一种切换耳机工作模式方法和一种耳机与流程
本发明涉及计算机控制领域领域,具体涉及一种切换耳机工作模式的方法和耳机。
背景技术:
目前,主动降噪耳机凭借着隔绝外部噪音的优势得到了广大用户的青睐。但是其在实际应用中依旧存在以下缺点:
(一)通过检测环境噪音来控制耳机进入主动降噪模式,误识别率高,极易将有用的信息过滤掉,降低用户体验。
(二)由于其隔音效果好,当需要听取外界信息时或其他需求时,用户只能手动将主动降噪开关关掉或取下耳机,过程比较繁琐。
(三)只能对主动降噪模式和正常模式进行切换,功能模式单一,适用范围有限,无法满足多种环境需求,操作不够便捷。
技术实现要素:
本发明提供了一种切换耳机工作模式方法和耳机,以解决现有的主动降噪耳机功能模式单一、误识别率高、操作不便和用户体验低问题。
根据本发明的一个方面,提供了一种切换耳机工作模式方法,所述耳机包括麦克风和反馈式降噪模组,所述方法包括:
实时获取用户的头部姿态数据和人体生理信息;
将获取到的所述头部姿态数据和所述人体生理信息与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配;判断所述头部姿态数据和所述人体生理信息是否与所述映射表中的耳机工作模式同时匹配,若是,则切换耳机工作模式;若否,则不切换耳机工作模式。。
根据本发明的另一个方面,提供了一种耳机,所述耳机包括麦克风和反馈式降噪模组,所述耳机包括:
存储器,用于保存头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表;
人体传感器,用于实时获取用户的人体生理信息,并将所述人体生理信息发送至所述处理器;
动作传感器,用于实时获取用户的头部姿态数据,并将所述头部姿态数据发送至所述处理器;
处理器,用于将获取到的所述头部姿态数据和所述人体生理信息与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配;判断所述头部姿态数据和所述人体生理信息是否与所述映射表中的耳机工作模式同时匹配,若是,则切换耳机工作模式;若否,则不切换耳机工作模式。
本发明的有益效果是:本发明的技术方案,通过实时获取头部姿态数据和人体生理信息,并将头部姿态数据和人体生理信息与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配;若头部姿态数据和人体生理信息与所述映射表中的耳机工作模式同时匹配,则进行耳机模式切换,否则不进行模式切换,实现了根据用户的使用意向自动切换至合适的耳机模式,解决现有的主动降噪耳机功能模式单一、误识别率高、操作不便的问题,增加了使用的舒适度,提升了用户体验。
附图说明
图1是本发明一个实施例的一种切换耳机工作模式方法的流程图;
图2是本发明一个实施例的一种耳机的结构示意图;
图3是本发明一个实施例的另一种耳机的结构示意图;
图4是本发明一个实施例的再一种耳机的结构示意图。
具体实施方式
本发明的设计构思是:为了解决现有的主动降噪耳机功能模式单一、误识别率高、操作不便和用户体验低问题,利用人体传感器采集人体的生理信息,同时利用动作传感器采集头部姿态数据,将获取到的生理信息和头部姿态数据与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配,当头部姿态数据和人体生理信息同时与所述映射表中的耳机工作模式匹配时,进行模式切换,否则,不进行模式切换。
实施例一
图1是本发明一个实施例的一种切换耳机工作模式方法的流程图,如图1所示,所述方法包括:
在步骤s110中,实时获取用户的头部姿态数据和人体生理信息。
在步骤s120中,将获取到的所述头部姿态数据和所述人体生理信息与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配;判断所述头部姿态数据和所述人体生理信息是否与所述映射表中的耳机工作模式同时匹配,若是,则切换耳机工作模式;若否,则不切换耳机工作模式。
需要说明的是,人体生理信息包括心率信号数据、呼吸频率数据或者血压数据等。以人体生理信息包括心率信号数据为例。部分映射表如下表所示:
表1.头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的部分映射表
由此可知,本发明的技术方案,通过实时获取头部姿态数据和人体生理信息,并将头部姿态数据和人体生理信息与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配;若头部姿态数据和人体生理信息是否与所述映射表中的耳机工作模式同时匹配,则进行耳机模式切换,否则不进行模式切换,实现了根据用户的使用意向自动切换至合适的耳机模式,解决现有的主动降噪耳机功能模式单一、误识别率高、操作不便的问题,增加了使用的舒适度,提升了用户体验。
在本发明的一个实施例中,图1所示的方法还包括:
接受来自外部的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表,并根据所述映射表更新原头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表。实时更新的映射表是基于机器学习理论得到的,实时更新映射表的目的在于降低耳机工作模式的误识别率,进一步提升用户体验。
在本发明的一个实施例中,所述切换耳机工作模式包括:
读取与所述头部姿态数据和人体生理信息同时匹配的耳机工作模式控制指令,并将所述耳机工作模式控制指令发送至所述麦克风和所述反馈式降噪模组,控制所述麦克风和所述反馈式降噪模组进行相应模式下的操作,实现不同耳机工作模式的智能切换,提升用户体验。
在本发明的一个实施例中,所述控制所述麦克风和所述反馈式降噪模组进行相应模式下的操作包括:
控制麦克风和反馈式降噪模组均关闭,也就是说麦克风和反馈式降噪模组都不使用,进入第一模式,可以将第一种模式命名为睡眠模式;例如,当检测到用户头部处于平躺,并保持一定时间内(1小时)不动,同时人体传感器检测到用户在一段时间内心率保持在静息心率的范围(因个人静息心率差异,耳机会有初始化检测、设定静息心率的过程),则将耳机切换至睡眠模式;
或者,控制麦克风关闭,控制反馈式降噪模组开启,并控制反馈式降噪模组对播放的音频信号进行优化处理,进入第二模式,可以将第二种模式命名为正常模式,例如,在听歌或者观看视频时切换至正常模式;
或者,控制麦克风和反馈式降噪模组均开启,控制麦克风拾取外界的声音信号,将所述声音信号进行反相处理,并控制反馈式降噪模组将所述反相处理后的声音信号与播放的音频信号进行融合处理,进入第三种模式,可以将第三种模式命名为主动降噪模式;例如,如当用户阅读时,动作传感器检测到头部由由平视变为向下转动30°-60°之间,并保持5-6秒不变,同时人体传感器检测到用户在一段时间内心率保持在静息心率的范围(因个人静息心率差异,智能耳机会有初始化检测、设定静息心率的过程),处理器将检测到的信号与外储存器中的数据比对,发现与一组数据相同,该组数据指向主动降噪模式,则麦克风与扬声器同时开启,启动主动降噪模式;
或者,控制反馈式降噪模组仅对所述反相处理后的声音信号进行优化处理,进入第四种模式,可以将第四种模式命名为耳塞模式;
或者,控制反馈式降噪模组仅对所述放大处理后的声音信号进行优化处理,进入第五种模式,可以将第五种模式命名为通话模式;在实际应用中,关于增强外界人声功能,可以通过软件方面解决,如pc端通过软件adobeaudition可以直接实现人声增强。需要说明的是,adobeaudition是一个专业音频编辑和混合环境。
实施例二
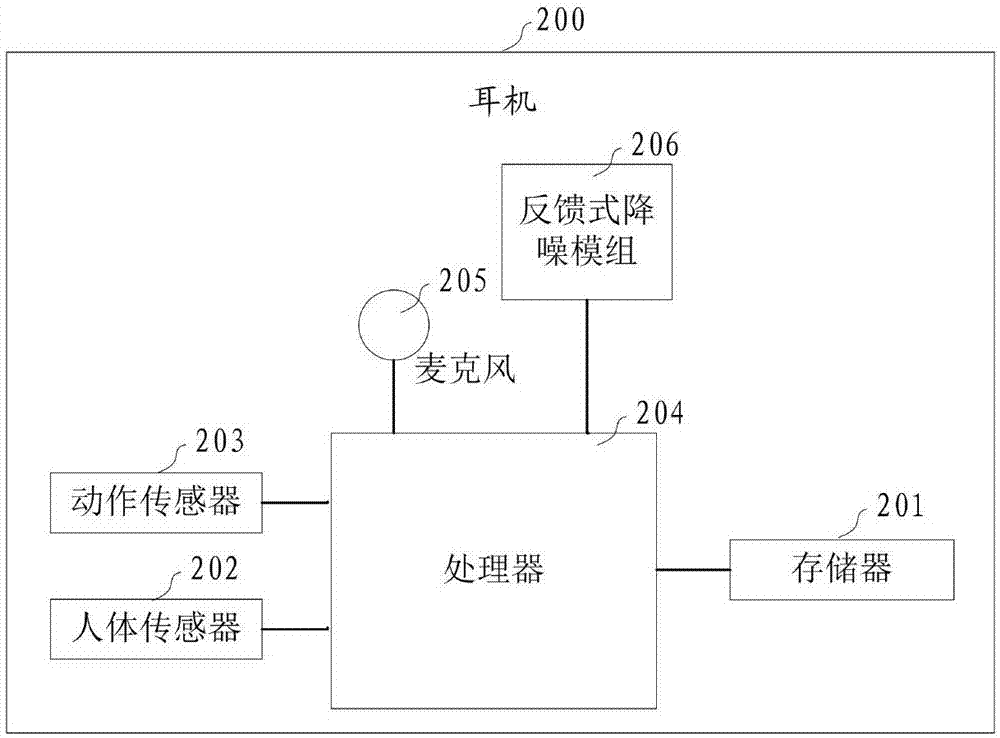
图2是本发明一个实施例的一种耳机的结构示意图,如图2所示,一种耳机,所述耳机包括麦克风205和反馈式降噪模组206,所述耳机包括:
存储器201,用于保存头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表;
人体传感器202,用于实时获取用户的人体生理信息,并将所述人体生理信息发送至所述处理器204;
动作传感器203,用于实时获取用户的头部姿态数据,并将所述头部姿态数据发送至所述处理器204;
处理器204,用于将获取到的所述头部姿态数据和所述人体生理信息与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配;判断所述头部姿态数据和所述人体生理信息是否与所述映射表中的耳机工作模式同时匹配,若是,则切换耳机工作模式;若否,则不切换耳机工作模式。
由此可知,本发明的技术方案,通过实时获取头部姿态数据和人体生理信息,并将头部姿态数据和人体生理信息与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配;若头部姿态数据和人体生理信息是否与所述映射表中的耳机工作模式同时匹配,则进行耳机模式切换,否则不进行模式切换,实现了根据用户的使用意向自动切换至合适的耳机模式,解决现有的主动降噪耳机功能模式单一、误识别率高、操作不便的问题,增加了使用的舒适度,提升了用户体验。
图3是本发明一个实施例的另一种耳机的结构示意图,如图3所示,在本发明的一个实施例中,所述耳机还包括无线通信模块207;
所述无线通信模块207,用于接受来自外部的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表,并将所述映射表发送至所述处理器204;
所述处理器204,还用于根据来自所述无线通信模块21的映射表更新存储器201中的原头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表。
需要说明的是,无线通信模块207可以接收智能设备212、移动终端或者pc机发送的映射表。实时更新的映射表是基于机器学习理论得到的,实时更新映射表的目的在于降低耳机工作模式的误识别率,进一步提升用户体验。
在本发明的一个实施例中,所述处理器204,具体用于读取与所述头部姿态数据和人体生理信息同时匹配的耳机工作模式控制指令,并将所述耳机工作模式控制指令发送至麦克风205和反馈式降噪模组206,控制所述麦克风205和所述反馈式降噪模组206进行相应模式下的操作;
所述麦克风205和所述反馈式降噪模组206,用于根据所述耳机工作模式控制指令进行相应模式下的操作。
在本发明的一个实施例中,所述处理器204,还具体用于控制麦克风205和反馈式降噪模组206均关闭,进入第一模式;
或者,所述处理器204,还具体用于控制麦克风205关闭,控制反馈式降噪模组206开启,并控制反馈式降噪模组206对播放的音频信号进行优化处理,进入第二模式;
或者,所述处理器204,还具体用于控制麦克风205和反馈式降噪模组206均开启,控制麦克风205拾取外界的声音信号,将所述声音信号进行反相处理,并控制反馈式降噪模组206将所述反相处理后的声音信号与播放的音频信号进行融合处理,进入第三模式;
或者,所述处理器204,还具体用于控制麦克风205和反馈式降噪模组206均开启,控制麦克风205拾取外界的声音信号,将所述声音信号进行反相处理,控制反馈式降噪模组206仅对所述反相处理后的声音信号进行优化处理,进入第四种模式;
或者,所述处理器204,还具体用于控制麦克风205和反馈式降噪模组206均开启,控制麦克风205拾取外界的声音信号,将所述声音信号进行放大处理,控制反馈式降噪模组206仅对所述放大处理后的声音信号进行优化处理。
在本发明的一个实施例中,所述人体传感器单元202包括心率传感器、呼吸频率传感器和血压传感器;
所述心率传感器,用于检测用户的心率信号数据,并将所述心率信号数据传送至所述处理器204;
所述呼吸频率传感器,用于检测用户的呼吸频率数据,并将所述呼吸频率数据发送至所述处理器204。
所述血压传感器,用于检测用户的血压数据,并将所述血压数据发送至所述处理器204。
在本发明的一个实施例中,所述动作传感器203包括mems传感器、陀螺仪或者惯性测量单元。
在本发明的一个实施例中,仍如图3所示,所述耳机还包括电磁传感器208、电源控制模块209和电池210,所述电磁传感器208,用于检测无线充电盒,并将检测到所述无线充电盒的信息发送至电源控制模块209;
电源控制模块209,用于接收来自电磁传感器208的检测到所述无线充电盒的信息,并根据所述信息控制电池210接收来自所述无线充电盒的电量。
为了使本发明的技术方案更加清晰,下面举一个具体的例子进行解释。当用户阅读时,动作传感器检测到头部由由平视变为向下转动30°-60°之间,并保持5-6秒不变,同时人体传感器检测到用户在一段时间内心率保持在静息心率的范围(因个人静息心率差异,智能耳机会有初始化检测、设定静息心率的过程),这些信息传输到处理器中。处理器对收到信息进行模式匹配,判断出用户要选择的模式为主动降噪模式,然后控制麦克风拾取外界噪音。噪音经过模/数转换后被传输到处理器中的数字信号处理模块dsp中进行处理,得到一个与原噪声信号反相的信号,再将它进行数/模转换,然后输入到反馈式降噪模组中。反馈式降噪模组将接收到的反相信号和要播放的音频信号做处理,经过加法器实现两个信号的混合叠加,通过均衡器对各个频段做增益优化,得到一个混合的音频信号,并将其输入到扬声器中。扬声器播放出的声音信号与环境中的噪音信号叠加后,消除了环境噪音,实现主动降噪。
同样,人体传感器和动作传感器也可以捕捉到其他的姿态信息,然后由处理器进行判断识别。如当处理器判断出用户要使用正常模式时,可以控制关闭麦克风,不拾取噪音,降噪模块只对要播放的音频信号做优化,然后输入到扬声器。当处理器判断出用户要使用耳塞模式时,可以控制打开麦克风,拾取噪音,并输入到处理器中的数字信号处理模块dsp中进行处理,得到与原噪声信号反相的信号,然后输入到反馈式降噪模组中,降噪模块只接收该反相信号并做优化,然后输入到扬声器。当处理器判断出用户要使用通话模式时,可以控制打开麦克风,拾取外界语音信号,并输入到处理器中的数字信号处理模块dsp中进行放大处理(不做反相运算),然后输入到反馈式降噪模组中,降噪模块只接收该信号并做优化,然后输入到扬声器。当处理器判断出用户要使用睡眠模式时,可以控制关闭麦克风,不拾取噪音,降噪模块也不接收音频信号,同时使扬声器处于关闭状态。
实施例三
耳机还包括壳体、耳塞和电路板;壳体上对应扬声器和麦克205所在位置设置有开孔;
人体传感器单元202、动作传感器203、存储器201、处理器204、反馈式降噪模组206、无线通信模块207、电磁传感器208和电源控制模块209设置在电路板pcba上。
综上所述,本发明的技术方案,通过实时获取头部姿态数据和人体生理信息,并将头部姿态数据和人体生理信息与预存的头部姿态数据、人体生理信息与不同耳机工作模式控制指令对应的映射表进行匹配;若头部姿态数据和人体生理信息是否与所述映射表中的耳机工作模式同时匹配,则进行耳机模式切换,否则不进行模式切换,实现了根据用户的使用意向自动切换至合适的耳机模式,解决现有的主动降噪耳机功能模式单一、误识别率高、操作不便的问题,增加了使用的舒适度,提升了用户体验。
以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!