一种对虚拟场景直播进行美颜处理的方法及系统与流程
本发明涉及多媒体数据处理领域,特别是涉及一种对虚拟场景直播数据进行处理的技术。
背景技术:
由于设备成本的下降和直播技术的日臻成熟,通过网络进行表演直播的娱乐形式逐渐为大众所接受和欢迎。虚拟场景合成技术是一种应用于电视台演播厅录播节目或电影制作中的多媒体数据处理技术,例如天气预报节目等。
现有技术中,虚拟场景合成技术通常通过将摄像装置采集到的纯色背景中的人像提取出来,然后与渲染出来的虚拟场景背景进行叠加合成,再将合成后的图像数据输出用于播放或录制存储。
现有的虚拟场景技术无法实现主播对象与观众对象之间高品质的互动交流。具体的,例如在网络直播领域中,现有的直播平台和技术,使得观众只能看到主播摄像头拍摄的画面,观众可以向主播赠送虚拟礼物,但是这些虚拟礼物只能在现有的场景下进行粗糙地叠加。又例如,现有MTV制作通常由导演和表演者交流后录制完成,录制过程缺乏趣味性,录制效果单一。并且在现有直播技术中,为了使客户端能够看到其他客户端与主播之间的互动效果,需要客户端将互动信息和素材发送到云端服务器,云端服务器通知所有在线客户端从指定位置下载素材,并由客户端叠加到直播画面上。可见,客户端需要下载指定素材,效率低下,且浪费流量;并且需要每个客户端在本地存储所述互动素材,占用客户端存储空间,而且互动内容不便于及时进行扩展。
而且,由于摄像装置所拍摄的主播对象的像素点高,成像真实,导致主播对象脸部的瑕疵都直接呈现在镜头上,故此,在直播之前往往需要对主播对象进行美颜。而现有的美颜处理,是对图像中的每个像素点进行处理运算,处理运算的数据量大,具有较高的延迟,并占用大量CPU资源,无法应用于实时性要求较高的直播。另外,在一些现有的直播数据处理方案中,是直接对视频流进行美颜处理,无形中增加了直播的延迟。
因此发明人认为需要研发一种能够降低网络虚拟场景直播美颜处理所造成直播延迟的技术。
技术实现要素:
为此,需要提供一种能够对虚拟场景直播数据进行快速美颜处理的技术,用于降低网络虚拟场景直播美颜处理的延迟时间。
为实现上述目的,发明人提供了一种对虚拟场景直播进行美颜处理的方法,包括以下步骤:
实时获取摄像装置的数据,得到第一图像数据;
将第一图像数据转换成纹理图像,并将所述纹理图像更新至虚拟场景中;
通过GPU从纹理图像中识别出第一对象,将纹理图像除第一对象外的剩余部分透明化,然后对第一对象进行美颜处理,再对美颜后的第一对象及所述虚拟场景进行渲染,得到渲染图像。
进一步的,得到渲染图像之后还包括步骤:
对所述渲染图像进行合成图像编码操作,得到第一视频数据;
获取摄像装置数据的同时,实时获取音效器的音频数据,将音效器的音频数据与第一视频数据封装成音视频数据。
进一步的,得到所述音视频数据之后还包括步骤:通过实时流传输协议,将所述音视频数据直播给局域网中的在线客户端;
或通过实时流传输协议,将所述音视频数据发送给第三方网络服务器;
第三方网络服务器生成所述音视频数据的互联网直播链接。
进一步的,还包括接收客户端发送的互动指令,从及根据互动指令更新或切换虚拟场景。
进一步的,所述对所述渲染图像进行合成图像编码操作包括步骤:
使用硬件编码模块截取所述渲染图像,以及对所截取的渲染图像进行压缩编码。
进一步的,所述对第一对象进行美颜处理包括步骤:利用shader对第一对象进行磨皮处理,去斑处理和加亮处理。
进一步的,所述虚拟场景为3D虚拟现实场景或3D视频场景。
为实现上述目的,发明人还提供了另一技术方案:一种对虚拟场景直播进行美颜处理的系统,包括:
解析单元,用于实时获取摄像装置的数据,得到第一图像数据;
更新单元,用于将第一图像数据转换成纹理图像,并将所述纹理图像更新至虚拟场景中;以及
渲染单元,通过GPU从纹理图像中识别出第一对象,将纹理图像除第一对象外的剩余部分透明化,然后对第一对象进行美颜处理,再对美颜后的第一对象及所述虚拟场景进行渲染,得到渲染图像。
进一步的,对虚拟场景直播进行美颜处理的系统还包括:
合成图像编码单元,用于对所述渲染图像进行合成图像编码操作,得到第一视频数据;以及
封装单元,用于获取摄像装置数据的同时,实时获取音效器的音频数据,将音效器的音频数据与第一视频数据封装成音视频数据。
进一步的,还包括传输单元,用于通过实时流传输协议,将所述音视频数据直播给局域网中的在线客户端;
或用于通过实时流传输协议,将所述音视频数据发送给第三方网络服务器;
第三方网络服务器生成所述音视频数据的互联网直播链接。
进一步的,还包括互动单元,用于接收客户端发送的互动指令,从及根据互动指令更新或切换虚拟场景。
进一步的,所述合成图像编码单元对所述渲染图像进行合成图像编码操包括,使用硬件编码模块截取所述渲染图像,以及对所截取的渲染图像进行压缩编码。
区别于现有技术,美颜处理是对直播图像中的每个像素点进行处理运算,或对直播的视频流进行美颜处理,处理的数据量大,延迟时间长;上述技术方案先将摄像装置的数据转换成纹理图像,并将纹理图像更新至虚拟场景中,然后在虚拟场景渲染阶段,通过GPU识别第一对象,并对第一对象进行美颜处理,得到渲染图像,其中,GPU进行图像渲染以及第一对象的识别与美颜处理是并行进行的,该技术方案将第一对象的识别以及美颜处理放到图像渲染阶段中,通过GPU同时并行进行,从而大大降低了虚拟场景直播时美颜处理的延迟时间。
附图说明
图1为具体实施方式所述对虚拟场景直播进行美颜处理的方法的流程图;
图2为具体实施方式中得到渲染图像后进行网络直播的操作流程图;
图3具体实施方式所述对虚拟场景直播进行美颜处理的系统的模块框图;
图4具体实施方式所述对虚拟场景直播进行美颜处理的系统的模块框图;
图5具体实施方式所述网络虚拟场景直播系统的示意图。
附图标记说明:
10、解析单元
20、更新单元
30、渲染单元
40、合成图像编码单元
50、封装单元
501、摄像装置
502、传声器
503、视频解码器
504、Unity端
505、录制服务器
506、RTSP服务器
507、客户端
508、第三方服务器
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
请参阅图1,本实施例一种对虚拟场景直播进行美颜处理的方法,该方法可应用于通过网络进行真人与虚拟场景相结合的视频直播节目,包括以下步骤:
S101、实时获取摄像装置的数据,得到第一图像数据。具体的,对所述摄像装置的数据进行解码,并在每获得到一帧完整的解码图像数据时,将图像数据放至数据缓冲区中。在某些实施例中,使用FFMPEG+mediacodec的组合对摄像装置的实时数据流进行读取、解码、并实时更新到缓冲区中。FFMPEG+mediacodec是android平台下实现硬编码硬解码的类,能明显提升数据流编解码的速度。
S102、将第一图像数据转换成纹理图像,并将所述纹理图像更新至虚拟场景中。其中,所述纹理图像是指具有纹理的图像,纹理是计算机图形学名词,是一种反映图像中同质现象的视觉特征,它体现了物体表面的具有缓慢变化或者周期性变化的表面结构组织排列属性。纹理又称纹理贴图,是贴在物体表面,体现物体表面细节的一幅或多幅二维图形。纹理具有三大标志:某种局部序列性不断重复、非随机排列、纹理区域内大致为均匀的统一体。纹理不同于灰度、颜色等图像特征,它通过像素及其周围空间邻域的灰度分布来表现,即:局部纹理信息。局部纹理信息不同程度的重复性,即全局纹理信息。
在实施例中,将所述纹理图像更新至虚拟场景中,可以是将纹理图像以纹理的形式体现在虚拟场景的一个平面中。所述虚拟场景包括计算机模拟的虚拟现实场景或真实拍摄的视频场景等。更进一步的,实施例还可以结合新近发展的3D图像技术来提供虚拟场景,例如3D虚拟现实场景或3D视频场景。
3D虚拟现实场景技术是一种可以创建和体验虚拟世界的计算机仿真系统,它利用计算机生成一种现实场景的3D模拟场景,是一种多源信息融合的交互式的三维动态视景和实体行为的系统仿真。虚拟场景包括任何现实生活中存在的实际场景,包含视觉、听觉等任何能通过体感感受到的场景,通过计算机技术来模拟实现。3D虚拟现实场景的一种应用是3D虚拟舞台,3D虚拟舞台是通过计算机技术模拟现实舞台,实现一种立体感、真实感强的舞台效果。可以通过3D虚拟舞台实现,在现实中不在舞台上的主播对象在各种舞台上进行表演的场景效果。
3D视频是拍摄影像时,用两台摄影机模拟左右两眼视差,分别拍摄两条影片,然后将这两条影片同时放映到银幕上,放映时让观众左眼只能看到左眼图像,右眼只能看到右眼图像。最后两幅图像经过大脑叠合后,就能看到具有立体纵深感的画面,即为3D视频。
S103、通过GPU从纹理图像中识别出第一对象,将纹理图像除第一对象外的剩余部分透明化,然后对第一对象进行美颜处理,再对美颜后的第一对象及所述虚拟场景进行渲染,得到渲染图像。其中,第一对象为摄像装置所拍摄的图像中的对象。在不同的实施例中根据需要,第一对象可以是不同的具体对象,例如第一对象可以是真人主播,可以是宠物动物等;第一对象的数量可以是单个,也可以是2个以上。根据这些实际需求的不同,可以使用不同的算法和设置,以有效地在虚拟场景中提取第一对象。由于第一对象是在第一图像数据内,因此,从虚拟场景中提取第一对象,实际上就是从第一图像数据中提取第一对象。以下通过一具体提取第一对象的算法实施例进行举例说明。
在某一实施例中,第一图像数据中,第一对象为人物主播,主播所处的背景为纯色背景。识别虚拟场景中第一对象的具体步骤为:GPU将纹理图像中的每个像素的颜色值与预设的阈值做比较;若像素的颜色值在预设的阈值内,则该像素点不属于第一对象,并将该像素点的Alpha通道设为零,即将背景显示为透明色;若像素的颜色值在预设的阈值外,则该像素点属于第一对象,该像素点的Alpha通道设为1,即保留该像素点从而识别并提取出对象。
由于背景为纯色,所以本实施例采用色度键法进行抠图。其中预设的阈值为背景颜色的颜色值,例如,背景颜色为绿色,则预设的像素点RGB颜色值的阈值为(0±10、255-10、0±10)。背景色可以选择绿色或蓝色,在拍摄的场所可同时设置两种颜色的背景,供主播选择。当主播穿与绿色反差较大的衣服唱歌时,可选用绿色的背景。在对象(人像)提取过程中,由于主播穿的衣服与背景色相差较大,所以图像中的每个像素的颜色值与预设的阈值进行比较后,背景部分像素点的颜色值在预设的阈值内,将背景部分像素点的Alpha通道设为零,即将背景显示为透明色;而人像部分的像素点不在预设的阈值内,保留人像部分,从而实现将纹理图像中的背景部分透明化。
在对象(人像)提取过程中,还可设置阈值区间,当像素的颜色值大于上限值时,将该像素点的Alpha通道设为零,即将背景显示为透明色;当当像素的颜色值小于下限值时,将该像素点的Alpha通道设为1,即保留人像部分;当像素的颜色值介于上限和下限之间,认为该像素是过渡色(一半出现在图像边缘处),这时使用线性函数将该像素的alpha通道设置为0~1中的一个。过渡色的设定有利于抠出来的人像和虚拟场景进行更自然的融合。
所述美颜处理是指,对所选择的对象进行处理以提高其颜值,在不同的实施例中根据需要,所述对第一对象进行美颜处理可以包括皮肤磨皮处理、脸部去斑处理和加亮处理。本发明的美颜操作均可通过shader实现GPU对第一对象的识别以及进行美颜处理。以人物为美颜对象为例,首先在shader程序中,先从人物对象中识别出皮肤部分,皮肤识别可利用人类皮肤在YCbCr颜色空间的呈现高斯分布的特点,对皮肤和非皮肤区域进行分割。其中,所述Shader(又称着色器)是一段能够针对3D对象进行操作、并被GPU所执行的程序。在识别出皮肤之后可进行磨皮处理,磨皮处理是使用双边滤波算法,对皮肤进行平滑处理,平滑皮肤区域的同时避免边缘钝化。在磨皮处理之后可进行加亮处理,加亮部分采用LOG曲线进行整体像素的增益校正,避免图像变化过于生硬。
所述图像渲染是利用计算机技术进行视觉设计的最后一道工序(当然,除了后期制作),也是使设计的图像以3D视觉进行呈现的阶段。
在实施例中,将摄像装置的数据转换成纹理图像,并将纹理图像更新至虚拟场景中,然后在虚拟场景渲染阶段;所述第一对象的识别与美颜,都是在图像渲染阶段通过GPU并行执行的,不占用CPU时间,提高系统速度;并且由于GPU是专门对图像进行处理的硬件,对不同大小的像素运算时间一样,例如,8位、16位、32位的像素运算时间均一样,可大大节省了对像素的运算时间;而普通的CPU会随像素大小的增大延长处理时间,所以本实施例的人像提取速度大大提高。上述的区别点使得本实施例中还可以采用带有GPU的嵌入式设备实现,即使嵌入式方案中的CPU性能较弱,但是应用本实施例的方案,嵌入式设备方案仍然能实现流畅显示,因为若使用CPU从第一图像数据中提取第一对象,CPU需进行读取摄像装置获取的视频,并进行抠图等处理,CPU负担太重,无法进行流畅的显示。而本实施例应用于嵌入式方案中,将上述抠图处理放入GPU中进行,既减轻了CPU的负担,同时不会对GPU的运行造成影响。
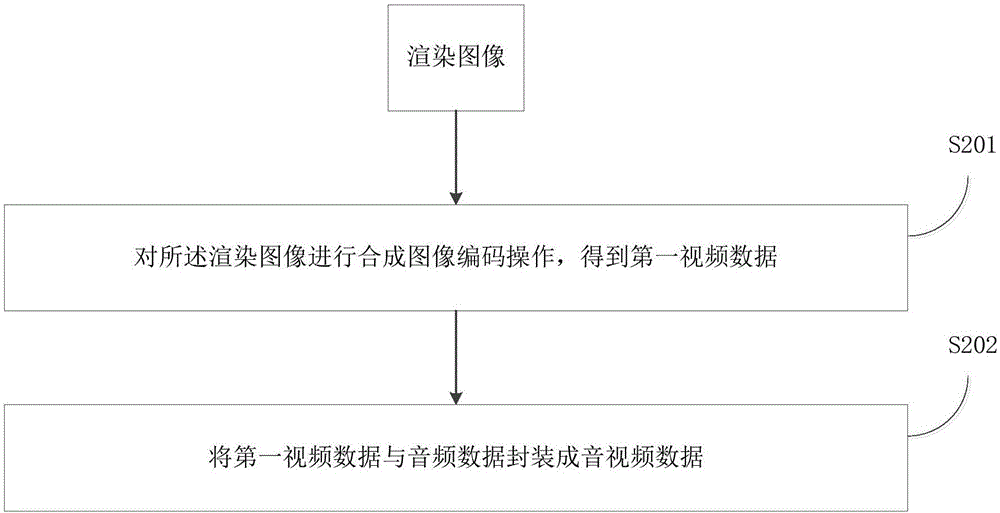
请参阅图2,在一些实施例中,在得到渲染图像之后还包括步骤:
S201、对所述渲染图像进行合成图像编码操作,得到第一视频数据;
S202、以及将第一视频数据与音频数据封装成音视频数据,其中,所述音频数据是在获取摄像装置数据的同时,通过音效器实时获取的。
其中,所述对所述渲染图像进行合成图像编码操作,包括步骤:
通过安卓、ios或windows等设备自带的硬件编码模块截取所述渲染图像,以及对所截取的渲染图像进行压缩编码。
而在获取所述音频数据时,音效器获取音频数据,并将音频数据编码成便于网络传输的音频格式。在一些直播应用的实施例中,所述音频数据主要为直播者演唱的声音及歌曲伴奏的混合声音。
在上述实施例中,所述合成图像编码操作、获取音频数据以及封装操作是由不同的设备分别完成,从而保证数据处理的速率与实时性。而在一些实施例中,上述合成图像编码操作、获取音频数据以及封装操作也可在同一服务器上完成。
封装所得到的音视频数据即可用于网络直播、显示或存储。其中,网络直播是将封装好的音视频数据传送给实时数据流服务器(即RTSP服务器),由实时数据流服务器在局域网内直播或互联网外直播。
在局域网内直播时,实时数据流服务器检测是否有客户端连接于该服务器,以及是否有播放请求,在检测到有客户端连接,并接收到播放请求时,通过实时流传输协议,将所述音视频数据发送给局域网在线客户端。所述客户端可以是各种支持RTSP的播放器,如PC机、平板电脑、智能手机等。客户端在接收到实时流服务器传来的音视频数据后,进行解码即可进行播放,播放的内容即为直播对象与虚拟场景相结合渲染的画面;音视频数据中的音频数据解码后,通过扬声器播放即为演唱者演唱的声音及伴奏。
在互联网直播时,实时数据流服务器通过实时流传输协议,将所述音视频数据发送给第三方网络服务器,由第三方网络服务器生成所述音视频数据的直播链接。客户端通过点击所述直播链接,即可获取所述音视频数据的实时数据流,并通过解码播放。
在一些实施例中,客户端还可通过计算机网络发送互动指令与主播进行虚拟场景互动。主播端接收到客户端发送的互动指令时,可根据互动指令更新或切换虚拟场景,并在渲染阶段对新的虚拟场景与第一对象进行渲染。其中,所述计算机网络可以是Internet网络也可以是局域网,可以是由有线网络、WiFi网络、3G/4G移动通讯网络、蓝牙网络或ZigBee网络等进行连接。
在不同虚拟场景中互动的实施例中,互动指令可以包括不同的内容,在某些实施例中,所述互动指令包括将第一素材更新到虚拟场景中的命令。具体为:在将第一对象实时更新到虚拟场景的同时,根据所述互动指令,将第一素材也更新到虚拟场景中,并对美颜后的第一对象及所述虚拟场景进行渲染,得到渲染图像。
所述第一素材可以为图像素材、声音素材或者图像素材与声音素材的结合。以网络直播为例,所述第一素材包括有虚拟礼物、点赞、背景音、喝彩等,网络直播的观众可通过移动手机,向主播送鲜花等虚拟礼物的互动指令,所送的礼物将以鲜花图片的形式在虚拟场景中体现出来。网络直播的观众还可以通过移动手机,向主播发送鼓掌的互动指令,鼓掌的互动指令将以掌声的形式进行播放。
这些第一素材可以是系统预置的,供给用户选择使用,而在某些实施例中,所述互动指令除了包括将第一素材更新到虚拟场景中的命令,还可包括了第一素材的内容数据。例如观众在通过移动终端上传一个赠送虚拟礼物的互动指令,以及在互动指令中还包含了一张所赠送虚拟礼物的图片,在接收到所述互动指令后,将所述礼物的图片更新至虚拟场景中。因此观众在发送互动指令时,除了可以选择互动的方式,还可以根据自己的喜好自定义第一素材的内容数据,如喜欢的图片素材、声音素材或图片与声音结合的素材。
在一些实施例中,所述互动指令还包括变换虚拟场景镜头的命令,所述变换虚拟场景镜头的命令包括有切换虚拟场景镜头的视角,改变虚拟场景镜头焦距以及对虚拟场景进行局部模糊处理等。通过切换虚拟场景镜头的视角,可以模拟从不同视角观看虚拟场景的画面;通过改变虚拟场景镜头焦距,可对拉近和推远虚拟场景的画面;而对对虚拟场景进行局部模糊处理,可使虚拟场景中未模糊处理部分画面被突出显示。通过所述变换虚拟场景镜头的命令,可大大提高观众的互动程度和趣味性。
上述虚拟场景互动的实施例中,可以根据客户端发送的互动指令,对虚拟场景进行更新或切换,以实现在得到的渲染图像中既具有丰富多彩的场景变化效果,又同时保存有第一对象的实时活动效果。上述技术方案中观众可通过客户端发送互动指令,在主播端将互动的内容与第一对象更新至虚拟场景中,使互动内容、主播对象以及虚拟场景融合在一起,因此各第一终端均可看到互动的效果,其中互动的内容是在主播端就融合至虚拟场景中,因此,各观众的客户端无需从服务器下载互动素材,从而便于互动内容的扩展。
请参阅图3,另一实施例为一种对虚拟场景直播进行美颜处理的系统,该虚拟场景直播进行美颜处理的系统可用于通过网络进行真人与虚拟场景相结合的视频直播节目,该系统包括:
解析单元10,用于实时获取摄像装置的数据,得到第一图像数据。对所述摄像装置的数据进行解码,并在每获得到一帧完整的解码图像数据时,将图像数据放至数据缓冲区中。在某些实施例中,使用FFMPEG+mediacodec的组合对摄像装置的实时数据流进行读取、解码、并实时更新到缓冲区中。FFMPEG+mediacodec是android平台下实现硬编码硬解码的类,能明显提升数据流编解码的速度。
更新单元20,用于将第一图像数据转换成纹理图像,并将所述纹理图像更新至虚拟场景中。在实施例中,将所述纹理图像更新至虚拟场景中,可以是将纹理图像以纹理的形式体现在虚拟场景的一个平面中。更进一步的,实施例还可以结合新近发展的3D图像技术来提供虚拟场景,例如3D虚拟现实场景或3D视频场景。
渲染单元30,用于通过GPU从纹理图像中识别出第一对象,将纹理图像除第一对象外的剩余部分透明化,然后对第一对象进行美颜处理,再对美颜后的第一对象及所述虚拟场景进行渲染,得到渲染图像。其中,第一对象为摄像装置所拍摄的图像中的对象。在不同的实施例中根据需要,第一对象可以是不同的具体对象,例如第一对象可以是真人主播,可以是宠物动物等;第一对象的数量可以是单个,也可以是2个以上。所述对第一对象进行美颜处理可以包括皮肤磨皮处理、脸部去斑处理和加亮处理。
在实施例中,将摄像装置的数据转换成纹理图像,并将纹理图像更新至虚拟场景中,然后在虚拟场景渲染阶段;所述第一对象的提取与美颜,都是在图像渲染阶段通过GPU并行执行的,由于GPU是专门对图像进行处理的硬件,对不同大小的像素运算时间一样,不仅不占用CPU时间,而且可大大节省了对像素的运算时间,从而有效降低了虚拟场景直播时美颜处理的延迟时间。
请参阅图4,在一些实施例中,对虚拟场景直播进行美颜处理的系统还包括:
合成图像编码单元40,用于对所述渲染图像进行合成图像编码操作,得到第一视频数据;以及
封装单元50,用于获取摄像装置数据的同时,实时获取传声器的数据,将声效器的数据与第一视频数据封装成音视频数据。
合成图像编码单元通过合成图像编码服务器的硬件编码模块截取所述渲染图像,以及对所截取的渲染图像进行压缩编码。
而在获取所述音频数据时,音效器获取音频数据,并将音频数据编码成便于网络传输的音频格式。在一些直播应用的实施例中,所述音频数据主要为直播者演唱的声音及歌曲伴奏的混合声音。
在上述实施例中,所述合成图像编码操作、获取音频数据以及封装操作是由不同的设备分别完成,从而保证数据处理的速率与实时性。而在一些实施例中,上述合成图像编码操作、获取音频数据以及封装操作也可在同一服务器上完成。
对虚拟场景直播进行美颜处理的系统还包括传输单元,用于通过实时流传输协议,在局域网内直播或互联网外直播。
在局域网内直播时,实时数据流服务器检测是否有客户端连接于该服务器,以及是否有播放请求,在检测到有客户端连接,并接收到播放请求时,通过实时流传输协议,将所述音视频数据发送给局域网中在线客户端。客户端在接收到实时流服务器传来的音视频数据后,进行解码即可进行播放,播放的内容即为直播对象与虚拟场景相结合渲染的画面;音视频数据中的音频数据解码后,通过扬声器播放即为演唱者演唱的声音及伴奏。
在互联网直播时,,实时数据流服务器通过实时流传输协议,将所述音视频数据发送给第三方网络服务器,由第三方网络服务器生成所述音视频数据的互联网直播链接。客户端通过点击所述链接,即可获取所述音视频数据的实时数据流,并通过解码播放。
在一些实施例中,所述对虚拟场景直播进行美颜处理的系统还包括互动单元,用于接收客户端发送的互动指令,从及根据互动指令更新或切换虚拟场景。因此客户端可通过计算机网络发送互动指令与主播进行虚拟场景互动。主播端接收到客户端发送的互动指令时,可根据互动指令更新或切换虚拟场景,并在渲染阶段对新的虚拟场景与第一对象进行渲染。其中,所述计算机网络可以是Internet网络也可以是局域网,可以是由有线网络、WiFi网络、3G/4G移动通讯网络、蓝牙网络或ZigBee网络等进行连接。
在不同虚拟场景中互动的实施例中,互动指令可以包括不同的内容,在某些实施例中,所述互动指令包括将第一素材更新到虚拟场景中的命令。具体为:在将第一对象实时更新到虚拟场景的同时,根据所述互动指令,将第一素材也更新到虚拟场景中,并对美颜后的第一对象及所述虚拟场景进行渲染,得到渲染图像。
所述第一素材可以为图像素材、声音素材或者图像素材与声音素材的结合。以网络直播为例,所述第一素材包括有虚拟礼物、点赞、背景音、喝彩等,网络直播的观众可通过移动手机,向主播送鲜花等虚拟礼物的互动指令,所送的礼物将以鲜花图片的形式在虚拟场景中体现出来。网络直播的观众还可以通过移动手机,向主播发送鼓掌的互动指令,鼓掌的互动指令将以掌声的形式进行播放。
这些第一素材可以是系统预置的,供给用户选择使用,而在某些实施例中,所述互动指令除了包括将第一素材更新到虚拟场景中的命令,还可包括了第一素材的内容数据。例如观众在通过移动终端上传一个赠送虚拟礼物的互动指令,以及在互动指令中还包含了一张所赠送虚拟礼物的图片,在接收到所述互动指令后,将所述礼物的图片更新至虚拟场景中。因此观众在发送互动指令时,除了可以选择互动的方式,还可以根据自己的喜好自定义第一素材的内容数据,如喜欢的图片素材、声音素材或图片与声音结合的素材。
在一些实施例中,所述互动指令还包括变换虚拟场景镜头的命令,所述变换虚拟场景镜头的命令包括有切换虚拟场景镜头的视角,改变虚拟场景镜头焦距以及对虚拟场景进行局部模糊处理等。通过切换虚拟场景镜头的视角,可以模拟从不同视角观看虚拟场景的画面;通过改变虚拟场景镜头焦距,可对拉近和推远虚拟场景的画面;而对对虚拟场景进行局部模糊处理,可使虚拟场景中未模糊处理部分画面被突出显示。通过所述变换虚拟场景镜头的命令,可大大提高观众的互动程度和趣味性。
上述虚拟场景互动的实施例中,可以根据客户端发送的互动指令,对虚拟场景进行更新或切换,以实现在得到的渲染图像中既具有丰富多彩的场景变化效果,又同时保存有第一对象的实时活动效果。上述技术方案中观众可通过客户端发送互动指令,在主播端将互动的内容与第一对象更新至虚拟场景中,使互动内容、主播对象以及虚拟场景融合在一起,因此各第一终端均可看到互动的效果,其中互动的内容是在主播端就融合至虚拟场景中,因此,各观众的客户端无需从服务器下载互动素材,从而便于互动内容的扩展。
请参阅图5,为一实施例中网络虚拟场景直播系统的示意图,该网络虚拟场景直播系统可对直播对象进行美颜处理,并进行实时直播,该系统包括有摄像装置501、声效器502、视频解码器503、Unity端504、录制服务器505、RTSP服务器506、第三方服务器508和客户端507。
其中,摄像装置501用于获取直播对象的视频数据。
声效器502用于获取直播对象的音频数据。
所述视频解码器503用于对摄像装置501所获取的视频数据进行解码,并在每获取一帧完整的图像数据(YCrCb格式)时,将图像数据放到解码器的缓冲区中;所述视频解码器503还用于将解码得到的图像数据,转换成纹理贴图,并传递给Unity端504。其中,视频解码器503使用FFMPEG+mediacodec(android平台下实现硬编码硬解码的类)的组合对网络摄像头的视频数据流进行读取、解码、并实时更新到缓冲区中,从而明显提升编解码速度。视频解码器503使用GLES来给摄像头数据生成纹理贴图。其中,所述GLES即为OpenGL ES(英文全称为:OpenGL for Embedded Systems),是OpenGL三维图形API的子集,是针对手机、PDA和游戏主机等嵌入式设备而设计,GLES2.0是GLES的一个版本。
Unity端504集成为GPU,并安装有Unity3D软件,Unity3D软件是由Unity Technologies开发的一个让玩家轻松创建诸如三维视频游戏、建筑可视化、实时三维动画等类型互动内容的多平台的综合型游戏开发工具,是一个全面整合的专业游戏引擎。Unity类似于Director,Blender game engine,Virtools或Torque Game Builder等利用交互的图型化开发环境为首要方式的软件。
Unity端504将纹理贴图以纹理的形式体现在虚拟场景的一个平面中,之后,Unity端504的GPU还用于对虚拟场景进行渲染,在渲染阶段,对图像数据中的直播对象进行抠图和美颜,从而得到包括有直播对象和虚拟场景的渲染图像。
抠图将直播对象和背景分离,使背景部分不显示,抠图时预设一个像素参考点作为抠图的基准颜色,并设置抠图阈值上下限。对图像逐像素进行比较运算,得出当前像素与预设像素的差异量。当差异量小于阈值下限,则认为该像素点是背景色,并将该像素的alpha通道置为0,使其为透明;当差异量大于阈值上限,这时候认为该像素点是前景色,alpha通道置为1,使其保留下来;当差异量介于上限和下限之间,认为该像素是过渡色,使用线性函数将alpha通道设置为0~1中的一个,使该像素一半出现在图像边缘处。过渡色的设定有利于抠出来的人像和虚拟场景融合的更自然。
美颜时先对对象(主要是人物对象)进行肤色识别,肤色识别是利用人类皮肤在YCbCr颜色空间的呈现高斯分布的特点,将皮肤和非皮肤区域区分开来。肤色识别之后对皮肤进行磨皮,磨皮是使用双边滤波算法,在平滑皮肤区域的同时避免边缘钝化。然后是去除斑点和加亮处理,加亮处理是采用LOG曲线进行整体像素的增益校正,避免图像变化过于生硬。以上抠图和美颜操作均通过GPU的渲染步骤(shader步骤)实现的。
录制服务器505用于使用硬件编码模块,对Unity端504的屏幕画面进行截取、压缩编码,得到视频数据;以及用于将声效器的音频数据编码成便于网络传输的音频格式。最后录制服务器505还用于对所述音频数据和视频数据后进行封装,封装好的数据即为可供播放的音视频数据,录制服务器505将封装好的数据传递给RTSP服务器506。
RTSP服务器506即为实时流服务器,用于音视频数据的直播,直播分为内网直播和外网直播两种方式,在本实施例中,RTSP服务器506将音视频数据推送到第三方服务器508中,第三方服务器508生成外网链接供各地网络客户端507点播。客户端在接收到第三方服务器传来的音视频数据后,解码即可显示画面,画面内容即为虚拟场景渲染的画面;音频数据解码后通过扬声器播放即为演唱者演唱的声音及伴奏。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括……”或“包含……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
本领域内的技术人员应明白,上述各实施例可提供为方法、装置、或计算机程序产品。这些实施例可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。上述各实施例涉及的方法中的全部或部分步骤可以通过程序来指令相关的硬件来完成,所述的程序可以存储于计算机设备可读取的存储介质中,用于执行上述各实施例方法所述的全部或部分步骤。所述计算机设备,包括但不限于:个人计算机、服务器、通用计算机、专用计算机、网络设备、嵌入式设备、可编程设备、智能移动终端、智能家居设备、穿戴式智能设备、车载智能设备等;所述的存储介质,包括但不限于:RAM、ROM、磁碟、磁带、光盘、闪存、U盘、移动硬盘、存储卡、记忆棒、网络服务器存储、网络云存储等。
上述各实施例是参照根据实施例所述的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到计算机设备的处理器以产生一个机器,使得通过计算机设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机设备以特定方式工作的计算机设备可读存储器中,使得存储在该计算机设备可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机设备上,使得在计算机设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已经对上述各实施例进行了描述,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改,所以以上所述仅为本发明的实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!