主动降噪系统的制作方法
技术领域
本文揭示了一种降噪系统,其包括用于允许使用者欣赏,例如,已降低了环境噪声的再现音乐等的头戴式耳机。
背景技术:
通常可以获得的是被结合在头戴式耳机中的主动降噪系统,也称为主动噪声消除(ANC)系统。目前实际使用的降噪系统被分为两种类型,包括反馈型和前馈型。
在戴在使用者耳朵上的反馈型降噪头戴式耳机中,麦克风被设置在一种声管中。进入声管的外部噪声通过麦克风被收集、相位反转并从布置在麦克风和噪声源之间的扬声器发出,从而减少外部噪声。
在前馈型的降噪头戴式耳机中,当该耳机被戴到使用者的头上时,第一麦克风位于扬声器和耳道之间,即,在耳朵附近。第二麦克风被设置在噪声源和扬声器之间,并且被用于收集外部声音。第二麦克风的输出被用于使得从第一麦克风到扬声器的路径的传输特性与沿着外部噪声到达耳道的路径的传输特性相同。进入声管并通过第一麦克风收集的外部噪声被相位反转,并从布置在第一麦克风和噪声源之间的扬声器发出,以减少外部噪声。
在这两种类型中,麦克风都必须被布置在扬声器前方并靠近使用者的耳朵,这样做一方面使得使用者很不舒适,另一方面可能会导致麦克风的严重损坏,因为在该位置上对麦克风的机械保护被减弱。因此,存在着用于头戴式耳机的改善的降噪系统的普遍需求。
技术实现要素:
本文描述的主动降噪系统的一个实施例包括,当暴露于环境噪声时,声学上耦合到使用者耳朵上的耳机。该耳机包括带有孔径的杯状外壳;将电信号转换成被辐射给使用者耳朵的声信号并被布置在杯状外壳的孔径处从而形成耳机空腔的发送换能器;以及将声信号转换成电信号,被布置在耳机空腔内的接收换能器。该系统进一步包括从发射换能器向耳朵延伸并具有第一传递特性的第一声学路径;从发射换能器向接收换能器延伸并具有第二传递特性的第二声学路径;以及被电连接到接收换能器和发送换能器,并通过生成被提供给发射换能器的降噪电信号来补偿环境噪声的控制单元。降噪电信号是通过用第三传递特性滤波接收-换能器信号而得到的,并且其中第二和第三传递特性一起模拟(model)第一传递特性。
附图说明
下面基于附图中示出的示范性实施例更加具体地描述了各种具体实施例。除非另外说明,在所有附图中同样的组件被标注为相同的参考数字。
图1是公知的反馈主动降噪系统的示意图;
图2是公知的前馈降噪系统的示意图;
图3是本文揭示的反馈主动降噪系统的一个实施例的示意图;
图4是本文揭示的主动降噪系统的一个实施例中采用的耳机的示意图;
图5是在公知的主动降噪系统中信号流的示意图;
图6是本文揭示的具有闭环结构的主动降噪系统的一个实施例中的信号流的示意图;
图7是本文揭示的具有闭环结构的主动降噪系统的一个可替代实施例中的信号流的示意图;
图8是图7中示出的系统之下的基本原理的示意图;
图9是本文揭示的采用滤-x最小均方(FxLMS)算法的主动降噪系统的一个实施例的示意图;
图10是本文揭示的具有开环结构的主动降噪系统的一个实施例的示意图;
图11是说明在扩散噪声场中且麦克风距离为2cm的MSC函数的示意图;以及
图12是说明在扩散噪声场中且麦克风距离为2cm的阻尼函数的示意图。
具体实施方式
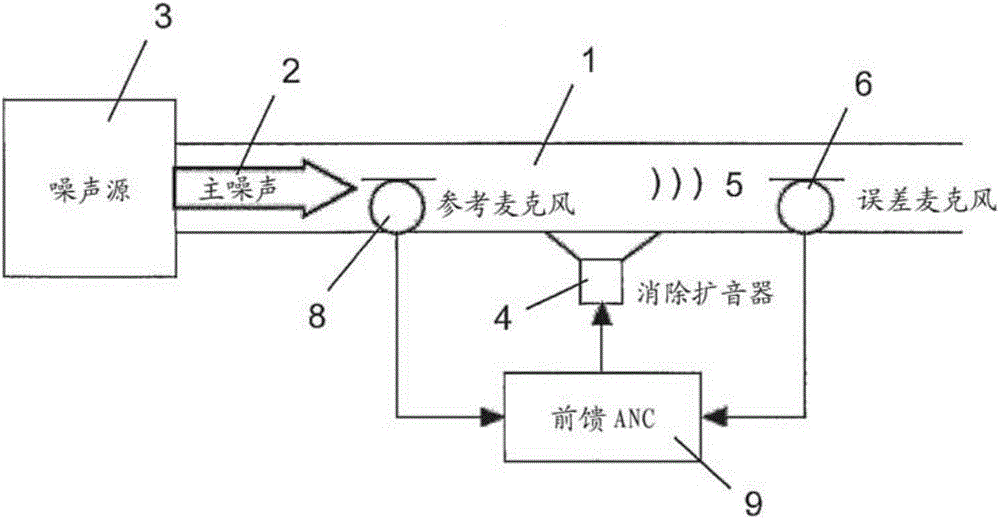
图1是公知的具有声管1的反馈型的主动降噪系统的示意图,在声管1的第一端处,噪声(所谓的主噪声2)从噪声源3被引入声管1中。主噪声2的声波经过管1传播到管1的第二端,例如,在声管被戴在使用者头上时,该声波从声管的第二端被辐射到使用者的耳朵中。为了在管中降低或消除主噪声2,扬声器(例如,扩音器4)将消除声音5引入管1中。该消除声音5具有至少对应于外部噪声、但优选地与外部噪声相同的幅度,然而相位相反。进入管1的外部噪声2通过误差麦克风6被收集,并且通过反馈ANC处理单元7被相位反转,然后从扩音器4被发射以降低主噪声2。误差麦克风6被布置在扩音器4的下游,并且因此,与到扩音器4的距离相比,更加靠近管1的第二端,即,在以上的实例中,误差麦克风6更靠近使用者的耳朵。
为了建立如图2所示的公知的前馈型的主动降噪系统,如图1所示,附加的参考麦克风8被设置在系统中的噪声源3和扩音器4之间,并且反馈ANC处理单元7被前馈ANC处理单元9代替。参考麦克风8收集主噪声2,并且参考麦克风8的输出被用于调整从扩音器4到误差麦克风6的路径的传输特性,使其与主噪声2到达管1的第二端,即,使用者的耳朵,所沿的路径的传输特性相匹配。使用从扩音器4到误差麦克风6的信号路径的调整后的传输特性,将由误差麦克风6收集的主噪声2的相位反转,并从布置在两个麦克风6和8之间的扩音器4发射,以降低外部噪声。信号的反转和传输路径调整是由前馈ANC处理单元9执行的。
图3中示出了本文揭示的反馈主动降噪系统的一个实施例。图3的系统与图1的系统不同,因为误差麦克风6被实际布置在管1的第一端和扩音器4之间,而不是被布置在扩音器4和管1的第二端之间。而且,滤波器10被连接在误差麦克风6和反馈ANC处理单元7之间。滤波器10被调整成使得麦克风6虚拟地位于扩音器4的下游,即,在扩音器4和管1的第二端之间,模拟(modeling)虚拟误差麦克风6’。
图4是本文揭示的主动降噪系统的一个实施例中采用的耳机11的示意图。耳机11可以是头戴式耳机(未示出)的一部分,并且可以被声学耦合到使用者13的耳朵12上。在该实例中,耳朵12被暴露于环境噪声,环境噪声形成了从噪声源3发出的主噪声2。耳机11包括带有孔径15的杯状外壳14。该孔径可以被栅、网格、或任意其他声音可透过的结构或材料覆盖。
将电信号转换成被辐射到耳朵12的声学信号且在该实例中由扬声器16形成的发送换能器被布置在外壳14的孔径15处,从而形成耳机空腔17。扬声器16可被密封地安装到外壳14上,以提供气密的空腔17,即,创建密封容积。可替代地,根据具体情况,可将空腔17通风(vented)。
将声学信号转换成电信号的接收换能器,例如,误差麦克风18被布置在耳机空腔17内。据此,误差麦克风18被布置在扬声器16和噪声源2之间。声学路径19从扬声器16延伸到耳朵12,并且其传递特性为HSE(z)。声学路径20从扬声器16延伸到误差麦克风18,并且其传递特性为HSM(z)。
图5是公知的主动降噪系统(例如,图1的系统)中的信号流的示意图,该系统进一步包括信号源21,用于提供由扬声器22声学辐射的期望信号x[n]。该扬声器还起到例如图1的系统中的扩音器4的消除扩音器的作用。由扬声器22辐射的声音经由传递特性为HSM(z)的(次)路径24被传递给误差麦克风23(如,图1的麦克风6)。
麦克风23接收来自扬声器22的声音和来自噪声源(未示出)的噪声N[n],并由此生成电信号e[n]。信号e[n]被提供给减法器25,减法器25从信号e[n]减去滤波器26的输出信号以生成信号N*[n],信号N*[n]是噪声N[n]的电表达形式。滤波器26的传递特性为H*SM(z),该传递特性H*SM(z)是次路径24的传递特性HSM(z)的估计值。信号N*[n]由滤波器27滤波,其中滤波器27的传递特性与传递特性H*SM(z)的反相相等,然后被提供给减法器28,减法器28从期望信号x[n]减去滤波器27的输出信号以生成将要提供给扬声器22的信号。滤波器26被提供了与扬声器22相同的信号。在以上参考图5描述的系统中,使用了所谓的闭环结构,如以上已经看到的那样。
图6示出了本文揭示的闭环主动降噪系统的一个实施例中的信号流。在该系统中,具有传递特性HSC(z)的附加滤波器29被连接在误差麦克风23和减法器25之间。其传递特性HSC(z)如下:
HSC(z)=HSE(z)–HSM(z).
据此,实际的(物理的、真实的)次路径24和滤波器29的传递特性HSM(z)、HSC(z)一起模拟在扬声器22和在期望信号位置处(例如,在使用者的耳朵12处)的麦克风(以下也称为“虚拟麦克风”)之间的虚拟(期望)信号路径30的传递特性HSE(z)。当将上述应用到例如图4的系统时,麦克风18可以从其在噪声源3和扬声器16之间的真实位置被虚拟地移到使用者耳朵12(图示为耳朵麦克风12)处的(期望)位置上。
在图3的系统中,期望的信号路径从扩音器4延伸到虚拟麦克风6’。物理的(真实的)信号路径从麦克风6延伸到扩音器4。依靠麦克风6下游的滤波器29,真实的麦克风6的位置被虚拟地移到麦克风6’的位置。
图7示出了本文揭示的闭环主动降噪系统的一个可替代实施例中的信号流。再一次地,信号源21将期望信号x[n]提供给扬声器22,扬声器22不仅对信号x[n]进行声学辐射,而且有效地起到降噪作用。被扬声器22辐射的声音经由具有传递特性HSM(z)的(次)路径24传播到误差麦克23。
麦克风23从扬声器22接收声音和噪声N[n],并且由此生成电信号e[n]。信号e[n]被提供给加法器31,加法器31将滤波器26的输出信号加到信号e[n]上,以生成信号N*[n],该信号N*[n]是噪声N[n]的电表达方式(在该实例中为估计值)。滤波器26具有传递特性H*SM(z),该传递特性H*SM(z)对应于次路径24的传递特性HSM(z)。信号N*[n]被滤波器32滤波,其中滤波器32的传递特性与传递特性H*SM(z)的反相相等,然后被提供给减法器28,减法器28从期望信号x[n]减去滤波器32的输出信号,以生成将要提供给扬声器22的信号。从滤波器32的输出信号减去信号x[n]的减法器33的输出信号被提供给滤波器26。
图8是图7示出的系统的基本原理的示意图,其中噪声源34经由传输特性为P(z)的主(传输)路径36向误差麦克风35发送噪声信号d[n],在误差麦克风35的位置处产生噪声信号d’[n]。
误差信号e[n]被提供给加法器40,加法器40从信号e[n]减去滤波器41的输出信号以生成信号d^[n],该信号d^[n]是噪声信号d’[n]的估计表达式。滤波器41具有传递特性S^(z),该传递特性S^(z)是次路径39的传递特性S(z)的估计值。信号d^[n]被具有传递特性w(z)的滤波器42滤波,然后被提供给减法器43,减法器43从期望信号x[n],如,由信号源37供给的音乐或语音,中减去滤波器42的输出信号,以生成将要提供给扩音器38的信号,用于经由传输特性为S(z)的次(传输)路径39传输到误差麦克风35。从期望信号x[n]中减去滤波器42的输出信号的来自减法器43的输出信号被提供给滤波器41。
可使用如下面参考图9描述的适应算法对图8的系统进行增强。在这种系统中,滤波器42是由适应控制单元44控制的可控滤波器。适应控制单元44从减法器40接收由滤波器45滤波的信号d^[n],并从误差麦克风35接收误差信号e[n]。滤波器45具有和滤波器41相同的传输特性,即,S^(z)。可控滤波器41和控制单元44一起形成自适应滤波器,该自适应滤波器可用于调整,例如,所谓的最小均方(LMS)算法,或者,如在本实施例的情况下,滤波-x最小均方(FxLMS)算法。然而,其它算法也可能是适用的,例如,滤波-e LMS算法或类似算法。
通常,如那些在图8和9中示出的反馈ANC系统估计纯噪声信号d’[n],并将该估计噪声信号d^[n]输入ANC滤波器,即,在该实例中的滤波器42。为了估计纯噪声信号d’[n],对从扩音器38到误差麦克风35的声学次路径39的传输特性S(z)进行估计。在滤波器41中使用估计的次路径39的传输特性S^(z),以电滤波被提供给扬声器38的信号。通过从误差信号e[n]中减去滤波器41的信号输出,获得估计噪声信号d^[n]。如果估计次路径S^(z)与实际次路径S(z)完全相同,则估计噪声信号d^[n]与实际的纯噪声信号d’[n]完全相同。估计噪声信号d^[n]在传输特性为W(z)的(ANC)42中被滤波,其中
W(z)=P(z)/S(z),
然后从期望信号x[n]中被减去。信号e[n]可以表示如下:
当且仅当S^(z)=S(z),并且同样地d^[n]=d’[n]时,
e[n]=d[n]·P(z)+x[n]·S(z)-d^[n]·(P(z)/S^(z))·S(z)=x[n]·S(z)。
估计噪声信号d^[n]如下:
当且仅当S^(z)=S(z)时,
d^[n]=e[n]-(x[n]-d'[n]·(P(z)/S^(z))·S^(z))=d'[n]·P(z)=d[n]。
由此,估计噪声信号d^[n]模拟实际噪声信号d[n]。
诸如以上公式等描述的闭环系统的目标是,通过在将期望信号提供给扬声器之前从期望信号中减去估计的噪声信号来减少期望信号的不希望的降低。在开环系统中,为了获得降噪效果,通过特殊滤波器来供给误差信号,在该特殊滤波器中,误差信号经过低通滤波(例如,低于1kHz)并且被控制增益以获得稳定的适度的环路增益和相位调整(例如,反转)。然而,由此可见,开环系统可导致期望信号被降低。另一方面,开环系统比闭环系统复杂性低。
图10中示出了本文揭示的类型的开环ANC系统。信号源51将诸如音乐信号等的有用信号提供给加法器46,加法器46的输出信号经由适当的信号处理电路(未示出)被提供给扬声器47。加法器46还接收由误差麦克风48提供并由串联连接的滤波器49和滤波器50滤波的误差信号。滤波器50的传递特性为HOL(z),并且滤波器49的传递特性为HSC(z)。传递特性HOL(z)是普通开环系统的特性,传递特性HSC(z)是用于补偿误差麦克风48的虚拟位置和实际位置之间差异的特性。
普通闭环ANC系统在误差麦克风被安装成尽量接近耳朵,即,在耳朵里时,展现其最佳性能。然而,将误差麦克风置于耳朵里对于收听者来说将极为不方便,并且将劣化收听者感受到的声音。将误差麦克风置于耳朵外将使ANC系统的质量恶化。为解决这种两难的问题,多系统(numerous system)已经被引入,但是这些系统主要依靠机械结构的调整,即,已经尝试了在扬声器和误差麦克风之间提供紧凑型的封装(enclosure),理想地不会被例如一个人或不同使用者佩戴头戴式耳机的方式打乱。尽管这样的机械调整的确能够在一定程度上解决稳定性问题,但是由于它们位于扬声器和收听者耳朵之间,它们仍会导致声学性能失真。
为克服上述的两难问题,本文提出一种系统,其采用模拟或数字(或两者都有)信号处理,以允许一方面将误差麦克风置于远离耳朵处,另一方面保证了持续稳定的性能。本文揭示的系统通过将误差麦克风放置在扬声器的后面,即,在耳机和扬声器之间,解决了稳定性问题。这提供了限定封装,该限定封装不以任何方式使声学性能失真。在这种系统中,误差麦克风被布置成稍微远离收听者的耳朵,不可避免地导致ANC性能的恶化。该问题通过利用直接放置在使用者耳朵里的“虚拟麦克风”被克服。“虚拟麦克风”意味着麦克风实际上被布置在一个位置,但是通过适合的信号滤波看来相是出现在另一个“虚拟”的位置。以下实例是基于数字信号处理使得所有被使用的信号和传递特性均在离散的时间和谱域(n,z)中。对于模拟处理,使用连续的时间和谱域(t,s)中的信号和传递特性,这意味着在所考虑的实例中,n只需要被t代替,而z被s代替。
再次参考图6;为了造成“虚拟的”误差麦克风,评估理想传递特性HSE(z),即,在从扬声器到耳朵的信号路径(期望的次路径)上的传递特性,并且确定从扬声器到误差麦克风的信号路径(真实的次路径)上的实际的传递特性HSM(z)。为了确定在虚拟麦克风位置处提供理想声音接收和最佳噪声消除的滤波器特性W(z),滤波器特性W(z)被设置为W(z)=1/HSE(z)。虚拟误差麦克风接收的总信号x[n]·HSE(z)为:
其中,形成ANC系统的输入信号的估计噪声信号N[n]为:
从上面的等式可以看出,当在虚拟位置处的估计噪声信号N[n]与在收听者耳朵里的相同时,获得了最佳的噪声抑制。噪声抑制算法主要取决于次路径S(z)的精确度,在当前情况下通过其传递特性HSM(z)表示。如果次路径改变,系统必须适应新的状况,这需要额外的时间消耗和高成本的信号处理。
本文揭示的系统的主要途径包括保持次路径基本稳定,即,其传递特性HSM(z)恒定,以便保持附加信号处理的低复杂度。为此,误差麦克风被布置在使得不同操作模式不会造成次路径的传递函数HSM(z)发生重大波动的位置上。在本文揭示的系统中,误差麦克风被布置在耳机空腔内,该耳机空腔对波动相对不敏感,但相对远离耳朵,使得ANC算法的总体性能很差。然而,只需要提供非常少的附加信号处理的附加(全通)滤波来补偿与耳朵距离较远的缺点。用于实现传递特性1/HSE(z)和HSM(z)所需的附加信号处理不仅可以通过数字电路,而且也可以通过模拟电路来提供,例如,使用运算放大器的可编程RC滤波器。
如上面指出的,采用虚拟麦克风的ANC系统的性能基本取决于实际误差麦克风位置与虚拟麦克风位置(即,耳朵处)的噪声信号之间的差异。在连续的谱域中,对于这样的ANC系统的性能的估计,使用所谓的最大平方相干性(Maximum Square Coherence(MSC))函数Cij(ω),其定义如下:
其中和是自动功率密度谱(Auto Power Density Spectra),而是信号Xi和Xj的交叉功率密度谱(Cross Power Density Spectrum)。Gij(ω)是两个麦克风i和j的复相干函数(Complex Coherent Function)。复相干函数Gij(ω)基本上取决于局部噪声场。对于下面的最恶劣的情况考虑,假设为扩散噪声场。这样的场可被描述如下:
其中i,j∈[1,…,M]
其中f是单位为[Hz]的频率,dij是麦克风i和j之间的距离,其单位为[m],c是在室温下的空气中的声音速率(c=340[m/s]),并且M是麦克风的数量,在当前情况下为2,并且其中SI函数为
并且距离dij为:
MSC函数是,与时域中的相关系数相类似,两种处理的线性互相依赖的程度。如果信号xi(t)和xj(t)在各自的频率ω处完全相关,则MSC函数Cij(ω)的最大值为1,并且如果这些信号绝对不相关,其最小值为0,由此:
1≥Cij(ω)≥0
MSC函数描述了当来自麦克风j的信号是基于来自麦克风i的信号线性估计出来的时候发生的误差。如果在扩散噪声场中距离为d=2cm,MSC函数表现为如图11中所示。从MSC函数Cij(ω)得到最大ANC阻尼Dij(ω)如下:
Dij(ω)=20·log10(1-Cij(ω)) 单位[dB]
图12示出了在扩散噪声场中发生的阻尼函数Dij(ω),单位为[dB],麦克风距离为2cm。从图12可以看到,理论上,在麦克风距离为2cm的情况下,噪声抑制(阻尼)Dij(ω)=27dB可在扩散噪声场中频率为1kHz处获得,这是非常充分的。
- 还没有人留言评论。精彩留言会获得点赞!