户脸部的空间传递函数,确定空间的声学模型。基于该空间的声学模型,确定用户的人脸位置、扬声器阵列位置以及麦克风阵列6位置。这里人脸的位置,可以包括指采集获得图像中的人脸位置的指向,即用图像中获得的二维的指示方向代替位置。例如,以扬声器阵列中心为位置基准,人脸的位置可以用从扬声器阵列中的每一个指向每个用户人脸的指向来表征每个用户的位置。上述校准声音也可以是普通声音。
图6示出根据本发明上述实施例的虚拟声场产生装置进行校准操作的示意图。在校准操作时,声场控制器106控制扬声器阵列发出校准声音信号,该校准声音信号经空间内的空气传播到达麦克风阵列6,例如多个麦克风6或拾音头,被麦克风阵列6获取,根据声音传播速度以及声音信号的传播时间,从而能够获知在空间的当前布局下声音从扬声器阵列中的每个扬声器传播到达麦克风阵列6中每个麦克风的声音传播特性,即关于扬声器阵列的空间传递函数。
另外,定位系统104中的摄像头包括摄像头5,其拍摄并识别空间中布置的扬声器阵列和麦克风阵列及用户人脸的图像,从而能够获知扬声器阵列、麦克风装置以及用户人脸相互之间的相对位置。对扬声器阵列、麦克风阵列以及用户人脸的图像识别的技术可以基于现有技术进行。定位系统104将通过麦克风阵列获取的关于扬声器阵列的空间传递函数与通过摄像头获取的相对位置信息相结合,获得声音从扬声器阵列中的每个扬声器传播到达每个用户脸部的空间传递函数,即关于每个用户的空间传递函数,从而确定该空间的完整的声音模型。该完整的声音模型包括在当前空间设置环境下声音从扬声器阵列中的每个扬声器传播到达每个麦克风阵列6的空间传递函数组成的空间传递函数矩阵,以及声音从扬声器阵列中的每个扬声器传播到达用户头部的空间传递函数矩阵。该空间的声学模型是个多变量模型。当空间内的布置改变导致声音传播路径改变时,空间的声学模型也改变。当用户的位置改变时,空间的声学模型也改变。即:空间的声学模型随用户的位置更新而被更新。这能够实现根据用户实时位置更新声场中心,实现声场跟踪。
声场控制器基于空间的上述声音模型,调节声场输出装置的输出,再结合特定的声场模式控制输出给扬声器阵列的媒体声音。
定位系统104中的摄像头自动识别空间内的用户数目而配置声场模式。当识别空间内仅有一个用户时,虚拟声场产生装置的缺省配置为全景模式,即以空间中心或空间内的特定位置为中心建立虚拟声场。当识别空间内有两个以上用户时,虚拟声场产生装置的缺省配置为独享模式。在一种实施方式中,声场模式也可以由用户选择确定。优选地,虚拟声场产生装置可以具有声场模式输入端子,由用户输入选择声场模式。例如用户根据个人喜好选择综合模式或全景模式。另外,该声场模式输入端子还可以用于输入根据要播放的音源内容而自动确定的声场模式。例如,在进行体感游戏时,一种游戏设备根据游戏内容输出声场模式为独享模式(或全景模式)。在此情况下,虚拟声场产生装置的声场模式输入端子可以与游戏装置的声场模式输出端相连接,从而获取外部媒体内容的独享模式(或全景模式)输入,而代替内部的声场控制器106的声场模式控制,此时声场控制器106根据空间声学模型和外部输入的声场模式而操作扬声器阵列。
在一个实施例中,虚拟声场产生装置还包括扬声器阵列。扬声器阵列用于接收从声场输出装置108输出的声音信号。
图7示出根据本发明实施例的虚拟声场产生方法。包括以下步骤:
S702,从外部接收媒体声音;
S704,定位空间内用户的人脸位置、扬声器阵列位置,并计算和校准所述空间的声学模型;
S706,基于所述空间的声学模型和特定的声场模式控制所述媒体声音输出;
S708,输出经控制的所述媒体声音。
优选地,上述方法进一步包括:确定所述空间的声学模型,基于所述空间的声学模型以及所述用户、所述扬声器阵列及所述摄像头5的图像确定所述用户的人脸位置、扬声器阵列位置以及麦克风阵列位置。
优选地,所述方法进一步包括:所述声场模式包括全景模式、独享模式或综合模式,它们的操作情况如上所述。
上述虚拟声场产生方法的其他优选的实施方式可以从以上描述中获得。
应当注意,尽管在附图中以特定顺序描述了本发明的装置的组成和方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。相反,流程图中描绘的步骤可以改变执行顺序。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
- 还没有人留言评论。精彩留言会获得点赞!