一种仿射投影最大熵子带自适应回声消除方法与流程
本发明属于语音通信的自适应回声对消
技术领域:
。
背景技术:
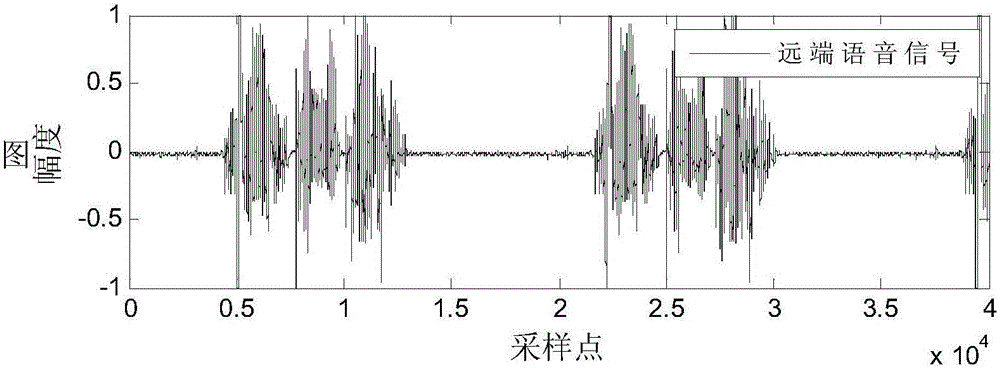
:为了解决通信时,系统回声干扰问题,各种各样的回声消除方法被提出。目前回声消除方法主要有移频技术、子带中心削波技术、话音控制开关技术、梳状滤波技术、话筒阵列技术、自适应回声消除技术。前5种方法成本高、设计难度大等缺点。而自适应回声消除方法不仅成本低,而且可以获得良好的性能,因此,自适应回声消除方法是目前回声消除的主流技术。自适应回声消除技术中,自适应滤波器是能够根据输入信号自主调整性能进行数字信号处理的数字滤波器,自适应滤波器的参数是动态的预先设定不可调整的。所谓自适应滤波器就是能够在工作过程中逐步学习出所需的统计特性,并以此为依据自动调整滤波器系数,以达到最佳滤波的效果;一旦输入信号的特性发生变化,它又可以跟踪这种变化,自动调整滤波器参数,使滤波性能重新达到最佳。传统的LMS(最小均方)滤波器是应用较为广泛的滤波器,主要是因为其具有结构简单、易于实现等优点。已得到国内外研究者的广泛关注。然而,在实际的通信中的回声信道具有阶数长等特点。传统LMS滤波器的性能会大大降低,为了解决这一问题,引入子带滤波器,该种方法将输入信号经过分析滤波器按频率分割为多个子带信号,由于输入信号的频率与回声的相关度高,对不同的子带信号自适应的进行不同的回声消除,再进行归一化处理,能从整体上降低回声消除的难度,从而可以获得较好的收敛速度。不同子带信号的自适应处理方法也即对不同子带信号赋予不同的权系数,能提高收敛速度。不同子带信号权系数的更新算法,较成熟的方法有,文献1的仿射投影符号子带(APSSAF)回声消除方法“Twovariantsofthesignsubbandadaptivefilterwithimprovedconvergencerate”(J.Ni,X.Chen和J.Yang,SignalProcess.,vol.96,pp.325–331,May.2014)。该方法结合和符号算法和子带带算法的优点,当冲激响应发生时,包括冲激信号在内的误差信号幅值经过符号算法处理后为正一或负一,使得冲激信号对算法的收敛性影响几乎为零。因此该算法具有良好的抗冲激干扰能力。然而,由于在算法的收敛时,仅仅通过误差信号的符号(正负),而不考虑误差信号的大小,来进行算法权向量的更新,使其虽然抗冲激干扰能力好,但其收敛速度有待提高。技术实现要素:本发明的发明目的就是提供一种仿射投影最大熵子带自适应回声消除方法,该方法对通信系统的声学回声消除效果好,收敛速度快,抗干扰能力强。本发明实现其发明目的所采用的技术方案是,一种仿射投影最大熵子带自适应回声消除方法,其步骤如下:A、远端信号分割将当前时刻n到时刻n-L+1之间的采样远端信号,构成当前时刻n的远端信号向量U(n),U(n)=[u(n),u(n-1),...,u(n-L+1)]T;L=512是滤波器抽头数,上标T表示转置运算;远端信号向量U(n)经分析滤波器一分割成I个远端子带向量Ui(n),Ui(n)=[ui(n),ui(n-1),...,ui(n-L+1)]T;同时,将近端麦克风拾取到的当前时刻n的带回声的近端信号d(n)经分析滤波器二分割成I个近端子带信号di(n);其中,i为远端子带向量或近端子带信号的序号,i=1,2,...,I;I为远端子带向量或近端子带信号的总个数;B、信号抽取将远端子带向量Ui(n)经抽取器进行I抽取;即将n=k=KI时刻的远端输入子带向量Ui(n)抽出,得到抽取时刻k的远端输入子带抽取向量Ui(k),Ui(k)=[ui(kI),ui(kI-1),...,ui(kI-L+1)]T;同样,也对近端子带信号di(n)经抽取器进行I抽取得到抽取时刻k的近端子带抽取信号di(k),di(k)=di(KI);其中,K为抽取的序号,k为第K次抽取的抽取时刻;C、将抽取时刻k和前P-1个抽取时刻的远端子带抽取向量Ui(k),Ui(k-1)…Ui(k-P+1)组合,得到抽取时刻k的远端子带仿射投影矩阵,Xi(k)=[Ui(k),Ui(k-1),...,Ui(k-P+1)];再将抽取时刻k的I个远端子带仿射投影矩阵X1(k),X2(k),...,XI(k)组合得到抽取时刻k的远端输入子带仿射投影矩阵X(k),X(k)=[X1(k),X2(k),...,XI(k)];同时,将抽取时刻k和前P-1个抽取时刻的近端子带抽取信号di(k),di(k-1),...,di(k-P+1)组合,得到抽取时刻k的近端子带仿射投影矩阵Di(k)=[di(k),di(k-1),...,di(k-P+1)];再将抽取时刻k的I个近端子带仿射投影向量D1(k),D2(k),...,Di(k),...,DI(k)组合得到抽取时刻k的近端子带仿射投影向量D(k),D(k)=[D1(k),D2(k),...,Di(k),...,DI(k)];D、滤波器输出将抽取时刻k的远端输入子带仿射投影矩阵X(k)通过自适应回声消除滤波器滤波后得到抽取时刻k的输出向量Y(k),Y(k)=W(k)TX(k);其中,W(k)为抽取时刻k的自适应回声消除滤波器的抽头权向量,其初始值为零,即W(1)=0;E、回声抵消将抽取时刻k的近端子带仿射投影向量D(k)与抽取时刻k的输出向量Y(k)相减后得到抽取时刻k的回声消除后的净信号向量E(k),E(k)=D(k)-Y(k),并将其回送给远端;F、抽头权向量更新计算出净信号向量最大熵V(k),V(k)=exp[-0.04×diag(XT(k)X(k))E(k)⊙E(k)]其中,exp[·]表示取自然指数,diag(·)表示取矩阵的对角元素。⊙表示向量的对应元素相乘;计算下一个抽取时刻k+1的自适应回声消除滤波器的抽头权向量W(k+1),W(k+1)=W(k)+μX(k)(XT(k)X(k)+δH)-1E(k)⊙V(k)其中,μ为步长,取值为0.01~1,δ为正则化参数,其取值为0.001~0.01,H表示单位矩阵,G、迭代令k=k+1,重复A、B、C、D、E、F的步骤,直至通话结束。与现有技术相比,本发明的有益效果是:本发明通过引入净信号向量最大熵,基于当前抽取时刻的净信号向量的最大熵V(k)更新确定出下一抽取时刻的权向量W(k+1)=W(k)+μX(k)(XT(k)X(k)+δH)-1E(k)⊙V(k);当有冲激干扰时,近端信号离散值D(k)=[D1(k),D2(k),...,Di(k),...,DI(k)]中的元素会很大,净信号向量E(n)中的元素也会很大,这时信号向量的最大熵V(k)的值将变为接近零的数值,此时权向量的更新接近于零,几乎停止更新;从而,本发明具有很好的抗冲激干扰能力。并且,当系统没有冲激干扰时,净信号向量E(n)中的元素会很小,净信号向量最大熵V(k)的值与净信号向量E(n)近似相等,权向量的变化大,更新快。总之,本发明的权向量更新不仅考虑了误差信号(净信号)的符号,更考虑了其大小,使其既具有很好的抗冲激干扰能力好,同时又有较好的收敛速度。下面结合附图和具体实施方式对本发明进行详细说明。附图说明图1是本发明仿真实验的信道图。图2a是仿真实验用的双通话中的近端信号(语音)图和远端信号(语音)。图2b仿真实验用的双通话中的远端信号(语音)图图3是文献1方法和本发明方法的仿真实验归一化稳态失调曲线。具体实施方式实施例本发明的一种具体实施方式是,一种仿射投影最大熵子带自适应回声消除方法,其步骤如下:A、远端信号分割将当前时刻n到时刻n-L+1之间的采样远端信号,构成当前时刻n的远端信号向量U(n),U(n)=[u(n),u(n-1),...,u(n-L+1)]T;L=512是滤波器抽头数,上标T表示转置运算;远端信号向量U(n)经分析滤波器一分割成I个远端子带向量Ui(n),Ui(n)=[ui(n),ui(n-1),...,ui(n-L+1)]T;同时,将近端麦克风拾取到的当前时刻n的带回声的近端信号d(n)经分析滤波器二分割成I个近端子带信号di(n);其中,i为远端子带向量或近端子带信号的序号,i=1,2,...,I;I为远端子带向量或近端子带信号的总个数;B、信号抽取将远端子带向量Ui(n)经抽取器进行I抽取;即将n=k=KI时刻的远端输入子带向量Ui(n)抽出,得到抽取时刻k的远端输入子带抽取向量Ui(k),Ui(k)=[ui(kI),ui(kI-1),...,ui(kI-L+1)]T;同样,也对近端子带信号di(n)经抽取器进行I抽取得到抽取时刻k的近端子带抽取信号di(k),di(k)=di(KI);其中,K为抽取的序号,k为第K次抽取的抽取时刻;C、将抽取时刻k和前P-1个抽取时刻的远端子带抽取向量Ui(k),Ui(k-1)…Ui(k-P+1)组合,得到抽取时刻k的远端子带仿射投影矩阵,Xi(k)=[Ui(k),Ui(k-1),...,Ui(k-P+1)];再将抽取时刻k的I个远端子带仿射投影矩阵X1(k),X2(k),...,XI(k)组合得到抽取时刻k的远端输入子带仿射投影矩阵X(k),X(k)=[X1(k),X2(k),...,XI(k)];同时,将抽取时刻k和前P-1个抽取时刻的近端子带抽取信号di(k),di(k-1),...,di(k-P+1)组合,得到抽取时刻k的近端子带仿射投影矩阵Di(k)=[di(k),di(k-1),...,di(k-P+1)];再将抽取时刻k的I个近端子带仿射投影向量D1(k),D2(k),...,Di(k),...,DI(k)组合得到抽取时刻k的近端子带仿射投影向量D(k),D(k)=[D1(k),D2(k),...,Di(k),...,DI(k)];D、滤波器输出将抽取时刻k的远端输入子带仿射投影矩阵X(k)通过自适应回声消除滤波器滤波后得到抽取时刻k的输出向量Y(k),Y(k)=W(k)TX(k);其中,W(k)为抽取时刻k的自适应回声消除滤波器的抽头权向量,其初始值为零,即W(1)=0;E、回声抵消将抽取时刻k的近端子带仿射投影向量D(k)与抽取时刻k的输出向量Y(k)相减后得到抽取时刻k的回声消除后的净信号向量E(k),E(k)=D(k)-Y(k),并将其回送给远端;F、抽头权向量更新计算出净信号向量最大熵V(k),V(k)=exp[-0.04×diag(XT(k)X(k))E(k)⊙E(k)]其中,exp[·]表示取自然指数,diag(·)表示取矩阵的对角元素。⊙表示向量的对应元素相乘;计算下一个抽取时刻k+1的自适应回声消除滤波器的抽头权向量W(k+1),W(k+1)=W(k)+μX(k)(XT(k)X(k)+δH)-1E(k)⊙V(k)其中,μ为步长,取值为0.01~1,δ为正则化参数,其取值为0.001~0.01,H表示单位矩阵,G、迭代令k=k+1,重复A、B、C、D、E、F的步骤,直至通话结束。仿真实验:为了验证本发明的有效性,进行了仿真实验,并与现有的文献1算法进行了对比。仿真实验的远端信号为语音信号,采样频率为8000Hz,采样点个数40000。回声信道脉冲响应在高2.5m,宽3.75m,长6.25m,温度20℃,湿度50%的安静密闭房间内获得,脉冲响应长度即滤波器抽头数L=512。实验的背景噪声为高斯白噪声,信噪比为30dB。并且在麦克风接收到的近端信号中,从第15000个采样点加入长度为20000采样点的语音信号。按照以上实验条件,用本发明方法与现有的两种方法进行回声消除实验。各种方法的参数具体取值如表1。表1实验各算法的最优参数近似取值文献1μ=0.05;P=4;δ=0.01本发明μ=0.1;P=4;I=4;δ=0.01图1是实验用的安静密闭房间构成的通信系统的信道图,图2a、图2b分别是实验用的双通话中近端信号(语音)和远端信号(语音)图。图3是文献1和本发明的实验的归一化稳态失调曲线。由图3可知,在双通话情况下,本发明比文献1收敛速度更快,稳态误差更小。本发明在约20000个采样时刻(0.25s)收敛,稳态误差约在-34dB;而文献1则在约30000个采样时刻(0.375s)收敛,稳态误差约在-19dB;本发明比文献1收敛速度快近40%,稳态误差减小了近两倍。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1