行车记录拍摄方法及装置与流程
本发明涉及行车记录仪领域,尤其涉及一种行车记录拍摄方法及装置。
背景技术:
行车记录仪能够作为交通事故责任认定证据,有效维护自身权益,是很多车主购买行车记录仪的重要原因。然而根据交通法规定,只有原始、完整、无剪辑的行车记录仪视频才能作为有效证据,如果出现漏秒、丢帧等影响视频完整度、原始性的录像,让关键时间取证困难。
由于存储空间有限,现有的行车记录仪通常采用分段录制的方法,以在存储空间不足时删除最早录制的视频,才能继续进行当前的视频录制。每段视频的录制时间通常在5分钟以内,一段视频录制结束后进行储存,并开始下一段视频的录制。
由于现有行车记录仪当一段视频录制完毕时摄像头和麦克风被关闭,当下一段视频开始录制时再重新启动摄像头和麦克风,而摄像头由关闭到开启这段时间内无法进行录制,导致相邻两段视频的过渡处产生漏秒、或丢帧,通常漏秒达到2秒以上,影响行车记录仪视频拍摄的完整性。
技术实现要素:
本发明提供一种行车记录拍摄方法及装置,以优化行车记录仪漏秒、或丢帧状况,保证行车记录仪视频拍摄的完整性。
本发明的一个方面是提供一种行车记录拍摄方法包括:
接收摄像头连续采集的视频帧;
分段提取所述视频帧,生成预定时长的视频,并通过麦克风提取与每段视频对应的音频;
将提取的每段视频和音频合并形成行车记录文件。
本发明的另一个方面是提供一种行车记录拍摄装置,包括:
接收模块,用于接收摄像头连续采集的视频帧;
视频生成模块,用于分段提取所述视频帧,生成预定时长的视频;
音频生成模块,用于通过麦克风提取与每段视频对应的音频;
合成模块,用于将提取的每段视频和音频合并形成行车记录文件。
本发明提供的行车记录拍摄方法及装置,通过接收摄像头连续采集的视频帧,并分段提取所述视频帧,生成预定时长的视频,并通过麦克风提取与每段视频对应的音频,最后将提取的每段视频和音频合并形成行车记录文件。本发明的行车记录拍摄方法,在提取视频帧生成预定时长的视频时并不影响接收摄像头连续采集的视频帧以及将采集的视频帧存储于缓存或内存的线程,因此并不需要将摄像头进行关闭,从而保证了视频的连续性,优化行车记录仪漏秒、或丢帧状况,保证行车记录仪视频拍摄的完整性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一实施例提供的行车记录拍摄方法流程图;
图2为本发明另一实施例提供的行车记录拍摄方法流程图;
图3为本发明一实施例提供的行车记录拍摄装置的结构图;
图4为本发明另一实施例提供的行车记录拍摄装置的结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
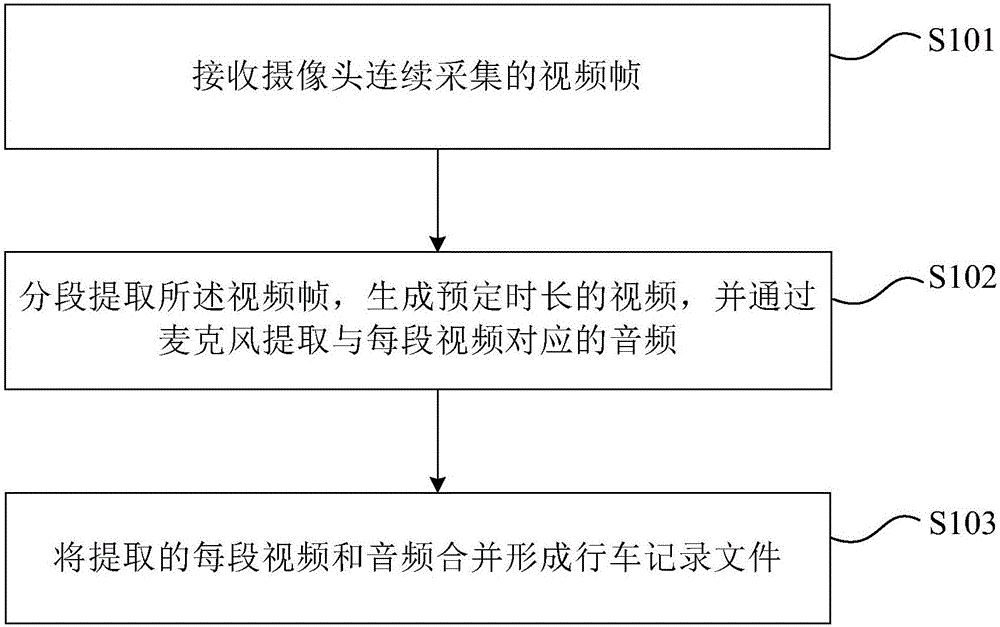
图1为本发明一实施例提供的行车记录拍摄方法流程图。如图1所示,本实施例提供了一种行车记录拍摄方法,该方法具体步骤如下:
s101、接收摄像头连续采集的视频帧。
在本实施例中,通过摄像头连续采集视频帧,即整个录制过程中摄像头并不关闭,其中获取到的视频帧存于行车记录仪的缓存中或者指定的一段内存中。
s102、分段提取所述视频帧,生成预定时长的视频,并通过麦克风提取与每段视频对应的音频。
本实施例中,从存储视频帧的缓存或内存中提取视频帧,分段生成预定时长的视频,由于提取视频帧生成预定时长的视频时并不影响接收摄像头连续采集的视频帧以及将采集的视频帧存储于缓存或内存的线程,因此并不需要将摄像头进行关闭。此外,在提取音频时也不需要关闭麦克风,并且麦克风提取的音频与视频相对应,从而也保证了声音的同步性。
更具体的,所述分段提取所述视频帧,生成预定时长的视频,采用以下两种方案实现:
方案一:采用glsurfaceview实时提取所述视频帧,并进行编码,在到达每段所述预定时长时对编码后的该段视频进行存储;
在本方案中,采用glsurfaceview进行实时提取视频帧,其中,glsurfaceview为android系统中的一个视图类,是surfaceview的子类,其中surfaceview类是view类的子类,它包含一个能保存屏幕像素信息的surface对象,surface对象在物理上对应着一块内存,它的内容可以直接被复制到显存,因此更新速度快。surfaceview的特点是可以直接访问内存上的图像数据,提高内存效率;可以用后台线程来更新屏幕图像,避免因主线程繁忙而造成阻塞;可以控制图像更新速度(帧频),提高用户体验。可以通过它看见surface的全部或部分内容,也可以通过它在surface上绘制图形。而glsurfaceview是基于surfaceview再次进行拓展的视图类,可以做到数据和显示的分离,比如在没有屏幕的设备照样可以开预览实时直播。本实施例中通过glsurfaceview实时提取所述视频帧。当然也可采用其他视频捕捉器获取视频帧。本实施例中在提取视频帧后,并进行编码,其中视频编码可采用现有技术中的编码技术,例如h.264编码技术,将提取的视频帧压缩成为视频码流,从而降低视频的数据量。本方案采用glsurfaceview实时提取所述视频帧,其存储视频帧的缓存或内存可以较小,节约更多的存储空间。
方案二:在到达每段所述预定时长时,采用glsurfaceview对该段预定时长内的视频帧进行提取和编码,生成该段预定时长对应的所述视频。
在本实施例中,摄像头连续采集的视频帧存贮在缓存或内存中,当到达每段所述预定时长时,采用glsurfaceview对该段预定时长内的视频帧进行一次提取,再进行编码。本方案在每段预定时长结束后由glsurfaceview提取视频帧,不会造成主线程的阻塞。
需要说明的是,本实施例中也需要对音频进行编码,将音频采样数据压缩成为音频码流,从而降低音频的数据量。
s103、将提取的每段视频和音频合并形成行车记录文件。
本发明实施例,将相对应的每段视频和音频进行合并,从而形成行车记录文件,并将行车记录文件进行存储。
本实施例提供的行车记录拍摄方法,通过接收摄像头连续采集的视频帧,并分段提取所述视频帧,生成预定时长的视频,并通过麦克风提取与每段视频对应的音频,最后将提取的每段视频和音频合并形成行车记录文件。本实施例的行车记录拍摄方法,在提取视频帧生成预定时长的视频时并不影响接收摄像头连续采集的视频帧以及将采集的视频帧存储于缓存或内存的线程,因此并不需要将摄像头进行关闭,从而保证了视频的连续性,优化行车记录仪漏秒、或丢帧状况,保证行车记录仪视频拍摄的完整性。
图2为本发明另一实施例提供的行车记录拍摄方法流程图。如图2所示,在上述实施例的基础上,s101所述的接收摄像头连续采集的视频帧之后,还可包括:
s201、采用glsurfaceview对每一所述视频帧进行绘制和渲染,并实时显示在所述行车记录仪的屏幕上。
本实施例中,通过glsurfaceview将每一视频帧绘制在surface界面上,并经过渲染后,实时显示在行车记录仪的屏幕上,以便于用户实时观察拍摄到的内容,例如可以在倒车过程中观察行车记录仪作为倒车显示。本实施例通过glsurfaceview对每一视频帧进行绘制和渲染是在一个子线程中完成,不会阻塞主线程,以保证行车记录拍摄过程的流畅性。
更进一步的,在s102所述的分段提取所述视频帧,生成预定时长的视频前,还可包括:
s202、若识别行车过程中发生事故,对事故发生的时刻采集的所述视频帧进行标记;或者,接收用户输入的标记指令,对所述标记指令对应的所述视频帧进行标记。
由于存储空间有限,在存储空间不足时需要删除最早保存的行车记录文件,在本实施例中对事故发生的时刻的视频帧进行标记,或者由用户控制对视频帧进行标记,从而使该段行车记录文件中包含了标记,以使在存储空间不足时锁定该段行车记录文件,防止被删除导致证据丢失。其中,对视频帧进行标记,可方便在后续对该段行车记录文件播放时快速定位到事故发生时刻,给用户带来更多的便利。
本实施例中,所述若识别行车过程中发生事故,对事故发生的时刻采集的所述视频帧进行标记,具体可包括:
接收重力感测器识别到碰撞或紧急刹车后发送的事故信号、或距离传感器检测到距物体的距离小于预设阈值时发送的事故信号;
根据事故信号对对应的视频帧进行标记。
通过重力感测器或距离传感器来实现事故的识别,具有较高的灵敏性。此外距离传感器检测物体与汽车的距离,还可应用于汽车的防盗,例如在锁车状态下,如果检测到有物体距离汽车的距离小于预设阈值时,对视频帧进行标记,以便于被盗后的取证。
图3为本发明一实施例提供的行车记录拍摄装置的结构图。本实施例提供一种行车记录拍摄装置,可以执行行车记录拍摄方法实施例提供的处理流程,如图3所示,本实施例提供的行车记录拍摄装置,具体包括:接收模块10、视频生成模块20、音频生成模块30以及合成模块40。
其中,接收模块10用于接收摄像头连续采集的视频帧;视频生成模块20用于分段提取所述视频帧,生成预定时长的视频;音频生成模块30用于通过麦克风提取与每段视频对应的音频;合成模块40用于将提取的每段视频和音频合并形成行车记录文件。
进一步的,视频生成模块20具体用于:采用glsurfaceview实时提取所述视频帧,并进行编码,在到达每段所述预定时长时对编码后的该段视频进行存储;或者,在到达每段所述预定时长时,采用glsurfaceview对该段预定时长内的视频帧进行提取和编码,生成该段预定时长对应的所述视频。
进一步的,如图4所示,上述行车记录拍摄装置还可包括显示模块50,用于采用glsurfaceview对每一所述视频帧进行绘制和渲染,并实时显示在所述行车记录仪的屏幕上。
进一步的,上述行车记录拍摄装置还可包括视频标记模块60,用于若识别行车过程中发生事故,对事故发生的时刻采集的所述视频帧进行标记;或者,接收用户输入的标记指令,对所述标记指令对应的所述视频帧进行标记。
其中,所述视频标记模块60具体用于:接收重力感测器识别到碰撞或紧急刹车后发送的事故信号、或距离传感器检测到距物体的距离小于预设阈值时发送的事故信号;根据事故信号对对应的视频帧进行标记。
本发明实施例提供的行车记录拍摄装置可以具体用于执行上述方法实施例的处理流程,具体功能此处不再赘述。
本实施例提供的行车记录拍摄装置,通过接收摄像头连续采集的视频帧,并分段提取所述视频帧,生成预定时长的视频,并通过麦克风提取与每段视频对应的音频,最后将提取的每段视频和音频合并形成行车记录文件。本实施例的行车记录拍摄装置,在提取视频帧生成预定时长的视频时并不影响接收摄像头连续采集的视频帧以及将采集的视频帧存储于缓存或内存的线程,因此并不需要将摄像头进行关闭,从而保证了视频的连续性,优化行车记录仪漏秒、或丢帧状况,保证行车记录仪视频拍摄的完整性。
在本发明所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
上述以软件功能单元的形式实现的集成的单元,可以存储在一个计算机可读取存储介质中。上述软件功能单元存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本发明各个实施例所述方法的部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
本领域技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。上述描述的装置的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!