一种手术会诊系统及手术室音频采集方法与流程
本发明涉及医疗设备领域,特别涉及一种手术会诊系统,还涉及一种手术室音频采集方法。
背景技术:
目前,对于疑难手术寻求外院专家进行远程指导会诊成为趋势,一方面可以提高手术的成功率,另一方面可以实现优质医疗资源对边远地区的覆盖,同时也可以节约医疗专家的出行时间。
现有的会诊系统主要由手术台前方的显示器、手术台上方的摄像头、以及手术台前方的摄像头组成。手术台前方的显示器用于显示会诊专家图像和输出语音,并且采集手术室的语音信号,手术台上方的摄像头用于采集手术操作过程,手术台前方摄像头用于采集手术人员或者手术仪器显示图像。
现有的会诊系统,由于是在手术室中使用,语音采集效果较差,远程专家会有收听不清楚的情况,影响手术进程。
技术实现要素:
本发明提出一种手术会诊系统及手术室音频采集方法,解决了现有技术中手术会诊系统语音采集效果差的问题。
本发明的技术方案是这样实现的:
一种手术会诊系统,包括:
语音采集装置;其中,
语音采集装置包括多个麦克风和消噪模块;
多个麦克风分别设置在手术室的多个位置,手术台上方设置至少一个麦克风;
消噪模块包括声纹识别单元、音量计算单元和音频叠加单元;
声纹识别单元被配置为对每个麦克风采集到的音频信号中的声纹信息进行识别,每个声源对应一个声纹信息;
音量计算单元被配置为对每个麦克风采集到的同一声源的音量值进行计算;
音频叠加单元被配置为根据各个麦克风采集到同一声源的音量值,将音量值最大的麦克风采集到的该声源的音频信号作为主音频信号,其他麦克风采集到的该声源的音频信号不输出,仅用于计算该声源的音量值,将所有麦克风采集到的该声源的音量值相叠,与该声源的主音频信号合成后作为该声源的音频信号输出。
可选地,上述手术会诊系统,还包括:身份识别模块,被配置为根据用户图像,识别用户身份。
可选地,上述手术会诊系统,还包括:位置识别模块,被配置为根据用户图像,判断用户所在位置。
可选地,所述音频叠加单元还被配置为:根据用户所在位置,指定离该用户距离最近的麦克风采集到的音频信号为主音频信号,其他麦克风采集到的该声源的音频信号不输出,仅用于计算该声源的音量值。
本申请还提出了一种手术室音频采集方法,包括:
在手术室的多个位置设置麦克风,采集手术室的多个位置的音频信号;
对每个麦克风采集到的音频信号中的声纹信息进行识别,每个声源对应一个声纹信息;
对每个麦克风采集到的同一声源的音量值进行计算;
根据各个麦克风采集到同一声源的音量值,将音量值最大的麦克风采集到的该声源的音频信号作为主音频信号,其他麦克风采集到的该声源的音频信号不输出,仅用于计算该声源的音量值,将所有麦克风采集到的该声源的音量值相叠,与该声源的主音频信号合成后作为该声源的音频信号输出。
可选地,上述手术室音频采集方法,还包括:根据用户图像,识别用户身份。
可选地,上述手术室音频采集方法,还包括:根据用户图像,判断用户所在位置。
可选地,上述手术室音频采集方法,还包括:根据用户所在位置,指定离该用户距离最近的麦克风采集到的音频信号为主音频信号,其他麦克风采集到的该声源的音频信号不输出,仅用于计算该声源的音量值。
本发明的有益效果是:提高手术室中医护人员的语音采集效果,方便与远程专家交流。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请一种手术会诊系统的示意图;
图2为本申请一种手术室音频采集方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
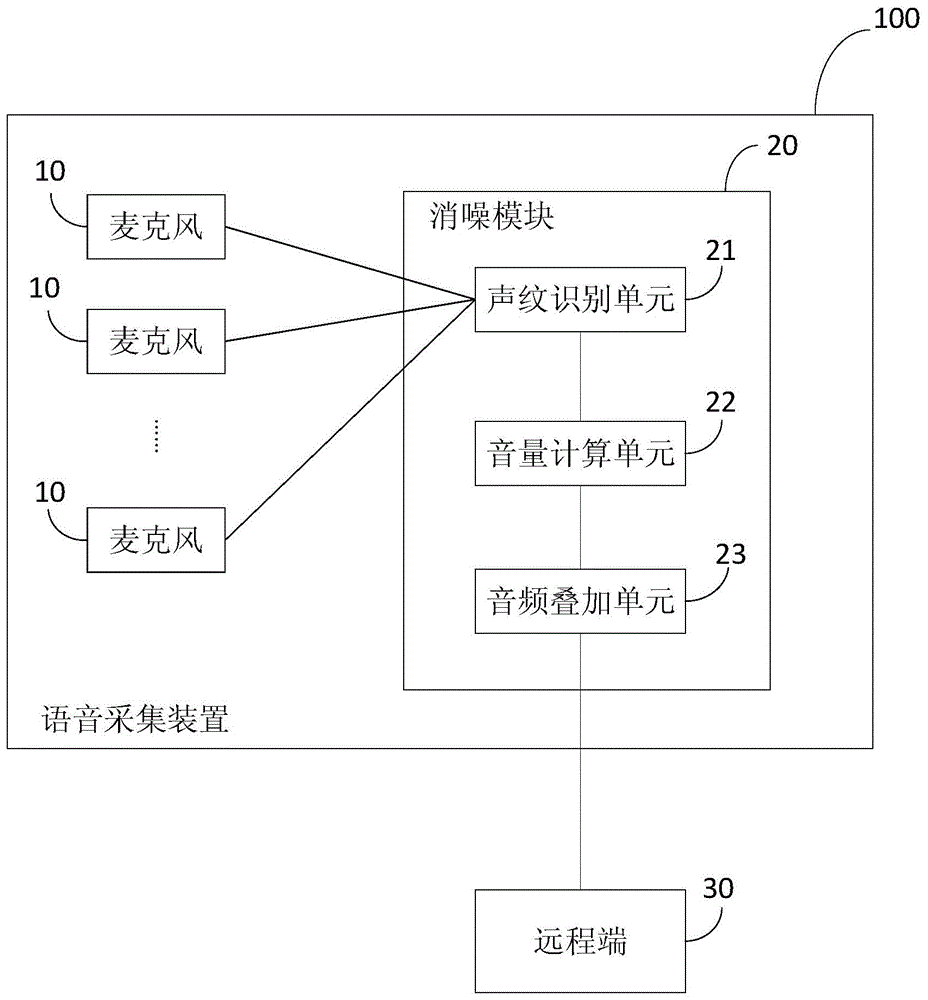
如图1所示,本申请提出了一种手术会诊系统,包括:语音采集装置100,语音采集装置被配置为对手术室中的医务人员的语音进行采集,输出音频信号到远程专家所在的远程端。其中,语音采集装置包括多个麦克风10和消噪模块20。多个麦克风10分别设置在手术室的多个位置,手术台上方设置至少一个麦克风,手术室的其他位置根据面积分配剩余麦克风。例如,手术台上方设置一个或多个麦克风,监控仪器侧设置至少一个麦克风,保证手术操作人员以及仪器控制人员的语音能够被有效采集。消噪模块20包括声纹识别单元21、音量计算单元22和音频叠加单元23。
在一些实施例中,声纹识别单元21被配置为对每个麦克风采集到的音频信号中的声纹信息进行识别,每个声源对应一个声纹信息,由于多个麦克风会同时采集到同一声源的音频信号,因此,一个声源也即一个声纹信息同时对应多个音频信号。由于手术室中的声源比较单一,主要为医护人员的对话语音,因此,声源通常为相应的医护人员的语音。例如,医生a说出了一段语音,声纹识别单元21识别出多个麦克风采集的音频信号中包含该声纹信息,进而对该声纹信息对应的音频信号进行归类。由于每个麦克风与声源的距离不同,因此,各个麦克风采集到的该声源的音频信号的音量值并不相同,而且会有延时甚至回音,声纹识别单元21对同一声源的音频信号进行归类,可选地,声纹识别单元21还被配置为对预设时间延时范围内的同一声源的音频信号进行归类,作为同一段音频信号。
在一些实施例中,音量计算单元22被配置为对同一声源在预设时间范围内的不同麦克风采集到的音频信号的音量值进行计算,按照音量值大小进行排序。例如,声纹识别单元21对同一声源的同一段语音进行了归类,音量计算单元22对该声源的音频信号的音量值进行计算并按照大小排序。
在一些实施例中,音频叠加单元23被配置为根据各个麦克风采集到同一声源的音量值,将音量值最大的麦克风采集到的该声源的音频信号作为主音频信号,其他麦克风采集到的该声源的音频信号不输出,仅用于计算该声源的音量值,将所有麦克风采集到的该声源的音量值相叠,与该声源的主音频信号合成后作为该声源的音频信号输出,输出的音频信号最终被远程端30的专家接收并收听。
在一些实施例中,上述手术会诊系统还包括:身份识别模块,被配置为根据用户图像,识别用户身份。可选地,身份识别模块包括摄像头,被配置为采集手术室中的图像,根据用户图像识别出用户身份。可选地,身份识别模块包括存储器,被配置为预先存储用户图像,当采集的手术室图像包含用户图像时,识别出用户身份。
在一些实施例中,上述手术会诊系统还包括:位置识别模块,被配置为根据用户图像,判断用户所在位置。可选地,位置识别模块还被配置为:获取确定身份的用户的位置。采用该可选实施例,位置识别模块对目标用户的位置进行跟踪,可以精确确定该用户位置。可选地,所述音频叠加单元还被配置为:根据用户所在位置,指定离该用户距离最近的麦克风采集到的音频信号为主音频信号,其他麦克风采集到的该声源的音频信号不输出,仅用于计算该声源的音量值。
例如,医生a为主治医生,对患者进行手术,因此,他的语音需要准确采集,首先身份识别模块确定医生a的身份,然后位置识别模块时刻跟踪医生a的位置,音频叠加单元指定离该医生a距离最近的麦克风采集到的音频信号为主音频信号,并与计算得到的音量值合成最终的医生a的语音发送到远程端。采用上述实施例,可以更加精准的提取用户的语音信号,降低噪声影响。
本申请还提出了一种手术室音频采集方法,包括:步骤1,在手术室的多个位置设置麦克风,采集手术室的多个位置的音频信号;步骤2,对每个麦克风采集到的音频信号中的声纹信息进行识别,每个声源对应一个声纹信息;步骤3,对每个麦克风采集到的同一声源的音量值进行计算;步骤4,根据各个麦克风采集到同一声源的音量值,将音量值最大的麦克风采集到的该声源的音频信号作为主音频信号,其他麦克风采集到的该声源的音频信号不输出,仅用于计算该声源的音量值,将所有麦克风采集到的该声源的音量值相叠,与该声源的主音频信号合成后作为该声源的音频信号输出。
可选地,上述手术室音频采集方法还包括:根据用户图像,识别用户身份。
可选地,上述手术室音频采集方法还包括:根据用户图像,判断用户所在位置。
可选地,上述手术室音频采集方法还包括:根据用户所在位置,指定离该用户距离最近的麦克风采集到的音频信号为主音频信号,其他麦克风采集到的该声源的音频信号不输出,仅用于计算该声源的音量值。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!